大屏26深度学习模型来从文档图片中自动化地提取出关键信息成为一项亟待解决的挑战
大屏26深度学习模型来从文档图片中自动化地提取出关键信息成为一项亟待解决的挑战
深度学习模型来从文档图片中自动化地提取出关键信息成为一项亟待解决的挑战,受到学术界和工业界的广泛关注。
深度学习模型已经在OCR领域,包括文本检测和文本识别任务,获得了巨大的成功。而从文档中提取关键信息(如图1所示),其作为OCR的下游任务,存在非常多的实际应用场景。使用人力来从这些文档中提取信息是重复且费时费力的。如何通过深度学习模型来从文档图片中自动化地提取出关键信息成为一项亟待解决的挑战,受到学术界和工业界的广泛关注。下面将对近期几篇相关文章进行简要介绍,并将其分为三个类别:基于栅格(grid-based)、基于图结构(graph-based)和端到端(end-to-end)。

(a)火车票

(b)购物收据
图1 从文档图片中提取关键信息
1. 基于栅格的文档图片关键信息提取技术
该类方法基于图片像素点将图片转换为栅格表示向量,输入到深度学习网络中以学习提取关键信息。
1.1 Chargrid[1]
这篇文章指出文档中的文本间关系不仅受文本的序列顺序影响,还与文档中各文本的版式分布有关。为解决上述问题,作者提出chargrid方法,其将文档图片映射为一个字符级别的2D栅格表示,如图2所示。对于每一个字符栅格采用one-hot编码表示,整个图片的向量表示为\tilde{g} \in \mathbb{R}^{H×W×N_{c}}g~∈RH×W×Nc,其中HH和WW是图片的长和宽,N_{c}Nc是字符类别数。
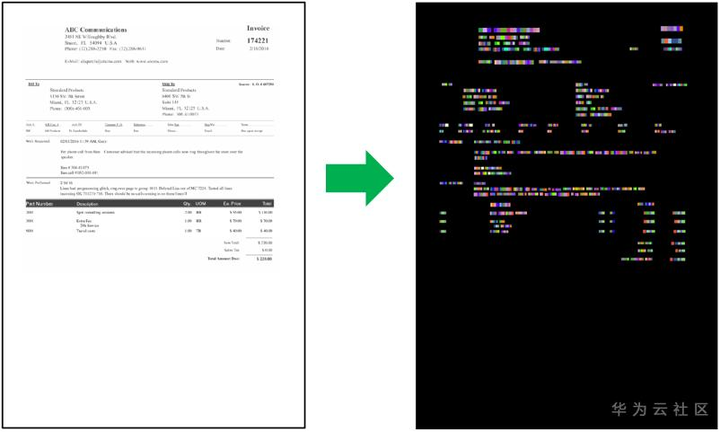
图2 chargrid的文档表示
随后该向量表示作为chargrid-net的输入,基于encoder-decoder的CNN网络结构(如图3所示)进行关键信息的文本框检测和语义分割。整个网络由分割损失、边框分类和边框坐标回归三个部分组成的损失函数优化学习:{\mathcal{L}}_{total}={\mathcal{L}}_{seg}+{\mathcal{L}}_{boxmask}+{\mathcal{L}}_{boxcoord}Ltotal=Lseg+Lboxmask+Lboxcoord。关键信息内容通过将分割类别属于同一类别的字符整合得到。
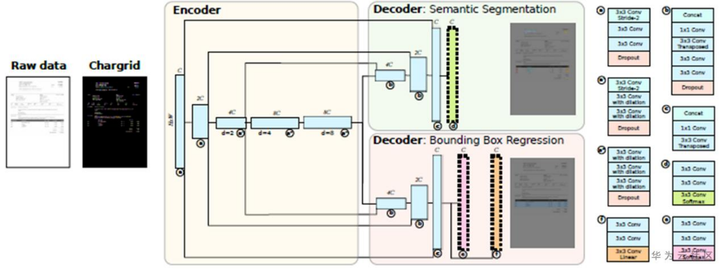
图3 chargrid模型架构
1.2 CUTIE[2]
这篇文章同样指出仅利用NLP技术是无法处理文档中各文本间的布局信息。因此作者设计了CUTIE方法,如图4所示,将文档图片映射为保留各文本空间位置关系的栅格向量表示,然后设计了两类CNN模型来进行关键信息题:CUTIE-A,采用高分辨率网络HRNet作为骨干网络;CUTIE-B,采用空洞卷积的CNN网络。整个模型由每个box的预测类别和真实类别间的交叉熵损失优化学习。
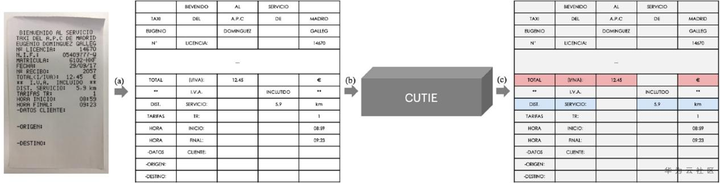
图4 CUTIE模型架构
2. 基于图结构的文档图片关键信息提取技术
基于图结构的方法是将文档图片看作是由文本切片(text segment)组成的图结构,并利用神经网络模型来学习出各文本切片间的关系来提取出文档的关键信息内容。
2.1 GC-BiLSTM-CRF[3]
这篇文章指出传统NER方法BiLSTM-CRF无法利用文档图片中各文本切片间的布局信息。为解决上述问题,作者提出利用图卷积神经网络来学习文本切片的语义信息和布局信息。
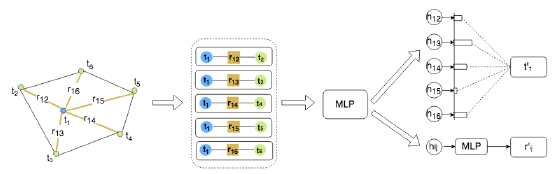
图5 图卷积神经网络学习文本切片的图向量表示
具体地,将文本切片看做点,将文本间关系看做边,来构造一个全连接图结构。利用图卷积神经网络来学习得到每个文本切片的图向量表示,如图5所示。
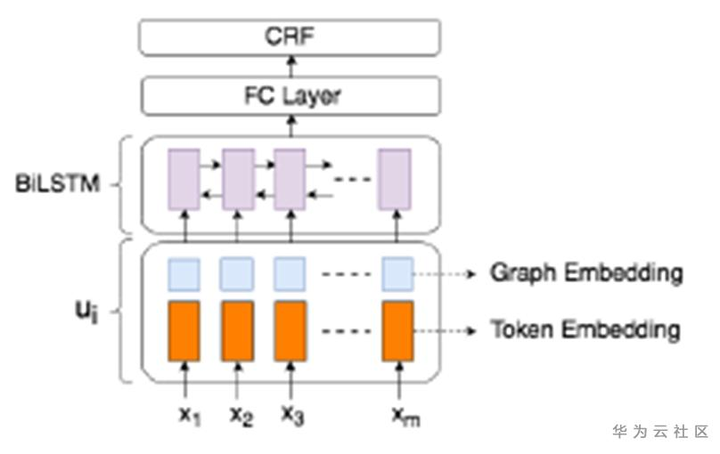
图6 引入图向量表示的BiLSTM-CRF
在得到文本切片的图向量表示后,将其与文本切片中每个文本token的Word2Vec向量拼接,输入到BiLSTM-CRF网络中进行文档图片的关键信息提取。整个模型由文本切片分类任务和IOB序列分类任务联合优化学习。
2.2 LayoutLM[4]
这篇文章指出预训练模型已经在NLP领域获得了巨大的成功,但是其缺乏对布局和版式信息的利用,从而不适用于文档图片关键信息提取任务。为解决上述问题,作者提出LayoutLM模型。
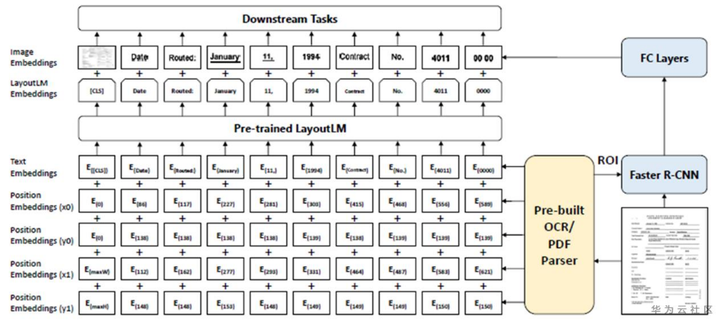
图7 LayoutLM模型架构
该模型以BERT(NLP领域非常强大的预训练模型)为骨干网络,为了利用布局和版式信息,引入了2D位置向量表示,即各文本切片的两点标注(左上角的横纵坐标和右下角的横纵坐标)分别通过横纵两个方向上的索引表得到的向量。同时可以选择性地加入切片的视觉向量表示以补充更多的信息。由于BERT本质上可被看做是一个全连接的图网络,因此我们将LayoutLM也归类于基于图结构的技术。后续出现了类似于LayoutLM的预训练模型如Lambert[5]等,在文档图片关键信息提取任务上都取得了SOTA结构,证明了深度学习模型基于大语料和大模型的强大能力。
3.端到端的文档图片关键信息提取技术
端到端的方法,顾名思义,就是直接以原始图片作为输入得到文档的关键信息内容。
3.1 EATEN[6]
这篇文章指出,基于检测识别流程的信息提取技术会受到如轻微的位置偏移等带来的影响。为解决上述问题,作者提出EATEN方法,其直接从原始图片输入中提取出文档关键信息内容。
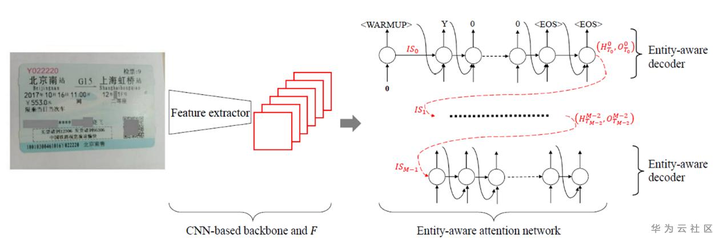
图8 EATEN模型架构
具体地,如图8的网络结构所示,EATAN采用CNN骨干网络来提取得到文档图片的高层视觉信息,然后利用实体类别感知的注意力网络来学习实体布局信息,最后利用基于LSTM的解码器解码得到预设的实体内容。该模型由于直接从图片中得到文档关键信息,易于加速优化,便于边缘部署。
3.2 TRIE[7]
这篇文章指出,现有方法对关键信息提取都是将其作为多个独立的任务进行,即文字检测、文字识别和信息提取,彼此之间无法进行相互监督学习,因此作者提出一个端到端的网络模型TRIE,同时对上述三个任务进行模型学习。
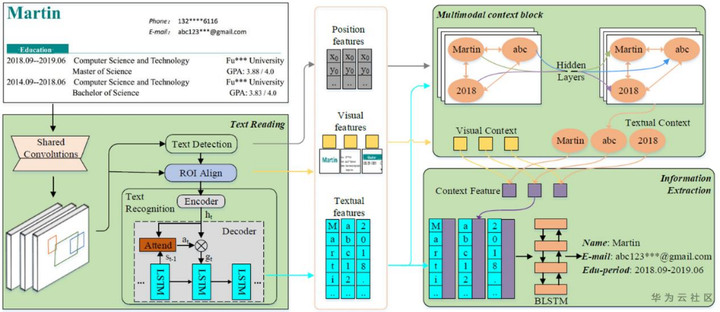
图9 TRIE模型架构
具体地,利用ResNet+FPN作为骨干网络,进行文字检测,然后利用检测网络+ROIAlign的结果进行attention+encoder-decoder的文字识别,最后将文本位置信息、视觉信息、语义信息进行融合,通过BiLSTM来进行IOB标签分类得到文档关键信息。整个TRIE模型对三个任务(即文本检测、文本识别和信息提取)进行共同优化学习:

小结:
本文对OCR领域中文档图片的关键信息提取技术进行了简要介绍,将近期技术按模型分为基于栅格、基于图和端到端三种类别,对每个类别筛选了两篇论文进行了阐述。总的来说,基于大语料的预训练图模型展现出了巨大的实力,而端到端模型也存在不小的潜力。
参考文献:
[1] Katti, Anoop R., et al. “Chargrid: Towards Understanding 2D Documents.” EMNLP, 2018.
