

Python刷题-7654321py9大题库
1.封版战斗札记项目从早期不断迭代2.Linux核心命令3-1系列文章目录3.Linux核心命令3-2Linux系统信息网络磁盘用户4.linux的基础结构和常用的命令基本 Linux 命令的列表:Linux命令行tar/zip/7z对文件分卷压缩/解压缩5.MySql记录的一些使用方法和经验MariaDB6.win10环境Windows环境下MYSQL5.7免安装版下载、配置(win10-x64位32g内存)7.java-echart报表插件使用笔记8.【MySQL必知必会】初探MySQL到使用9.ChatGPT API使用介绍 1.概述 随着人工智能技术的不断发展,越来越多的AI产品被应用到各个领域
10.Python刷题-7654321py9大题库
11.python练习题py8题库解析Python刷题-1
1、下列代码运行结果是?
a = map(lambda x: x**3, [1, 2, 3])
list(a)
[1, 8, 27]
2、Which numbers are printed?()
for i in range(2):
print i
for i in range(4,6):
print i
0, 1, 4, 5 答:range,左闭右开,range(2)输出的是0,1,range(4,6)表示在4和6之间左闭右开,是4,5
range()函数的语法如下:
range(start, end[, step])
参数说明:
start: 计数从 start 开始。默认是从 0 开始。例如 range(5) 等价于 range(0, 5);
end: 计数到 end 结束,但不包括 end。例如:range(0, 5) 等于 [0, 1, 2, 3, 4],没有5;
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
详情请参考:
http://www.runoob.com/python/python-func-range.html
因此上述代码实际将输出:
0
1
4
5
3、for i in range(2):
print i
for i in range(4,6):
print I
打印的结果是()
0, 1, 4, 5
4、下列哪种不是Python元组的定义方式?
(1)
(1, )
(1, 2)
(1, 2, (3, 4))
Python 中的 tuple 结构为 “不可变序列”,用小括号表示。为了区别数学中表示优先级的小括号,当 tuple 中只含一个元素时,需要在元素后加上逗号。
>>> print(type((1,)))
<class 'tuple'>
>>> print(type((1)))
<class 'int'>
5、What gets printed?()
print r"\nwoow"
the text like exactly like this: \nwoow 前导标识符 r 不会被输出,只起标记作用,r代表不被转义
Python 中字符串的前导 r 代表原始字符串标识符,该字符串中的特殊符号不会被转义,适用于正则表达式中繁杂的特殊符号表示。
最典型的例子,如要输出字符串 \n,由于反斜杠的转义,因此一般的输出语句为:
print "\\n"
这里的 \\ 将被转义为 \ 。而采用原始字符串输出时,则不会对字符串进行转义:
print r"\n"
因此本题答案为 C,输出 \nwoow 。注意前导标识符 r 不会被输出,只起标记作用。
6、以下声明错误的是:D
A、dic = {}
B、dic = {100:200}
C、dic = {(1,2,3):'test'}
D、dic = {[1,2,3]:'test'}
字典的键值必须是不可变类型,如数字,字符串,元组,而列表是可变类型。
可变(mutable)对象类型 :list、dict、set、bytearray、user-defined classes (unless specifically made immutable)
不可变(immutable)对象类型: int、float、decimal、complex、bool、str、tuple、range、frozenset、bytes
7、对于以下代码,描述正确的是:
list = ['1', '2', '3', '4', '5']
print list[10:]
A、导致 IndexError
B、输出['1', '2', '3', '4', '5']
C、编译错误
D、输出[]
切片操作不会引起下标越界异常
索引会报错,如list[10], list index out of range,而切片不会,只会给空列表如list[10:11]结果是空列表
8、下列程序运行结果为:
a=[1, 2, 3, 4, 5]
sums = sum(map(lambda x: x + 3, a[1::3]))
print(sums)
13
a=[1, 2, 3, 4, 5]
sums = sum(map(lambda x: x + 3, a[1::3]))
'''
a[1::3]意思是切片取值
a[1]=2,
: 代表取值到列表结尾,3为步长 ,取值结果为[2,5]
lambda 匿名函数 返回x+3,则为[5,8],再求合13
'''
print(sums)
a[1::3]的意思是,从下标1开始步长为3的元素,在这道题里也就是2、5;
两个冒号中间的数字代表从开始到小于该下标,留空则直到结尾,比如a[0:4:1]则是从下标0开始到下标4之间步长为1的元素。
这是Python里面的切片步长写法,它的原始形式应该是这样的:[start: end : step]
表示“从开始索引位置的那个值计算,经过多少步长到结束索引位置”,有时候end会被省略。
所以这里就表示从索引为1的(a=[1, 2, 3, 4, 5])数字,就是这里的2(因为索引都是从0开始计算)开始计算 三步,下一个就是5。
9、有如下类定义,下列描述错误的是? D
class A(object):
pass
class B(A):
pass
b = B()
A、isinstance(b, A) == True
B、isinstance(b, object) == True
C、issubclass(B, A) == True
D、issubclass(b, B) == True
abc isinstance(object,classinfo),用于判断object是否是classinfo的一个实例,或者object是否是classinfo类的子类的一个实例,如果是返回True. issubclass(class,classinfo),用于判断class是否是classinfo类的子类,如果是返回True.
新式类:class 类(object基类)
继承类:class 子类(父类1[,父类2,父类3])#在继承元组中列了一个以上的类,那么它就被称作"多重继承"
class A(object):#新式类,相当于A继承object基类
pass
class B(A):#B类继承A类
pass
b = B()#实例化
10、已知print_func.py的代码如下:
print('Hello World!')
print('__name__ value: ', __name__)
def main():
print('This message is from main function')
if __name__ == '__main__':
main()
print_module.py的代码如下:
import print_func
print("Done!")
运行print_module.py程序,结果是:
Hello World!
__name__ value: print_func
Done!
