ZooKeeper原理及介绍
Zookeeper简介
1.1 什么是Zookeeper
-
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是大数据生态中的重要组件。它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
-
它是一个为分布式应用提供一致性协调服务的中间件
1.2 ZooKeeper提供了什么
- 文件系统
- Zookeeper提供一个多层级的节点命名空间(节点称为znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M。
- 通知机制
- client端会对某个znode建立一个watcher事件,当该znode发生变化时,这些client会收到zk的通知,然后client可以根据znode变化来做出业务上的改变等。
1.3 什么是分布式系统
-
很多台计算机组成一个整体, 一个整体一致对外并且处理同一请求
-
内部的每台计算机都可以相互通信(rest/rpc)
-
客户端到服务端的一次请求到响应结束会经历多台计算机
-
图示1

-
图示2
1.4 分布式系统的问题
-
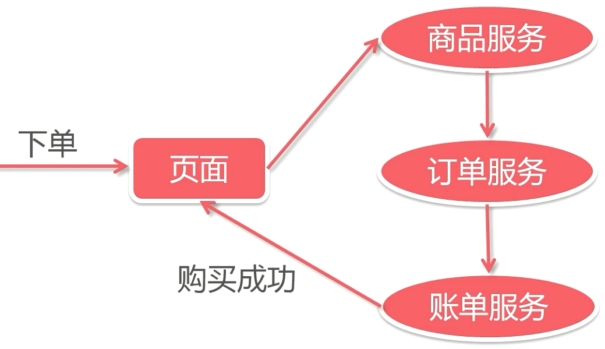
服务的动态注册和发现,为了支持高并发,OrderService被部署了4份,每个客户端都保存了一份服务提供者的列表,但这个列表是静态的(在配置文件中写死的),如果服务的提供者发生了变化,例如有些机器down了,或者又新增了OrderService的实例,客户端根本不知道,想要得到最新的服务提供者的URL列表,必须手工更新配置文件,很不方便。
-
问题 : 客户端和服务提供者的紧耦合
![]()
-
解决方案: 解除耦合,增加一个中间层 -- 注册中心它保存了能提供的服务的名称,以及URL。首先这些服务会在注册中心进行注册,当客户端来查询的时候,只需要给出名称,注册中心就会给出一个URL。所有的客户端在访问服务前,都需要向这个注册中心进行询问,以获得最新的地址。
![]()
-
注册中心可以是树形结构,每个服务下面有若干节点,每个节点表示服务的实例。
![]()
-
注册中心和各个服务实例直接建立Session,要求实例们定期发送心跳,一旦特定时间收不到心跳,则认为实例挂了,删除该实例。
![]()
-
-
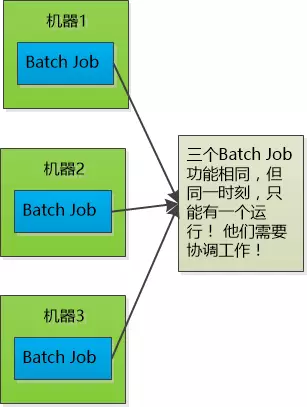
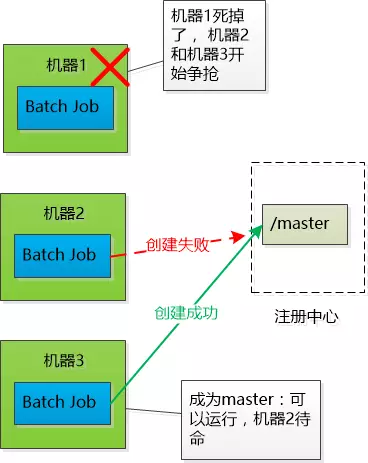
Job协调问题
-
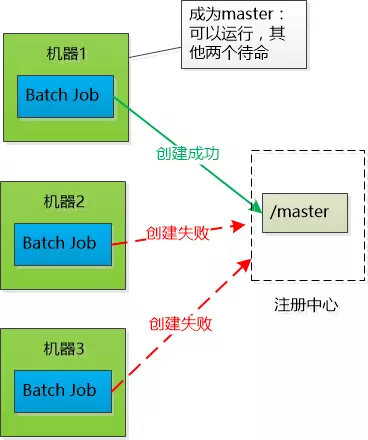
三个Job的功能相同,部署在三个不同的机器上,要求同一时刻只有一个可以运行,也就是如果有一个宕了的话,需要在剩下的两个中选举出
Master继续工作![]()
-
所以这三个Job需要互相协调
-