[2] Zhao, Xiaohui, et al. “Cutie: Learning to understand documents with convolutional universal text information extractor.” arXiv, 2019
[3] Liu, Xiaojing, et al. “Graph Convolution for Multimodal Information Extraction from Visually Rich Documents.” NAACL, 2019.
[4] Xu, Yiheng, et al. “Layoutlm: Pre-training of text and layout for document image understanding.” KDD, 2020.
[5] Garncarek, Łukasz, et al. “LAMBERT: Layout-Aware language Modeling using BERT for information extraction.” arXiv, 2020
[6] Guo, He, et al. “Eaten: Entity-aware attention for single shot visual text extraction.” ICDAR, 2019.
[7] Zhang, Peng, et al. “TRIE: End-to-End Text Reading and Information Extraction for Document Understanding.” ACM MM, 2020.
本文分享自华为云社区《技术综述十:文字识别之关键信息提取》,原文作者:小菜鸟chg 。
Java基于opencv实现图像数字识别(一)
最近分到了一个任务,要做数字识别,我分配到的任务是把数字一个个的分开;当时一脸懵逼,直接百度java如何分割图片中的数字,然后就百度到了用BufferedImage这个类进行操作;尝试着做了一下,做到灰度化,和二值化就做不下去了;然后几乎就没有啥java的资料了,最多的好像都是c++,惹不起、惹不起......
我也想尝试着用c++做一下,百度到了c++基于opencv来做图像识别的;但是要下vs啊,十几个g呢,我内存这么小,配置这么麻烦,而且vs各个版本又有自己的特色;百度了以下,java基于opencv来做图像识别,发现也很少,但是有资料啊,而且配置也很简单啊,能做到就做到哪,慢慢学;现在我已经做到切割图片了,用的是投影法,效果还可以。可以先看以下
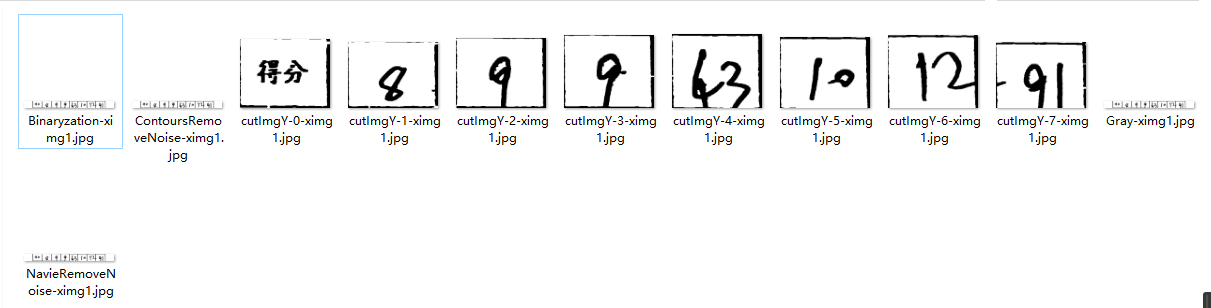
我们来一步步实现,先从下载opencv、配置java环境、写一个测试用例开始;肯定比你想象中的要简单
一、下载opencv,我用的是windows系统,这个应该没啥区别吧,java跨平台的
直接百度搜索opencv,建议去opencv中文网站下载吧;我刚开始下载的时候,下到一大半的时候突然停了,就这样停了;明明中文网站啊,还需要梯子吗;算了,我还是FQ吧,然后就下好了,一步步安装,就好了,没啥难的。安装好后,就长这样,我也没有配置环境;

二、配置java开发环境
也很简单,就是把F:\openCv\opencv\build\java这个目录下的一个jar添加到环境变量,然后看你是系统是多少位的,把相应目录下的文件拷贝到你的项目中

空项目大概就是这样
三、我们测试一下,就用opencv二值化处理一张图片
我们来看一下代码
public static void main(String[] args) {
// 这个必须要写,不写报java.lang.UnsatisfiedLinkError
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
File imgFile = new File("C:/Users/admin/Desktop/open/test.png");
String dest = "C:/Users/admin/Desktop/open";
Mat src = Imgcodecs.imread(imgFile.toString(), Imgcodecs.CV_LOAD_IMAGE_GRAYSCALE);
Mat dst = new Mat();
Imgproc.adaptiveThreshold(src, dst, 255, Imgproc.ADAPTIVE_THRESH_MEAN_C, Imgproc.THRESH_BINARY, 13, 5);
Imgcodecs.imwrite(dest + "/AdaptiveThreshold" + imgFile.getName(), dst);
}
我们来看一下效果图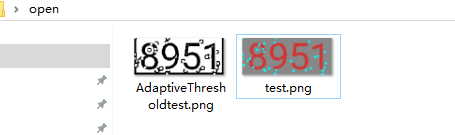
Java基于opencv实现图像数字识别(二)—基本流程
做一个项目之前呢,我们应该有一个总体把握,或者是进度条;来一步步的督促着我们来完成这个项目,在我们正式开始前呢,我们先讨论下流程。
我做的主要是表格中数字的识别,但这个不是重点。重点是通过这个我们可以举一反三,来实现我们自己的业务。
图像的识别主要分为两步:图片预处理和图像识别;这两步都很重要
图像预处理:
1、 图像灰度化;二值化
2、 图像降噪,去除干扰线
3、 图像腐蚀、膨胀处理
4、 字符分割
5、 字符归一化
图像识别:
1、 特征值提取
2、 训练
3、 测试
灰度化:
在RGB模型中,如果R=G=B时,则彩色表示灰度颜色,其中R=G=B的值叫灰度值;因此,灰度图像每个像素点只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。一般常用的是加权平均法来求像素点的灰度值
常见的加权方法如下:
1:)Gray = B ; Gray = G ; Gray = R
2:)Gray = max({B , G , R})
3:)Gray = (B + G + R) / 3
4:)Gray = 0.072169 * B + 0.715160 * G + 0.212671 * R
5:)Gray = 0.11 * B + 0.59 * G + 0.3 * R
这几种方法中,第一为分量法,即用RGB三个分量的某一个分量作为该点的灰度值;第二种方法为最大值法,将彩色图像中的三个分量亮度的最大值作为灰度图的灰度值;第三种方法是将彩色图像中的三分量求平均得到一个灰度图;后两种都属于加权平均法,其中第四种是opencv开发库所采用的一种求灰度值算法;第五种为从人体生理学角度所提出的一种求灰度值算法(人眼对绿色的敏感最高,对蓝色敏感最低)
二值化:
图像的二值化,就是将图像上的像素点的灰度值设置位0或255这两个极点,也就是将整个图像呈现出明显的只有黑和白的视觉效果
图像降噪:
就是处理掉一些干扰因素;
主要的降噪算法
滤波类:通过设计滤波器对图像进行处理。特点是速度往往比较快,很多卷积滤波可以借助快速傅里叶变化来加速
稀疏表达类:自然图片之所以看起来不同于随机噪音/人造结构,是因为大家发现他们总会在某一个横型下存在稀疏表达。而我们想排除的噪音往往无法被稀疏化。基于这个判别式模型,用稀疏性来约束自然图像,在很多逆问题里取得了拔群的效果
外部先验:如果从有噪音的图片本身无法找到规律,我们也可以借助其他类似但又没有噪音的图片,来总结图片具有的固有属性。这一类方法利用的外部图片来创造先验条件,然后用于约束需要预测的图片。最有代表性就是混合高斯模型
聚类低秩:除了可稀疏性,低秩性也是自然图片常见的一个特性。数学上,可稀疏表达的数据可以被认为是在Union of low-dimensional subspaces;而低秩数据则是直接存在于一个Low-dimensional subspace。这个更严格的限制往往也可以取得很好的降噪效果。
深度学习(Deep Learning):这类可以归于外部先验的子类,如果说解决逆问题的关键,是寻找一个好的图像约束器,那么我们为什么不用一个最好的约束器?深度学习方法的精髓,就在于通过大量的数据,学习得到一个高复杂度(多层网络结构)的图片约束器,从而将学习外部先验条件这一途径推到极限。近期的很多这类工作,都是沿着这一思路,取得了非常逆天的效果。
字符分割:就是把图片有用的部分一个个分割下来;字符分割有很多方法,但并不是每一种方法都是万能的,我们需要根据自己的业务来调整;常见的就是投影法和连通域法
投影法:就是分析每一维上黑色像素点的个数(假设是二值化的图像),然后设置一个阙值,根据这个阙值来分割图片
图像腐蚀、膨胀处理
腐蚀:图像的一部分区域与指定的核进行卷积,求核的最小值并赋值给指定区域。 腐蚀可以理解为图像中高亮区域的领域缩小。
膨胀:图像的一部分区域与指定的核进行卷积,求核的最大值并赋值给指定区域。 膨胀可以理解为图像中高亮区域的领域扩大。
字符的归一化:
就是将分割好的图像内的字符归一化到一个标准模板大小;归一化的理想结果就是:归一化到标准模板大小;倾斜校正;笔画宽度归一化;字形归一化。
注:
本文章参考了很多博客,感谢;主要是跟着一个博客来实现的https://blog.csdn.net/ysc6688/article/category/2913009(也是基于opencv来做的,只不过他是用c++实现的)感谢
Java基于opencv实现图像数字识别(三)—灰度化和二值化
一、灰度化
灰度化:在RGB模型中,如果R=G=B时,则彩色表示灰度颜色,其中R=G=B的值叫灰度值;因此,灰度图像每个像素点只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。一般常用的是加权平均法来求像素点的灰度值,opencv开发库所采用的一种求灰度值算法如下;
:)Gray = 0.072169 * B + 0.715160 * G + 0.212671 * R
有两种方式可以实现灰度化,如下
方式1
@Test
public void toGray() {
// 这个必须要写,不写报java.lang.UnsatisfiedLinkError
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
File imgFile = new File("C:/Users/admin/Desktop/open/test.png");
String dest = "C:/Users/admin/Desktop/open";
//方式一
Mat src = Imgcodecs.imread(imgFile.toString(), Imgcodecs.CV_LOAD_IMAGE_GRAYSCALE);
//保存灰度化的图片
Imgcodecs.imwrite(dest + "/toGray" + imgFile.getName(), src);
}
方式2
@Test
public void toGray() {
// 这个必须要写,不写报java.lang.UnsatisfiedLinkError
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
File imgFile = new File("C:/Users/admin/Desktop/open/test.png");
String dest = "C:/Users/admin/Desktop/open";
//方式二
Mat src = Imgcodecs.imread(imgFile.toString());
Mat gray = new Mat();
Imgproc.cvtColor(src, gray, Imgproc.COLOR_BGR2GRAY);
src = gray;
//保存灰度化的图片
Imgcodecs.imwrite(dest + "/toGray2" + imgFile.getName(), src);
}
二值化:图像的二值化,就是将图像上的像素点的灰度值设置位0或255这两个极点,也就是将整个图像呈现出明显的只有黑和白的视觉效果