如果是直接执行print_func文件,则__name__的值为__main__;
如果是以导入模块的形式执行print_func文件,则__name__的值为该文件名print_func。
__name__的目的就是如果是以导入模块的形式执行文件,不会执行if __name__ == '__main__'下面的语句。
Python刷题-2
1、下面哪个是Python中的不变的数据结构? tuple
A、set
B、list
C、tuple
D、dict
#可变数据类型:列表list[ ]、字典dict{ }
#数据发生改变,但内存地址不变
#不可变数据类型:整型int、字符串str' '、元组tuple()
#当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也会改变;
2、以下程序输出为: 11 22 (33, 44, 55, 66, 77, 88, 99)
def test(a,b,*args):
print(a)
print(b)
print(args)
test(11,22,33,44,55,66,77,88,99)
# 11给a, 22给b,剩下的包装成元组给了不定长参数 *args
# python参数传递里的不定长参数:加了*的参数以元组方式传入,加了**的参数会以字典方式传入
4、下列哪个语句在Python中是非法的?
A、 x = y = z = 1
B、 x = (y = z + 1)
C、 x, y = y, x
D、 x += y
# y = z + 1 的结果没有返回值,就无法赋值到 x
5、下面代码运行后,a、b、c、d四个变量的值,描述错误的是? ( D )
import copy
a = [1, 2, 3, 4, ['a', 'b']]
b = a
c = copy.copy(a)
d = copy.deepcopy(a)
a.append(5)
a[4].append('c')
A、 a == [1,2, 3, 4, ['a', 'b', 'c'], 5]
B、 b == [1,2, 3, 4, ['a', 'b', 'c'], 5]
C、 c == [1,2, 3, 4, ['a', 'b', 'c']]
D、 d == [1,2, 3, 4, ['a', 'b', ‘c’]]
import copy
a = [1, 2, 3, 4, ['a', 'b']]
b = a # 引用,除非直接给a重新赋值,否则a变则b变,b变则a变
c = copy.copy(a) # 浅复制,只会拷贝父对象, 不会拷贝父对象中的子对象,所以若a的子对象变则c 变,但是父对象变c不会变
d = copy.deepcopy(a) #深拷贝,完全拷贝,完全独立于原对象,a变也不变
a.append(5) # 改变父对象
a[4].append('c') #改变父对象中的 ['a', 'b']子对象
# a=[1, 2, 3, 4, ['a', 'b','c'],5]
b=[1, 2, 3, 4, ['a', 'b','c'],5]
c=[1, 2, 3, 4, ['a', 'b','c']]
d=[1, 2, 3, 4, ['a', 'b']]
6、以下程序输出为:
正在装饰
正在验证权限
def w1():
print('正在装饰')
def inner():
print('正在验证权限')
return inner()
w1()
# 因为return inner()后面有括号所以会执行函数,如果改为
def w1():
print("正在装饰")
def inner():
print("正在验证权限")
return inner
w1()
# 最后一行的括号去掉,那么结果就是“正在装饰”
如果外层函数返回的是一个函数名的话,运行结果应该是:正在装饰
如果外层函数返回的是函数调用的话,运行结果是:正在装饰 正在验证权限
7、假设可以不考虑计算机运行资源(如内存)的限制,以下 python3 代码的预期运行结果是:(B)
import math
def sieve(size):
sieve= [True] * size
sieve[0] = False
sieve[1] = False
for i in range(2, int(math.sqrt(size)) + 1):
k= i * 2
while k < size:
sieve[k] = False
k += i
return sum(1 for x in sieve if x)
print(sieve(10000000000))
A、455052510
B、455052511
C、455052512
D、455052513
这是一个求质数个数的题不说了,简单做一个递归的优化,每次都用质数筛
#这个地方以100举例
import math
def sieve(size):
sieve= [True] * size
sieve[0] = False
sieve[1] = False # 这100个数除了0和1其余默认为True
for i in range(2, int(math.sqrt(size)) + 1): # 从2开始一直到10
k= i * 2
while k < size:
sieve[k] = False
k += i # 4为首项,公差为2的数为False;6为首项公差为3的数,以此类推,直到20为首项公差为10的数
# 对sieve中每个元素进行遍历,如果x为真,则计算器加1
return sum(1 for x in sieve if x) # 统计True的个数
print(sieve(100))
8、what gets printed? Assuming python version 2.x( A )
print type(1/2)
A、 <type 'int'>
B、 <type 'number'>
C、 <type 'float'>
D、<type 'double'>
E、<type 'tuple'>
# Python2 中除法默认向下取整,因此 1/2 = 0,为整型。
# 而 Python3 中的除法为正常除法,会保留小数位,因此 1/2 = 0.5,为浮点型。
9、从运行层面上来看,从四个选项选出不同的一个。python
JAVA
Python
objectC
C#
Python 只有它是动态语言
动态语言的定义:动态编程语言 是 高级程序设计语言 的一个类别,在计算机科学领域已被广泛应用。它是一类 在 运行时可以改变其结构的语言 :例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。动态语言目前非常具有活力。众所周知的 ECMAScript ( JavaScript )便是一个动态语言,除此之外如 PHP 、 Ruby 、 Python 等也都属于动态语言,而 C 、 C++ 等语言则不属于动态语言
10、关于return说法正确的是( B D )
A、python函数中必须有return
B、return可以返回多个值
C、return没有返回值时,函数自动返回Null
D、执行到return时,程序将停止函数内return后面的语句
# return会跳出函数(遇到它,函数就结束)
# break会跳出当前循环
# continue 跳出当前循环并执行下一次
# C. return没有返回值时,函数自动返回None,Python没有Null
Python刷题-3
1、关于Python中的复数,下列说法错误的是(C)
A、表是复数的语法是real + image j
B、实部和虚部都是浮点数
C、虚部必须后缀j,且必须小写
D、方法conjugate返回复数的共轭复数
分析:
A,Python中复数表达形式:real + image j/J;
B,Python实部和虚部均浮点类型;
C,虚部后缀为j或J;
D,方法conjugate返回复数的共轭复数,如1+2j调用此方法后变为1-2j;
2、What gets printed?( 4 )
nums=([1,1,2,3,3,3,4])
