python 构建一个聊天机器人
ChatOps可以让你使用基于聊天的接口来管理DevOps任务。本文主要让我们了解如何使用Slack构建一个简单的机器人来控制Kubernetes集群。最后我们可以使用Slack聊天消息查看Kubernetes日志和信息。不需要Kubernetes的先验知识,也不需要Slack API。
那么,首先我们来探索一下什么是ChatOps。
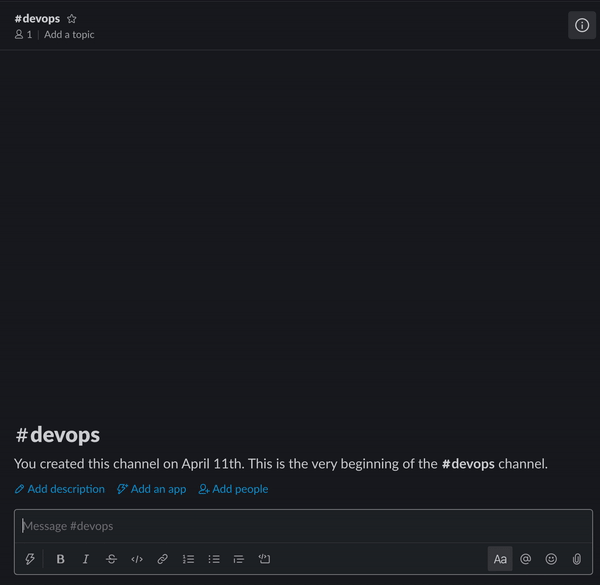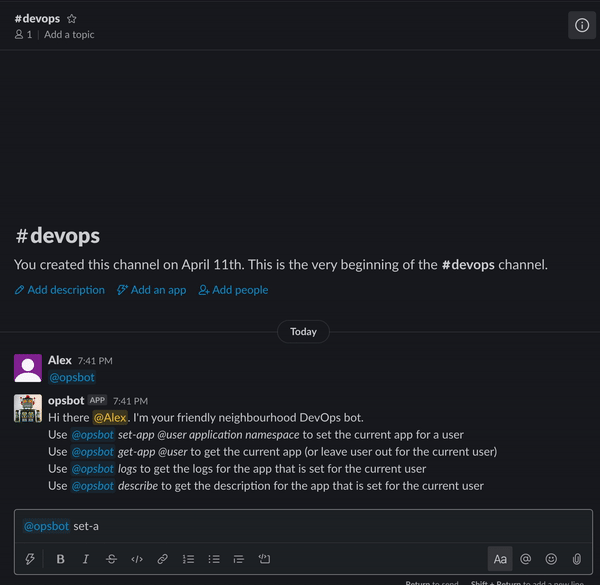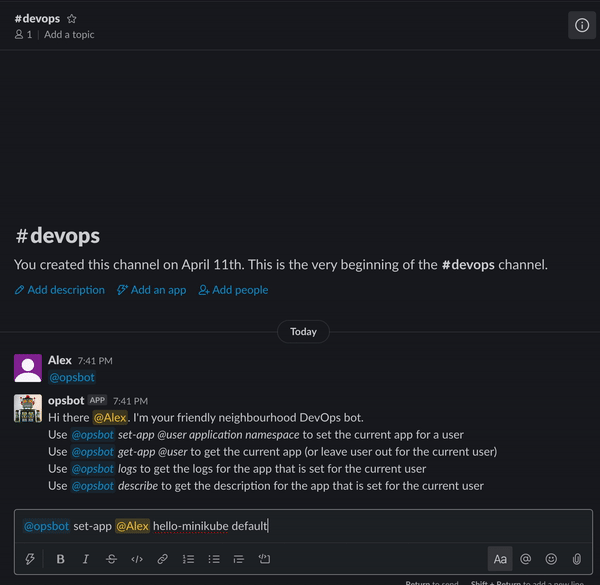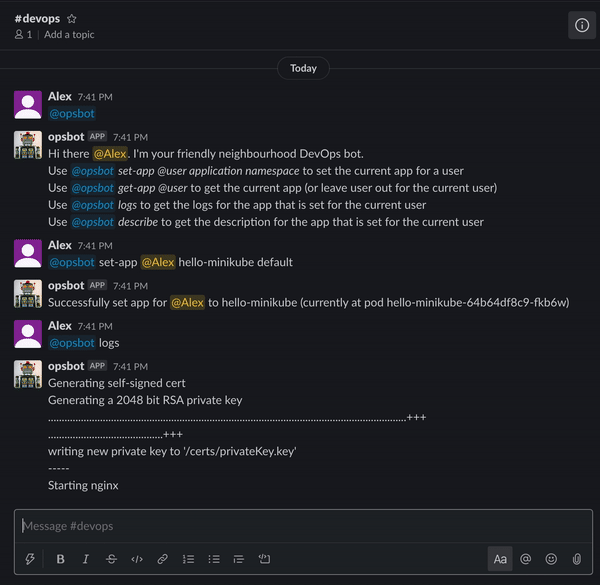
什么是ChatOps
ChatOps是一种使用聊天消息执行DevOps任务的方式,例如部署、监视和系统管理。例如,将日志消息发送到聊天机器人会检索最新的日志消息,或者可以从聊天消息触发部署。
下面描述了一些重要的优点:
与机器人聊天,这是一种非常人性化的方法来管理基础结构。 @chatbot日志比kubectl日志hello-minikube-64b64df8c9-fkb6w -ndefault更容易理解。它可以是共享聊天的一部分,以便人们可以协作和共享信息。这也提供了已执行命令和动作的记录。它可以帮助安全地克服网络和防火墙的限制,使在家中或旅途中工作成为可能。通过DevOps工具的统一接口,使用相同的接口管理Kubernetes和OpenShift它可以简化和保护基础设施的任务,因此开发人员可以自行完成。
设置
本文介绍了使用以下方法构建最小的聊天机器人:
Minikube作为Kubernetes环境。Kubernetes被标记为“生产级容器编排”。 Kubernetes允许我们部署、管理和扩展Docker映像。Minikube是用于在开发机器上运行Kubernetes的集成解决方案。Slack作为聊天服务器。Python来实现实际的ChatOps服务器。
Minikube
为了在开发机器上快速运行Kubernetes,Minikube在单个虚拟机映像中实现了Kubernetes集群。你可以在此处找到详细的安装说明:
https://kubernetes.io/docs/setup/learning-environment/minikube/#installation
作者要将其安装在自己的macOs系统上,并使用VirtualBox作为虚拟化驱动程序。你可以在这里找到VirtualBox:https://www.virtualbox.org/wiki/Downloads
安装VirtualBox之后,可以使用以下命令将Minikube安装在macO上。它还将部署一个示例应用程序。这里假设你已安装了homebrew软件:https://brew.sh/。
brew install minikube # install via Homebrew
minikube start - driver=virtualbox # start and use Virtualbox
kubectl create deployment hello-minikube-image=k8s.gcr.io/echoserver:1.10 # install sample app
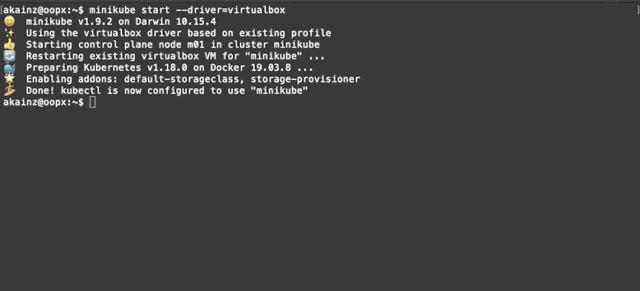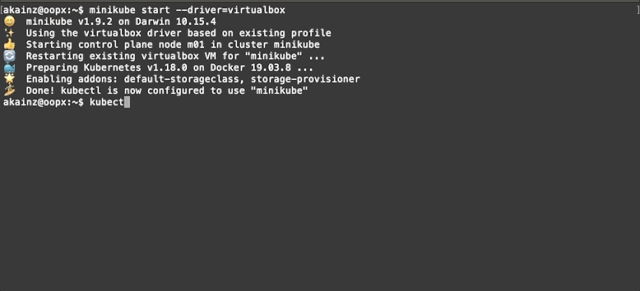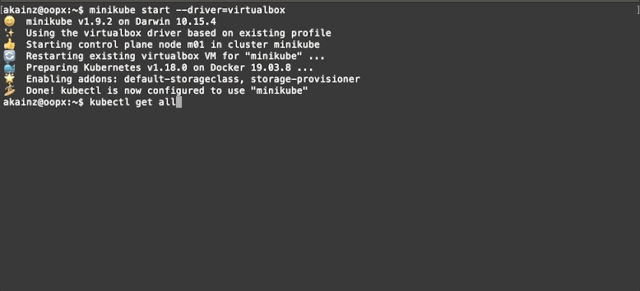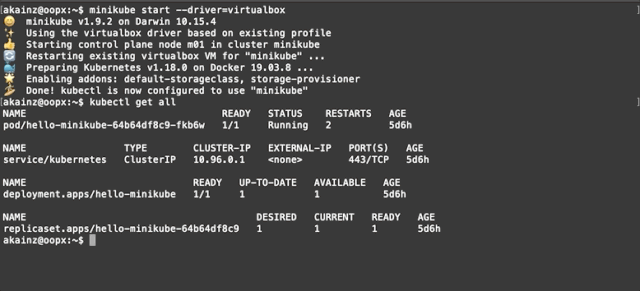