常见的二值化方法为固定阀值和自适应阀值,固定阀值就是制定一个固定的数值作为分界点,大于这个阀值的像素就设为255,小于该阀值就设为0,这种方法简单粗暴,但是效果不一定好.另外就是自适应阀值,每次根据图片的灰度情况找合适的阀值。自适应阀值的方法有很多,这里采用了一种类似K均值的方法,就是先选择一个值作为阀值,统计大于这个阀值的所有像素的灰度平均值和小于这个阀值的所有像素的灰度平均值,再求这两个值的平均值作为新的阀值。重复上面的计算,直到每次更新阀值后,大于该阀值和小于该阀值的像素数目不变为止。
代码如下
@Test
public void binaryzation(Mat mat) {
int BLACK = 0;
int WHITE = 255;
int ucThre = 0, ucThre_new = 127;
int nBack_count, nData_count;
int nBack_sum, nData_sum;
int nValue;
int i, j;
int width = mat.width(), height = mat.height();
//寻找最佳的阙值
while (ucThre != ucThre_new) {
nBack_sum = nData_sum = 0;
nBack_count = nData_count = 0;
for (j = 0; j < height; ++j) {
for (i = 0; i < width; i++) {
nValue = (int) mat.get(j, i)[0];
if (nValue > ucThre_new) {
nBack_sum += nValue;
nBack_count++;
} else {
nData_sum += nValue;
nData_count++;
}
}
}
nBack_sum = nBack_sum / nBack_count;
nData_sum = nData_sum / nData_count;
ucThre = ucThre_new;
ucThre_new = (nBack_sum + nData_sum) / 2;
}
//二值化处理
int nBlack = 0;
int nWhite = 0;
for (j = 0; j < height; ++j) {
for (i = 0; i < width; ++i) {
nValue = (int) mat.get(j, i)[0];
if (nValue > ucThre_new) {
mat.put(j, i, WHITE);
nWhite++;
} else {
mat.put(j, i, BLACK);
nBlack++;
}
}
}
// 确保白底黑字
if (nBlack > nWhite) {
for (j = 0; j < height; ++j) {
for (i = 0; i < width; ++i) {
nValue = (int) (mat.get(j, i)[0]);
if (nValue == 0) {
mat.put(j, i, WHITE);
} else {
mat.put(j, i, BLACK);
}
}
}
}
}
测试二值化
@Test
public void binaryzation() {
// 这个必须要写,不写报java.lang.UnsatisfiedLinkError
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
File imgFile = new File("C:/Users/admin/Desktop/open/test.png");
String dest = "C:/Users/admin/Desktop/open";
//先经过一步灰度化
Mat src = Imgcodecs.imread(imgFile.toString());
Mat gray = new Mat();
Imgproc.cvtColor(src, gray, Imgproc.COLOR_BGR2GRAY);
src = gray;
//二值化
binaryzation(src);
Imgcodecs.imwrite(dest + "/binaryzation" + imgFile.getName(), src);
}
Opencv自己也提供了二值化的接口,好像没有上面的效果好,这里也把代码放出来
@Test
public void testOpencvBinary() {
// 这个必须要写,不写报java.lang.UnsatisfiedLinkError
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
File imgFile = new File("C:/Users/admin/Desktop/open/test.png");
String dest = "C:/Users/admin/Desktop/open";
Mat src = Imgcodecs.imread(imgFile.toString(), Imgcodecs.CV_LOAD_IMAGE_GRAYSCALE);
Imgcodecs.imwrite(dest + "/AdaptiveThreshold1" + imgFile.getName(), src);
Mat dst = new Mat();
Imgproc.adaptiveThreshold(src, dst, 255, Imgproc.ADAPTIVE_THRESH_MEAN_C, Imgproc.THRESH_BINARY, 13, 5);
Imgcodecs.imwrite(dest + "/AdaptiveThreshold2" + imgFile.getName(), dst);
Imgproc.adaptiveThreshold(src, dst, 255, Imgproc.ADAPTIVE_THRESH_MEAN_C, Imgproc.THRESH_BINARY_INV, 13, 5);
Imgcodecs.imwrite(dest + "/AdaptiveThreshold3" + imgFile.getName(), dst);
Imgproc.adaptiveThreshold(src, dst, 255, Imgproc.ADAPTIVE_THRESH_GAUSSIAN_C, Imgproc.THRESH_BINARY, 13, 5);
Imgcodecs.imwrite(dest + "/AdaptiveThreshold4" + imgFile.getName(), dst);
Imgproc.adaptiveThreshold(src, dst, 255, Imgproc.ADAPTIVE_THRESH_GAUSSIAN_C, Imgproc.THRESH_BINARY_INV, 13, 5);
Imgcodecs.imwrite(dest + "/AdaptiveThreshold5" + imgFile.getName(), dst);
}
本文章参考了很多博客,感谢;主要是跟着一个博客来实现的https://blog.csdn.net/ysc6688/article/category/2913009(也是基于opencv来做的,只不过他是用c++实现的)感谢
Java基于opencv实现图像数字识别(四)—图像降噪
我们每一步的工作都是基于前一步的,我们先把我们前面的几个函数封装成一个工具类,以后我们所有的函数都基于这个工具类
这个工具类呢,就一个成员变量Mat,非常的简单,这里给出代码
public class ImageUtils {
private static final int BLACK = 0;
private static final int WHITE = 255;
private Mat mat;
/**
* 空参构造函数
*/
public ImageUtils() {
}
/**
* 通过图像路径创建一个mat矩阵
*
* @param imgFilePath
* 图像路径
*/
public ImageUtils(String imgFilePath) {
mat = Imgcodecs.imread(imgFilePath);
}
public void ImageUtils(Mat mat) {
this.mat = mat;
}
/**
* 加载图片
*
* @param imgFilePath
*/
public void loadImg(String imgFilePath) {
mat = Imgcodecs.imread(imgFilePath);
}
/**
* 获取图片高度的函数
*
* @return
*/
public int getHeight() {
return mat.rows();
}
/**
* 获取图片宽度的函数
*
* @return
*/
public int getWidth() {
return mat.cols();
}
/**
* 获取图片像素点的函数
*
* @param y
* @param x
* @return
*/
public int getPixel(int y, int x) {
// 我们处理的是单通道灰度图
return (int) mat.get(y, x)[0];
}
/**
* 设置图片像素点的函数
*
* @param y
* @param x
* @param color
*/
public void setPixel(int y, int x, int color) {
// 我们处理的是单通道灰度图
mat.put(y, x, color);
}
/**
* 保存图片的函数
*
* @param filename
* @return
*/
public boolean saveImg(String filename) {
return Imgcodecs.imwrite(filename, mat);
}
}
灰度化和二值化的代码我没有贴出来,因为代码实在有点长
我们接着上一步的成果,来开始我们的降噪
一、8邻域降噪
我感觉9宫格降噪更形象一点;即9宫格中心被异色包围,则同化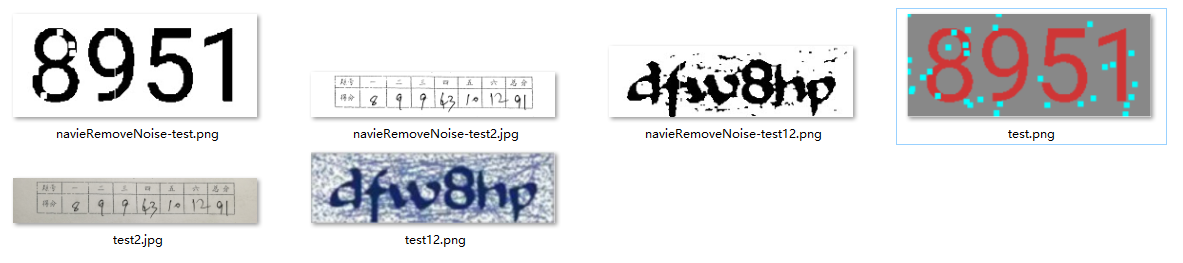
降噪效果还是蛮好的,这个方法对小噪点比较好
/**
* 8邻域降噪,又有点像9宫格降噪;即如果9宫格中心被异色包围,则同化
* @param pNum 默认值为1
*/
public void navieRemoveNoise(int pNum) {
int i, j, m, n, nValue, nCount;
int nWidth = getWidth(), nHeight = getHeight();
// 对图像的边缘进行预处理
for (i = 0; i < nWidth; ++i) {
setPixel(i, 0, WHITE);
setPixel(i, nHeight - 1, WHITE);
}
for (i = 0; i < nHeight; ++i) {
setPixel(0, i, WHITE);
setPixel(nWidth - 1, i, WHITE);
}
// 如果一个点的周围都是白色的,而它确是黑色的,删除它
for (j = 1; j < nHeight - 1; ++j) {
for (i = 1; i < nWidth - 1; ++i) {
nValue = getPixel(j, i);
if (nValue == 0) {
nCount = 0;
// 比较以(j ,i)为中心的9宫格,如果周围都是白色的,同化
for (m = j - 1; m <= j + 1; ++m) {
for (n = i - 1; n <= i + 1; ++n) {
if (getPixel(m, n) == 0) {
nCount++;
}
}
}
if (nCount <= pNum) {
// 周围黑色点的个数小于阀值pNum,把该点设置白色
setPixel(j, i, WHITE);
}
} else {
nCount = 0;
// 比较以(j ,i)为中心的9宫格,如果周围都是黑色的,同化
for (m = j - 1; m <= j + 1; ++m) {
for (n = i - 1; n <= i + 1; ++n) {
if (getPixel(m, n) == 0) {
nCount++;
