Python爬虫爬取动态网页
Python爬虫爬取动态网页
我们经常会遇到直接把网页地址栏中的url传到get请求中无法直接获取到网页的数据的情况,而且右键查看网页源代码也无法看到网页的数据,同时点击第二页、第三页等进行翻页的时候,网页地址栏中的url也没变,这些就是动态网页,例如:http://www.neeq.com.cn/disclosure/supervise.html 。
解决办法:
对于动态网页抓取的关键是先分析网页数据获取和跳转的逻辑,再去写代码。接下来,将以上面的那个网页为例,介绍如何利用Python来爬取动态网页的数据。
1、分析网页数据请求和跳转的逻辑:
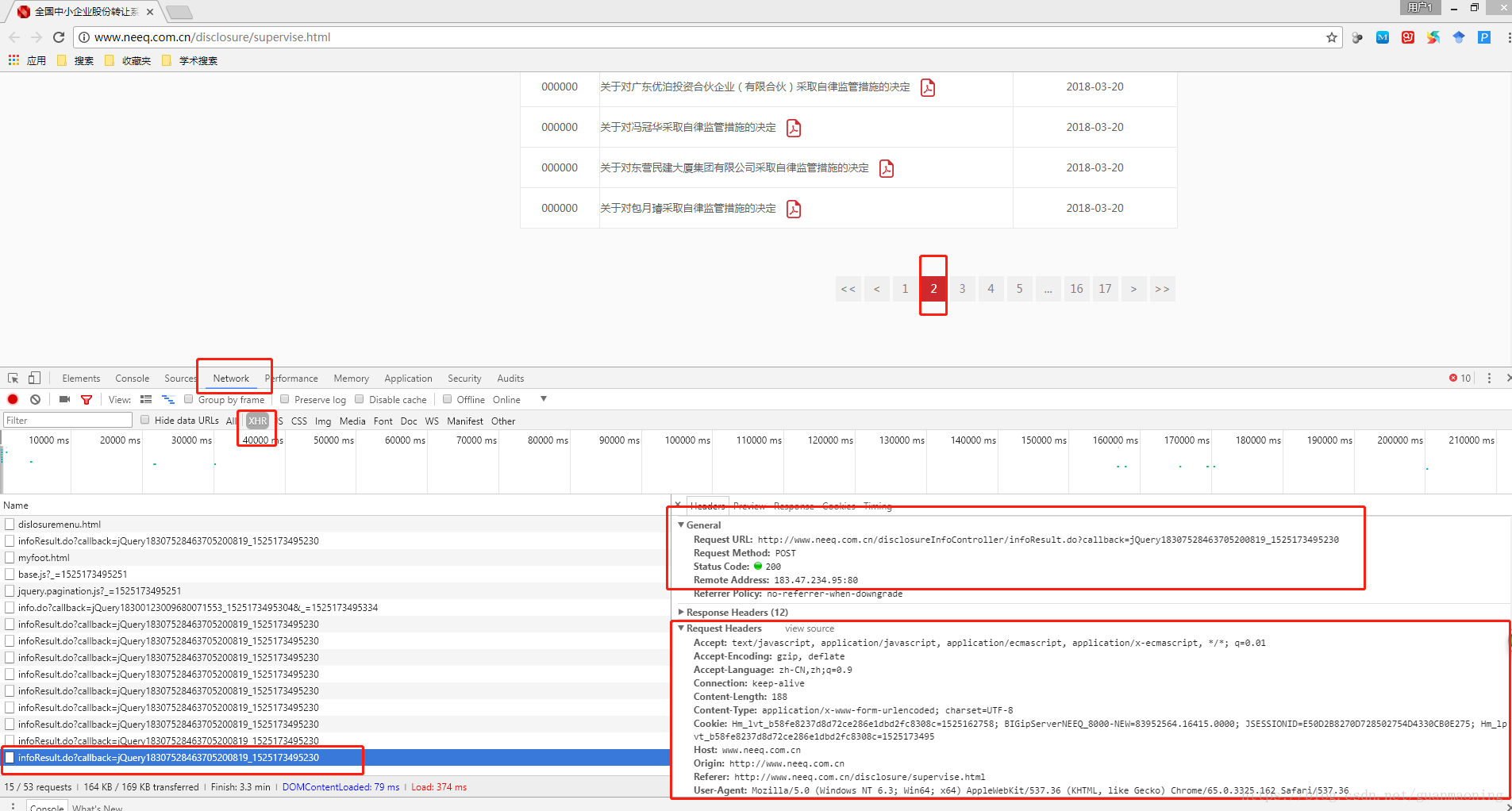
如上图所示,我们打开网页之后,按“F12”进入chrome浏览器的开发工具,点击“Network”->XHR(有时候是JS),然后我们点击上面的页面跳转栏的“2”跳转到第二页,然后我们可以看到开发工具左边的框里出现了一个新的请求,即左下图的最下面那一行(蓝色那条),我们用鼠标点击它,就可以在右边显示出该请求的headers的相关信息。在Headers中我们可以知道:Requests URL就是该网页真正请求的URL,而且由Request Method可以知道这是一个post请求,而下面的Request Headers就是该请求所需要设置的headers参数。因为这是一个post请求,所以我们要查看一下post请求提交了那些数据,所以我们可以在右边的Headers中继续往下拉来查看。
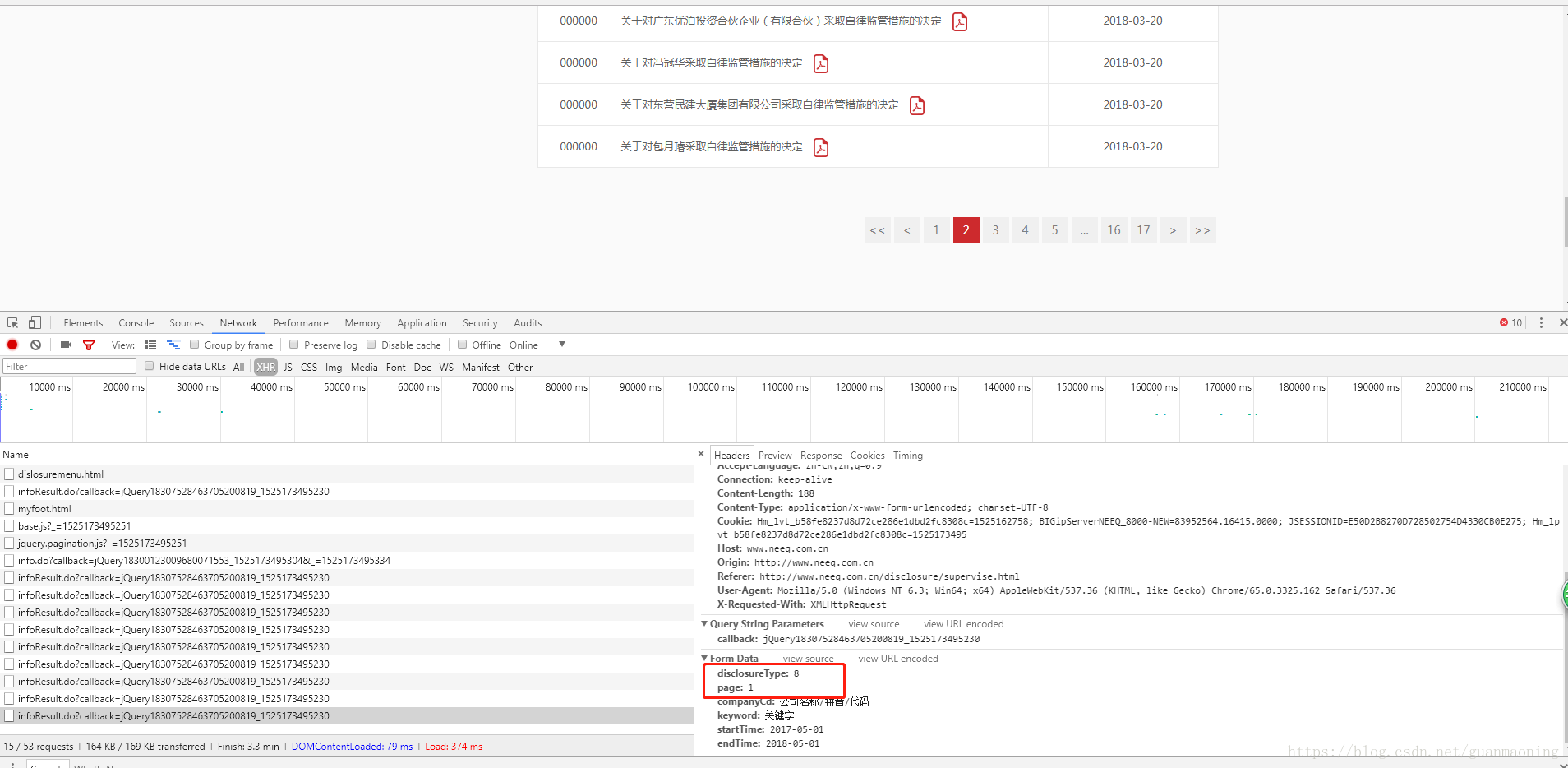
所以由上图的Form Data我们可以知道,post请求上传了两个关键的数据:disclosureType和page,到此我们就成功地分析了该动态网页数据请求和跳转的逻辑,接下来通过编程来实现爬取该网页的数据。
2、Coding:
-
# -*- coding: utf-8 -*-
-
"""
-
Created on Tue May 01 18:52:49 2018
-
-
@author: gmn
-
"""
-
#导入requests module
-
import requests
-
#导入random module
-
import random
-
#导入json module
-
import json
-
-
# =============================================================================
-
# 应对网站反爬虫的相关设置
-
# =============================================================================
-
#User-Agent列表,这个可以自己在网上搜到,用于伪装浏览器的User Agent
-
USER_AGENTS = [
-
"Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1"
-
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
-
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
-
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
-
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
-
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
-
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
-
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
-
"Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50",
-
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
-
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
-
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
-
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
-
