

大数据技巧
项目技巧
会话切割(Spark SQL)
1.利用schema生成类
可以通过定义avsc文件,并结合avro-maven-plugin插件就可以自动生成对应的类
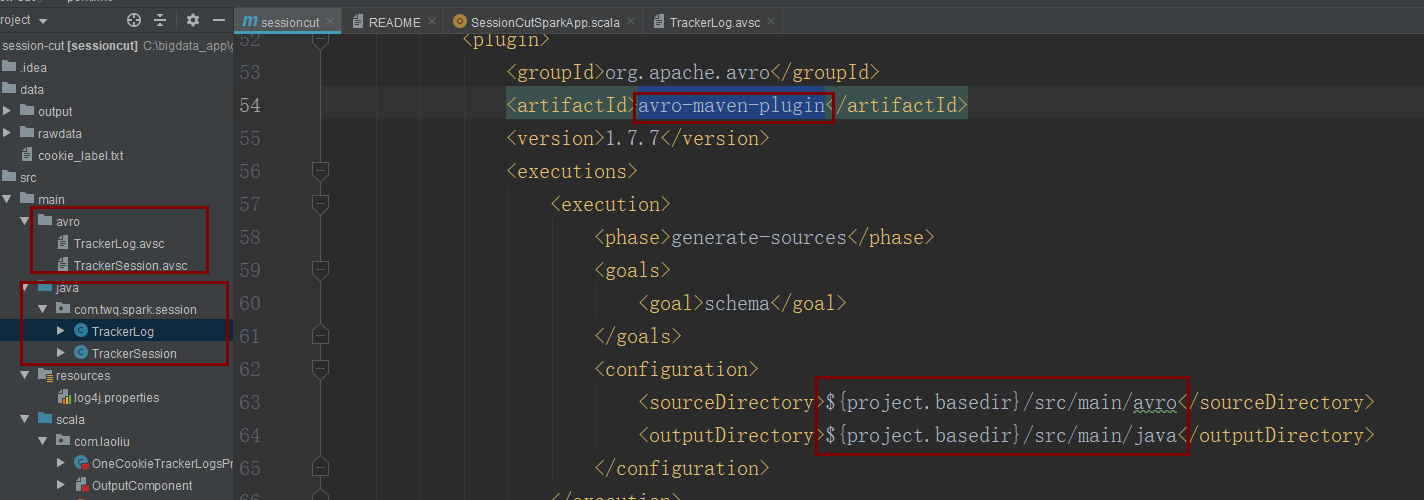


<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.7</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
{"namespace": "com.twq.spark.session",
"type": "record",
"name": "TrackerLog",
"fields": [
{"name": "log_type", "type": "string"},
{"name": "log_server_time", "type": "string"},
{"name": "cookie", "type": "string"},
{"name": "ip", "type": "string"},
{"name": "url", "type": "string"}
]
}
2.开启高效序列化:上面1中生成的类型,默认是没有实现序列化的,如果需要从Driver端传输给Executor端,可以开启kryo序列化
// 开启kryo序列化,因为在读取日志进行RDD操作时,可能设置序列化操作
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
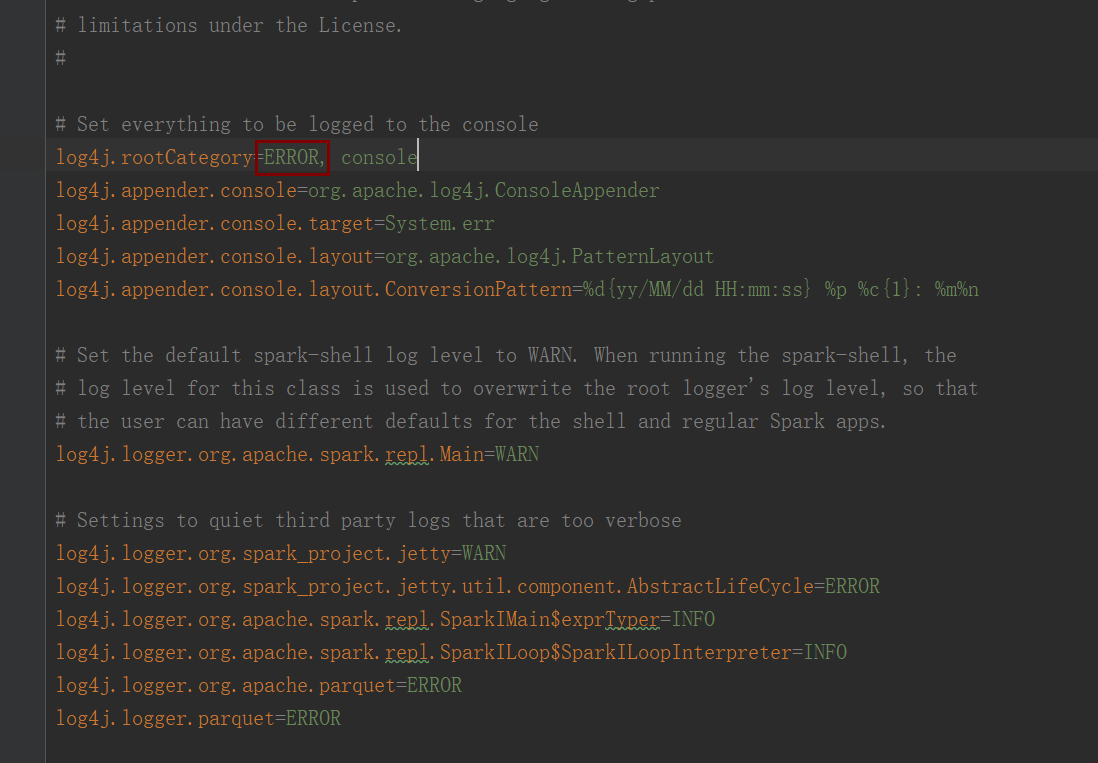
3.屏蔽屏幕打印日志:在运行Spark程序过程会打印很多INFO的日志,如果嫌这些日志会干扰你,你可以这么做,到$SPARK_HOME/conf下,把这文件log4j.properties.template去掉.template复制一份,放在maven项目的resources,并修改INFO为ERROR
4.巧妙运用foldleft进行前后对比
sortedTrackerLogs.foldLeft((cutedTrackerLogList, Option.empty[TrackerLog])){
case ((build, preLog),currLog) => {
val currLogTime = dateFormat.parse(currLog.getLogServerTime.toString).getTime
// 超过30分钟就生成一个新的会话
if(preLog.nonEmpty &&
currLogTime - dateFormat.parse(preLog.get.getLogServerTime.toString).getTime > 30 * 60 * 1000) {
cutedTrackerLogList += currentLogArray.clone()
currentLogArray.clear()
}
currentLogArray += currLog
(build, Some(currLog))
}
}
6.增加自己的打印日志
val logger = LoggerFactory.getLogger("etl")