}
}
}
if (nCount >= 7) {
// 周围黑色点的个数大于等于7,把该点设置黑色;即周围都是黑色
setPixel(j, i, BLACK);
}
}
}
}
}
二、连通域降噪

我们先介绍一个函数(floodFill)
floodFill就是把一个点x的所有相邻的点都涂上x点的颜色,一直填充下去,直到这个区域内所有的点都被填充完为止
在计算的过程中,每扫描到一个黑色(灰度值为0)的点,就将与该点连通的所有点的灰度值都改为1,因此这一个连通域的点都不会再次重复计算了。下一个灰度值为0的点所有连通点的颜色都改为2,这样依次递加,直到所有的点都扫描完。接下来再次扫描所有的点,统计每一个灰度值对应的点的个数,每一个灰度值的点的个数对应该连通域的大小,并且不同连通域由于灰度值不同,因此每个点只计算一次,不会重复。这样一来就统计到了每个连通域的大小,再根据预设的阀值,如果该连通域大小小于阀值,则其就为噪点。这个算法比较适合检查大的噪点,与上个算法正好相反。

因为我找的图像关系,效果可能不咋明显;
/**
* 连通域降噪
* @param pArea 默认值为1
*/
public void contoursRemoveNoise(double pArea) {
int i, j, color = 1;
int nWidth = getWidth(), nHeight = getHeight();
for (i = 0; i < nWidth; ++i) {
for (j = 0; j < nHeight; ++j) {
if (getPixel(j, i) == BLACK) {
//用不同颜色填充连接区域中的每个黑色点
//floodFill就是把一个点x的所有相邻的点都涂上x点的颜色,一直填充下去,直到这个区域内所有的点都被填充完为止
Imgproc.floodFill(mat, new Mat(), new Point(i, j), new Scalar(color));
color++;
}
}
}
//统计不同颜色点的个数
int[] ColorCount = new int[255];
for (i = 0; i < nWidth; ++i) {
for (j = 0; j < nHeight; ++j) {
if (getPixel(j, i) != 255) {
ColorCount[getPixel(j, i) - 1]++;
}
}
}
//去除噪点
for (i = 0; i < nWidth; ++i) {
for (j = 0; j < nHeight; ++j) {
if (ColorCount[getPixel(j, i) - 1] <= pArea) {
setPixel(j, i, WHITE);
}
}
}
for (i = 0; i < nWidth; ++i) {
for (j = 0; j < nHeight; ++j) {
if (getPixel(j, i) < WHITE) {
setPixel(j, i, BLACK);
}
}
}
}
注:
本文章参考了很多博客,感谢;主要是跟着一个博客来实现的https://blog.csdn.net/ysc6688/article/category/2913009(也是基于opencv来做的,只不过他是用c++实现的)感谢
Java基于opencv实现图像数字识别(五)—腐蚀、膨胀处理
腐蚀:去除图像表面像素,将图像逐步缩小,以达到消去点状图像的效果;作用就是将图像边缘的毛刺剔除掉
膨胀:将图像表面不断扩散以达到去除小孔的效果;作用就是将目标的边缘或者是内部的坑填掉
使用相同次数的腐蚀和膨胀,可以使目标表面更平滑;但也有场景限制,就是如果去噪不干净的话,会出现意想不到的结果,尽量别使用
大概的效果,适合降噪比较干净的图
// 图像腐蚀/膨胀处理
public void erodeImg() {
Mat outImage = new Mat();
// size 越小,腐蚀的单位越小,图片越接近原图
Mat structImage = Imgproc.getStructuringElement(Imgproc.MORPH_RECT, new Size(5, 2));
/**
* 图像腐蚀
* 腐蚀说明: 图像的一部分区域与指定的核进行卷积,
* 求核的最`小`值并赋值给指定区域。
* 腐蚀可以理解为图像中`高亮区域`的'领域缩小'。
* 意思是高亮部分会被不是高亮部分的像素侵蚀掉,使高亮部分越来越少。
*/
Imgproc.erode(mat, outImage, structImage, new Point(-1, -1), 2);
mat = outImage;
/**
* 膨胀
* 膨胀说明: 图像的一部分区域与指定的核进行卷积,
* 求核的最`大`值并赋值给指定区域。
* 膨胀可以理解为图像中`高亮区域`的'领域扩大'。
* 意思是高亮部分会侵蚀不是高亮的部分,使高亮部分越来越多。
*/
Imgproc.dilate(mat, outImage, structImage , new Point(-1, -1), 2);
mat = outImage;
}
本文章参考了很多博客,感谢;主要是跟着一个博客来实现的https://blog.csdn.net/ysc6688/article/category/2913009 感谢
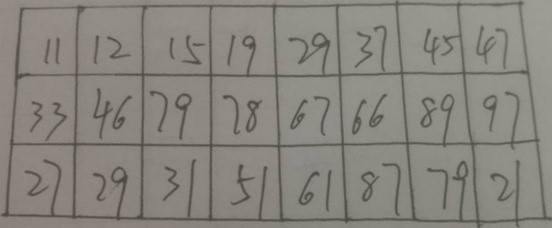
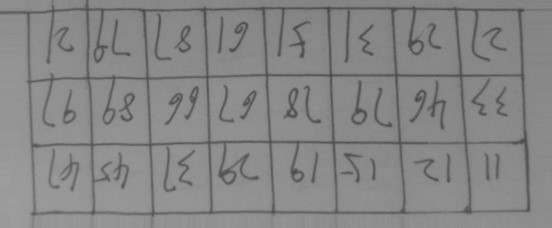
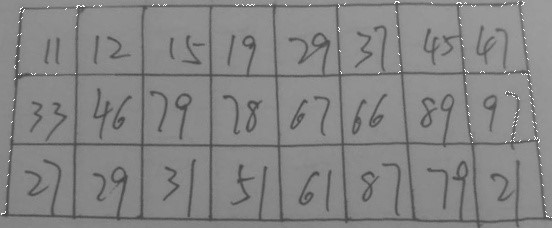
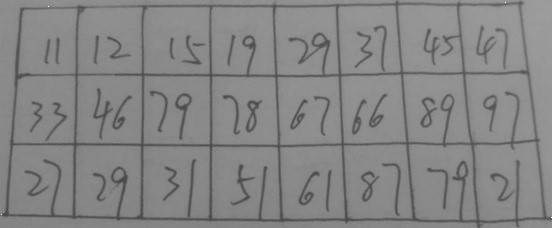
Java基于opencv实现图像数字识别(五)—投影法分割字符
水平投影法
1、水平投影法就是先用一个数组统计出图像每行黑色像素点的个数(二值化的图像);
2、选出一个最优的阀值,根据比这个阀值大或小,用一个数组记录相应Y轴的坐标;
3、因为是水平切割我们只需要Y轴的切割点即可,宽度默认图像的宽,高度可以用相邻的切割点相减得到;
4、优化切割点,把切割点靠近的都清除掉
5、设置感应区的区域,切割图片
垂直投影法和水平投影法类似,对比思考一下
因为我做的是表格的切割,你如果想实现验证码的切割,或者其他的类比这个,我想也是很容易实现的
我们先看一下,效果,还是很不错的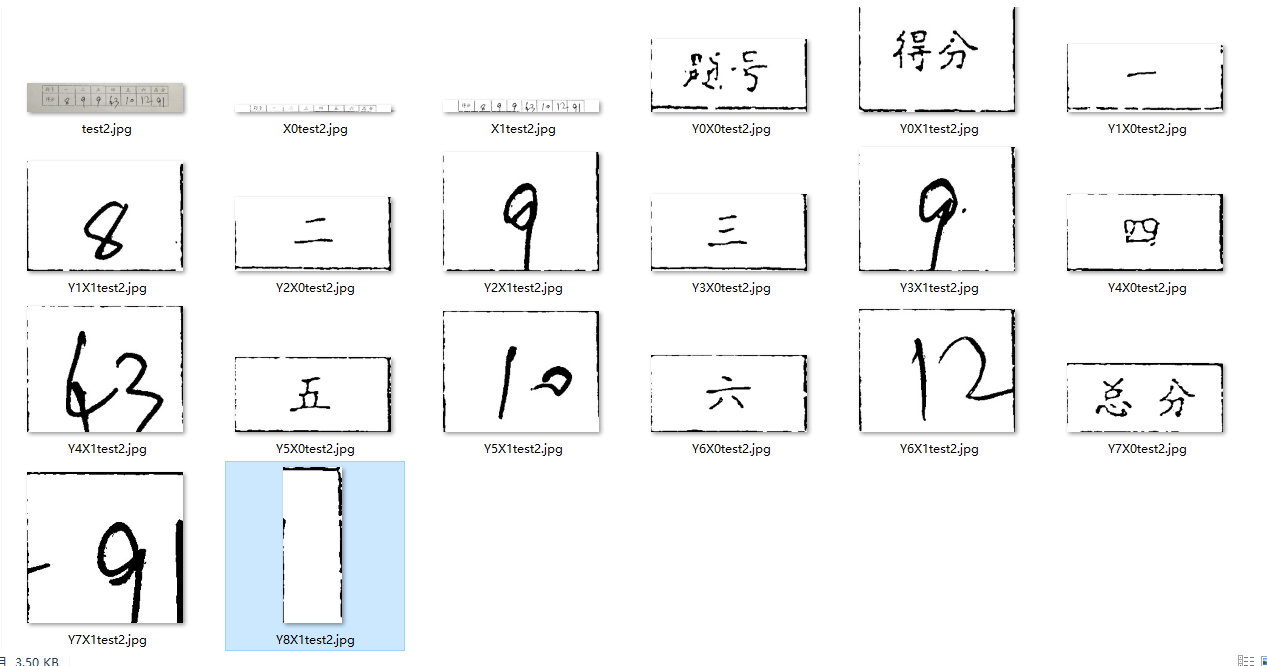
水平切割代码
// 图像切割,水平投影法切割
public List<Mat> cutImgX() {
int i, j;
int nWidth = getWidth(), nHeight = getHeight();
int[] xNum = new int[nHeight], cNum;
int average = 0;// 记录像素的平均值
// 统计出每行黑色像素点的个数
for (i = 0; i < nHeight; i++) {
for (j = 0; j < nWidth; j++) {
if (getPixel(i, j) == BLACK) {
xNum[i]++;
}
}
}
// 经过测试这样得到的平均值最优
cNum = Arrays.copyOf(xNum, xNum.length);
Arrays.sort(cNum);
for (i = 31 * nHeight / 32; i < nHeight; i++) {
average += cNum[i];
}
average /= (nHeight / 32);
// 把需要切割的y点都存到cutY中
List<Integer> cutY = new ArrayList<Integer>();
for (i = 0; i < nHeight; i++) {
if (xNum[i] > average) {
cutY.add(i);
}
}
// 优化cutY把
if (cutY.size() != 0) {
int temp = cutY.get(cutY.size() - 1);
// 因为线条有粗细,优化cutY
for (i = cutY.size() - 2; i >= 0; i--) {
int k = temp - cutY.get(i);
if (k <= 8) {
cutY.remove(i);
} else {
temp = cutY.get(i);
}
}
}
// 把切割的图片都保存到YMat中
List<Mat> YMat = new ArrayList<Mat>();
for (i = 1; i < cutY.size(); i++) {
// 设置感兴趣的区域
int startY = cutY.get(i - 1);
int height = cutY.get(i) - startY;
Mat temp = new Mat(mat, new Rect(0, startY, nWidth, height));
Mat t = new Mat();
temp.copyTo(t);
YMat.add(t);
}
return YMat;
}
垂直投影法
// 图像切割,垂直投影法切割
public List<Mat> cutImgY() {
int i, j;
int nWidth = getWidth(), nHeight = getHeight();
int[] xNum = new int[nWidth], cNum;
int average = 0;// 记录像素的平均值
// 统计出每列黑色像素点的个数
for (i = 0; i < nWidth; i++) {
for (j = 0; j < nHeight; j++) {
if (getPixel(j, i) == BLACK) {
xNum[i]++;
}
}
}
// 经过测试这样得到的平均值最优 , 平均值的选取很重要
cNum = Arrays.copyOf(xNum, xNum.length);
Arrays.sort(cNum);
for (i = 31 * nWidth / 32; i < nWidth; i++) {
average += cNum[i];
}
average /= (nWidth / 28);
// 把需要切割的x点都存到cutY中,
List<Integer> cutX = new ArrayList<Integer>();
for (i = 0; i < nWidth; i += 2) {
if (xNum[i] >= average) {
cutX.add(i);
}
}
if (cutX.size() != 0) {
int temp = cutX.get(cutX.size() - 1);
// 因为线条有粗细,优化cutY
for (i = cutX.size() - 2; i >= 0; i--) {
int k = temp - cutX.get(i);
if (k <= 10) {
cutX.remove(i);
} else {
temp = cutX.get(i);
}
}
}
// 把切割的图片都保存到YMat中
List<Mat> XMat = new ArrayList<Mat>();
for (i = 1; i < cutX.size(); i++) {
// 设置感兴趣的区域
int startX = cutX.get(i - 1);
int width = cutX.get(i) - startX;
Mat temp = new Mat(mat, new Rect(startX, 0, width, nHeight));
Mat t = new Mat();
temp.copyTo(t);
XMat.add(t);
}
return XMat;
}
注:本文章参考了很多博客,感谢;主要是跟着一个博客来实现的https://blog.csdn.net/ysc6688/article/category/2913009(也是基于opencv来做的)感谢
Java基于opencv—归一化
Opencv中提供了resize函数,可以把图像调整到相同大小
Java中resize函数的声明,内部调用的都是native方法
