初学python爬虫,爬取“豆瓣电影 Top 250”相关信息,并下载电影封面
注:
- 所学的视频教程:B站Python爬虫基础5天速成(2021全新合集)Python入门+数据可视化
- 对应的网址:豆瓣电影 Top 250
- 对应的html文本位置标注:
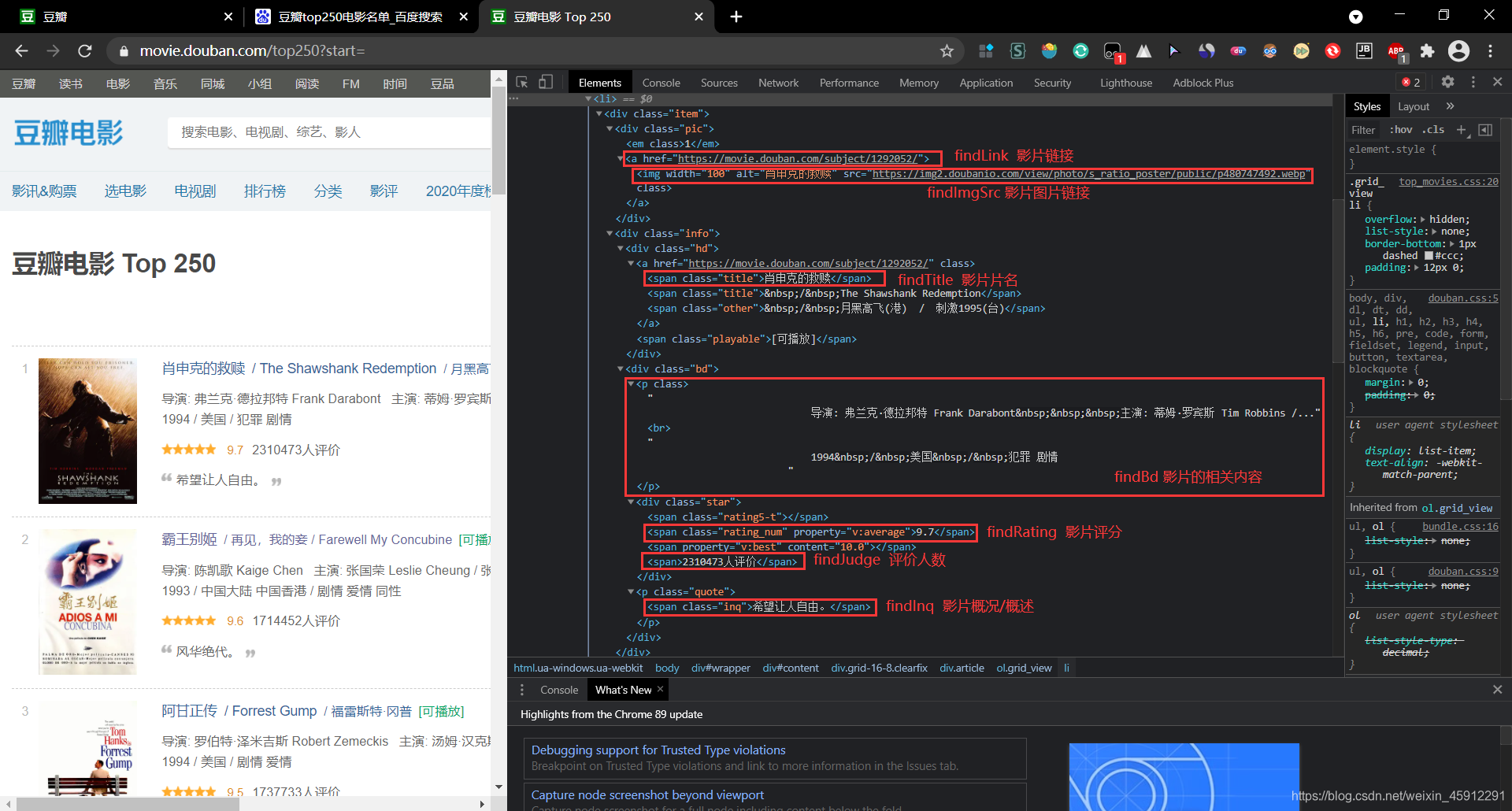
一、爬取“豆瓣电影 Top 250”相关信息:

1、准备工作
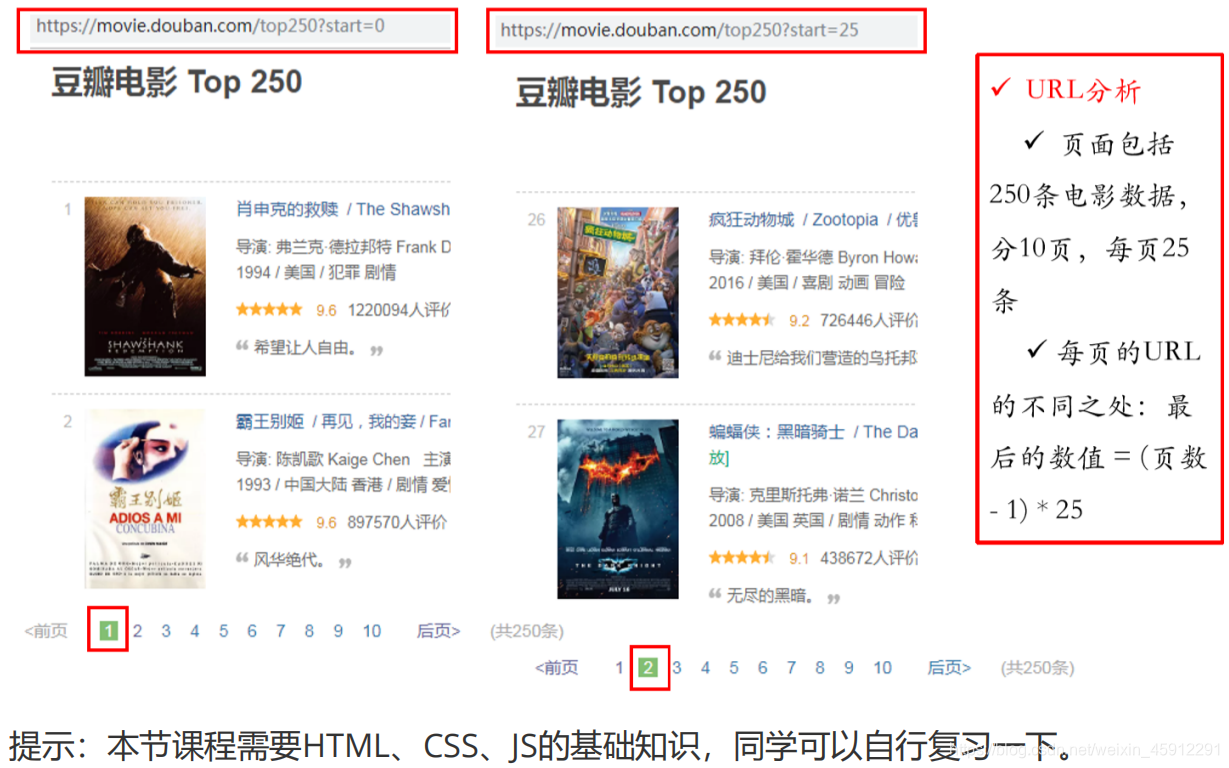
2、获取数据

补充:urllib
urllib的详解使用 - 简书:https://www.jianshu.com/p/63dad93d7000
3、标签解析

补充:BeautifulSoup4和re
BeautifulSoup4相关介绍 - web教程网:http://www.jsphp.net/python/show-24-214-1.html
Python 正则表达式 | 菜鸟教程:https://www.runoob.com/python/python-reg-expressions.html
4、保存数据
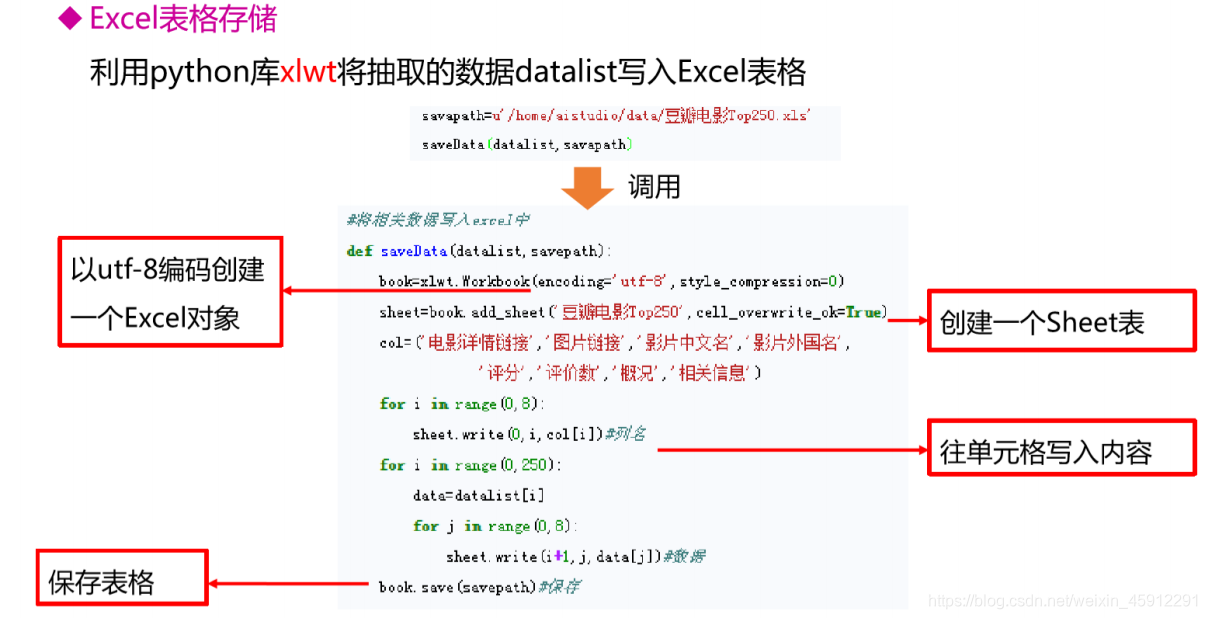
补充:xlwt
python模块之xlwt模块:https://blog.csdn.net/qq_31851107/article/details/103691790
附:爬取“豆瓣电影 Top 250”相关信息的完整代码:
# -*- coding: utf-8 -*-
# @Time : 2021/3/17 21:04
# @Author : 信仰
# @File : spider.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import re
import urllib
import xlwt # Python 用来在 Excel 写入数据和格式化数据的工具包
import sqlite3
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath = "豆瓣电影top250.xls" # 默认与此.py文件在同一个目录下
saveData(datalist, savepath)
# askURl("https://movie.douban.com/top250?start=")
# 全局变量
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,表示规则(字符串的模式)