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
-
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
-
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
-
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)",
-
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)",
-
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
-
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT)",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12 "
-
]
-
#IP地址列表,用于设置IP代理
-
IP_AGENTS = [
-
"http://58.240.53.196:8080",
-
"http://219.135.99.185:8088",
-
"http://117.127.0.198:8080",
-
"http://58.240.53.194:8080"
-
]
-
-
#设置IP代理
-
proxies={"http":random.choice(IP_AGENTS)}
-
-
-
# =============================================================================
-
# 上面的设置是为了应对网站的反爬虫,与具体的网页爬取无关
-
# =============================================================================
-
-
# =============================================================================
-
# 下面这些是根据刚才第一步的分析来设置的,所以下面需要按照第一步的分析来设置对应的参数。
-
# 根据第一步图片的右下角部分来设置Cookie、url、headers和post参数
-
# =============================================================================
-
#设置cookie
-
Cookie = "Hm_lvt_b58fe8237d8d72ce286e1dbd2fc8308c=1525162758; BIGipServerNEEQ_8000-NEW=83952564.16415.0000; JSESSIONID=E50D2B8270D728502754D4330CB0E275; Hm_lpvt_b58fe8237d8d72ce286e1dbd2fc8308c=1525165761"
-
#设置动态js的url
-
url = 'http://www.neeq.com.cn/disclosureInfoController/infoResult.do?callback=jQuery18307528463705200819_1525173495230'
-
#设置requests请求的 headers
-
headers = {
-
'User-agent': random.choice(USER_AGENTS), #设置get请求的User-Agent,用于伪装浏览器UA
-
'Cookie': Cookie,
-
'Connection': 'keep-alive',
-
'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
-
'Accept-Encoding': 'gzip, deflate',
-
'Accept-Language': 'zh-CN,zh;q=0.9',
-
'Host': 'www.neeq.com.cn',
-
'Referer': 'http://www.neeq.com.cn/disclosure/supervise.html'
-
}
-
#设置页面索引
-
pageIndex=0
-
#设置url post请求的参数
-
data={
-
'page':pageIndex,
-
'disclosureType':8
-
}
-
-
#requests post请求
-
req=requests.post(url,data=data,headers=headers,proxies=proxies)
