


Spark Streaming总结
对Spark Streaming的原理讲解以及每个批对应blockRDD怎么进行分区的,细看总结第一第二
- 实时流的WordCount程序 :包括6个部分,实例编程入口,创建数据接收器,数据处理,结果输出,启动流处理程序,等待终止程序
- Spark Streaming本地模式 用于调试,需要注意的是实例content采用local,并且要两个core,一个用于实时计算,一个用于数据接收
- nc -lk 9998启动socket服务端,nc master 9998启动socket客户端,两者可以进行socket通信
- 实例化Spark Streaming两种方法:一种是传入sparkcontext实例(引用),一种是传入sparkconf,第二种方式本质上还是会创建SparkContext,另外在调用stop方式时,如果传入false,代表只停实时流程序,不停SparkContext,如果为true那sc也会停掉;实时流的处理代码必须在start之前才有效;JVM中只能有一个StreamingContext实例 详情
- Spark Streaming提供的是微批处理的服务,怎么分批?会有一个batch interval,这个在实例化StreamingContext时会给,也就是接收的数据会按照这个值(时间间隔),划分批次,存入Spark内存中,而DStream就是Spark streaming的编程模型,你可以理解DStream就是分为多个时间批次的RDD,最后都是转换成RDD来达到计算
- 接收器为socket,用作实验String类型的数据,另外队列接收器也做为实验类型,可以测更多种类型的数据 内存队列和Spark Shell交互
- 在RDD中的API,DStream里基本都有,并且最终都是调用RDD的Api来进行计算的,它还提供了两个转换成RDD进行计算的API,transform和transformWith,transform就是把单个DStream转换成RDD,然后你就可以进行RDD的操作了,比如你可以用这个 对DStream和HDFS的静态数据进行join操作,transformWith则是把两个DStream抓换成RDD,其中DStream的join操作本质就是调用这个API 详细
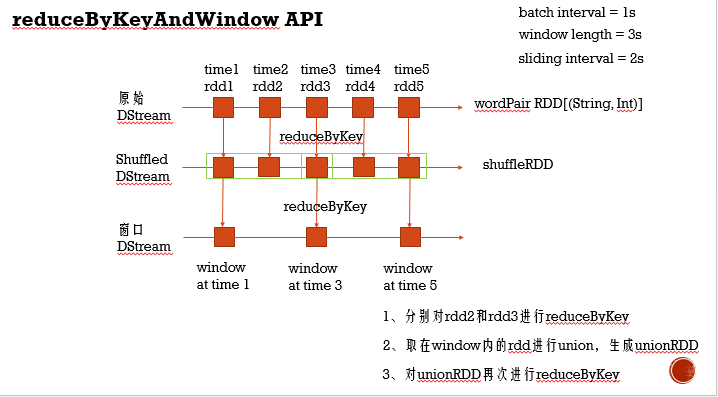
- Window API:窗口函数的逻辑计算由三个时间决定了,第一个batch interval,决定数据按多久的量来划分块,第二个,window length,这也是按时间计,要求是batch interval的倍数,这个决定了窗口跨度多少个数据块,第三个就是sliding interval,滑动时间间隔,也必须是batch interval的倍数,由于Spark Streaming是实时流处理,所以这个决定了窗口按照啥规律进行移动计算
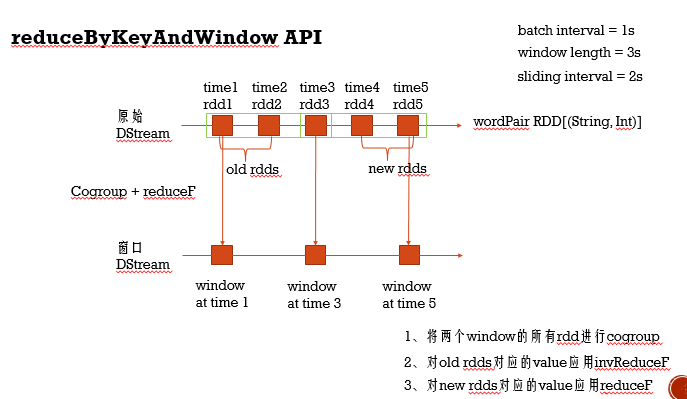
- reduceByKeyAndWindow API:reduceByKey带这个字眼的功能就不用多说了,对于Spark Streaming中这个API有两种用法,第一种使用方法,就是简单的传入累加函数,这种方式发生两次shuffle,第一次是在每个batch interval间隔的分区数据里进行shuffle。第二次则是对窗口里所有的batch interval数据union后,进行shuffle分区,所以这种方式某些场景下,效率比较低, 第二种使用方法就是不仅传入累加函数,还传入的一个反作用的函数,这种方式会发生一次shuffle,原理就是Cogroup + reduceF,跨两个窗口操作,其中对旧RDD进行反作用函数,新RDD就正操作,所以这种方式会之前的RDD有依赖,所以这种方式必须checkpoint,定时斩断依赖,不过它也有自己适合的场景,就是滑动时间比较短,窗口长度很长的场景,说白了就是当前窗口会有好多之前窗口的RDD 详细
方式一
方式二
10. countByWindow 统计窗口的数据量, reduceByWindow 不分key的按计算函数统计,countByValueAndWindow 统计各个key在窗口中出现的次数 详情
11. updateStateByKey对实时流启动以来所有的数据进行统计,这个也要进行checkpoint,这个API也有两种使用方法,都传入函数,不过函数参数不同,简单版是value和state参数,而复杂点,要求高点的(比如对某些key进行过滤),参数类型为迭代器 详情
12. mapWithState这个接口相对updateStateByKey性能更高(尤其对其第二种用法),它支持初始化某些key的值,还支持设置key的超时时间(目标是所有的key,只要某个key超过这个时间没更新就会失效),并且在print上也两种方式,默认的是只会输出更新的key,如果要把所有的打印出来,就要用stateSnapshots().print() 详情