# .* 表示许多的各种的字符, ? 表示 这样的字符"有"或者“没有”(0次或者1次)
# 例子:<a href="https://movie.douban.com/subject/1291546/">或者<a href=" 将没有链接的包含在内(考虑意外情况)
# 影片图片
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S表示忽略换行符 因为 . 不包含换行符,加上re.S就可以把 .的概念“匹配”到任何字符
# 影片片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 影片评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 找到评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>') # \d* 表示0到多个数字
# 不能写成(r'<span>1893209人评价</span>') 因为可能因为span标签不止一个而匹配不成功
# 找到概况
findInq = re.compile(r'<span class="inq">(.*)</span>')
# 找到影片的相关内容
findBd = re.compile(r'<p class="">(.*?)</p>', re.S) # 忽视(.所不包含的)换行符
# 此处的?不可省略, 因为<\p>可能不止一个
# 注:省略?之后在”肖申克的救赎“电影中输出的结果:'导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins ... 1994\xa0 \xa0美国\xa0 \xa0犯罪 剧情\n < p>\n<div class="star">\n<span class="rating5-t">< span>\n<span class="rating_num" property="v:average">9.7< span>\n<span content="10.0" property="v:best">< span>\n<span>2310473人评价< span>\n< div>\n<p class="quote">\n<span class="inq">希望让人自由。< span>'
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURl(url) # 保存获取到的网页源码
# 逐一解析数据
soup = BeautifulSoup(html,
"html.parser") # 指定Beautiful的解析器为“html.parser”,类似的还有BeautifulSoup(markup,"lxml")BeautifulSoup(markup, "lxml-xml") BeautifulSoup(markup,"xml")等等很多种
