

优秀的 Java 爬虫项目?
优秀的 Java 爬虫项目?
GitHub 上有哪些优秀的 Java 爬虫项目?
1.webporter
star:2.1k
webporter 是一个基于垂直爬虫框架webmagic的 Java 爬虫应用,旨在提供一套完整的数据爬取,持久化存储和可视化展示的实践样例。
目前提供了知乎用户数据的爬虫示例,作者还在不定时进行调整和补充。
2.XueQiuSuperSpider
star:1.1k
股票信息的超级爬虫。雪球网、东方财富、同花顺目前已经提供了很多种股票筛选方式,但是筛选方式是根据个人操作风格来定义的,三个网站有限的筛选方式显然不能满足广大股民、程序员特别是数据分析控的要求。
而XueQiuSuperSpider是一个可以任意拓展,实现任意数据搜集与分析的爬虫程序。
3.gecco
star:1.8k
Gecco是使用Java语言开发的易于使用的轻量级Web爬虫。使用Geccointegriert jsoup,httpclient,fastjson,spring,htmlunit,redission ausgezeichneten框架,配置多个jQuery样式选择器就可以快速地编写爬虫了。
4.SeimiCrawler
star:1.5k
SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架。能降低新手开发一个替代高且性能不差的爬虫系统的门性能,并提高开发爬虫系统的开发效率。
在设计思想上受Python的爬虫框架Scrapy启发,同时融合了Java语言本身的特点。
5.电影推荐系统
star:1.1k
这个项目是基于大数据过滤引擎的电影推荐系统,包含爬虫,电影网站(前端和对准),后台管理系统以及推荐系统(Spark)。
6.spring-boot-quick
star:1.1k
基于springboot的快速学习示例,还整合了一些开源框架,如:rabbitmq(延迟队列)、Kafka、jpa、redies、oauth2、swagger、jsp、docker、spring-batch、异常处理、日志输出、多模块开发、多环境打包、缓存cache、爬虫、jwt、dubbo和Async等等。
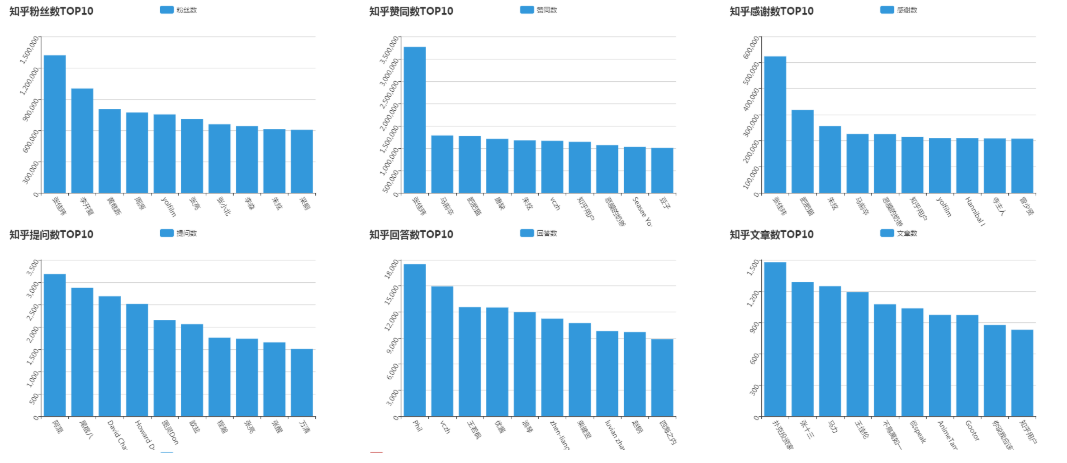
7.知乎crawler
一个基于Java的高性能,免费HTTP代理池,支持横向扩展,分布式抓取爬虫项目。主要功能是抓取知乎用户,主题,问题,答案,文章等数据。比如:
8.FreeBook
基于MVP模式开发的带缓存网络爬虫,采用最流行框架构造,可以免费下载电子书,非常适合准备毕业设计的同学~
最后,提醒大家,如果你没有打好Java基础,这些爬虫项目做起来会比较难。在做之前,你可以再去学习一遍Java基础,以达到事半功倍的效果:
戳链接免费试听后加微信jiuzhangsuanfa5,发送课程试听截图+【知乎Java】,还能免费获取Java大礼包哟~