print(len(nums))
set 类型的特性是会移除集合中重复的元素,因此变量 nums 实际上等于:set中的数据不能重复,会自动去除重复的值
nums = {1, 2, 3, 4}
3、以下程序输出为:None 18
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'北京'}
age = info.get('age')
print(age)
age=info.get('age',18)
print(age)
dict.get(key, value=None)
当value的值存在时返回其本身,当key的值不存在时返回None(即默认参数)。
5、已知a = [1, 2, 3]和b = [1, 2, 4],那么id(a[1])==id(b[1])的执行结果 ( TRUE )
print(id(a[1]) ==id (b[1])) True
print((a[1]) is (b[1])) True
1、is 比较两个对象的 id 值是否相等,是否指向同一个内存地址;
2、== 比较的是两个对象的内容是否相等,值是否相等
在python3.6中对于小整数对象有一个小整数对象池,范围不止在[-5,257)之间。我试了百万以上的数地址都是相同的。
id(object)是python的一个函数用于返回object的内存地址。但值得注意的是,python 为了提高内存利用效率会对一些简单的对象(如数值较小的int型对象,字符串等)采用重用对象内存的办法。
6、以上函数输出结果为: 一个 shape = (10,5) 的 one-hot 矩阵
import numpy as np
a = np.repeat(np.arange(5).reshape([1,-1]),10,axis = 0)+10.0
b = np.random.randint(5, size= a.shape)
c = np.argmin(a*b, axis=1)
b = np.zeros(a.shape)
b[np.arange(b.shape[0]), c] = 1
print b
>>> a = np.repeat(np.arange(5).reshape([1,-1]),10)
>>> a
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4])
>>> a = np.repeat(np.arange(5).reshape([1,-1]),10,axis=0)
>>> a
array([[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]])
a = np.repeat(np.arange(5).reshape([1,-1]),10,axis = 0)+10.0
>>> a
array([[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.],
[ 10., 11., 12., 13., 14.]])
#生成数组[0,1,2,3,4]
np.arange(5)
#原数组共有x个元素,reshape([n,-1])意思是将原数组重组为n行x/n列的新数组
#所以数组共有5个元素,重组为1行5列的数组
reshape([1,-1])
#因为axis=0,所以是沿着竖轴方向重复,增加列数(行的方向上(axis=1),在列的方向上(axis=0))
#所以原数组增加10行
repeat(np.arange(5).reshape([1,-1]), 10, axis = 0)
#数组每个元素都+10
a = repeat(np.arange(5).reshape([1,-1]), 10, axis = 0) + 10
>>> b = np.random.randint(5, size= a.shape) # 随机生成大小为a.shape的数组,数组元素为[0,5)区间范围的整数。
>>> b
array([[0, 4, 3, 0, 2],
[0, 0, 3, 3, 3],
[3, 1, 4, 3, 1],
[3, 2, 3, 0, 2],
[3, 4, 4, 0, 3],
[0, 3, 2, 4, 3],
[0, 4, 1, 0, 1],
[4, 4, 4, 0, 4],
[1, 2, 2, 2, 2],
[2, 0, 1, 0, 4]])
>>> c = np.argmin(a*b, axis=1) # 随机生成大小为a.shape的数组,数组元素为[0,5)区间范围的整数。
>>> c
array([0, 0, 1, 3, 3, 0, 0, 3, 0, 1], dtype=int64)
>>> b = np.zeros(a.shape) # 生成a.shape大小的全零数组
>>> b
array([[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.]])
>>> b[np.arange(b.shape[0]), c] = 1
>>> b
array([[ 1., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.],
[ 0., 0., 0., 1., 0.],
[ 0., 0., 0., 1., 0.],
[ 1., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 0.],
[ 0., 0., 0., 1., 0.],
[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.]])
b.shape[0]表示b的列数,10列
b[np.arange(10), c]=1表示np.arange(10)生成的数组中,所有c对应的位置全置为1。
7、python代码如下:
foo = [1,2]
foo1 = foo
foo.append(3)
答案:
foo 值为[1,2,3]
foo1 值为[1,2,3]
8、__new__和__init__的区别,说法正确的是?
答案:
__new__是一个静态方法,而__init__是一个实例方法
__new__方法会返回一个创建的实例,而__init__什么都不返回
只有在__new__返回一个cls的实例时,后面的__init__才能被调用
当创建一个新实例时调用__new__,初始化一个实例时用__init__
9、解释型语言的特性有什么?
答案:
非独立
效率低
非独立:JavaScript语言依赖执行环境,对于客户端来说是浏览器,对于服务端来说是node。
效率低:执行前不需要编译,执行时才编译,因此效率低。
10、下面的程序根据用户输入的三个边长a,b,c来计算三角形面积.请指出程序中的错误:(设用户输入合法,面积公式无误) (BC)
import math
a, b, c = raw_input(“Enter a,b,c: ”)
s = a + b + c
s = s / 2.0
area = sqrt(s*(s-a)*(s-b)*(s-c))
print “The area is:”, area
A、1
B、2
C、5
D、6
2错是因为too many values to unpack,这个错误。Python2可以改为a, b, c = raw_input(), raw_input(),这样不会有语法错误,但是a, b, c都还是字符串,用type()命令可以知道,之后可能还要int()回来,所以要么使用eval(raw_input()),要么就是用Python3。5错,应该是math.sqrt,或者上面1直接用from math import sqrt。
`raw_input`获取的都是str类型, 那么第4行`str/float` 也是错误。
Python刷题-4
Python刷题-4
1、Python不支持的数据类型有( A )
A、char
B、int
C、float
D、list
注意:
string 不是 char!!!!