# 注:解析器负责把 HTML 解析成相关的对象,而 BeautifulSoup 负责操作数据(增删改查)。“html.parser” 是 Python 内置的解析器
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串,形成列表(注:class是一个类别/属性,需要加下划线,否则会报错)
# print(item)#测试查看电影item
data = []
item = str(item)
# 影片详情的链接
link = re.findall(findLink, item)[0] # re库用来通过正则表达式查找指定的字符串
data.append(link) # 添加链接
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc) # 添加图片
titles = re.findall(findTitle, item) # 片名可能只有一个中文名,没有外国名
if (len(titles) == 2):
ctitle = titles[0] # 添加中文名
data.append(ctitle)
otitle = titles[1].replace("/", "") # 去掉无关的符号
data.append(otitle) # 添加外国名
else:
data.append(titles[0])
data.append(' ') # 外国名字留空
rating = re.findall(findRating, item)[0]
data.append(rating) # 添加评分
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum) # 添加评价人数
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "") # 去掉句号
data.append(inq) # 添加概述
else:
data.append(" ") # 留空
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) # 去掉<br/>
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data)
# print(datalist)
return datalist
def askURl(url): # 得到指定一个URL的网页内容
head = {
"User-Agent": "Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome / 89.0.4389.90Safari / 537.36"
}
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据
def saveData(datalist, savepath):
print("save....")
