数据仓库(Data Warehouse)
一般公司的程序系统会分为OLTP(online transaction processing)和OLAP(online analytical processing)两个部分,其中OLTP叫联机事务处理,这个部分是直接面对用户,一般要求实时性高,并发高,支持事务,数据相对不大,一般存储在关系型数据库,典型例子:我们进行购物的购物和淘宝;OLAP又叫联机分析处理,这部分主要给数据分析人员用,它要求数据实时性不高,一般数据量大,并且需要依据的数据分析结果做决策,典型例子:就是我们平时接触的大数据平台

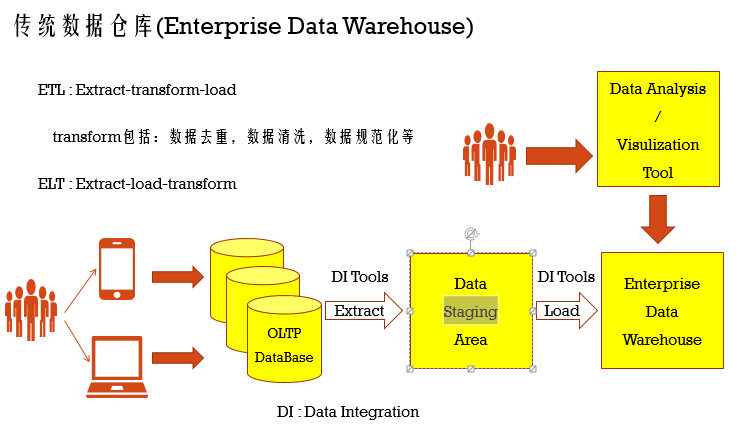
到此,你就可以理解到我们大数据人员在开发时接触的就是OLAP系统,我们会大数据技术去进行分析,但是大数据技术没出来之前,之前的OLAP技术架构是怎样的呢?也就是传统数据仓库怎么进行交互?当然无论是现在的还是传统数仓,都有一个很重要的概念就是ETL,也就是Extract-transform-load的缩写,传统数仓和大数据数仓数据处理流程基本一致,唯一不同的就是从OLTP平台导数据到我们的分析数据库里的方式不一样,其中Data Staging Area临时存储区域使用的是传统存储的技术比如关系型数据库mysql,其中在这个临时区域里还是负责ETL的transform操作,当然有的数据导入流程是ELT,也就是transform操作在分析数据库里,这种方式使得分析数据库存在资源竞争的问题

针对以上问题,大数据数仓,则是把临时存储区域,换成HDFS,然后基于大数据组件进行transform操作,这样不仅能适应数据量大的场景,在处理效率上也是非常高
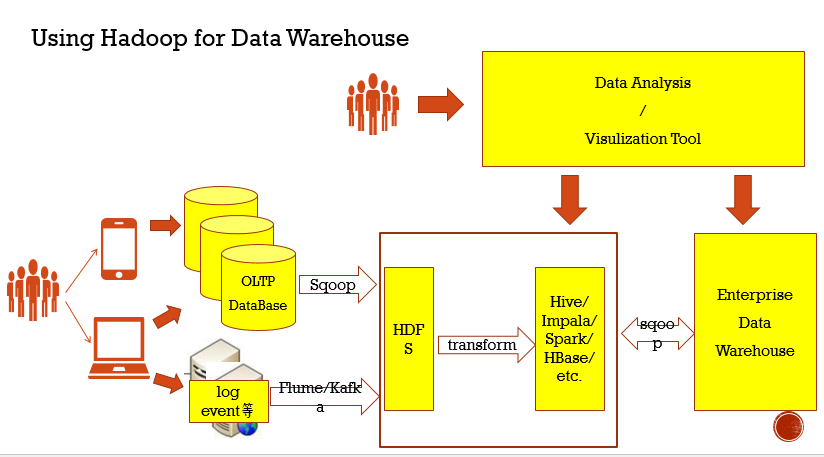
在上面图中,可以看出平时我们基本上都是从OLTP上获取最新的数据,获取的方式包括 1. 通过Sqoop从OLTP的关系型数据库导入到HDFS 2. 通过Flume和Kafka收集数据给到HDFS;正好这两种方式对应了离线和实时两种处理场景,并且存在HDFS上的数据经过transform存储在Hive或者Hbase中,当然也可以通过Sqoop把分析数据结果存储传统数据库,那么在进一步分析或者可视化就从这两个地方获取数据

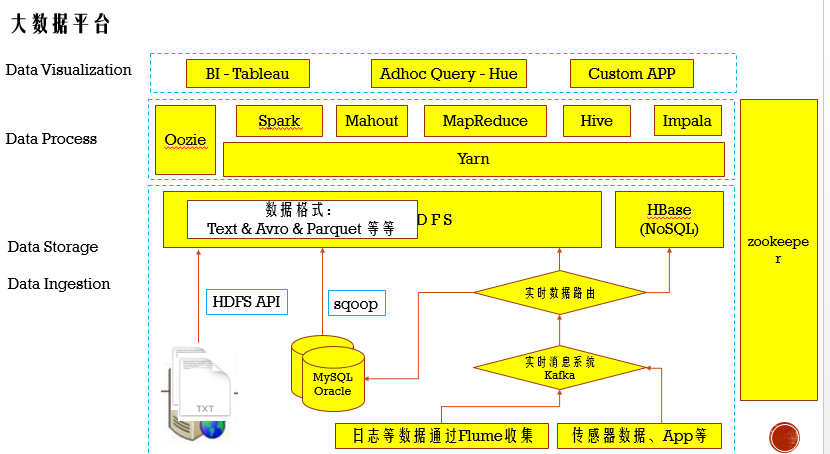
平时我们大数据技术架构如下,其中Sqoop主要负责把关系型数据的数据导入HDFS,其内部实现是转换MapReduce的task进行分区导入