更多回答
github地址:xtuhcy/gecco
Gecco是一款用java语言开发的轻量化的易用的网络爬虫。整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器就能很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对修改关闭、对扩展开放。
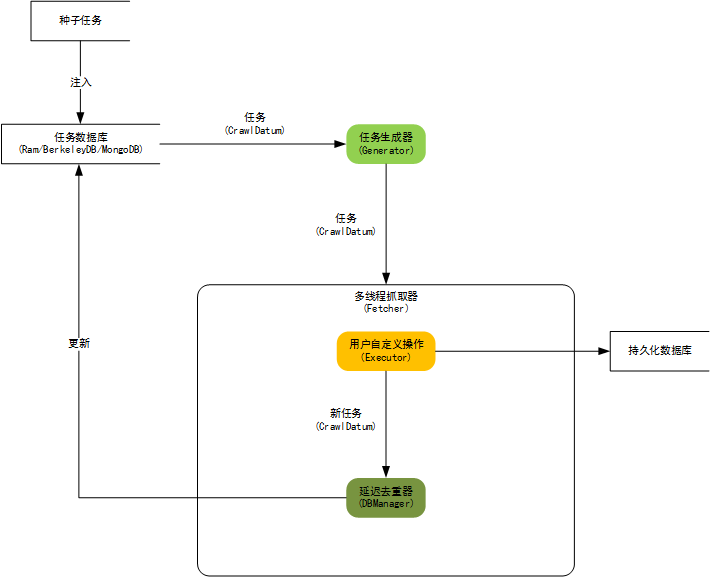
2、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
3、Spiderman
码云地址:l-weiwei/Spiderman2 - 码云 - 开源中国
使用案例:展现垂直爬虫的能力 - 像风一样自由
Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。
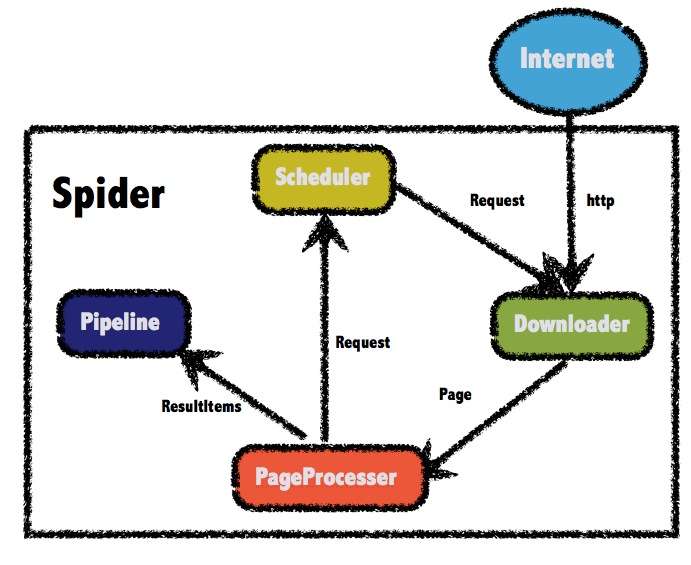
4、WebMagic
码云地址:flashsword20/webmagic - 码云 - 开源中国
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
5、Heritrix
github地址:internetarchive/heritrix3
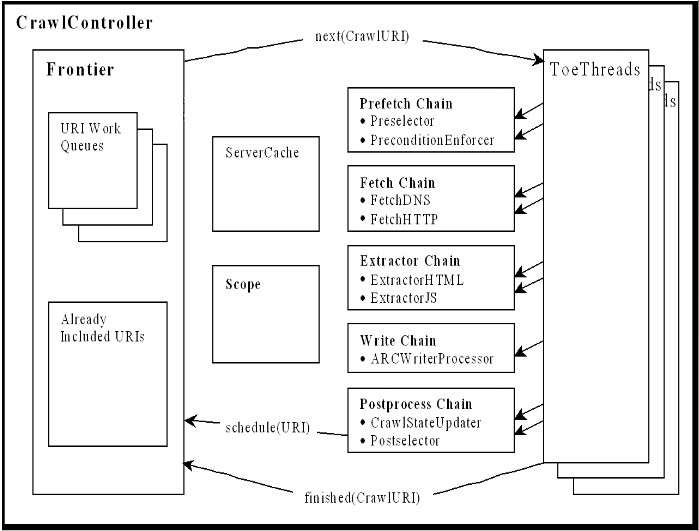
6、crawler4j
github地址:yasserg/crawler4j · GitHub
crawler4j是Java实现的开源网络爬虫。提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫。
1.nutch
地址:apache/nutch · GitHub
apache下的开源爬虫程序,功能丰富,文档完整。有数据抓取解析以及存储的模块。而且这玩意儿还包括了一个开箱即用的搜索引擎,安装好就可以搜索了。
2.Heritrix
地址:internetarchive/heritrix3 · GitHub
很早就有了,经历过很多次更新,使用的人比较多,功能齐全,文档完整,网上的资料也多。有自己的web管理控制台,包含了一个HTTP 服务器。操作者可以通过选择Crawler命令来操作控制台。
3.crawler4j
地址:yasserg/crawler4j · GitHub
因为只拥有爬虫的核心功能,所以上手极为简单,几分钟就可以写一个多线程爬虫程序。
当然,上面说的nutch有的功能比如数据存储不代表Heritrix没有,反之亦然。具体使用哪个合适还需要仔细阅读文档并配合实验才能下结论啊~
还有比如JSpider,WebEater,Java Web Crawler,WebLech,Ex-Crawler,JoBo等等,这些没用过,不知道。。