logger.info("123")
8.Spark Sql设置shuffle分区数:默认是200,如需调整可以通过下面这种方式
spark.conf.set("spark.sql.shuffle.partitions", 4)
9.实例化时trait minin技巧:trait混入时,除了定义类可以混入,在实例对象时也可以混入,可以在覆写默认实现时使用
object Test {
def main(args: Array[String]): Unit = {
val obj = new Ob
obj.default
val obj2 = new Ob with Overwrite
obj2.default
}
}
trait Default {
def default = {
println("default")
}
}
trait Overwrite extends Default {
override def default: Unit = {
print("overwrite")
}
}
class Ob extends Default
地图切片
1. 合适的技术选择,可以通过谷歌和百度,巧用关键词,主要从自己的使用场景、github上的活跃度、学习资料的可得性、maven仓储的维护时间
2. 多语言数据传输,如果想让数据在不同语言之间使用,你会有什么方案,如果你想到xml,你还是很可以的哦!不过xml解析起来,非常费性能,如果不在乎性能,还是可以用用,不过这还有一种由谷歌提供的比较高效的方案,就是Protoc Buffers,它就是主要做多语言数据传输的,Protoc Buffers使用步骤:第一,按照它们给的规则定义proto文件 第二,安装protoc工具,用命令生成类 第三,通过生成的类来实例对象存放数据,并通过这个类提供写接口给到文件输出流,写入对应的文件中,得到文件也可以在其他语言通过这样生成的类来进行读取
3. 性能调优,可利用资源和并行度,RDD调优你需要知道划分了几个stage,每个stage有多少task,以及task运行时间,来确定怎么调优,要知道性能瓶颈在哪,这些都可以在spark UI看到,并且并行度提高的前提需要core资源提高,如果瓶颈是在shuffle后,那你在shuffle api调高分区,还不够,需要调高core资源,需要注意的是,读取时分区在1-2个,往上调高资源,还是取2,而shuffle过程默认没给分区器时,则是取父RDD的分区数
4. 集合的多线程运行:par
println(Runtime.getRuntime.availableProcessors())
(0 to 6).par.foreach(i => {
println(Thread.currentThread().getName)
println(i)
TimeUnit.SECONDS.sleep(3)
})
5. 划分成多个job的好处就是可以针对job给参数,比如某个job运行时间长,可以在某个shuffle api给分区数给高点, 比如在此项目针对每个level运行时长针对给分数区,通过zip函数传入
