
爬虫——Scrapy框架 https://www.cnblogs.com/mayi0312/tag/%E7%88%AC%E8%99%AB/
爬虫——Scrapy框架
- Scrapy是用纯Python实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来爬取网页内容以及各种图片,非常方便。
- Scrapy使用了Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图
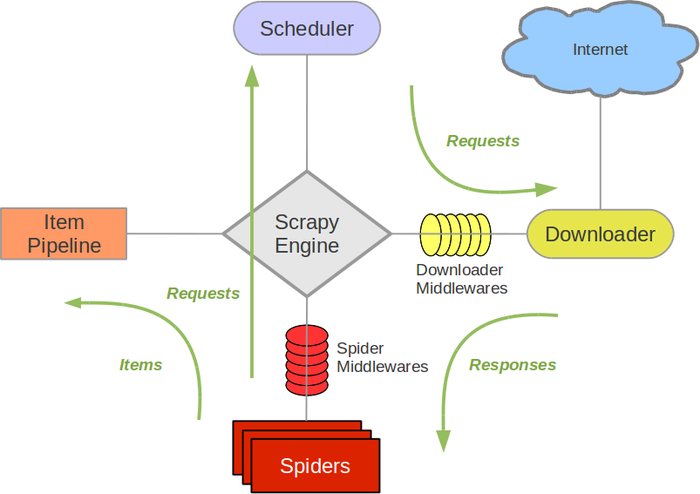
- Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器):它负责接受引擎发送过来的Resquest请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Resquests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses和从Spider出去的Resquests)。
制作Scrapy爬虫一共需要4步:
- 新建项目(scrapy startproject 项目名):新建一个新的爬虫项目
- 明确目标(编写items.py):明确你想要爬取的目标
- 制作爬虫(spiders/xxxspider.py):制作爬虫开始爬取网页
- 存储内容(pipelines.py):设计管道存储爬取内容
入门案例
目标:
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的Spider并提取出结构化数据(Item)
- 编写Item Pipelines来存储提取到的Item(结构化数据)
一、新建项目(scrapy startproject)
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行命令:
|
1
|
scrapy startrpoject mySpider |
其中,mySpider为项目名称,可以看到将会创建一个mySpider文件夹,目录结构大致如下:
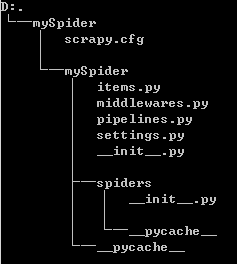
下载来简单介绍一下各个主要文件的作用:
|
1
2
3
4
5
6
7
|
scrapy.cfg:项目的配置文件mySpider/:项目的Python模块,将会从这里引用代码mySpider/items.py:项目的目标文件mySpider/middlewares.py:项目的管道文件mySpider/pipelines.py:项目的管道文件mySpider/settings.py:项目的设置文件mySpider/spiders/:存储爬虫代码目录 |
二、明确目标(mySpider/items.py)
我们这里以抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息为例。
1.打开mySpider目录下的items.py
2.Item定义结构化数据字段,用来保存爬取的数据,有点像Python中的dict,但是提供了一些额外的保护以减少错误。
3.可以通过创建一个scrapy.Item类,并且定义类型为scrapy.Field的类属性来定义一个Item。
4.接下来,创建一个ItcastItem类和构建item模型(model)。
|
1
2
3
4
5
6
7
8
9
10
|
import scrapyclass ItcastItem(scrapy.Item): # define the fields for your item here like: # 教师名 name = scrapy.Field() # 职称 level = scrapy.Field() # 简介 info = scrapy.Field() |
三、制作爬虫(spiders/itcastSpider.py)
爬虫功能要分两步:
1.爬数据
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
|
1
|
scrapy genspider itcast "itcast.cn" |
打开mySpider/spider目录里的itcast.py,默认增加了下列代码:
|
1
2
3
4
5
6
7
8
9
10
11
|
import scrapyclass ItcastSpider(scrapy.Spider): name = "itcast" allowed_domains = ["itcast.cn"] start_urls = ( 'http://www.itcast.cn/', ) def parse(self, response): pass |
我们也可以自行创建itcast.py并编写上面的代码,只不过使用命令可以免云编写固定代码的麻烦