可变数据类型:列表list[ ]、字典dict{ }
不可变数据类型:整型int、字符串str' '、元组tuple()
2、下列程序打印结果为: [1, 2, 3, 4, 5, 5, 7]
nl = [1,2,5,3,5]
nl.append(4) #在列表的末尾插入4,[1,2,5,3,5,4]
nl.insert(0,7) #在列表0索引处插入7,[7,1,2,5,3,5,4]
nl.sort() #对列表升序排列,[1,2,3,4,5,5,7]
print nl
append()方法是指在列表末尾增加一个数据项。
extend()方法是指在列表末尾增加一个数据集合。
insert()方法是指在某个特定位置前面增加一个数据项。
nl=[1,2,5,3,5];
nl.append(4)得nl=[1,2,5,3,5,4];
nl.insert(0,7)得nl=[7,1,2,5,3,5,4];
nl.sort()输出[1,2,3,4,5,5,7]
3、以下代码输出为: 10
list1 = {'1':1,'2':2}
list2 = list1
list1['1'] = 5
sum = list1['1'] + list2['1']
print(sum)
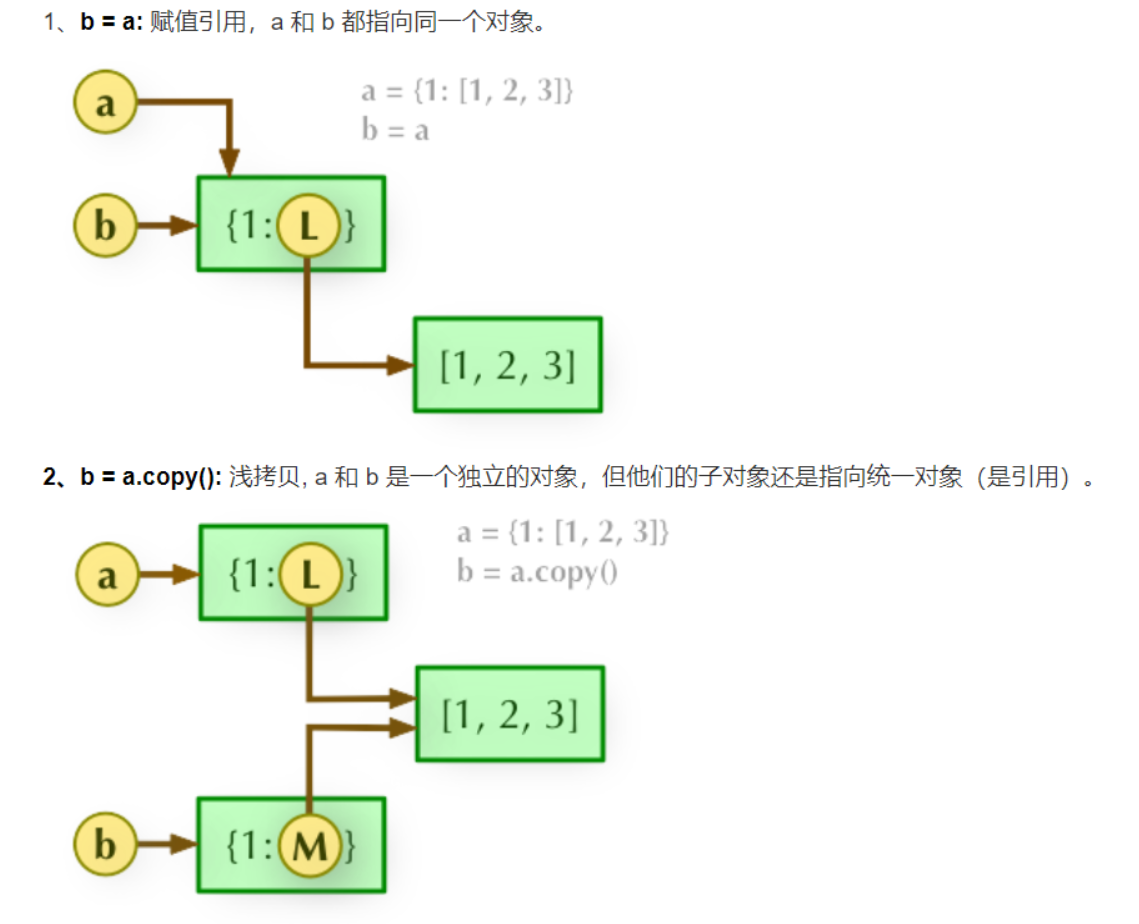
b = a: 赋值引用,a 和 b 都指向同一个对象。
list1 和 list2 指向的是同一块内存空间
list1['1']=5 ------> 改变了这一块内存空间中'1'的value值
执行这一步后内存空间存储的数据变为:{'1': 5, '2': 2}
因此 sum = list1['1']+list2['1']=5+5=10
4、Python调用read()函数可实现对文件内容的读取
read()读整个文件;readline()读一行;readlines()读所有行到list
1.read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象。 2.readline()方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
3.readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。
5、下面的python3函数,如果输入的参数n非常大,函数的返回值会趋近于以下哪一个值(选项中的值用Python表达式来表示)()
import random
def foo(n):
random.seed()
c1 = 0
c2 = 0
for i in range(n):
x = random.random()
y = random.random()
r1 = x * x + y * y
r2 = (1 - x) * (1 - x) + (1 - y) * (1 - y)
if r1 <= 1 and r2 <= 1:
c1 += 1
else:
c2 += 1
return c1 / c2
A、 4 / 3
B、 (math.pi - 2) / (4 - math.pi)
C、math.e ** (6 / 21)
D、math.tan(53 / 180 * math.pi)
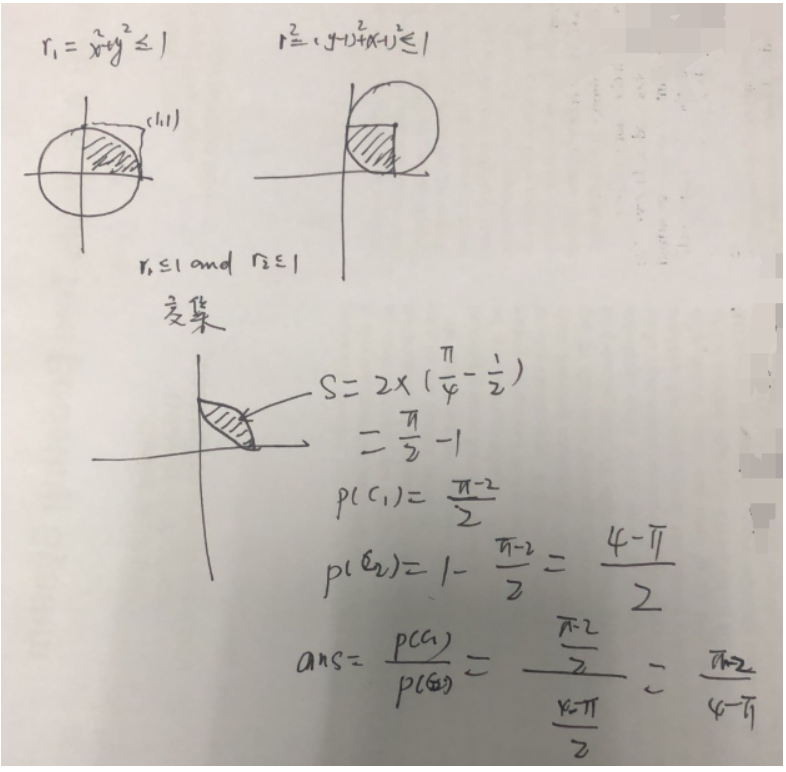
7、下列代码运行结果是?( C )
a = 'a'
print a > 'b' or 'c'
A、a
B、b
C、c
D、True
E、False
由于比较运算符优先级大于逻辑运算符,根据上表,当 a > 'b',即 'a' > 'b' 为 Fasle 时('a' 的 ASCII 码比 ‘b’ 小),返回值为 'c',故答案选C。

9、下列程序打印结果为( B )
import re
str1 = "Python's features"
str2 = re.match( r'(.*)on(.*?) .*', str1, re.M|re.I)
print str2.group(1)
A、Python
B、Pyth
C、thon’s
D、Python‘s features
多个标志可以通过按位 OR(|) 来指定
re.M:多行匹配,影响 ^ 和 $
re.I:使匹配对大小写不敏感
分组:即用圆括号将要提取的数据包住,通过 .group()获取,一般和“|”结合使用
re.match( r'(.*)on(.*?) .*', str1, re.M|re.I),将on左边和右边分组
>>print(str2.group(0))
Python's features
>>print(str2.group(1))
Pyth
>>print(str2.group(2))
's
str1 = "Python's features"
r'(.*)on(.*?) .*'
有几个()就有几个group
group(0) = group() = Python's features
第一个()=group(1)
第二个()=group(2)
.*适配所有
?到后面的空格为止
.匹配单个任意字符
*匹配前一个字符出现0次或无限次