public static void resize(Mat src, Mat dst, Size dsize, double fx, double fy, int interpolation)
{
resize_0(src.nativeObj, dst.nativeObj, dsize.width, dsize.height, fx, fy, interpolation);
return;
}
//javadoc: resize(src, dst, dsize)
public static void resize(Mat src, Mat dst, Size dsize)
{
resize_1(src.nativeObj, dst.nativeObj, dsize.width, dsize.height);
return;
}
解释下各个参数的意思:
src: 待改变大小的图像
dst: 输出的目标图像
dsize: 目标图像的尺寸
fx:width方向的缩放比例,如果它是0,那么它就会按照
(double)dsize.width/src.cols来计算
fy:height方向的缩放比例,如果它是0,那么它就会按照(double)dsize.height/src.rows来计算
interpolation:这个是指定插值的方式,图像缩放之后,肯定像素要进行重新计算的,就靠这个参数来指定重新计算像素的方式,有以下几种:
INTER_NEAREST - 最邻近插值INTER_LINEAR - 双线性插值,如果最后一个参数你不指定,默认使用这种方法INTER_AREA - 区域插值; 区域插值分为3种情况。图像放大时类似于线性插值,图像缩小时可以避免波纹出现。INTER_CUBIC -基于4x4像素邻域的3次插值法INTER_LANCZOS4 - 8x8像素邻域内的Lanczos插值
实战演示一下
/**
* 把图片归一化到相同的大小
*
* @param src
* Mat矩阵对象
* @return
*/
public static Mat resize(Mat src) {
//src = trimImg(src);//这个函数可以忽略,不产生影响
Mat dst = new Mat();
// 区域插值(INTER_AREA):图像放大时类似于线性插值,图像缩小时可以避免波纹出现。
Imgproc.resize(src, dst, dsize, 0, 0, Imgproc.INTER_AREA);
return dst;
}
效果: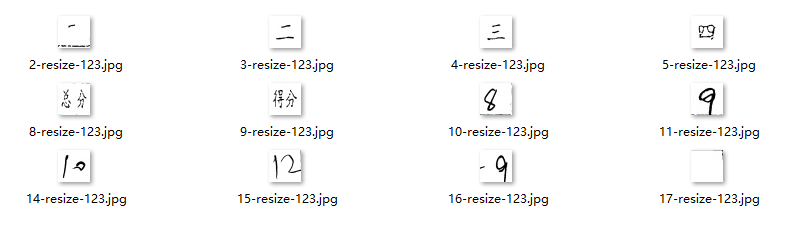
本项目的所有代码地址:https://github.com/YLDarren/opencvHandleImg
Java基于opencv—矫正图像
更多的时候,我们得到的图像不可能是正的,多少都会有一定的倾斜,就比如下面的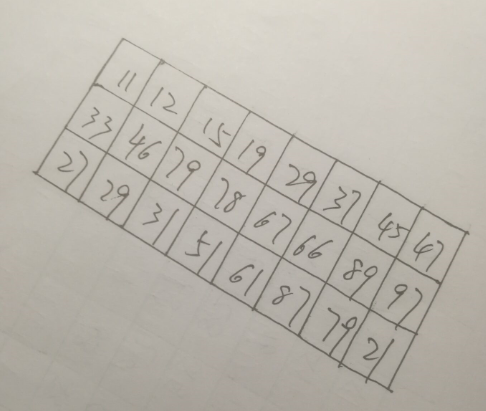
我们要做的就是把它们变成下面这样的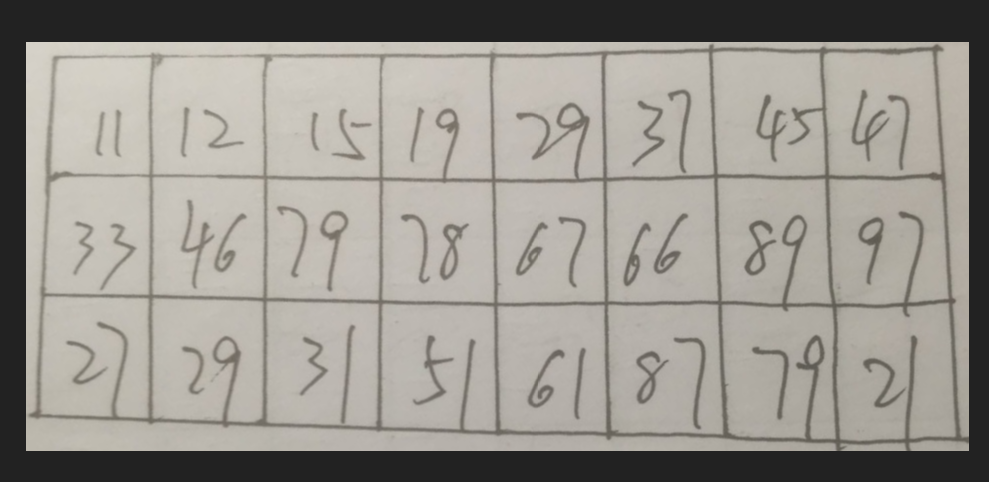
我们采用的是寻找轮廓的思路,来矫正图片;只要有明显的轮廓都可以采用这种思路
具体思路:
1、先用opencv提供的canny函数,进行一次边缘检测
2、再用opencv提供的findContours函数,寻找图像的轮廓,从中间结果种,找到最大的轮廓,就是我们图像的最外面的轮廓
3、得到最终轮廓后,计算矩形轮廓与水平的夹角,然后旋转图像
4、最后我们在从旋转后的图像中,把我们感兴趣的切割出来,就可以了
我们实际的实现一下
先用opencv提供的canny函数,进行一次边缘检测;具体的函数就不再讲解,百度上非常多
/**
* canny算法,边缘检测
*
* @param src
* @return
*/
public static Mat canny(Mat src) {
Mat mat = src.clone();
Imgproc.Canny(src, mat, 60, 200);
HandleImgUtils.saveImg(mat , "C:/Users/admin/Desktop/opencv/open/x/canny.jpg");
return mat;
}
再用opencv提供的findContours函数,寻找图像的轮廓,从中间结果种,找到最大的轮廓,就是我们图像的最外面的轮廓
/**
* 返回边缘检测之后的最大矩形,并返回
*
* @param cannyMat
* Canny之后的mat矩阵
* @return
*/
public static RotatedRect findMaxRect(Mat cannyMat) {
List<MatOfPoint> contours = new ArrayList<MatOfPoint>();
Mat hierarchy = new Mat();
// 寻找轮廓
Imgproc.findContours(cannyMat, contours, hierarchy, Imgproc.RETR_EXTERNAL, Imgproc.CHAIN_APPROX_NONE,
new Point(0, 0));
// 找出匹配到的最大轮廓
double area = Imgproc.boundingRect(contours.get(0)).area();
int index = 0;
// 找出匹配到的最大轮廓
for (int i = 0; i < contours.size(); i++) {
double tempArea = Imgproc.boundingRect(contours.get(i)).area();
if (tempArea > area) {
area = tempArea;
index = i;
}
}
MatOfPoint2f matOfPoint2f = new MatOfPoint2f(contours.get(index).toArray());
RotatedRect rect = Imgproc.minAreaRect(matOfPoint2f);
return rect;
}
得到最终轮廓后,计算矩形轮廓与水平的夹角,然后旋转图像
/**
* 旋转矩形
*
* @param src
* mat矩阵
* @param rect
* 矩形
* @return
*/
public static Mat rotation(Mat cannyMat, RotatedRect rect) {
// 获取矩形的四个顶点
Point[] rectPoint = new Point[4];
rect.points(rectPoint);
double angle = rect.angle + 90;
Point center = rect.center;
Mat CorrectImg = new Mat(cannyMat.size(), cannyMat.type());
cannyMat.copyTo(CorrectImg);
// 得到旋转矩阵算子
Mat matrix = Imgproc.getRotationMatrix2D(center, angle, 0.8);
Imgproc.warpAffine(CorrectImg, CorrectImg, matrix, CorrectImg.size(), 1, 0, new Scalar(0, 0, 0));
return CorrectImg;
}
最后我们在从旋转后的图像中,把我们感兴趣的切割出来,就可以了
/**
* 把矫正后的图像切割出来
*
* @param correctMat
* 图像矫正后的Mat矩阵
*/
public static void cutRect(Mat correctMat , Mat nativeCorrectMat) {
// 获取最大矩形
RotatedRect rect = findMaxRect(correctMat);
Point[] rectPoint = new Point[4];
rect.points(rectPoint);
int startLeft = (int)Math.abs(rectPoint[0].x);
int startUp = (int)Math.abs(rectPoint[0].y < rectPoint[1].y ? rectPoint[0].y : rectPoint[1].y);
int width = (int)Math.abs(rectPoint[2].x - rectPoint[0].x);
int height = (int)Math.abs(rectPoint[1].y - rectPoint[0].y);
System.out.println("startLeft = " + startLeft);
System.out.println("startUp = " + startUp);
System.out.println("width = " + width);
System.out.println("height = " + height);
for(Point p : rectPoint) {
System.out.println(p.x + " , " + p.y);
}
Mat temp = new Mat(nativeCorrectMat , new Rect(startLeft , startUp , width , height ));
Mat t = new Mat();
temp.copyTo(t);
HandleImgUtils.saveImg(t , "C:/Users/admin/Desktop/opencv/open/x/cutRect.jpg");
}
整合整个过程
/**
* 矫正图像
*
* @param src
* @return
*/
public static void correct(Mat src) {
// Canny
Mat cannyMat = canny(src);
// 获取最大矩形
RotatedRect rect = findMaxRect(cannyMat);
// 旋转矩形
Mat CorrectImg = rotation(cannyMat , rect);
Mat NativeCorrectImg = rotation(src , rect);
//裁剪矩形
cutRect(CorrectImg , NativeCorrectImg);
HandleImgUtils.saveImg(src, "C:/Users/admin/Desktop/opencv/open/x/srcImg.jpg");
HandleImgUtils.saveImg(CorrectImg, "C:/Users/admin/Desktop/opencv/open/x/correct.jpg");
}
测试代码
/**
* 测试矫正图像
*/
public void testCorrect() {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
Mat src = HandleImgUtils.matFactory("C:/Users/admin/Desktop/opencv/open/x/x7.jpg");
HandleImgUtils.correct(src);
}
Java方面opencv的例子还是蛮少的,代码都是自己参考博客写的,照顾不周的地方,请见谅
本项目的所有代码地址:https://github.com/YLDarren/opencvHandleImg
Java基于opencv—透视变换矫正图像
很多时候我们拍摄的照片都会产生一点畸变的,就像下面的这张图
虽然不是很明显,但还是有一点畸变的,而我们要做的就是把它变成下面的这张图
效果看起来并不是很好,主要是四个顶点找的不准确,会有一些偏差,而且矫正后产生的目标图是倒着的,哪位好心人给说说为啥
因为我也没有测试畸变很大的图像,也不能保证方法适用于每个图像,这里仅提供我的思路供大家参考。
思路:
我们最重要的就是找到图像的四个顶点,有利用hough直线,求直线交点确定四个顶点,有采用寻找轮廓确定四个顶点等等;今天我提供的思路,也是采用寻找轮廓的方法,用approxPolyDP函数,对图像轮廓点进行多边形拟合,可以得到大概的一个这样的图