-
print(req.content) #通过打印req.content,我们可以知道post请求返回的是json数据,而且该数据是一个字符串类型的
-
#获取包含json数据的字符串
-
#str_data=req.content
-
##获取json字符串数据
-
#str_json=str_data[8:-2]
-
#print(str_json)
-
##把json数据转成dict类型
-
#json_Info=json.loads(str_json)
运行结果如下:
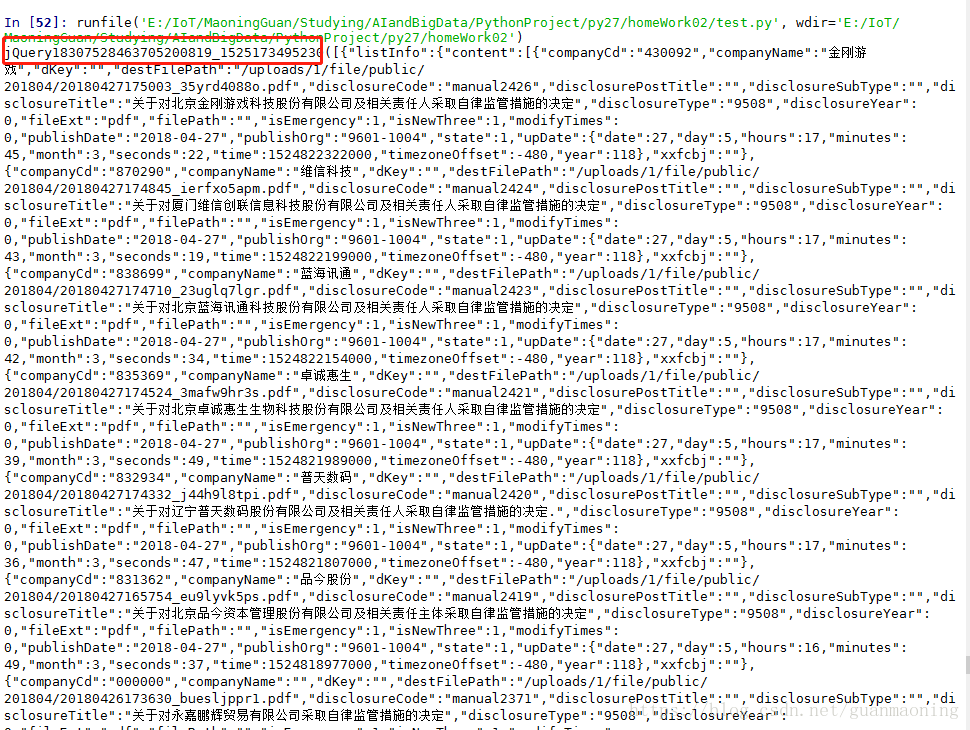
我们可以看到返回的数据req.content为json格式的数据,但是json数据的前面和后面分别是"jQuery18307528463705200819_1525173495230(["和"])",所以我们要去掉这两部分,留下中间的json格式的数据。在此之前,我们可以发现“jQuery18307528463705200819_1525173495230”就是我们的url参数“callback”的值,所以为了去掉jQuery后面的一大串数字,我们可以把“callback”的值改成“jQuery”(当然你也可以改成其他的值),所以url变为'http://www.neeq.com.cn/disclosureInfoController/infoResult.do?callback=jQuery',在此运行代码,可以得到:

而且我们发现req.content是一个字符串类型的数据,所以我们可以用:
-
#获取json字符串数据
-
str_json=str_data[8:-2]
来获取我们需要的中间的那部分json数据,此时代码如下:
-
# -*- coding: utf-8 -*-
-
"""
-
Created on Tue May 01 18:52:49 2018
-
-
@author: gmn
-
"""
-
#导入requests module
-
import requests
-
#导入random module
-
import random
-
#导入json module
-
import json
-
-
# =============================================================================
-
# 应对网站反爬虫的相关设置
-
# =============================================================================
-
#User-Agent列表,这个可以自己在网上搜到,用于伪装浏览器的User Agent
-
USER_AGENTS = [
-
"Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1"
-
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
-
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
-
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
-
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
-
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
-
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
-
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
-
"Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50",
-
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
-
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
-
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
-
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
-
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
-