?匹配前一个字符出现0次或1次
(.*)提取的数据为str1字符串中on左边的所有字符,即Pyth
(.*?)提取的数据为str1中on右边,空格前面,即's
分类: 刷题
Python刷题-5
1、当一个嵌套函数在其外部区域引用了一个值时,该嵌套函数就是一个闭包,以下代码输出值为:16
def adder(x):
def wrapper(y): # 第二步
return (x + y) # 第五步
return (wrapper) # 第三步
# adder5是对wrapper的引用 此时x等于5
adder5 = adder(5) #返回了 wrapper ,且x=5; 第一步
print(adder5(adder5(6))) # 第四步
闭包:如果一个函数内部又定义了一个函数,就把外部的函数称为外函数,内部的函数称为内函数。如果内函数引用了外函数的变量,而外函数返回内函数(引用),就把这种形式称之为 闭包。并且当外函数结束时会将变量绑定给内函数。
adder(5) = wrapper(x=5, y)
adder5 = wrapper(x=5, y)
adder5(6) = wrapper(x=5, 6) = 5 + 6 = 11
adder5(adder5(6)) = adder(11) = wrapper (x =5, 11) = 5 + 11 = 16
# 外部函数确定了x的值为5,内部函数的值为6,所以第一次计算结果为11,第二次计算,还是在x为5的前提下,需要在11的基础上再加5
那什么是闭包呢,一言以蔽之:一个持有外部环境变量的函数就是闭包。
因为wrapper是闭包 所以adder5返回的是wrapper函数 接下来adder5(6) 返回的是11=5+6 同理 再调用一次就是16 = 11+5
2、如下程序会打印多少个数:
# python2:9个
# python3:10个
k = 1000
sum = 0
while k > 1:
sum += 1
print(k)
k = k/2
print(sum)
python2 整数除法/时,会取整的,所以应该是9个。
python3 除法/,结果是浮点的,所以是10个
# 1000
# 500.0
# 250.0
# 125.0
# 62.5
# 31.25
# 15.625
# 7.8125
# 3.90625
# 1.953125
# 10
# 代码运行应该是10个,python是不会自动取整的
3、What gets printed? 6
kvps = { '1' : 1, '2' : 2 }
theCopy = kvps.copy()
kvps['1'] = 5
sum = kvps['1'] + theCopy['1']
print sum
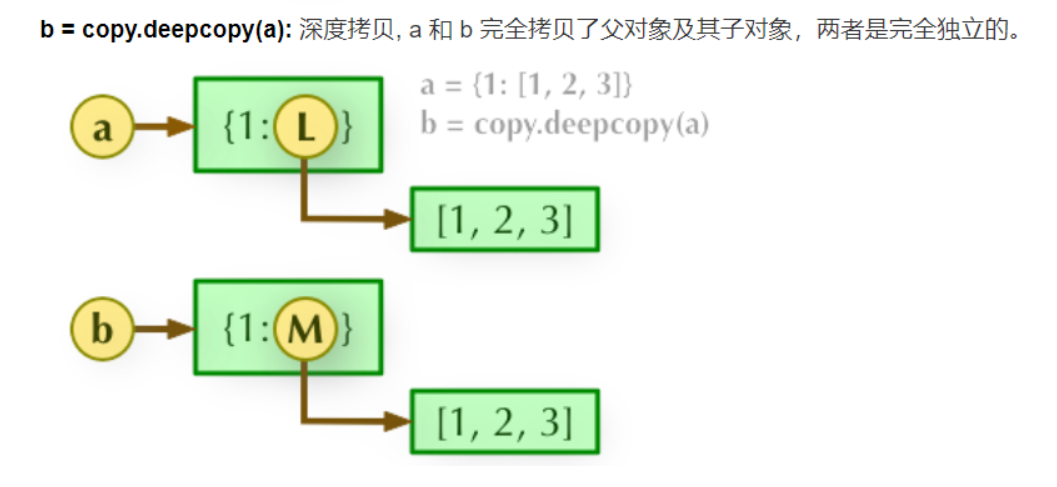
# object.copy()和copy.copy(object)一样是浅拷贝,深拷贝只有copy.deepcopy(object)
# 在 Python2 和 Python3 中,copy() 方法的意义相同,均为返回一个浅复制的 dict 对象,而浅复制是指只拷贝父对象,不会拷贝对象的内部的子对象,即两个 dict 父对象 kvps 与 theCopy 相互独立,但对它们内部子对象的引用却是共享的,所以 kvps['1'] 的改变不影响 theCopy['1'] 的值(因为改变的是父对象的值)。
顺便一提,深复制是指完全拷贝父对象与子对象,即都相互独立。
注意,这里的子对象不是子类的对象,而是在父对象中的二级对象。
4、What gets printed? 4
counter = 1
def doLotsOfStuff():
global counter
for i in (1, 2, 3):
counter += 1
doLotsOfStuff()
print(counter)
# 当内部作用域想修改外部变量时,需要使用global声明。
# 考察 global 的意义,即在局部作用域 doLotsOfStuff() 函数中,声明对全局作用域中的 counter 变量的引用。
在变量前加global代表修改的是全局变量, 原counter=1,三次循环+1故=4, 函数执行完,全局变量被修改=4
5、有如下函数定义,执行结果正确的是? foo(3)=18;foo(2)=12
def dec(f):
n = 3
def wrapper(*args,**kw):
return f(*args,**kw) * n
return wrapper
@dec # 先执行dec,将 @dec 下面的 函数 作为dec()的参数
def foo(n):
return n * 2
foo(2)
解析:
装饰器(Decorator)本身是一个函数,目的是在不改变待装饰函数代码的情况下,增加额外的功能,装饰器的返回值是已装饰的函数对象。
以foo(2)语句为例,上述代码等价于:
def dec(f):
n = 3
def wrapper(*args,**kw):
return f(*args,**kw) * n
return wrapper
def foo(n):