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象 style_compression=0表示样式压缩的效果
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) # 创建工作表 cell_overwrite_ok=True表示覆盖之前的内容
col = ("电影详情链接", "图片链接", "影片中文名", "影片外国名", "评分", "评价数", "概况", "相关信息")
for i in range(0, 8):
sheet.write(0, i, col[i]) # 列名
for i in range(0, 250):
print("第%d条" % (i + 1))
data = datalist[i]
for j in range(0, 8):
sheet.write(i + 1, j, data[j]) # 数据
book.save(savepath) # 保存
if __name__ == "__main__":
main()
print("爬取完毕!")
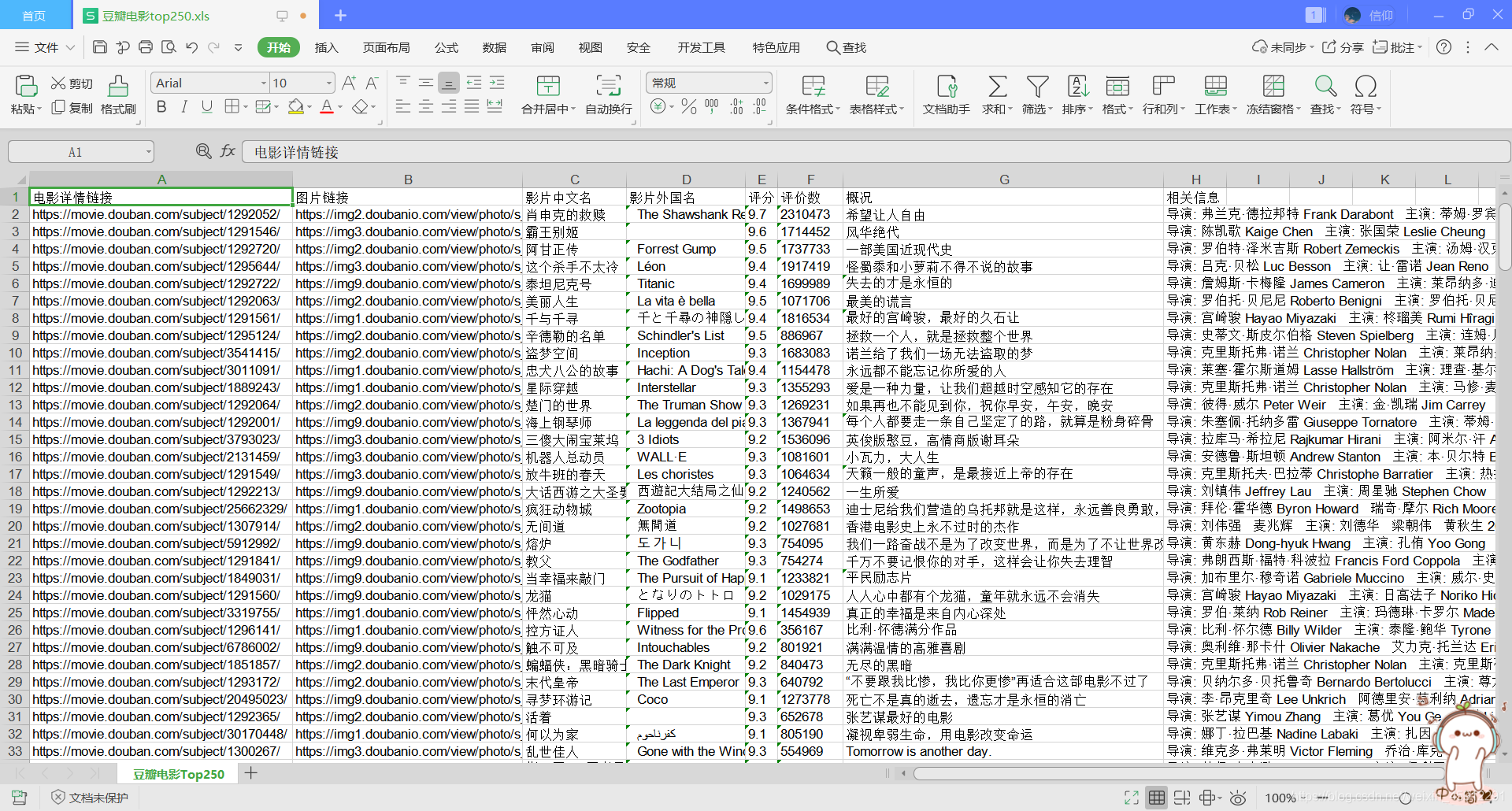
爬取成功后生成的Excel表格:
(注:生成的xls文件路径:savepath = "豆瓣电影top250.xls" # 默认与此.py文件在同一个目录下)
二、爬取/下载top250电影对应的封面
对“爬取“豆瓣电影 Top 250”相关信息”的代码适当修改,正则表达式提取部分只保留findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)部分,
找到所有图片的链接之后,保存图片的关键函数如下(含有对图片的命名):
def DownloadImg(datalist):
x = 1
for imgurl in datalist:
urllib.request.urlretrieve(imgurl, 'D:\IDMdownload\Image\%s.jpg' % x)
x += 1
print("已经爬取", x, "张图片")
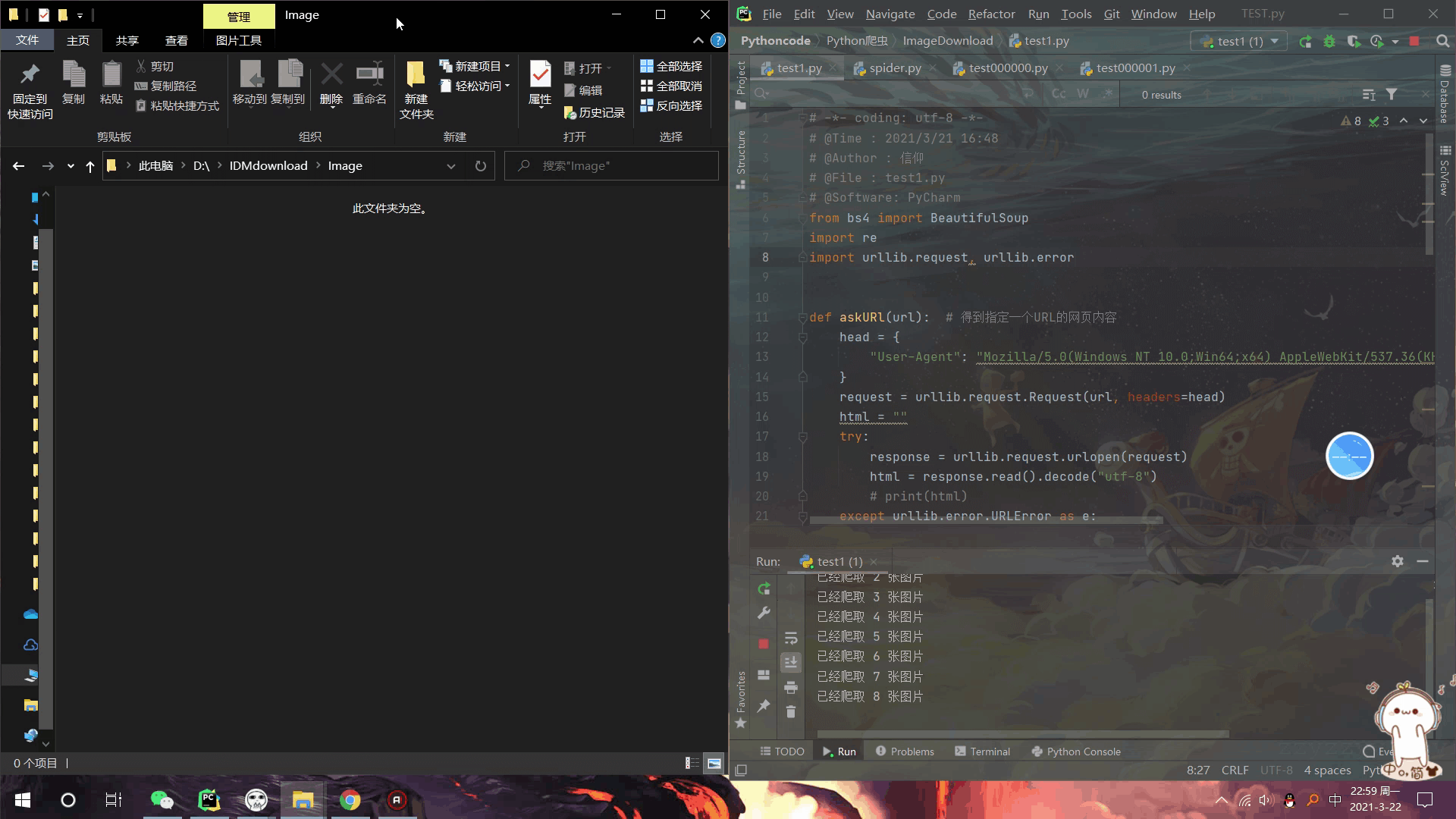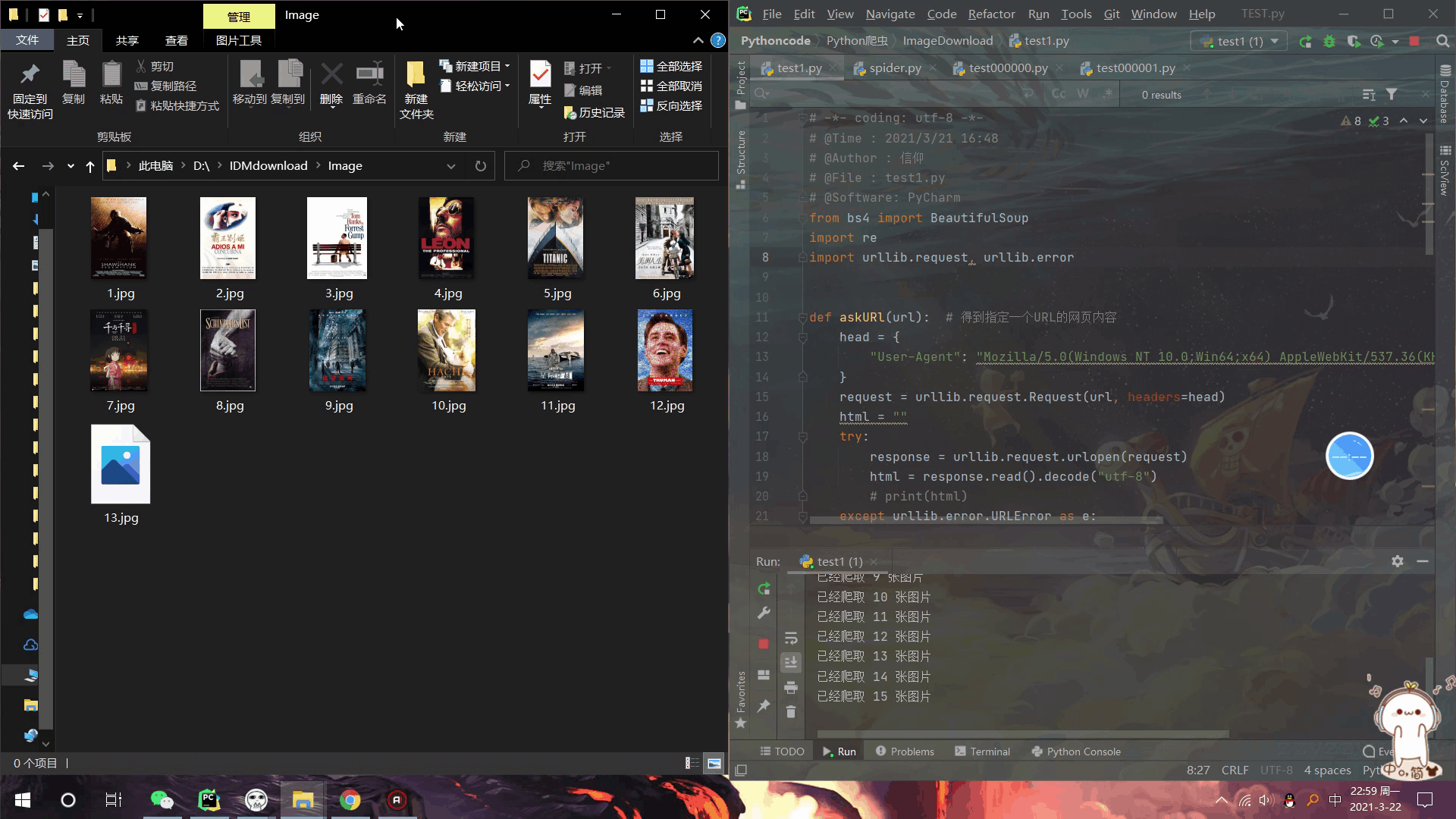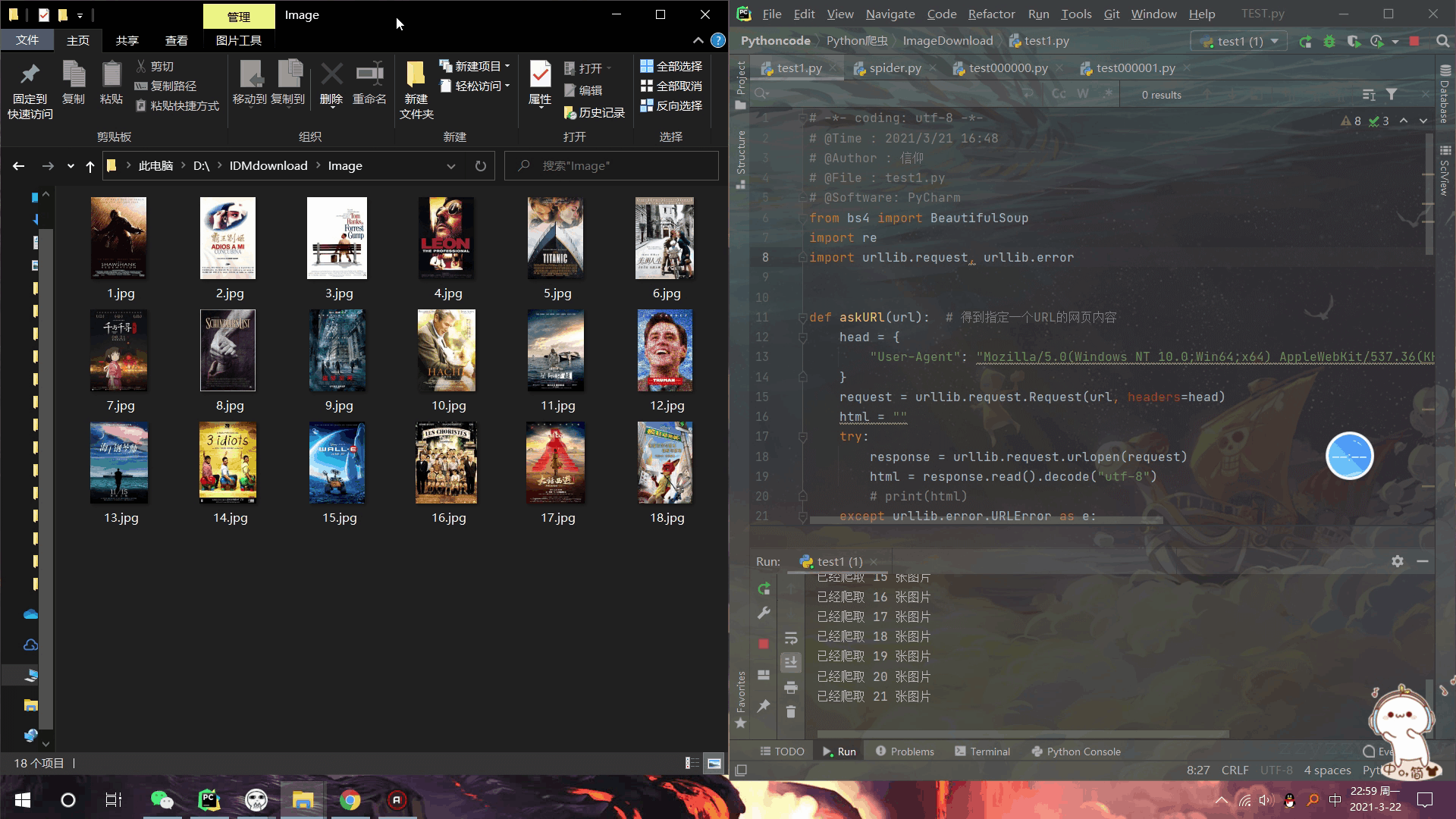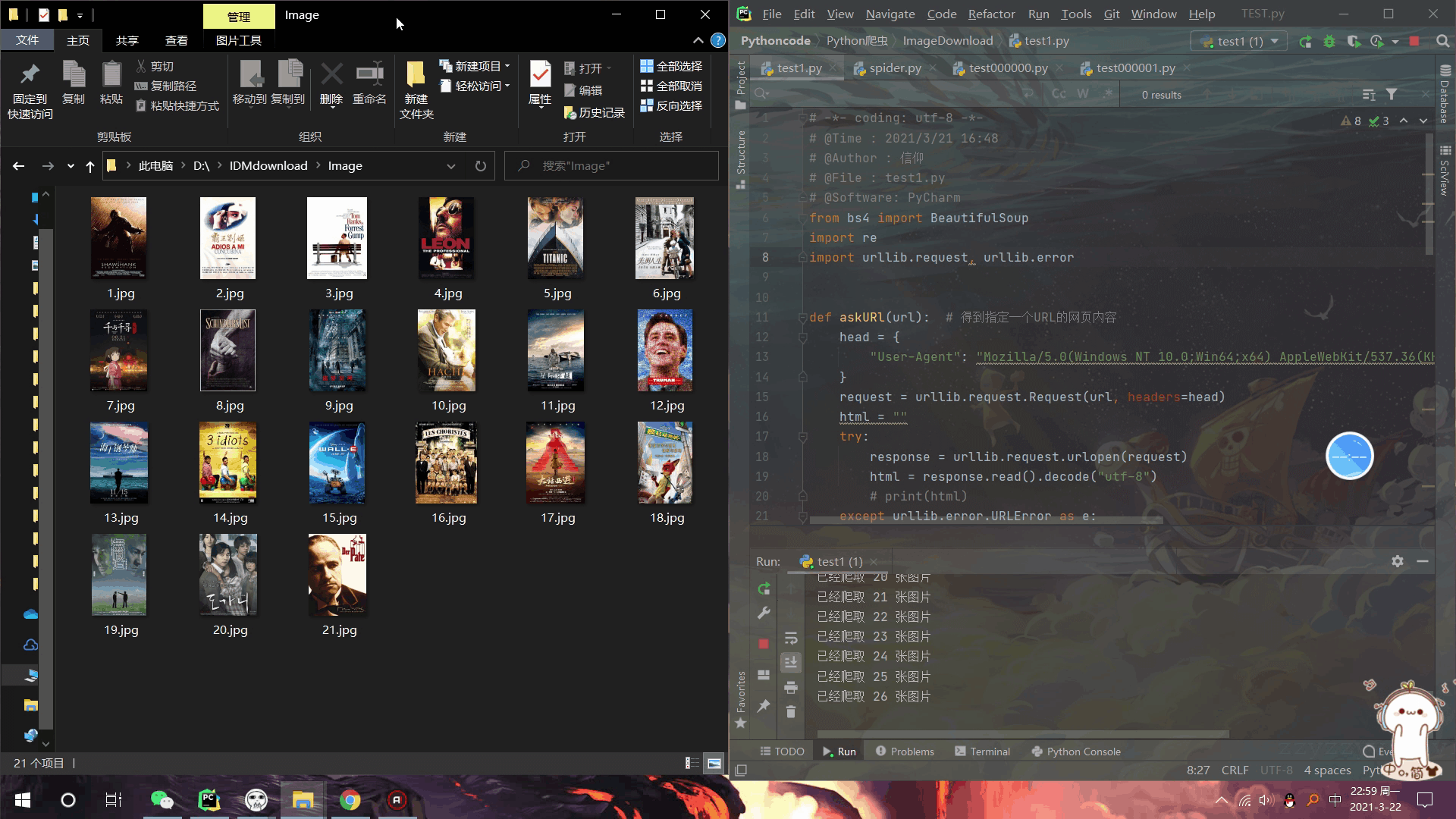
效果展示
附:下载电影封面的完整代码:
# -*- coding: utf-8 -*-
# @Time : 2021/3/21 16:48
# @Author : 信仰
# @File : test1.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import re
import urllib.request, urllib.error
def askURl(url): # 得到指定一个URL的网页内容
head = {
"User-Agent": "Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome / 89.0.4389.90Safari / 537.36"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
def getData(baseurl):
datalist = []
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURl(url) # 保存获取到的网页源码
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
item = str(item)
imgSrc = re.findall(findImgSrc, item)[0]
datalist.append(imgSrc) # 添加图片链接
return datalist
def DownloadImg(datalist):
x = 1
for imgurl in datalist:
urllib.request.urlretrieve(imgurl, 'D:\IDMdownload\Image\%s.jpg' % x)
x += 1
print("已经爬取", x, "张图片")
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl)
DownloadImg(datalist)
if __name__ == "__main__":
main()
print("爬取完毕!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号