可以看到图像的四个顶点处,都有小白点。接下来我们要做的就是把这些点归类,即划分出四个区域[左上,右上,右下,左下];我采用的是利用opencv的寻找轮廓,得到最大轮廓,然后生成最小外接矩形,确定四个顶点的大致位置;然后设置一个阀值,与上图中的点集合求距离,大于阀值的舍弃,小于的保留,可以得到如下的图像

这样所有的点集都落到了四个区域,利用矩形中,对角线距离最大,确定四个顶点的位置,发现效果并不是很好,如下图
到此四个顶点的位置大概的确定了,就只需要根据输入和输出点获得图像透视变换的矩阵,然后透视变换;
我们把思路再理一下:
1、寻找图像的四个顶点的坐标(重要)
思路: 1、canny描边 2、寻找最大轮廓 3、对最大轮廓点集合逼近,得到轮廓的大致点集合 4、把点击划分到四个区域中,即左上,右上,左下,右下 5、根据矩形中,对角线最长,找到矩形的四个顶点坐标
2、根据输入和输出点获得图像透视变换的矩阵
3、透视变换
我们来跟着思路实现一下代码
1、canny描边
/**
* canny算法,边缘检测
*
* @param src
* @return
*/
public static Mat canny(Mat src) {
Mat mat = src.clone();
Imgproc.Canny(src, mat, 60, 200);
HandleImgUtils.saveImg(mat, "C:/Users/admin/Desktop/opencv/open/x/canny.jpg");
return mat;
}
2、寻找最大轮廓;3、对最大轮廓点集合逼近,得到轮廓的大致点集合(代码中有很多冗余,后期会进行优化)
/**
* 利用函数approxPolyDP来对指定的点集进行逼近 精确度设置好,效果还是比较好的
*
* @param cannyMat
*/
public static Point[] useApproxPolyDPFindPoints(Mat cannyMat) {
List<MatOfPoint> contours = new ArrayList<MatOfPoint>();
Mat hierarchy = new Mat();
// 寻找轮廓
Imgproc.findContours(cannyMat, contours, hierarchy, Imgproc.RETR_EXTERNAL, Imgproc.CHAIN_APPROX_NONE,
new Point(0, 0));
// 找出匹配到的最大轮廓
double area = Imgproc.boundingRect(contours.get(0)).area();
int index = 0;
// 找出匹配到的最大轮廓
for (int i = 0; i < contours.size(); i++) {
double tempArea = Imgproc.boundingRect(contours.get(i)).area();
if (tempArea > area) {
area = tempArea;
index = i;
}
}
MatOfPoint2f approxCurve = new MatOfPoint2f();
MatOfPoint2f matOfPoint2f = new MatOfPoint2f(contours.get(index).toArray());
// 原始曲线与近似曲线之间的最大距离设置为0.01,true表示是闭合的曲线
Imgproc.approxPolyDP(matOfPoint2f, approxCurve, 0.01, true);
Point[] points = approxCurve.toArray();
return points;
}
获取四个顶点的参照点
/**
* 获取四个顶点的参照点,返回Point数组[左上,右上,右下,左下] 思路: 我们可以把四个点分成两部分,左部分,右部分
* 左部分:高的为左上,低的为左下(高低是以人的视觉) 右部分同理 首先我们找到最左和最右的位置,以它们的两个中间为分界点,
* 靠左的划分到左部分,靠右的划分到右部分 如果一个区域有三个或更多,哪个比较靠近分界线,划分到少的那个区域
*
* @param cannyMat
* @return
*/
public static Point[] findReferencePoint(Mat cannyMat) {
RotatedRect rect = findMaxRect(cannyMat);
Point[] referencePoints = new Point[4];
rect.points(referencePoints);
double minX = Double.MAX_VALUE;
double maxX = Double.MIN_VALUE;
for (int i = 0; i < referencePoints.length; i++) {
referencePoints[i].x = Math.abs(referencePoints[i].x);
referencePoints[i].y = Math.abs(referencePoints[i].y);
minX = referencePoints[i].x < minX ? referencePoints[i].x : minX;
maxX = referencePoints[i].x > maxX ? referencePoints[i].x : maxX;
}
double center = (minX + maxX) / 2;
List<Point> leftPart = new ArrayList<Point>();
List<Point> rightPart = new ArrayList<Point>();
// 划分左右两个部分
for (int i = 0; i < referencePoints.length; i++) {
if (referencePoints[i].x < center) {
leftPart.add(referencePoints[i]);
} else if (referencePoints[i].x > center) {
rightPart.add(referencePoints[i]);
} else {
if (leftPart.size() < rightPart.size()) {
leftPart.add(referencePoints[i]);
} else {
rightPart.add(referencePoints[i]);
}
}
}
double minDistance = 0;
int minIndex = 0;
if (leftPart.size() < rightPart.size()) {
// 左部分少
minDistance = rightPart.get(0).x - center;
minIndex = 0;
for (int i = 1; i < rightPart.size(); i++) {
if (rightPart.get(i).x - center < minDistance) {
minDistance = rightPart.get(i).x - center;
minIndex = i;
}
}
leftPart.add(rightPart.remove(minIndex));
} else if (leftPart.size() > rightPart.size()) {
// 右部分少
minDistance = center - leftPart.get(0).x;
minIndex = 0;
for (int i = 1; i < leftPart.size(); i++) {
if (center - leftPart.get(0).x < minDistance) {
minDistance = center - leftPart.get(0).x;
minIndex = i;
}
}
rightPart.add(leftPart.remove(minIndex));
}
if (leftPart.get(0).y < leftPart.get(1).y) {
referencePoints[0] = leftPart.get(0);
referencePoints[3] = leftPart.get(1);
}
if (rightPart.get(0).y < rightPart.get(1).y) {
referencePoints[1] = rightPart.get(0);
referencePoints[2] = rightPart.get(1);
}
return referencePoints;
}
4、把点击划分到四个区域中,即左上,右上,右下,左下(效果还可以)
/**
* 把点击划分到四个区域中,即左上,右上,右下,左下
*
* @param points
* 逼近的点集
* @param referencePoints
* 四个参照点集(通过寻找最大轮廓,进行minAreaRect得到四个点[左上,右上,右下,左下])
*/
public static Map<String, List> pointsDivideArea(Point[] points, Point[] referencePoints) {
// px1 左上,px2左下,py1右上,py2右下
List<Point> px1 = new ArrayList<Point>(), px2 = new ArrayList<Point>(), py1 = new ArrayList<Point>(),
py2 = new ArrayList<Point>();
int thresold = 50;// 设置距离阀值
double distance = 0;
for (int i = 0; i < referencePoints.length; i++) {
for (int j = 0; j < points.length; j++) {
distance = Math.pow(referencePoints[i].x - points[j].x, 2)
+ Math.pow(referencePoints[i].y - points[j].y, 2);
if (distance < Math.pow(thresold, 2)) {
if (i == 0) {
px1.add(points[j]);
} else if (i == 1) {
py1.add(points[j]);
} else if (i == 2) {
py2.add(points[j]);
} else if (i == 3) {
px2.add(points[j]);
}
} else {
continue;
}
}
}
Map<String, List> map = new HashMap<String, List>();
map.put("px1", px1);
map.put("px2", px2);
map.put("py1", py1);
map.put("py2", py2);
return map;
}
5、根据矩形中,对角线最长,找到矩形的四个顶点坐标(效果不好)
/**
* 具体的寻找四个顶点的坐标
*
* @param map
* 四个点集域 即左上,右上,右下,左下
* @return
*/
public static Point[] specificFindFourPoint(Map<String, List> map) {
Point[] result = new Point[4];// [左上,右上,右下,左下]
List<Point> px1 = map.get("px1");// 左上
List<Point> px2 = map.get("px2");// 左下
List<Point> py1 = map.get("py1");// 右上
List<Point> py2 = map.get("py2");// 右下
System.out.println("px1.size() " + px1.size());
System.out.println("px2.size() " + px2.size());
System.out.println("py1.size() " + py1.size());