要验证安装使用,请执行以下操作:kubectl get all,结果应显示示例pod,比如pod / hello-minikube-64b64df8c9-fkb6w。
Kubernetes的简要介绍
Kubernetes是一款允许在集群中管理docker映像的软件。这包括部署、扩展、管理和监视。基本部署单元是Pod。Pod可以包含多个docker映像或容器。我们将在本文中开发的聊天机器人仅支持具有单个图像的pod。可以通过kubectl命令和其他方式控制Kubernetes。
我们的服务器将使用以下Kubernetes命令:
kubectl get pods --selector=app={app} --namespace={namespace} :在名称空间中检索应用程序的pod。
kubectl logs {pod} --namespace={namespace}:获取容器中容器的日志(如果容器中只有一个图像)。
kubectl describe pod {pod} --namespace={namespace} :描述有关Pod的详细信息。
Slack
如果你没有Slack帐户,则可以通过https://slack.com 获得自己的工作区。
在本文中,我们将创建一个所谓的经典App,以便能够使用实时消息(RTM)API。
你可以在此处创建经典应用:https://api.slack.com/apps?new_classic_app=1。确保不要只是创建一个新的Slack App,因为它不支持实时消息。
该App将需要以下范围,bot和chat:write:bot。如果找不到这些范围,则可能是在最后一步中创建了一个非经典应用。
我们将为该应用添加说明和图标。对于作者的机器人,他正在使用Wikimedia的图像。
最后一步是将app安装到工作区并记下机器人令牌,单击“将应用程序安装到团队”。我们将允许该APP访问我们的工作区,并记下“ Bot User OAuth Access Token”。
ChatOps服务器
可以在https://gitlab.com/alexk/chatops-kubernetes上找到服务器的代码。它需要python 3,例如可以在macO上使用brew install python3安装。
然后下载并安装需求:
git clone git@gitlab.com:alexk/chatops-kubernetes.git
cd chatops-kubernetes/
pip3 install -r requirements.txt
然后将Slack令牌设置为与之一起使用:
export SLACK_API_TOKEN=<Your Slack token starts with xoxb-…>
并使用以下命令启动聊天机器人服务器:
python3 chatbot.py
实现服务器
如设置部分所述,我们将使用Slack中的实时消息传递功能。要使用此功能,我们必须创建一个经典App。
使用WebSocket的经典Slack App实时消息传递模型
在当前的Slack应用程序模型中,Slack针对每个聊天消息或命令将HTTP Post消息发送到chatbot服务器。
使用HTTP POSTS的现代Slack应用模型
但是,在ChatOps的背景下,经典的应用程序允许我们使用WebSockets连接到Slack。我们的聊天机器人服务器将对Slack端点使用HTTP GET调用。 Slack服务器将保持连接打开并向我们的聊天机器人流更新。
