python正则提取txt文本
首先,我们的文本可能有两种格式
1.没有特殊符号的单一村文本,比如这一份先知的标题与对应的url

2.第二种是有规律的,比如ip,账号密码,也是我们渗透里经常遇到的,

对于提取这2中文本的关键内容,这就需要用我们的正则了
第一种用如下代码
# -*- coding: utf-8 -* import re f = open("dg.txt", "r", encoding='utf-8') data = f.readlines() f.close() for line in data: pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') string = str(line) url = re.findall(pattern,string) f1 = open("url.txt", "a+", encoding='utf-8') for urls in url: f1.write(urls+'\n') f1.close()
这是提取url,我们唯一需要改变的就是第七行的正则即可,这是效果
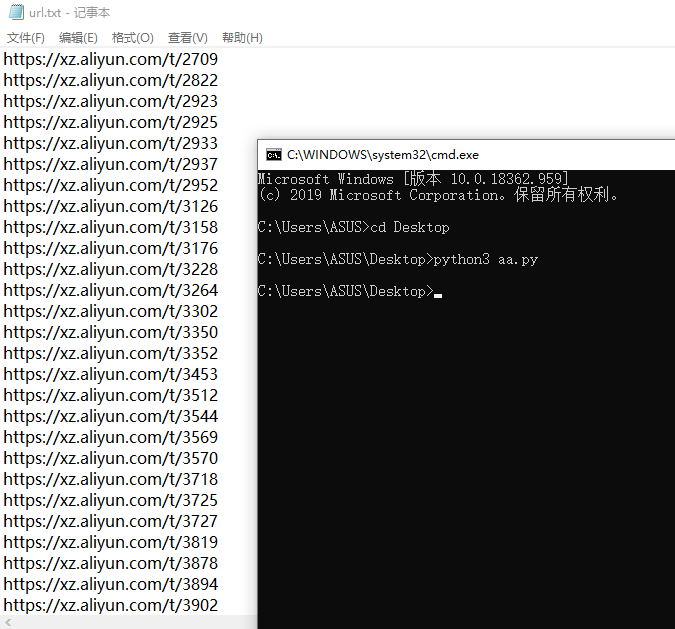
对于第二种,我们用如下代码
# -*- coding: utf-8 -* import re f = open("p.txt", "r", encoding='utf-8') data = f.readlines() f.close() for line in data: f1 = open("city.txt", "a+", encoding='utf-8') x = line.split("----") f1.write(x[4]) f1.write("\n") print(x[4]) f1.close()
这是效果
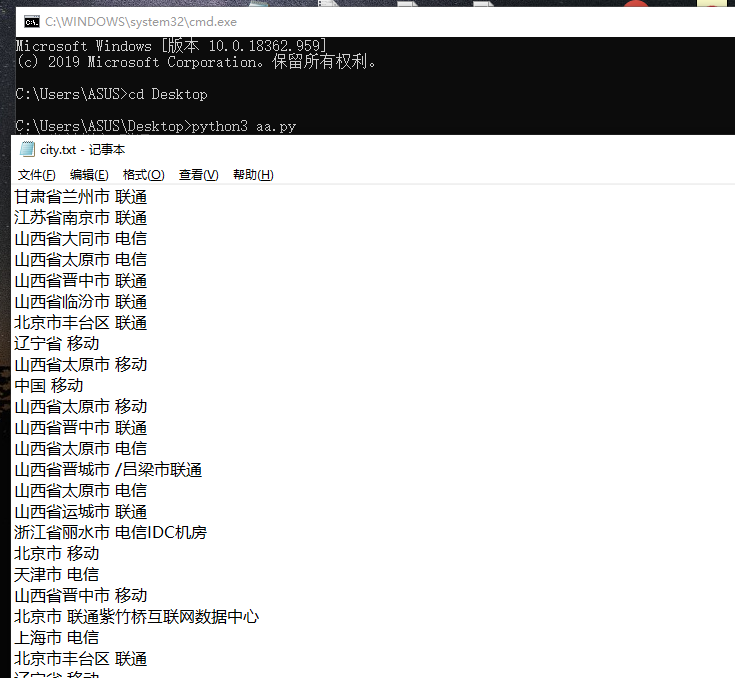
我们只需将特殊符号作为正则的标志,即可提取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号