docker搭建hadoop+hive+spark+hbase+zookeeper+scale集群adoop集群搭建(docker)
基于docker搭建hadoop+hive+spark+hbase+zookeeper+scale集群
1、设置主机上的虚拟缓存
当本地内存不足时,可以使用虚拟内存将一些内存数据转移到硬盘上,从而扩展计算机的内存容量。这样可以让计算机运行更复杂、更占用内存的程序,不会出现内存不足的情况。减轻物理存储器不足的压力,设置虚拟内存可以在内存不够的情况下将缓存一时放在硬盘上,解决内存不足问题。
通过虚拟内存,操作系统可以将应用程序使用的内存空间转换为虚拟地址,从而允许应用程序访问不在物理内存中的数据。这样可以避免因为内存不足而导致系统性能下降的情况。虚拟内存可以及时从物理内存中调出数据放到虚拟内存空间中,以便在高负载情况下释放内存空间,提升程序的运行速度。
设置步骤如下

2、虚拟机在安装时CPU、内存、硬盘的参数设置
处理器核心数量:12核的处理器有12个核心,而16核的处理器有16个核心,核心数量的增加可以提高处理器的并行计算能力,从而能够更快地处理大量的数据和复杂的任务。
性能表现:由于电脑的处理器是计算任务的核心,因此处理器性能的提高可以显著提高电脑的整体性能。由于16核处理器的处理能力更强大,因此在计算密集型应用程序中,16核相比12核的处理器会有更快的速度和更好的性能表现。
计划构建3个虚拟化的集群,因此至少设置CPU的内核总数为4,此处根据自己电脑性能来自行设置,为了提高性能,我此处将设置16核

虚拟机内存设置至少8个G,可根据自己电脑配置设置,由于我电脑内存是64G,我这里给虚拟机分配设置16G内存

8个G的内存,建议虚拟机的磁盘空间设置为50G


系统分区设置

设置静态ip地址

虚拟机配置阿里镜像
使用wget从指定的路径下载镜像文件

更新虚拟机上的软件包,更新过程中有两次输入y,总更新文件数625个,所以如果你虚拟硬盘空间不够,就先别操作了
注意:
yum update是yum命令的一个选项,用于更新系统中的所有已安装的软件包到最新版本。
当执行yum update命令时,yum会先检查可用的软件包,确定哪些软件包需要更新,并将它们的最新版本下载到系统中。这个过程中,yum会自动检查所有软件包的依赖关系,并在必要时同时更新依赖关系。更新完成后,yum还会重新配置系统中的软件包,以确保它们都能够正常工作。
yum update的底层原理是基于yum的软件包仓库的工作原理,yum会从远程的yum软件包仓库中获取软件包的信息,包括软件包的版本、依赖关系等,并与本地系统上已安装的软件包进行比较,确定需要更新哪些软件包。更新软件包的过程中,yum会在本地缓存中保存软件包,以便在需要时再次使用,以减少下载时间和网络流量。
yum update的好处是可以方便地更新所有已安装的软件包,以保证系统的安全性和稳定性。但需要注意的是,更新软件包可能会带来一些风险,例如更新后可能会出现兼容性问题,因此在更新之前最好备份系统或测试更新效果,以避免数据丢失或系统崩溃等问题。

.......中间执行过程省略,625行太多了

......中间执行过程省略,625行太多了

3、安装Docker
先删除docker,执行以下脚本

docker的安装步骤参考我站内帖子的步骤,此处不在演示,链接如下:
4、拉取镜像
(1)搜索镜像hadoop的基础集群镜像


(2)拉取镜像hadoop-base镜像

(3)拉取hadoop-namenode镜像

(4)拉取hadoop-datanode镜像

(5)拉取hadoop-resourcemanager镜像

(6)拉取hadoop-nodemanager镜像

(7)拉取hadoop-historyserver镜像

5.运行容器
(1)指定docker内部网络
查看子网ip地址和网关地址

指定docker的桥接网络模式,docker网络是为了让容器和容器之前通信的
创建时最好指定容器端口号映射。10000端口为hiveserver端口,后面本地客户端要通过beeline连接hive使用,有其他组件要安装的话可以提前把端口都映射出来,毕竟后面容器运行后再添加端口还是有点麻烦的。