这意味着我们不需要在DevOps基础架构上打开传入的端点。相反,我们将使用传出连接。
由于ChatOps服务器通常会以提升的权限运行,因此很难向外界端口开放。通过使用经典的App和websockets连接,我们为网络犯罪分子关闭了另一个攻击角度。
服务器将支持4个命令:
set-app为用户设置应用程序。因此,我们不必在每次使用其他命令时都提供应用程序名称。一种简单的安全访问方法是仅允许管理员用户执行此命令。
get-app为用户获取应用程序。
logs和describe用来检索所选应用程序的窗格上的日志和信息。
要存储选定的应用程序,我们将在db.py模块中使用嵌入式sqllite3数据库。
主事件循环如下所示:
@RTMClient.run_on(event="message") # subscribe to 'message' events
def process_command(**payload):
data = payload['data']
web_client = payload['web_client']
print(payload)
# ignore service messages, like joining a channel
is_service = 'subtype' in data and data['subtype'] is not None
if not is_service and 'text' in data:
channel_id = data['channel']
thread_ts = data['ts']
user = data['user']
text = data['text'] # get data from the event
tokens = text.split # split it up by space characters
me = tokens[0] # user id of the cht bot
# object to track the conversation state
conv = Conversation(web_client, channel_id, user)
if len(tokens) > 1:
print(tokens)
# first token is my userid, second will be the command e.g. logs
command = tokens[1]
print('received command ' + command)
if command in commands:
# get the actual command executor
command_func = commands[command]
try:
args = tokens[slice(2, len(tokens))]
# execute the command
result = command_func(conv, args)
if result is not None:
# and return the value from the
# command back to the user
conv.msg(result)
except Exception as e:
conv.msg(str(e))
else:
# show welcome message
web_client.chat_postMessage(
conv.msg(welcome.format(user=user, me=me))
)
else:
# show welcome message
conv.msg(welcome.format(user=user, me=me)
它使用@ RTMClient.run_on(event =” message”)进行注释,每次在当前聊天中发送消息时,Python Slack客户端都会调用该方法。
为了确保我们没有收到自己的消息,也没有服务消息(“…已经加入了对话”),我们使用这一行代码:
is_service = ‘subtype’ in data and data[‘subtype’] is not None 收到消息后,我们将其转换为令牌并获取每个命令的实际处理程序,然后单个命令将解析传入的参数。例如。 set-app命令会将应用程序存储在用户数据库中,以供用户使用。为了实现这一点,我们使用os.popen(cmd):
def logs(pod, namespace):
cmd = f'kubectl logs {pod} --namespace={namespace}'
print(f'Executing {cmd}')
stream = os.popen(cmd)
return stream.read
结论
使用Slack客户端支持的实时消息API,我们能够构建一个执行kubernetes命令的简单聊天机器人。也可以使用Slack中的现代POST事件来构建ChatBots。
让它能够成为ChatOps机器人的下一步是通过建立授权模型来提高安全性。当编排多个DevOps工具时,可能需要实现一个DevOps API,该API处理实际的编排并提供一个公共接口。然后可以使用该接口来构建多通道DevOps工具集,例如,可以由仪表板和ChatOps使用。
原文链接:https://hackernoon.com/how-to-build-a-chatops-bot-with-slack-and-kubernetes-3r2b3yjr
360金融首席科学家张家兴:别指望AI Lab做成中台用 Python 实现手机自动答题,这下百万答题游戏谁也玩不过我!黑客用上机器学习你慌不慌?这 7 种窃取数据的新手段快来认识一下关于 Docker ,你必须了解的核心都在这里了!5分钟!就能学会以太坊 JSON API 基础知识
对于机器学习模型的离线训练,很多同学已经非常熟悉,无论是TensorFlow,PyTorch,还是传统一点的Spark MLlib都提供了比较成熟的离线并行训练环境。但机器学习模型终究是要在线上环境进行inference的,如何将离线训练好的模型部署于线上的生产环境,进行线上实时的inference,其实一直是业界的一个难点。这里跟大家讨论一下几种可行的机器学习模型线上serving的方法。
一、自研平台
无论是在五六年前深度学习刚兴起的时代,还是TensorFlow,PyTorch已经大行其道的今天,自研机器学习训练与上线的平台仍然是很多大中型公司的重要选项。
为什么放着灵活且成熟的TensorFlow不用,而要从头到尾进行模型和平台自研呢?重要的原因是由于TensorFlow等通用平台为了灵活性和通用性支持大量冗余的功能,导致平台过重,难以修改和定制。而自研平台的好处是可以根据公司业务和需求进行定制化的实现,并兼顾模型serving的效率。笔者在之前的工作中就曾经参与过FTRL和DNN的实现和线上serving平台的开发。由于不依赖于任何第三方工具,线上serving过程可以根据生产环境进行实现,比如采用Java Server作为线上服务器,那么上线FTRL的过程就是从参数服务器或内存数据库中得到模型参数,然后用Java实现模型inference的逻辑。