System.out.println("py2.size() " + py2.size());
double maxDistance = 0;
double tempDistance;
int i, j;
int p1 = 0, p2 = 0;// 记录点的下标
// 寻找左上,右下
for (i = 0; i < px1.size(); i++) {
for (j = 0; j < py2.size(); j++) {
tempDistance = Math.pow(px1.get(i).x - py2.get(j).x, 2) + Math.pow(px1.get(i).y - py2.get(j).y, 2);
if (tempDistance > maxDistance) {
maxDistance = tempDistance;
p1 = i;
p2 = j;
}
}
}
result[0] = px1.get(p1);
result[2] = py2.get(p2);
// 寻找左下,右上
maxDistance = 0;
for (i = 0; i < px2.size(); i++) {
for (j = 0; j < py1.size(); j++) {
tempDistance = Math.pow(px2.get(i).x - py1.get(j).x, 2) + Math.pow(px2.get(i).y - py1.get(j).y, 2);
if (tempDistance > maxDistance) {
maxDistance = tempDistance;
p1 = i;
p2 = j;
}
}
}
result[1] = py1.get(p2);
result[3] = px2.get(p1);
return result;
}
整合寻找四个顶点坐标函数
/**
* 寻找四个顶点的坐标 思路: 1、canny描边 2、寻找最大轮廓 3、对最大轮廓点集合逼近,得到轮廓的大致点集合
* 4、把点击划分到四个区域中,即左上,右上,左下,右下 5、根据矩形中,对角线最长,找到矩形的四个顶点坐标
*
* @param src
*/
public static Point[] findFourPoint(Mat src) {
// 1、canny描边
Mat cannyMat = canny(src);
// 2、寻找最大轮廓;3、对最大轮廓点集合逼近,得到轮廓的大致点集合
Point[] points = useApproxPolyDPFindPoints(cannyMat);
//在图像上画出逼近的点
Mat approxPolyMat = src.clone();
for( int i = 0; i < points.length ; i++) {
setPixel(approxPolyMat, (int)points[i].y, (int) points[i].x, 255);
}
saveImg(approxPolyMat, "C:/Users/admin/Desktop/opencv/open/q/x11-approxPolyMat.jpg");
// 获取参照点集
Point[] referencePoints = findReferencePoint(cannyMat);
// 4、把点击划分到四个区域中,即左上,右上,左下,右下(效果还可以)
Map<String, List> map = pointsDivideArea(points, referencePoints);
// 画出标记四个区域中的点集
Mat areaMat = src.clone();
List<Point> px1 = map.get("px1");// 左上
List<Point> px2 = map.get("px2");// 左下
List<Point> py1 = map.get("py1");// 右上
List<Point> py2 = map.get("py2");// 右下
for (int i = 0; i < px1.size(); i++) {
setPixel(areaMat, (int) px1.get(i).y, (int) px1.get(i).x, 255);
}
for (int i = 0; i < px2.size(); i++) {
setPixel(areaMat, (int) px2.get(i).y, (int) px2.get(i).x, 255);
}
for (int i = 0; i < py1.size(); i++) {
setPixel(areaMat, (int) py1.get(i).y, (int) py1.get(i).x, 255);
}
for (int i = 0; i < py2.size(); i++) {
setPixel(areaMat, (int) py2.get(i).y, (int) py2.get(i).x, 255);
}
saveImg(areaMat, "C:/Users/admin/Desktop/opencv/open/q/x11-pointsDivideArea.jpg");
// 5、根据矩形中,对角线最长,找到矩形的四个顶点坐标(效果不好)
Point[] result = specificFindFourPoint(map);
return result;
}
透视变换,矫正图像
/**
* 透视变换,矫正图像 思路: 1、寻找图像的四个顶点的坐标(重要) 思路: 1、canny描边 2、寻找最大轮廓
* 3、对最大轮廓点集合逼近,得到轮廓的大致点集合 4、把点击划分到四个区域中,即左上,右上,左下,右下 5、根据矩形中,对角线最长,找到矩形的四个顶点坐标
* 2、根据输入和输出点获得图像透视变换的矩阵 3、透视变换
*
* @param src
*/
public static Mat warpPerspective(Mat src) {
// 灰度话
src = HandleImgUtils.gray(src);
// 找到四个点
Point[] points = HandleImgUtils.findFourPoint(src);
// Canny
Mat cannyMat = HandleImgUtils.canny(src);
// 寻找最大矩形
RotatedRect rect = HandleImgUtils.findMaxRect(cannyMat);
// 点的顺序[左上 ,右上 ,右下 ,左下]
List<Point> listSrcs = java.util.Arrays.asList(points[0], points[1], points[2], points[3]);
Mat srcPoints = Converters.vector_Point_to_Mat(listSrcs, CvType.CV_32F);
Rect r = rect.boundingRect();
r.x = Math.abs(r.x);
r.y = Math.abs(r.y);
List<Point> listDsts = java.util.Arrays.asList(new Point(r.x, r.y), new Point(r.x + r.width, r.y),
new Point(r.x + r.width, r.y + r.height), new Point(r.x, r.y + r.height));
System.out.println(r.x + "," + r.y);
Mat dstPoints = Converters.vector_Point_to_Mat(listDsts, CvType.CV_32F);
Mat perspectiveMmat = Imgproc.getPerspectiveTransform(srcPoints, dstPoints);
Mat dst = new Mat();
Imgproc.warpPerspective(src, dst, perspectiveMmat, src.size(), Imgproc.INTER_LINEAR + Imgproc.WARP_INVERSE_MAP,
1, new Scalar(0));
return dst;
}
测试函数
/**
* 测试透视变换
*/
public void testWarpPerspective() {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
Mat src = HandleImgUtils.matFactory("C:/Users/admin/Desktop/opencv/open/q/x10.jpg");
src = HandleImgUtils.warpPerspective(src);
HandleImgUtils.saveImg(src, "C:/Users/admin/Desktop/opencv/open/q/x10-testWarpPerspective.jpg");
}
本项目所有代码地址:https://github.com/YLDarren/opencvHandleImg
觉得写的不错话,还是希望能给个Star的
Java基于opencv—矫正图像
更多的时候,我们得到的图像不可能是正的,多少都会有一定的倾斜,就比如下面的
我们要做的就是把它们变成下面这样的
我们采用的是寻找轮廓的思路,来矫正图片;只要有明显的轮廓都可以采用这种思路
具体思路:
1、先用opencv提供的canny函数,进行一次边缘检测
2、再用opencv提供的findContours函数,寻找图像的轮廓,从中间结果种,找到最大的轮廓,就是我们图像的最外面的轮廓
3、得到最终轮廓后,计算矩形轮廓与水平的夹角,然后旋转图像
4、最后我们在从旋转后的图像中,把我们感兴趣的切割出来,就可以了
我们实际的实现一下
先用opencv提供的canny函数,进行一次边缘检测;具体的函数就不再讲解,百度上非常多
/**
* canny算法,边缘检测
*
* @param src
* @return
*/
public static Mat canny(Mat src) {
Mat mat = src.clone();
Imgproc.Canny(src, mat, 60, 200);
HandleImgUtils.saveImg(mat , "C:/Users/admin/Desktop/opencv/open/x/canny.jpg");
return mat;
}
再用opencv提供的findContours函数,寻找图像的轮廓,从中间结果种,找到最大的轮廓,就是我们图像的最外面的轮廓
/**
* 返回边缘检测之后的最大矩形,并返回
*
* @param cannyMat
* Canny之后的mat矩阵
* @return
*/
public static RotatedRect findMaxRect(Mat cannyMat) {
List<MatOfPoint> contours = new ArrayList<MatOfPoint>();
Mat hierarchy = new Mat();
// 寻找轮廓
Imgproc.findContours(cannyMat, contours, hierarchy, Imgproc.RETR_EXTERNAL, Imgproc.CHAIN_APPROX_NONE,
new Point(0, 0));
// 找出匹配到的最大轮廓
double area = Imgproc.boundingRect(contours.get(0)).area();
int index = 0;
// 找出匹配到的最大轮廓
for (int i = 0; i < contours.size(); i++) {
double tempArea = Imgproc.boundingRect(contours.get(i)).area();
if (tempArea > area) {
area = tempArea;
index = i;
}
}
MatOfPoint2f matOfPoint2f = new MatOfPoint2f(contours.get(index).toArray());