13. DStream有API让处理数据存储到HDFS上,其中saveAsHadoopFiles可以指定文件格式存储,比如TextFile或者SequenceFile, 还有针对各种格式的简单API,比如saveAsTextFiles和saveAsObjectFiles 详情
14. 实时流数据和MySQL交互,首先DStream提供了foreachRDD,它可以让你获取每个时间点的RDD,其次连接数据这种耗时的操作,应该实例一个连接池,并且使用foreachPartition来达到一个分区的数据使用一个数据库连接,再者就是发送数据使用addBatch,一批一批的发,并且如果分区的数据很大,还应该控制每批的条数,比如控制成500条, 最后考虑事物,操作数据库的原子性 详情
15. Spark Streaming也支持和Spark Sql交互,本质上就是用foreachRDD得到对应的RDD,然后toDF转成DataFrame来进行操作 详情
16. Spark Streaming实时流应用可以从数据接收,数据处理,结果输出三个环节进行优化,首先数据接收,你可以开启多个receiver增加吞吐量;另外需要结合core的资源,合理提高blockRDD的并行度,可以调节block interval,比如task太少,可以调小block interval;还可以调节receiver的接收速率(有自动调节的方式);其中就是数据处理过程中,要考虑并行度,blockRDD除了上面调节block interval,还可以通过reparation调节,另外就是shuffleRDD默认情况是有core数量决定的,当然也可以自动进行调节;考虑高效合理的序列化,在数据输入的时候,以及缓存RDD时,都需要序列化,以及传输给Executor的时候选择Kryo高效序列化机制;内存优化方面:如果内存够了,RDD可以只缓存到内存,不选择disk,以及注意tranform如果是window操作,分配合理内存;另外就是driver和Executor启动JVM时选择CMS垃圾收集器(追求最短回收停顿时间);输出数据环节具体考虑存储的地方,比如和mysql 可以参考14点 详细
17. Backpressure压力反馈机制:Spark Streaming怎么界定哪个时候进行调节呢?它提出了稳定和不稳定状态,当每批处理的时间batch process time 大于 batch interval界定了不稳定状态,这种情况下,程序会返回压力给数据接收receiver,进行调节接收数据,以达到稳定状态;资源动态分配机制,相对spark是指定一个一定时间的值来决定是否删除还是启动Executor,spark streaming则通过process time/batch interval的比值来控制的,当这个比值非常小,比如只有0.5时,则杀掉没有receiver的Executor,进行做到高效稳定,如果这个比值超过1,则会启动Executor,处理数据量增大,又会进行反馈给数据接收方,进而调高数据接收, 这两种机制都需要通过配置的方式把开关打开才能用
18. Spark Streaming程序考虑高可用性,需要从这几个方面想:1.driver端保存的配置信息,以及receiver跟踪信息 2.Executor接收的信息:包括已经分块的,也就是已经被receiver跟踪到的数据信息,还有就在未分块暂时攒着放在blockGenerator, 对于driver端,通过checkpoint机制做到,把数据存到hdfs上,而对于Executor已经分块的数据,只要实例接收器时,存储级别选择备份2,那么Executor挂掉时,就会找已经备份了的启动receiver,不过这个是针对已经分块,那些没分块没处理的数据,则需要WAL机制,本质就是checkpoint,这种机制不仅备份没分块的数据,还包括分块的数据,所以选择了这种机制,就没必须receiver那再选择备份2了
19. Spark Streaming实时流程序主要分为数据接收,数据处理,结果保存三个部分,并且流计算语义也分为at most once,at least once,exactly once三种语义,最好的实时流处理程序应该整体符合exactly once语义,也就是说在数据接收,数据处理,结果保存都符合exactly once语义,其中对数据接收receiver,在接收到数据,并存储备份好后发送回执给数据源,这样的receiver被称为Reliable Receiver,如果不发回执,则称为Unreliable,如果Receiver采用checkpint + WAL + Reliable receivers只能保证数据不会丢失,但可能重复消费,而Kafka的Direct方式能保证接收数据时,一条数据只消费一次,kafka的partition作为RDD的分区;数据转换过程,RDD通过依赖链高效容错,保证一条数据只处理一次;至于结果保存,可以通过幂等和支持事务保证数据同样数据只存储一次,幂等就是同样的数据,同样的结果,这样重复结果覆盖写就不会重复,事务可以通过主键唯一控制 详情