要建立一个Spider,你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性和一个方法。
|
1
2
3
4
5
6
7
8
9
|
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []:是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元组/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下: 1.负责解析返回的网页数据(response.body),提取结构化数据(生成item) 2.生成需要下一页的URL请求。 |
将start_urls的值修改为需要爬取的第一个url
|
1
2
3
4
5
|
start_urls = ("http://www.itcast.cn/channel/teacher/shtml",)或start_urls = ["http://www.itcast.cn/channel/teacher/shtml"] |
2.取数据
爬取整个网页完毕,接下来的就是取的过程了,首先观察页面源码:
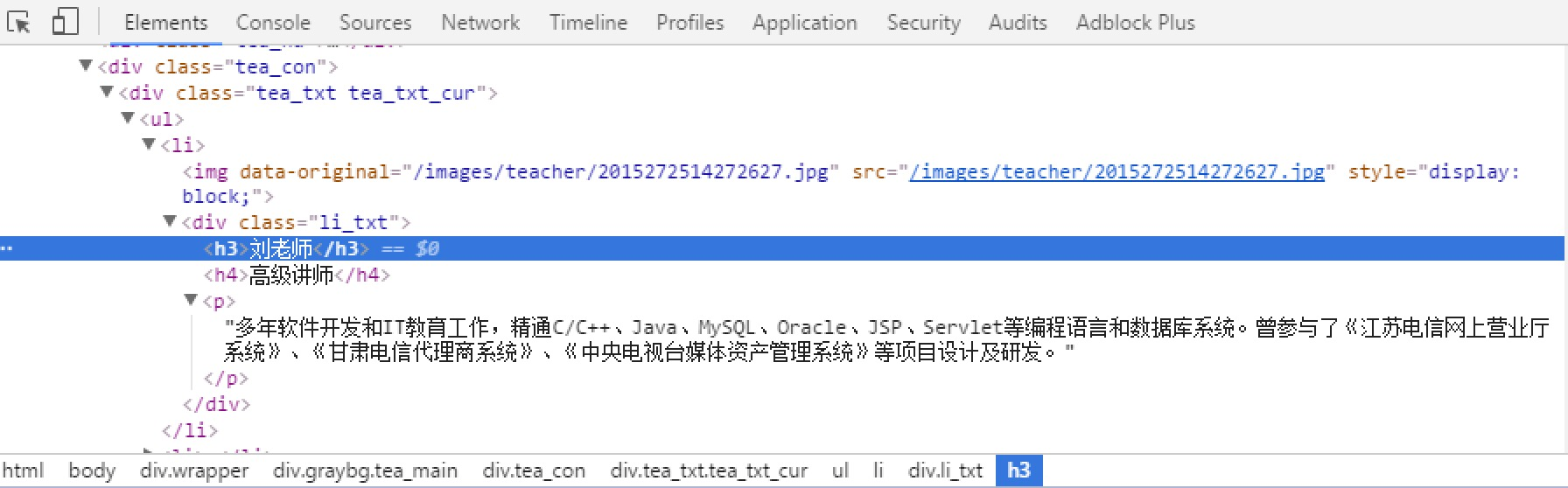
|
1
2
3
4
|
<div class="li_txt"> <h3> xxx </h3> <h4> xxx </h4> <p> xxxxx </p> |
则parse函数代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def parse(self, response): item = ItcastspiderItem() for each in response.xpath("//div[@class='li_txt']"): name = each.xpath("h3/text()").extract() level = each.xpath("h4/text()").extract() info = each.xpath("p/text()").extract() item["name"] = name[0].strip() item["level"] = level[0].strip() item["info"] = info[0].strip() yield item |
Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
验证爬取的数据(检查item包含某些字段,比如说name字段)
查重
将爬取结果保存到文件或者数据库中
编写item pipeline很简单,item pipeline组件是一个独立的Python类,其中process_item()方法必须实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
# -*- coding: utf-8 -*-# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.htmlimport jsonclass ItcastspiderPipeline(object): def __init__(self): self.file = open("传智教师.json", "w", encoding = "utf-8") self.first_flag = True def process_item(self, item, spider): if self.first_flag: self.first_flag = False content = "[\n" + json.dumps(dict(item), ensure_ascii = False) else: content = ",\n" + json.dumps(dict(item), ensure_ascii = False) self.file.write(content) return item def close_spider(self, spider): self.file.write("\n]") self.file.close() |
启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到settings.py文件ITEM_PIPELINES配置,就像下面这个例子:
|
1
2
3
4
5
|
# Configure item pipelines# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { 'itcastSpider.pipelines.ItcastspiderPipeline': 300,} |
分配组每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
启动爬虫
|
1
|
scrapy crawl teacher |
查看本地磁盘是有生成传智教师.json
