
数据结构-哈希表
哈希表结构
在python中,常见的两种基础数据结构字典和集合都是用哈希表实现的
哈希表是一个通过哈希函数来计算数据存储位置的数据结构
通常支持以下操作:
- 插入键值对 insert(key,value)
- 根据键获取值 get(key)
- 删除键值对 delete(key)
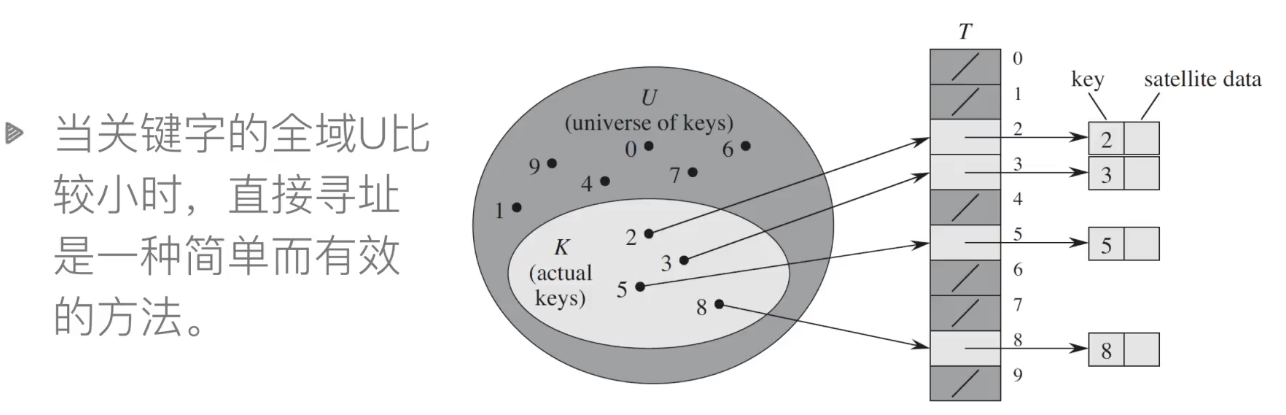
直接寻址表
把key为k的元素放到下标为k的位置上
直接寻址技术存在以下缺点:
- 当域U很大时,需要消耗大量内存
- U很大而实际出现的key很少,会浪费大量的空间
- 无法处理关键字不是数字的情况
改进直接寻址表:+哈希函数 = 哈希表
- 构建大小为m的寻址表T
- key为k的元素放到h(k)的位置上
- h(k)就是一个哈希函数,将域U映射到表T[0,..m-1]上
哈希表(Hash Table)
又称散列表,是一种线性表的存储结构,哈希表由一个直接寻址表和一个哈希函数组成
哈希函数h(k)将元素关键字K作为自变量,返回元素的存储下标
哈希冲突
由于哈希表的大小是有限的,而要存储的值的数量是无限的因此对于任何哈希函数,都会出现两个不同元素映射到同一个位置上的情况,这种情况叫做哈希冲突
比如h(k) = k % 7, 0,7,14都会映射到同一位置
解决哈希冲突方式1:开放寻址法
开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值

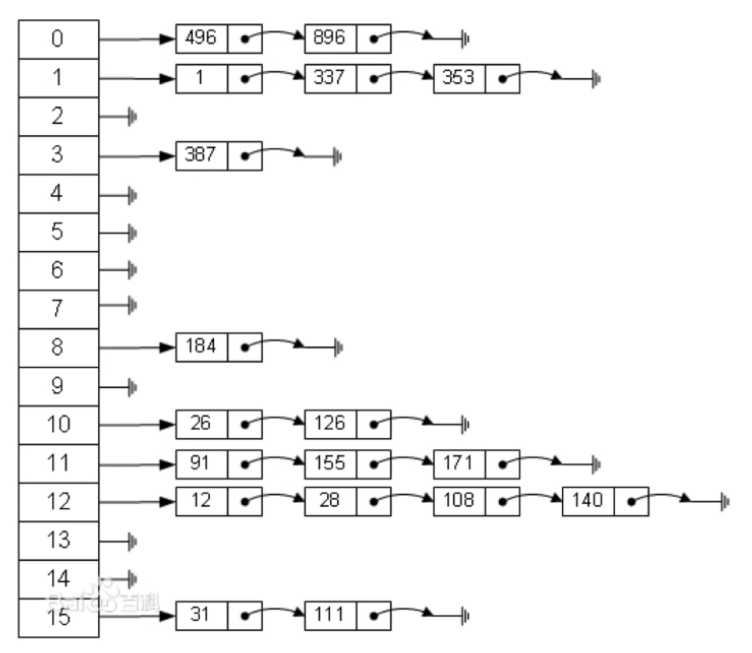
解决哈希冲突方式2:拉链法
哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后
常见哈希函数

实现哈希表
'''
链表实现删除???
'''
class LinkList:
class Node:
def __init__(self, item=None):
self.item = item
self.next = None
class LinkListIterator:
def __init__(self, node):
self.node = node
def __next__(self):
if self.node:
cur_node = self.node
self.node = cur_node.next
return cur_node.item
else:
raise StopIteration
def __iter__(self):
return self
def __init__(self, iterable=None):
self.head = None
self.tail = None
if iterable:
self.extend(iterable)
def append(self, obj):
s = LinkList.Node(obj)
if not self.head:
self.head = s
self.tail = s
else:
self.tail.next = s
self.tail = s
def extend(self, iterable):
for obj in iterable:
self.append(obj)
def find(self, obj):
for n in self:
if n == obj:
return True
else:
return False
def __iter__(self):
return self.LinkListIterator(self.head)
def __repr__(self):
return "<<" + ",".join(map(str, self)) + ">>"
# 实现类似集合的结构
class HashTable:
def __init__(self, size=101):
self.size = size
self.T = [LinkList() for i in range(self.size)]
def h(self, k):
return k % self.size
def insert(self, k):
i = self.h(k)
if self.find(k):
print("重复值")
else:
self.T[i].append(k)
def find(self, k):
i = self.h(k)
return self.T[i].find(k)
ht = HashTable()
ht.insert(0)
ht.insert(1)
ht.insert(3)
ht.insert(102)
ht.insert(105)
print(",".join(map(str, ht.T)))
print(ht.find(105))
print(ht.find(203))
哈希表应用-md5
文件的哈希值:若两个文件的哈希值相同,则可认为这两个文件是相同的
- 用户可以利用它来验证下载的文件是否完整
- 云存储服务商可以利用它来判断用户要上传的文件是否已经存在服务器上,从而实现秒传的功能,同时避免存储过多相同的文件副本