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
-
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
-
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)",
-
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)",
-
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
-
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT)",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12 "
-
]
-
#IP地址列表,用于设置IP代理
-
IP_AGENTS = [
-
"http://58.240.53.196:8080",
-
"http://219.135.99.185:8088",
-
"http://117.127.0.198:8080",
-
"http://58.240.53.194:8080"
-
]
-
-
#设置IP代理
-
proxies={"http":random.choice(IP_AGENTS)}
-
-
-
# =============================================================================
-
# 上面的设置是为了应对网站的反爬虫,与具体的网页爬取无关
-
# =============================================================================
-
-
# =============================================================================
-
# 下面这些是根据刚才第一步的分析来设置的,所以下面需要按照第一步的分析来设置对应的参数。
-
# 根据第一步图片的右下角部分来设置Cookie、url、headers和post参数
-
# =============================================================================
-
#设置cookie
-
Cookie = "Hm_lvt_b58fe8237d8d72ce286e1dbd2fc8308c=1525162758; BIGipServerNEEQ_8000-NEW=83952564.16415.0000; JSESSIONID=E50D2B8270D728502754D4330CB0E275; Hm_lpvt_b58fe8237d8d72ce286e1dbd2fc8308c=1525165761"
-
#设置动态js的url
-
url = 'http://www.neeq.com.cn/disclosureInfoController/infoResult.do?callback=jQuery'
-
#设置requests请求的 headers
-
headers = {
-
'User-agent': random.choice(USER_AGENTS), #设置get请求的User-Agent,用于伪装浏览器UA
-
'Cookie': Cookie,
-
'Connection': 'keep-alive',
-
'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
-
'Accept-Encoding': 'gzip, deflate',
-
'Accept-Language': 'zh-CN,zh;q=0.9',
-
'Host': 'www.neeq.com.cn',
-
'Referer': 'http://www.neeq.com.cn/disclosure/supervise.html'
-
}
-
#设置页面索引
-
pageIndex=0
-
#设置url post请求的参数
-
data={
-
'page':pageIndex,
-
'disclosureType':8
-
}
-
-
#requests post请求
-
req=requests.post(url,data=data,headers=headers,proxies=proxies)
-
#print(req.content) #通过打印req.content,我们可以知道post请求返回的是json数据,而且该数据是一个字符串类型的