爬虫——模拟点击动态页面
动态页面的模拟点击:
以斗鱼直播为例:http://www.douyu.com/directory/all
爬取每页的房间名、直播类型、主播名称、在线人数等数据,然后模拟点击下一页,继续爬取
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
#!/usr/bin/python3# -*- coding:utf-8 -*-__author__ = 'mayi'"""动态页面的模拟点击: 模拟点击斗鱼直播:http://www.douyu.com/directory/all 爬取每页房间名、直播类型、主播名称、在线人数等数据,然后模拟点击下一页,继续爬取"""from selenium import webdriverimport json# 调用环境变量指定的PhantomJS浏览器创建浏览器对象,executable_path:指定PhantomJS位置driver = webdriver.PhantomJS(executable_path = r"D:\Program Files\phantomjs\bin\phantomjs")from bs4 import BeautifulSoupclass DouyuSpider(object): """ 爬虫类 """ def __init__(self): self.url = "http://www.douyu.com/directory/all/" self.driver = webdriver.PhantomJS() self.file_name = open("douyu.json", "w", encoding = "utf-8") def run(self): """ 爬虫开始工作 """ self.driver.get(self.url) # 循环处理每一页,直至最后一页 page = 1 start_flag = True while True: # 等待3秒,防止访问过于频繁 self.driver.implicitly_wait(3) print("正在处理第" + page + "页......") page += 1 # 解析 soup = BeautifulSoup(self.driver.page_source, "lxml") # 在线直播部分 online_live = soup.find_all('ul', {'id': 'live-list-contentbox'})[0] # 房间列表 live_list = online_live.find_all('li') # 处理每一个房间 for live in live_list: # 房间名、直播类型、主播名称、在线人数 # 房间名 home_name = live.find_all('h3', {'class': 'ellipsis'})[0].get_text().strip() # 直播类型 live_type = live.find_all('span', {'class': 'tag ellipsis'})[0].get_text().strip() # 主播名称 anchor_name = live.find_all('span', {'class': 'dy-name ellipsis fl'})[0].get_text().strip() # 在线人数 online_num = live.find_all('span', {'class' :'dy-num fr'})[0].get_text().strip() # print(home_name, live_type, anchor_name, online_num) item = {} item["房间名"] = home_name item["直播类型"] = live_type item["主播名称"] = anchor_name item["在线人数"] = online_num if start_flag: start_flag = False content = "[\n" + json.dumps(item) else: content = ",\n" + json.dumps(item) self.file_name.write(content) # page_source.find()未找到内容则返回-1 if self.driver.page_source.find('shark-pager-disable-next') != -1: # 已到最后一页 break # 模拟点击下一页 self.driver.find_element_by_class_name('shark-pager-next').click() # 爬虫结束前关闭文件 self.file_name.write("\n]") self.file_name.close()if __name__ == '__main__': douyu = DouyuSpider() douyu.run() |