return n * 2
foo=dec(foo)
foo(2)
由此可见,@dec的作用是把原foo函数(待装饰函数)赋值给dec函数(装饰器),然后将返回值wrapper函数(已装饰函数)重新赋值给foo函数。因此,foo(2)语句实际执行情况是:
def wrapper (2):
return foo(2) * 3
注:以上代码是为了方便理解,直接将实参n=2代入函数定义中,语法上并无实际意义。
显然,用数学符号表示的话,函数执行结果为foo(2)= wrapper(2)= foo(2)*3= 2*2*3=12,其中前面的foo函数是已装饰函数,后面的foo函数是原来的待装饰函数。By the way,函数参数中的*args代表可变参数,**kw代表关键字参数。
@dec 装饰器,先执行dec(), 并将 @dec 下面的 函数 作为dec()的参数。 (装饰器的作用:为已经存在的对象添加额外的功能)
foo(n) = n * 2 * 3
foo(2) == (2*2)*3 == 12
foo(3) == (3*2)*3 == 18
6、下列Python语句正确的是:D
A、min = x if x < y = y
B、max = x > y ? x : y
C、if (x > y) print x
D、while True : pass
A、三元运算符的使用。基本语法为:a if condition else b
上述语句当 condition 为真时等于 a,为假时等于 b。因此 A 选项改为下列语句则正确:min = x if x<y else y
B、还是三元运算符的使用,只不过 B 选项的用法在 C、Java 等语言中成立,在 Python 中没有此用法,正确用法参见选项 A。
C、if 语句缺少冒号,并且正确用法如下:if (x>y): print x
D、while 语句与 pass 语句的使用。pass语句为空语句,意义只是为了保持程序结构的完整性。该选项写法正确,故选 D。
7、下列表达式的值为True的是:C
A、5+4j > 2-3j
B、3>2>2
C、(3,2)< ('a','b')
D、’abc’ > ‘xyz’
选项 A:Python2 与 Python3 均不支持复数比较大小;
ASCII码中小写字母>大写字母>数字
字母:
A-Z:65-90
a-z:97-122
1、复数是不可以比较大小的。
2、元组是可以比较大小的。tuple 的比较是从两者的第一个元素的 ASCII 码开始,直至两个元素不相等为止,若前面元素都相等,则元素个数多的 tuple 较大。
3、字符串是可以比较大小的。字符串的比较是从两者的第一个字符的ASCII码开始,直至两个元素不相等为止,若前面字符都相等,则字符个数多的字符串较大。
字母与数字的ASCII 码大小范围是 "a-z" > "A-Z" > "0-9"
8、有一段python的编码程序如下:urllib.quote(line.decode("gbk").encode("utf-16")),请问经过该编码的字符串的解码顺序是(D)
A、gbk utf16 url解码
B、gbk url解码 utf16
C、url解码 gbk utf16
D、url解码 utf16 gbk
解析:
字符串编译的过程:gbk==>unicode==>utf16==>url解码
字符串解码顺序为:url解码==>utf16==>unicode==>gbk
9、Python中函数是对象,描述正确的是? (ABCD)
A、函数可以赋值给一个变量
B、函数可以作为元素添加到集合对象中
C、函数可以作为参数值传递给其它函数
D、函数可以当做函数的返回值
解析:在 Python 中万物皆为对象,函数也不例外,函数作为对象可以赋值给一个变量、可以作为元素添加到集合对象中、可作为参数值传递给其它函数,还可以当做函数的返回值,这些特性就是第一类对象所特有的。
10、Python中单下划线_foo与双下划线__foo与__foo__的成员,下列说法正确的是?(ABC)
A、_foo 不能直接用于’from module import *’
B、__foo解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名
C、__foo__代表python里特殊方法专用的标识
D、__foo 可以直接用于’from module import *’
_xxx 不能用’from module import *’导入 (相当于protected)
__xxx__ 系统定义名字 (系统内置的,比如关键字)
__xxx 类中的私有变量名 (privated),所以更加不能使用from module import进行导入了
链接:https://www.nowcoder.com/questionTerminal/1c4b55a530ee499c986efe82c173b645
来源:牛客网
python中主要存在四种命名方式:
1、object #公用方法
2、_object #半保护
#被看作是“protect”,意思是只有类对象和子类对象自己能访问到这些变量,