要删除构建的网络可以通过docker network rm 网络名称
(2)建立Master容器


退出容器指令:ctrl+d
进入容器:docker exec -it 容器名 bash
(3)建立Slave1容器

(4)建立Slave2容器

(5)查看所有构建的容器

(6)三台机器修改hosts
第一种脚本直接编辑方法:


第二种finalshell快捷工具编辑模式:

提示:每个容器的ip都需要通过命令ifconfig查看,或者在创建的时候通过‘ --ip ’指定ip地址
(7)查看运行中的容器

由于容器是退出状态,没有启动,因此我们可以先启动容器







(8) 启动容器
hadoop集群搭建(docker)
1.准备安装包(hadoop-3.3.2.tar.gz和jdk-8u371-linux-x64.tar.gz)
2.创建Dockerfile文件:

# 镜像源 FROM centos:7 # 添加元数据 LABEL author="作者" date="2023/05/30" # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no RUN yum install -y openssh-server sudo RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config # 安装openssh-clients RUN yum install -y openssh-clients # 安装which RUN yum install -y which # 添加测试用户root,密码root,并且将此用户添加到sudoers RUN echo "root:root" | chpasswd RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key #启动sshd服务并且暴露22端口 RUN mkdir /var/run/sshd EXPOSE 22 # 拷贝并解压jdk ADD jdk-8u371-linux-x64.tar.gz /usr/local/ RUN mv /usr/local/jdk1.8.0_371 /usr/local/jdk1.8 ENV JAVA_HOME /usr/local/jdk1.8 ENV PATH $JAVA_HOME/bin:$PATH # 拷贝并解压hadoop ADD hadoop-3.3.2.tar.gz /usr/local RUN mv /usr/local/hadoop-3.3.2 /usr/local/hadoop ENV HADOOP_HOME /usr/local/hadoop ENV PATH $HADOOP_HOME/bin:$PATH
ENV LANG="en_US.utf8" # 设置容器启动命令 CMD ["/usr/sbin/sshd", "-D"]
3.构建并配置镜像
hadoop和jdk安装包要和Dockerfile文件放在同一目录,然后构建镜像
docker build -t hadoop-test .
构建容器:
docker run -d --name hadoop-test hadoop-test
进入容器:
docker exec -it hadoop-test bash
切换到hadoop配置目录:
cd /usr/local/hadoop/etc/hadoop/
配置hadoop环境变量:
vi hadoop-env.sh
追加以下内容:
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export JAVA_HOME=/usr/local/jdk1.8
配置核心参数:
vi core-site.xml
添加以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<!-- default 4096(4M) -->
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<!-- unit: minute, default 0 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
配置hdfs:
vi hdfs-site.xml
添加以下内容:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
配置资源管理:
vi yarn-site.xml
添加以下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
</configuration>
配置分布式计算:
vi mapred-site.xml
添加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
配置子节点:
vi workers
把默认的localhost改为datanode的hostname:
#localhost slave1 slave2
退出并关闭容器:
exit docker stop hadoop-test
把容器保存为新的镜像:
docker commit hadoop-test hadoop:base
4.搭建集群
创建network:
docker network create --subnet=192.168.0.0/24 hadoop
构建master、slave1、slave2三个容器:
docker run -d --name master --hostname master --network hadoop --ip 192.168.0.10 -P -p 8088:8088 -p 9870:9870 -p 19888:19888 hadoop:base docker run -d --name slave1 --hostname slave1 --network hadoop --ip 192.168.0.11 -P hadoop:base docker run -d --name slave2 --hostname slave2 --network hadoop --ip 192.168.0.12 -P hadoop:base
配置node免密登录:
进入master容器:
docker exec -it master bash
生成密钥,一直回车就行:
ssh-keygen
把密钥分发给其它node,需要输入yes和密码,密码是Dockerfile中配置的root:
ssh-copy-id master ssh-copy-id slave1 ssh-copy-id slave2
进入其它datanode做同样的操作。
在master容器中启动服务:
格式化hdfs(第一次需要格式化,后续不需要):
hdfs namenode -format
启动服务:
$HADOOP_HOME/sbin/start-all.sh
启动历史日志服务:
$HADOOP_HOME/bin/mapred --daemon start historyserver
查看启动的服务:
jps
如下所示:
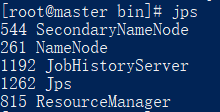
进入slave1、slave2容器,
查看启动的服务:
jps
如下所示:
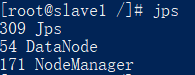
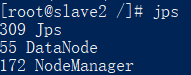
关闭服务:
$HADOOP_HOME/bin/mapred --daemon stop historyserver $HADOOP_HOME/sbin/stop-all.sh
5.hadoop测试
在master容器新建一个文件,随便输入一些内容,保存:
vi test.txt welcome hadoop
把文件保存到hdfs根目录:
hdfs dfs -put test.txt /
查看hdfs根目录:
hadoop fs -ls /
可以看到以下内容:

也可以访问浏览器页面localhost:9870,如下所示:
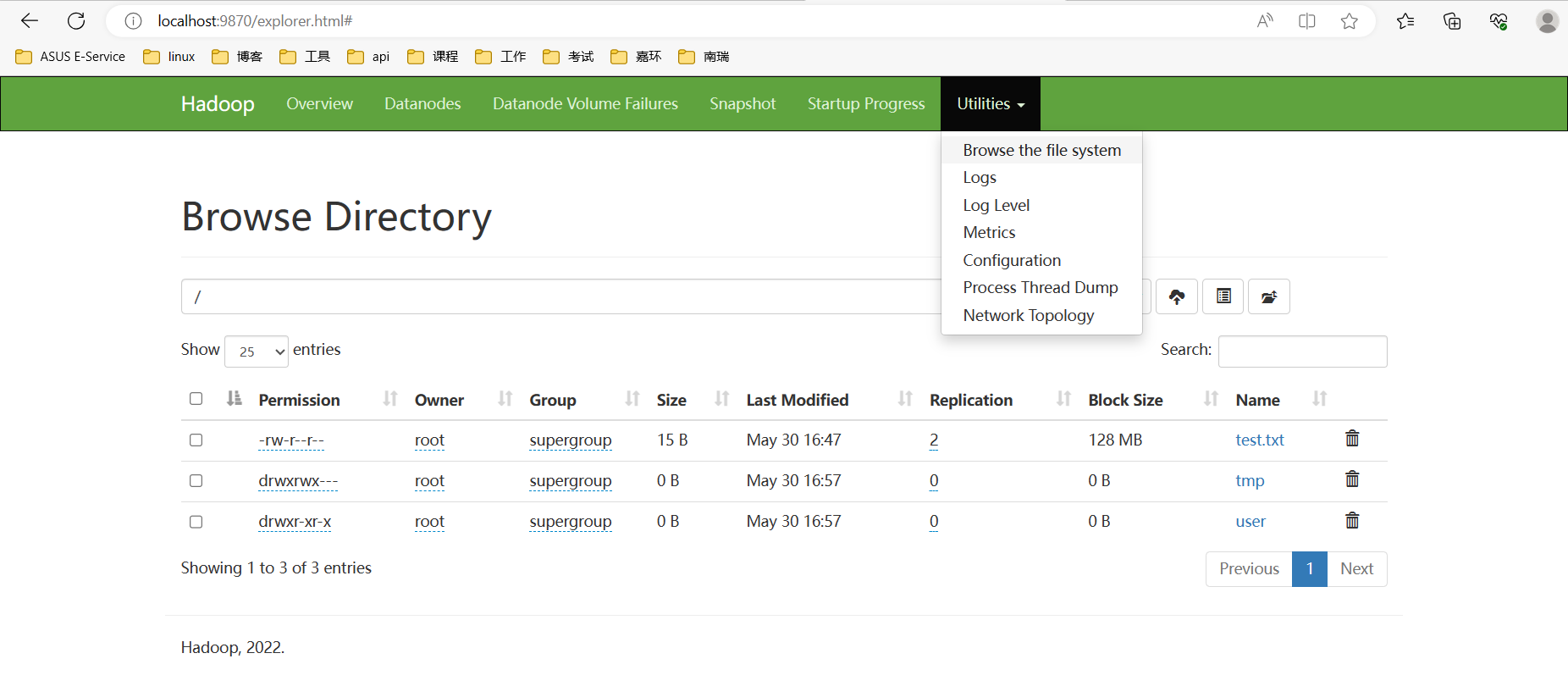
mapreduce服务测试:
切换到hadoop计算样例目录:
cd $HADOOP_HOME/share/hadoop/mapreduce
运行测试样例,调用jar包计算pi的值,计算100次:
hadoop jar hadoop-mapreduce-examples-3.3.2.jar pi 3 100
可以通过浏览器页面localhost:8088查看任务情况和日志等。
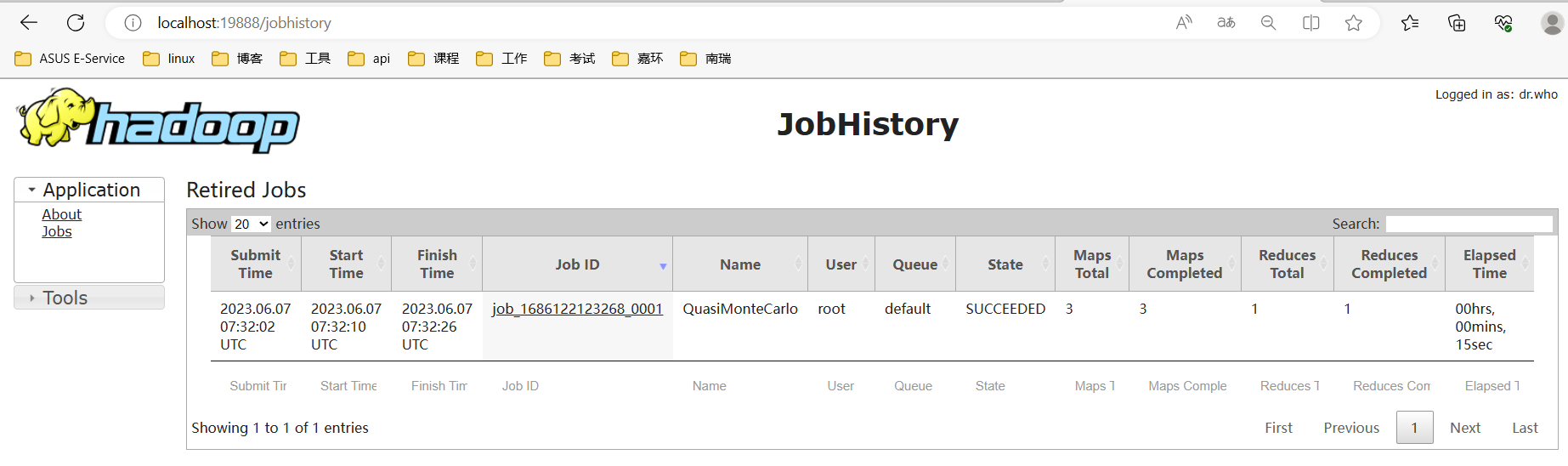
运行完的任务可以到浏览器页面localhost:19888查看,如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号