-
#获取包含json数据的字符串
-
str_data=req.content
-
#获取json字符串数据
-
str_json=str_data[8:-2]
-
print(str_json)
-
#把json数据转成dict类型
-
#json_Info=json.loads(str_json)
运行结果如下:

我们把str_json打印出来的字符串复制粘贴到网上的json在线解析工具来分析该数据的规律,结果如下:
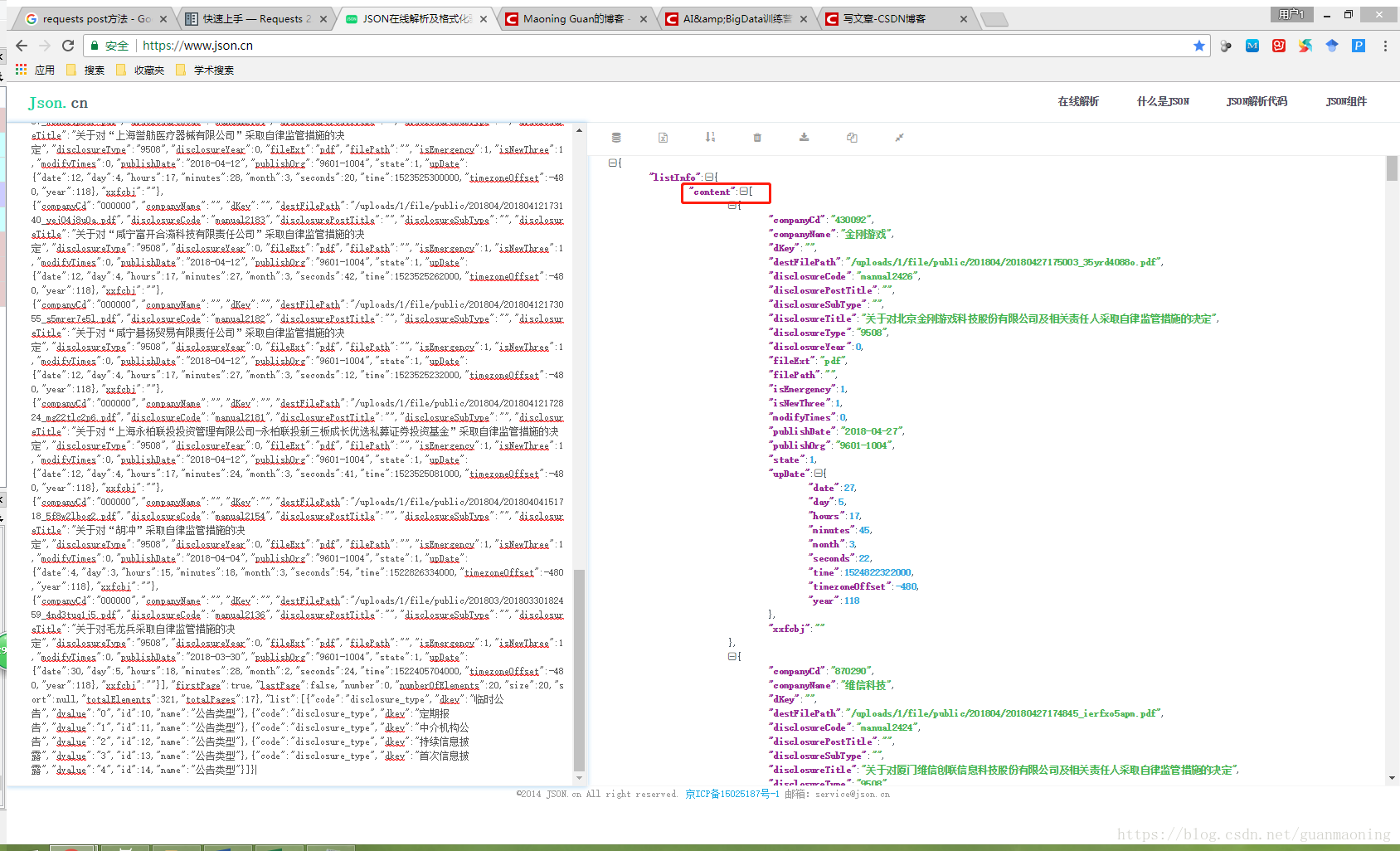
由右图,我们可以发现json数据的规律。接下来,我们先把str_json转成dict字典类型的数据:
-
#把json数据转成dict类型
-
json_Info=json.loads(str_json)
然后就可以通过字典数据的相关操作来获取网页的相关数据了。
完整代码如下:
-
# -*- coding: utf-8 -*-
-
"""
-
Created on Tue May 01 18:52:49 2018
-
-
@author: gmn
-
"""
-
#导入requests module
-
import requests
-
#导入random module
-
import random
-
#导入json module
-
import json
-
-
# =============================================================================
-
# 应对网站反爬虫的相关设置
-
# =============================================================================
-
#User-Agent列表,这个可以自己在网上搜到,用于伪装浏览器的User Agent
-
USER_AGENTS = [
-
"Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1"
-
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
-
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
-
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
-
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
-
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
-
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
-
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
-
"Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50",
-
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
-
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
-
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
-
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
-
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
-
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
-
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
-
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)",
-
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)",
-
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
-
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT)",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3",