在模块或类外不可以使用,不能用’from module import *’导入。
#__object 是为了避免与子类的方法名称冲突, 对于该标识符描述的方法,父
类的方法不能轻易地被子类的方法覆盖,他们的名字实际上是
_classname__methodname。
3、_ _ object #全私有,全保护
#私有成员“private”,意思是只有类对象自己能访问,连子类对象也不能访
问到这个数据,不能用’from module import *’导入。
4、_ _ object_ _ #内建方法,用户不要这样定义
Python刷题-6
1、下面哪个不是Python合法的标识符?(B)
A、int32
B、40XL
C、self
D、name
python中的标识符:
1)第一个字符必须是字母表中字母或下划线 _ 。
2)标识符的其他的部分由字母、数字和下划线组成。
3)标识符对大小写敏感。
4)不可以是python中的关键字,如False、True、None、class等。
注意:self不是python中的关键字。类中参数self也可以用其他名称命名,但是为了规范和便于读者理解,推荐使用self。
2、执行下面代码,请问输出结果为( A )
name = "顺顺"
def f1():
print(name)
def f2():
name = "丰丰"
f1()
f1()
f2()
A、顺顺 顺顺
B、丰丰 丰丰
C、顺顺 丰丰
D、丰丰 顺顺
3、下述字符串格式化语法正确的是?
A、'GNU's Not %d %%' % 'UNIX'
B、'GNU\'s Not %d %%' % 'UNIX'
C、'GNU's Not %s %%' % 'UNIX'
D、'GNU\'s Not %s %%' % 'UNIX'
python里面%d表数字,%s表示字符串,%%表示一个%;
单引号内嵌套单引号需要转义字符\;单引号内嵌套双引号不需要转义字符;
双引号内嵌套双引号需要转义字符\;双引号内引用单引号不需要转义字符;
4、关于Python中的复数,下列说法错误的是:C
A、表示复数的语法是real + image j
B、实部和虚部都是浮点数
C、虚部必须后缀j,且必须是小写
D、方法conjugate返回复数的共轭复数
正确答案选 C。
选项 A:Python 中复数的表示方法;
选项 B:复数的实部与虚部均为浮点数;
选项 C:虚部的后缀可以是 “j” 或者 “J”;
选项 D:复数的 conjugate 方法可以返回该复数的共轭复数。
5、在python中,使用open方法打开文件,语法如下:
open(文件名,访问模式) 如果以二进制格式打开一个文件用于追加,则访问模式为:( C )
A、rb
B、wb
C、ab
D、a
指定对文件打开方式即文件内容操作方式
"r", 只读
"w", 可写
"a", 追加
"rb", 二进制读
"wb", 二进制写
"ab":,二进制追加
6、关于Python内存管理,下列说法错误的是 ( B )
A、变量不必事先声明
B、变量无须先创建和赋值而直接使用
C、变量无须指定类型
D、可以使用del释放资源
本题答案选 B,原因如下:
Python 是弱类型脚本语言,变量就是变量,没有特定类型,因此不需要声明。
但每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。在赋值的同时变量也就创建了
用 del 语句可以释放已创建的变量(已占用的资源)。
7、下面程序的功能是什么?( A )
def f(a, b):
if b == 0:
print(a)
else:
f(b, a%b)
a,b = input("Enter two natural numbers: ")
print(f(a, b))
A、求 AB最大公因数
B、求AB最小公约数
C、求A%B
D、求A/B
a % b 是求余数
辗转相除法,又称欧几里得算法,以除数和余数反复做除法运算,当余数为 0 时,取当前算式除数为最大公约数。
最小公倍数=两整数的乘积➗最大公约数
input()不能同时赋值两个字符串
8、以上程序要求用户输入二进制数字0/1并显示之,请指出程序中代码第几行存在错误:( AD )
1.bit = input("Enter a binary digit:")
2.if bit = 0 or 1:
3. print "your input is" ,bit
4.else
5. print "your input is invalid"
A、4
B、5
C、3
D、2
由 print 的格式可知此代码在 Python2.x 下执行,并且第 2 行与第 4 行有语法错误,正确的代码如下:
bit = input("Enter a binary digit:")
if bit == 0 or bit == 1:
print "your input is" ,bit
else:
print "your input is invalid"
注意第 2 行千万不能写成:
if bit == 0 or 1: #相当于 if (bit == 0) or 1:
因为以上条件语句不管 bit 为何值,都恒为真!