但自研平台的弊端也是显而易见的,由于实现模型的时间成本较高,自研一到两种模型是可行的,但往往无法做到数十种模型的实现、比较、和调优。而在模型结构层出不穷的今天,自研模型的迭代周期过长。因此自研平台和模型往往只在大公司采用,或者在已经确定模型结构的前提下,手动实现inference过程的时候采用。
二、预训练embedding+轻量级模型
完全采用自研模型存在工作量大和灵活性差的问题,在各类复杂模型演化迅速的今天,自研模型的弊端更加明显,那么有没有能够结合通用平台的灵活性、功能的多样性,和自研模型线上inference高效性的方法呢?答案是肯定的。
现在业界的很多公司其实采用了“复杂网络离线训练,生成embedding存入内存数据库,线上实现LR或浅层NN等轻量级模型拟合优化目标”的上线方式。百度曾经成功应用的“双塔”模型是非常典型的例子(如图1)。
图1 百度的“双塔”模型
百度的双塔模型分别用复杂网络对“用户特征”和“广告特征”进行了embedding化,在最后的交叉层之前,用户特征和广告特征之间没有任何交互,这就形成了两个独立的“塔”,因此称为双塔模型。
在完成双塔模型的训练后,可以把最终的用户embedding和广告embedding存入内存数据库。而在线上inference时,也不用复现复杂网络,只需要实现最后一层的逻辑,在从内存数据库中取出用户embedding和广告embedding之后,通过简单计算即可得到最终的预估结果。
同样,在graph embedding技术已经非常强大的今天,利用embedding离线训练的方法已经可以融入大量user和item信息。那么利用预训练的embedding就可以大大降低线上预估模型的复杂度,从而使得手动实现深度学习网络的inference逻辑成为可能。
三、PMML
Embedding+线上简单模型的方法是实用却高效的。但无论如何还是把模型进行了割裂。不完全是End2End训练+End2End部署这种最“完美”的形式。有没有能够在离线训练完模型之后,直接部署模型的方式呢?本小节介绍一种脱离于平台的通用的模型部署方式PMML。
PMML的全称是“预测模型标记语言”(Predictive Model Markup Language, PMML)。是一种通用的以XML的形式表示不同模型结构参数的标记语言。在模型上线的过程中,PMML经常作为中间媒介连接离线训练平台和线上预测平台。
这里以Spark mllib模型的训练和上线过程为例解释PMML在整个机器学习模型训练及上线流程中扮演的角色(如图2)。
图2 Spark模型利用PMML的上线过程
图2中的例子使用了JPMML作为序列化和解析PMML文件的library。JPMML项目分为Spark和Java Server两部分。Spark部分的library完成Spark MLlib模型的序列化,生成PMML文件并保存到线上服务器能够触达的数据库或文件系统中;Java Server部分则完成PMML模型的解析,并生成预估模型,完成和业务逻辑的整合。
由于JPMML在Java Server部分只进行inference,不用考虑模型训练、分布式部署等一系列问题,因此library比较轻,能够高效的完成预估过程。与JPMML相似的开源项目还有Mleap,同样采用了PMML作为模型转换和上线的媒介。
事实上,JPMML和MLeap也具备sk-learn,TensorFlow简单模型的转换和上线能力。但针对TensorFlow的复杂模型,PMML语言的表达能力是不够的,因此上线TensorFlow模型就需要TensorFlow的原生支持——TensorFlow Serving。