-
"Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12 "
-
]
-
#IP地址列表,用于设置IP代理
-
IP_AGENTS = [
-
"http://58.240.53.196:8080",
-
"http://219.135.99.185:8088",
-
"http://117.127.0.198:8080",
-
"http://58.240.53.194:8080"
-
]
-
-
#设置IP代理
-
proxies={"http":random.choice(IP_AGENTS)}
-
-
-
# =============================================================================
-
# 上面的设置是为了应对网站的反爬虫,与具体的网页爬取无关
-
# =============================================================================
-
-
# =============================================================================
-
# 下面这些是根据刚才第一步的分析来设置的,所以下面需要按照第一步的分析来设置对应的参数。
-
# 根据第一步图片的右下角部分来设置Cookie、url、headers和post参数
-
# =============================================================================
-
#设置cookie
-
Cookie = "Hm_lvt_b58fe8237d8d72ce286e1dbd2fc8308c=1525162758; BIGipServerNEEQ_8000-NEW=83952564.16415.0000; JSESSIONID=E50D2B8270D728502754D4330CB0E275; Hm_lpvt_b58fe8237d8d72ce286e1dbd2fc8308c=1525165761"
-
#设置动态js的url
-
url = 'http://www.neeq.com.cn/disclosureInfoController/infoResult.do?callback=jQuery'
-
#设置requests请求的 headers
-
headers = {
-
'User-agent': random.choice(USER_AGENTS), #设置get请求的User-Agent,用于伪装浏览器UA
-
'Cookie': Cookie,
-
'Connection': 'keep-alive',
-
'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
-
'Accept-Encoding': 'gzip, deflate',
-
'Accept-Language': 'zh-CN,zh;q=0.9',
-
'Host': 'www.neeq.com.cn',
-
'Referer': 'http://www.neeq.com.cn/disclosure/supervise.html'
-
}
-
#设置页面索引
-
pageIndex=0
-
#设置url post请求的参数
-
data={
-
'page':pageIndex,
-
'disclosureType':8
-
}
-
-
#requests post请求
-
req=requests.post(url,data=data,headers=headers,proxies=proxies)
-
#print(req.content) #通过打印req.content,我们可以知道post请求返回的是json数据,而且该数据是一个字符串类型的
-
#获取包含json数据的字符串
-
str_data=req.content
-
#获取json字符串数据
-
str_json=str_data[8:-2]
-
#print(str_json)
-
#把json数据转成dict类型
-
json_Info=json.loads(str_json)
注意事项:
有时候我们按照以上步骤,仍然难以准确的找到数据访问的URL的时候,可以考虑使用selenium + 浏览器driver (如:chromedriver)的方式来爬取动态网页

 浙公网安备 33010602011771号
浙公网安备 33010602011771号