使用共享数据库表。我们知道数据库主键不能冲突,可以让三个Job向表中插入同样的数据,谁成功谁就是Master。缺点是如果抢到Master的Job挂了,则记录永远存在,其他的Job无法插入数据。所以必须加上定期更新的机制。
-
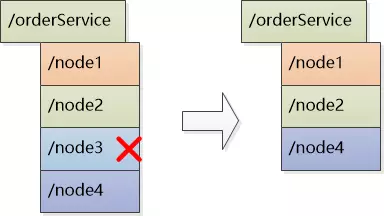
让Job在启动之后,去注册中心注册,也就是创建一个树节点,谁成功谁是Master(注册中心必须保证只能创建成功一次)。
![]()
-
这样,如果节点删除了,就开始新一轮争抢。
![]()
-
-
-
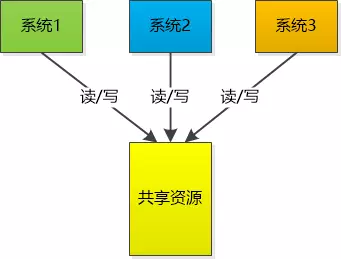
分布式锁, 多台机器上运行的不同的系统操作同一资源
![]()
-
使用Master选举的方式,让大家去抢,谁能抢到就创建一个
/distribute_lock节点,读完以后就删除,让大家再来抢。缺点是某个系统可能多次抢到,不够公平。 -
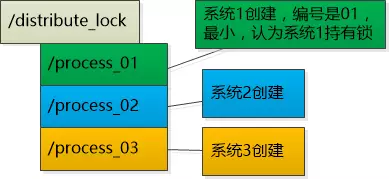
让每个系统在注册中心的
/distribute_lock下创建子节点,然后编号,每个系统检查自己的编号,谁的编号小认为谁持有了锁,比如下图中是系统1持有了锁![]()
-
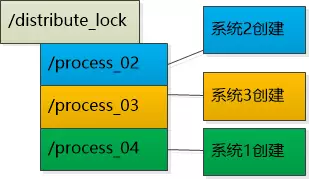
系统1操作完成以后,就可以把process_01删除了,再创建一个新的节点 process_04。此时是process_02最小了,所以认为系统2持有了锁。
![]()
-
操作完成以后也要把process_02节点删除,创建新的节点。这时候process_03就是最小的了,可以持有锁了。
![]()
-
-
注册中心的高可用
- 如果注册中心只有一台机器,一旦挂了,整个系统就宕了。所以需要多台机器来保证高可用性。这样引出了新的问题,比如树形结构需要在多台机器之间进行同步,通信超时了怎么办,如何保证树形结构在机器之间的强一致性。




1.5 Zookeeper作用
- master节点选举, 主节点down掉后, 从节点就会接手工作, 并且保证这个节点是唯一的,这也就是所谓首脑模式,从而保证我们集群是高可用的
- 统一配置文件管理, 即只需要部署一台服务器, 则可以把相同的配置文件同步更新到其他所有服务器, 此操作在云计算中用的特别多(例如修改了redis统一配置)
- 数据发布与订阅, 类似消息队列MQ
- 分布式锁,分布式环境中不同进程之间争夺资源,类似于多进程中的锁
- 集群管理, 保证集群中数据的强一致性
1.6 Zookeeper的特性
- 一致性: 数据一致性, 数据按照顺序分批入库
- 原子性: 事务要么成功要么失败
- 单一视图: 客户端连接集群中的任意zk节点, 数据都是一致的
- 可靠性:每次对zk的操作状态都会保存在服务端
- 实时性: 客户端可以读取到zk服务端的最新数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号