还有第 4 行的 else 后需要加上冒号。
9、若 a = range(100),以下哪些操作是合法的? (A B C D)
A、a[-3]
B、a[2:13]
C、a[::3]
D、a[2-3]
实际上是a[start:end:step]
根据a=range(100)可得start的默认值是0,end的默认值是99,step的默认值是1。
range(100)表示从0到99共一百个数
a[-3]和a[2-3]意味着倒数第三个数和倒数第一个数 分别是97 99
a[::3] start0 end99 step3 依次是0 3 6 9一直到99 步长为3
a[2:13]从a[2]到a[12] 不包括13,前闭后开
10、若 a = (1, 2, 3),下列哪些操作是合法的? (A B D) 元组:左闭右开
A、a[1:-1]
B、a*3
C、a[2] = 4
D、list(a)
如果a[-1] = (3), tuple 是一个不可改变的list,所以[1:-1],就是从1开始取,取不到-1,就是从第二个取值,取到倒数第二个
a[1:-1] ---->(2,) 元组必须带逗号,不带逗号会被误认为为int类型而不是元组
a*3---->(1,2,3,1,2,3,1,2,3) a本身没变,a*3是一个新的元组,已经不是a了
a是元组不可改变
list(a)----->[1,2,3]数组和列表可以相互转换
Python刷题-7
1、下面哪个是Python中的不变的数据结构? (C)
A、set
B、list
C、tuple
D、dict
2、下列代码输出为: 6
str1 = "Hello,Python";
str2 = "Python";
print(str1.index(str2));
index()方法语法:
str.index(str, beg=0, end=len(string))
参数
str -- 指定检索的字符串
beg -- 开始索引,默认为0。
end -- 结束索引,默认为字符串的长度。
从Hello开始数到p截止,从下标0开始数
str2指向字符串Python的起始位置,即P所在的位置。
str1.index(str2)即返回str1中str2指向的P位置的下标。
str1是一个字符串,下标从0开始数起,数到P就是6,注意逗号在字符串内也占一个位置。
详解:str1.index(str2)找到str2的起始字符,对应str1中哪个位置,从0开始数,这就是索引
3、以下哪个代码是正确的读取一个文件? (C)
A、f = open("test.txt", "read")
B、f = open("r","test.txt")
C、f = open("test.txt", "r")
D、f = open("read","test.txt")
Python中,打开文件语法为:
text = oepn(filePath, 操作方式,编码方式)
常见操作方式
'r':读
'w':写
'a':追加
常见编码方式
utf-8
gbk
4、下列哪种类型是Python的映射类型?(D)
A、str
B、list
C、tuple
D、dict
映射是一种关联式的容器类型,它存储了对象与对象之间的映射关系,字典是python里唯一的映射类型,它存储了键值对的关联,是由键到键值的映射关系。
5、如下程序的运行结果为:
def func(s,i,j):
if i<j:
func(s,i+1,j-1)
s[i],s[j] =s[j],s[i]
def main():
a = [10,6,23,-90,0,3]
func(a,0,len(a)-1)
for i in range(6):
print(a[i])
print('\n')
main()
答案:这是一道递归的题目
3
0
-90
23
6
10
1.首先,调用main() 函数内,已经定义了一个列表 a ,传入到func函数内,第一次传入的参数中 i,j 分别代表列表的首位、末尾值。即
i = 0 ,j = 5 此时满足 i<j ,则此时调用 满足的条件 ,又调用func ,此时传入的参数为 a、1,4 。这时需要执行函数,而不能往下执行,即暂不可执行第一次的 交换元素 s[0],s[5] = s[5],s[0].
- 执行内部函数 func(a,1,4) 则也满足 1<4 此时还需要再调用 func(a,2,3) .暂不执行 s[1],s[4]] = s[4],s[1].
3.再执行内部函数 func(a,2,3) ,还是满足2<3 此时还需要再调用 func(a,3,2) .暂不执行 s[2],s[3]] = s[3],s[2].
4.再执行内部函数func(a,3,2),此时不满足 3<2 . 即不执行任何内容。此时内部循环函数全部结束。再往上推。
5.上一步内部函数执行完后,则执行交换s[2],s[3]] = s[3],s[2]. 再往上推
-
s[1],s[4]] = s[4],s[1],再往上推
-
s[0],s[5] = s[5],s[0] 。即全部func结果结束。即交换了各个位置的元素。第一个变成最后一个、第二个变成倒数第二个、第三个变成倒数第三个。原来 的 a = [10,6,23,-90,0,3]
交换后的 a = [3,0,-90,23,6,10]
- for循环依次打印出a列表元素 ,每次打出一个都进行换行操作。
6、下面程序运行结果为:
for i in range(5):
i+=1
print("-------")
if i==3:
continue
print(i)
-------
1
-------
2
-------
-------
4
-------
5
考察 continue 跳出本句的循环,但循环仍在继续。故 i = 3 时不进行打印
7、下列代码输出为:TRUE
str = "Hello,Python"
suffix = "Python"
print (str.endswith(suffix,2))
str.endswith(suffix,2) 中的2是指:从字符串"Hello,Python" 中的位置2,也就是第一个‘l’开始检索,判断是否以suffix结尾,故本题输出 True 。
8、下列关于python socket操作叙述正确的是( CD )
A、使用recvfrom()接收TCP数据
B、使用getsockname()获取连接套接字的远程地址
C、使用connect()初始化TCP服务器连接
D、服务端使用listen()开始TCP监听
使用recvfrom()接收TCP数据(错误) socket.recv是tcp协议,recvfrom是udp传输 返回值是(data,address)
其中data是包含接收数据的字符串,address是 发送数据 的套接字地址。
使用getsockname()获取连接套接字的远程地址(错误) 返回套接字自己的地址
通常是一个元组(ipaddr,port)
使用connect()初始化TCP服务器连接 连接到address处的套接字。
一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
服务端使用listen()开始TCP监听
9、下列程序打印结果为: [1, 2, 3, 4, 5, 5, 7]
nl = [1,2,5,3,5]
nl.append(4)
nl.insert(0,7)
nl.sort()
print nl
append()方法是指在列表末尾增加一个数据项。
extend()方法是指在列表末尾增加一个数据集合。
insert()方法是指在某个特定位置前面增加一个数据项。
nl=[1,2,5,3,5];nl.append(4)得nl=[1,2,5,3,5,4];
nl.insert(0,7)得nl=[7,1,2,5,3,5,4];
nl.sort()输出[1,2,3,4,5,5,7] # sort 列表排序默认升序


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2020-04-28 pyecharts模块
2020-04-28 python 各种加密加密学习
2020-04-28 python并发编程之多线程