RotatedRect rect = Imgproc.minAreaRect(matOfPoint2f);
return rect;
}
得到最终轮廓后,计算矩形轮廓与水平的夹角,然后旋转图像
/**
* 旋转矩形
*
* @param src
* mat矩阵
* @param rect
* 矩形
* @return
*/
public static Mat rotation(Mat cannyMat, RotatedRect rect) {
// 获取矩形的四个顶点
Point[] rectPoint = new Point[4];
rect.points(rectPoint);
double angle = rect.angle + 90;
Point center = rect.center;
Mat CorrectImg = new Mat(cannyMat.size(), cannyMat.type());
cannyMat.copyTo(CorrectImg);
// 得到旋转矩阵算子
Mat matrix = Imgproc.getRotationMatrix2D(center, angle, 0.8);
Imgproc.warpAffine(CorrectImg, CorrectImg, matrix, CorrectImg.size(), 1, 0, new Scalar(0, 0, 0));
return CorrectImg;
}
最后我们在从旋转后的图像中,把我们感兴趣的切割出来,就可以了
/**
* 把矫正后的图像切割出来
*
* @param correctMat
* 图像矫正后的Mat矩阵
*/
public static void cutRect(Mat correctMat , Mat nativeCorrectMat) {
// 获取最大矩形
RotatedRect rect = findMaxRect(correctMat);
Point[] rectPoint = new Point[4];
rect.points(rectPoint);
int startLeft = (int)Math.abs(rectPoint[0].x);
int startUp = (int)Math.abs(rectPoint[0].y < rectPoint[1].y ? rectPoint[0].y : rectPoint[1].y);
int width = (int)Math.abs(rectPoint[2].x - rectPoint[0].x);
int height = (int)Math.abs(rectPoint[1].y - rectPoint[0].y);
System.out.println("startLeft = " + startLeft);
System.out.println("startUp = " + startUp);
System.out.println("width = " + width);
System.out.println("height = " + height);
for(Point p : rectPoint) {
System.out.println(p.x + " , " + p.y);
}
Mat temp = new Mat(nativeCorrectMat , new Rect(startLeft , startUp , width , height ));
Mat t = new Mat();
temp.copyTo(t);
HandleImgUtils.saveImg(t , "C:/Users/admin/Desktop/opencv/open/x/cutRect.jpg");
}
整合整个过程
/**
* 矫正图像
*
* @param src
* @return
*/
public static void correct(Mat src) {
// Canny
Mat cannyMat = canny(src);
// 获取最大矩形
RotatedRect rect = findMaxRect(cannyMat);
// 旋转矩形
Mat CorrectImg = rotation(cannyMat , rect);
Mat NativeCorrectImg = rotation(src , rect);
//裁剪矩形
cutRect(CorrectImg , NativeCorrectImg);
HandleImgUtils.saveImg(src, "C:/Users/admin/Desktop/opencv/open/x/srcImg.jpg");
HandleImgUtils.saveImg(CorrectImg, "C:/Users/admin/Desktop/opencv/open/x/correct.jpg");
}
测试代码
/**
* 测试矫正图像
*/
public void testCorrect() {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
Mat src = HandleImgUtils.matFactory("C:/Users/admin/Desktop/opencv/open/x/x7.jpg");
HandleImgUtils.correct(src);
}
Java方面opencv的例子还是蛮少的,代码都是自己参考博客写的,照顾不周的地方,请见谅
本项目的所有代码地址:https://github.com/YLDarren/opencvHandleImg
Centos7编译opencv3.4.1
参考博客
https://blog.csdn.net/wjbwjbwjbwjb/article/details/79111996
1、配置epel源
yum -y install epel-release
2、安装依赖包和基础包
yum -y install gcc gcc-c++
yum -y install cmake
yum -y install python-devel numpy
yum -y install gtk2-devel
yum -y install libdc1394-devel
yum -y install libv4l-devel
yum -y install gstreamer-plugins-base-devel
3、安装ffmpeg-devel
制作一个bash脚本,一键运行
vim install-ffmpeg.sh
-----内容如下-----
yum -y install vim
yum -y install epel-release
sudo rpm -import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
yum repolist
sudo rpm -import hrrp://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-destop-release-0-1.el7.nux.noarch.rpm
yum repolist
yum update -y
yum install -y ffmpeg
ffmpeg -version
-----内容如上-----
-----赋予可执行权限
chmod +x install-ffmpeg.sh
安装ffmpeg-devel
yum install ffmpeg-devel
4、安装ant
ps:当初我是下载的二进制文件自己解压,配置的环境变量,
但是编译的时候并没有生成JNI文件;没有ant的话opencv编译安装的时候,
是不会打包成jar的
yum -y install ant(流泪推荐)
5、编译opencv
下载源码解压,进到源码目录中
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/opencv-3.4.1/install -D BUILD_TESTS=OFF ..
make -j8
sudo make install
ps: cmake ... 命令后如果看到和下图大概一样的信息,就可以编译出java jar包,否则的话就编译不出,建议检查上面的步骤中是否有漏执行的,已经执行中出错的,出错的再执行一遍即可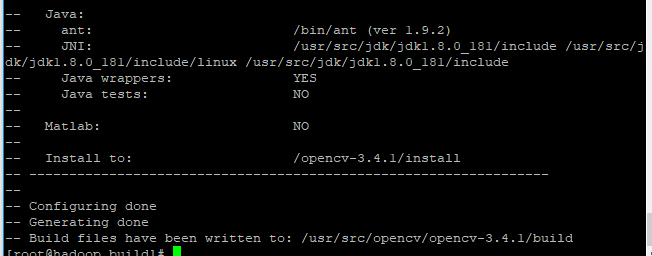
到此安装成功,可以到./build/bin目录下查看是否有opencv-341.jar生成
如果有,说明安装成功了;还可以到./build/lib目录下查看是否有libopencv_java341.so生成
mac上我也安装过,并没有centos的复杂,建议安装的时候用google搜索安装教程
接下来几天我还会写一篇用maven搭建基于opencv的ssm项目,敬请期待
搭建opencv javaweb项目
用到的技术maven、git、ssm、opencv、javaweb
搭建opencv javaweb项目时,踩了很多坑;怀疑过spring,想过python,最后竟然一不小心成了,what.......闲话不多说,让我们看看这关键的一条命令
即把opencv jar包放到maven本地仓库中mvn install:install-file -Dfile="G:\opencv\opencv\build\java\opencv-341.jar" -DgroupId=org.opencv -DartifactId=opencv -Dversion=3.4.1 -Dpackaging=jar
再看看一直报'javaClassNotDefound'的maven依赖配置
<dependency>
<groupId>org.opencv</groupId>
<artifactId>opencv</artifactId>
<version>3.4.1</version>
<systemPath>G:/opencv/opencv/build/java/opencv-341.jar</systemPath>
<scope>system</scope>
</dependency>
再看看不报错的配置
<dependency>
<groupId>org.opencv</groupId>
<artifactId>opencv</artifactId>
<version>3.4.1</version>
</dependency>
到这离成功已经很近了,我们还需要加载dll或者so文件
我们可以在用到opencv的类中用静态代码块加载dll或者so文件,
或者配置一个监听器如下,别忘了在web.xml中配置
package cn.edu.njupt.configure;
import cn.edu.njupt.utils.OpencvConstantUtils;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
public class InitOpencv implements ServletContextListener {
@Override
public void contextDestroyed(ServletContextEvent servletContextEvent) {
}
public void contextInitialized(ServletContextEvent arg0) {
System.load("G:/opencv/opencv/build/java/x64/opencv_java341.dll");
}
}
web.xml
<listener>
<listener-class>cn.edu.njupt.configure.InitOpencv</listener-class>
</listener>
到此项目可以说就搭建好了,liunx,mac只需要按照上述步骤把对应文件路径替换掉就可以了
本项目地址:https://github.com/YLDarren/stitp
相关项目地址:https://github.com/YLDarren/opencvHandleImg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号