四、TensorFlow Serving等原生serving平台
TensorFlow Serving 是TensorFlow推出的原生的模型serving服务器。本质上讲TensorFlow Serving的工作流程和PMML类的工具的流程是一致的。不同之处在于TensorFlow定义了自己的模型序列化标准。利用TensorFlow自带的模型序列化函数可将训练好的模型参数和结构保存至某文件路径。
TensorFlow Serving最普遍也是最便捷的serving方式是使用Docker建立模型Serving API。在准备好Docker环境后,仅需要pull image即可完成TensorFlow Serving环境的安装和准备:
docker pull tensorflow/serving
在启动该docker container后,也仅需一行命令就可启动模型的serving api:
tensorflow_model_server --port=8500 --rest_api_port=8501 \
--model_name=${MODEL_NAME} --model_base_path=${MODEL_BASE_PATH}/${MODEL_NAME}
这里仅需注意之前保存模型的路径即可。
当然,要搭建一套完整的TensorFlow Serving服务并不是一件容易的事情,因为其中涉及到模型更新,整个docker container集群的维护和按需扩展等一系例工程问题;此外,TensorFlow Serving的性能问题也仍被业界诟病。但Tensorflow Serving的易用性和对复杂模型的支持仍使其是上线TensorFlow模型的第一选择。
除了TensorFlow Serving之外,Amazon的Sagemaker,H2O.ai的H2O平台都是类似的专业用于模型serving的服务。平台的易用性和效率都有保证,但都需要与离线训练平台进行绑定,无法做到跨平台的模型迁移部署。
五、TensorFlow Serving的二次开发
TensorFlow Serving的效率问题其实一直是被业界诟病的主要问题。因此很多团队为了提高线上inference效率,采取了剥离TensorFlow Serving主要逻辑,去除冗余功能和步骤等方法,对TensorFlow Serving进行二次开发,与自己的server环境做融合。
@Stark Einstein 同学在专栏的留言中也提到,他们组的模型上线过程就是把TensorFlow Serving的主要逻辑拆出来,融合到其原有的C++服务中去,成功提高了整体服务的效率。
总结
机器学习模型的线上serving问题是非常复杂的工程问题,因为其与公司的线上服务器环境、硬件环境、离线训练环境、数据库/存储系统都有非常紧密的联系。正因为这样,各家采取的方式也都各不相同。可以说在这个问题上,即使本文已经列出了5种主要的上线方法,但也无法囊括所有业界的推荐模型上线方式。甚至于在一个公司内部,针对不同的业务场景,模型的上线方式也都不尽相同。
因此,作为一名算法工程师,除了应对主流的模型部署方式有所了解之外,还应该针对公司客观的工程环境进行综合权衡后,给出最适合的解决方案。
最后欢迎大家关注我的微信公众号:王喆的机器学习笔记(wangzhenotes),跟踪计算广告、推荐系统等机器学习领域前沿。
想进一步交流的同学也可以通过公众号加我的微信一同探讨技术问题,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号