6. 找性能瓶颈(1) jconsole:查看GC情况,内存占用情况,在java的安装目录bin目录下,双击jconsole.exe,选择你的本地的jvm进程连接,在【内存】可以查看内存的使用情况,以及GC时间,【概要】可以看堆内存大小,以及使用什么垃圾收集器,如果GC是一个瓶颈,可以尝试更换垃圾收集器,IDEA -> Run -> Edit Configurations -> VM Options,填 -XX:+UnlockExperimentalVMOptions -XX:+UserG1GC
7. 找性能瓶颈(1) jvisualvm.exe:看执行程序中方法的运行时间,方法运行时主要使用的是CPU,通过这个工具可以查看执行程序CPU的情况(注意:如果要使用这个工具查看某个进程,如果不让报错,需要给这个进程加个VM参数-Xverify:none),双击工具后,点选本地某个进程,【概述】可以看JVM的参数,【线程】可以看执行程序此时起了多少哪些线程,【Profiler】可以查看方法执行情况,点CPU就会开始分析,可以点击【快照】,它就会截取某个时间点下的各个方法执行时间的情况,然后对应进程下就会有个快照,点击快照,就可以开始进行分析了,由于Scala是函数式编程,所以看起来有点难找,需要认真看,比如自有时间可能代表写文件时间;另外查看spark程序的性能瓶颈时,需要注意的是大部分代码是在Executor上运行,所以你需要连接Executor的java进程进行分析,首先你需要在jvisualvm上【远程】新建好slave们主机名,比如我这里就是slave1,slave2,另外为了方便追踪Executor上进程,需要在提交spark应用时,给Executor JVM绑定一个端口(如下),这样在task运行时,就可以通过主机名:端口 连接Executor JVM进行分析,然后只要运行不同阶段,截取几个快照
--conf spark.executor.extraJavaOptions="-Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false "
8. 错误排查:出现错误,拿错误显示去百度和谷歌进行搜索,通常NoClass类似的错误都是缺包;另外项目下放了core-site.xml,在操作文件会自动带上hdfs,如果想用本地路径,可以删掉这个本地配置文件,hbase-site.xml也可以删掉,只要在代码里增加依赖的zookeeper位置就可以了;如果程序一直挂着,需要开启debug日志,就是配置log4j.prop...文件;搜索错误,发现HBase1.2.x强依赖protobuf-2.5.0,如果引入高版本的protobuf,会造成hbase各种问题,但是protobuf2.x又和3.x版本不兼容,那怎么解决,又要谷歌百度,比如你可以搜索 protobuf 版本不兼容,谷歌最好用英文,或者直接搜hbase protobuf-java,最后找到一个使用hbase-shaded-client库可以解决,但是使用这个后,还报一个NoClass的错误,你点具体错误,你会发现它会提示两个包,这个两个包冲突,但是有一个(hadoop-mapreduce-client-core:2.6.5)是你在maven中没有依赖的,这里没依赖,并不代表其他库没依赖,其中spark很可能依赖,然后去Maven Project下dependence下查看spark是否依赖,尝试在maven使用exclusion排除这个包,到此在本地可以运行了,程序此时用的protobuf 3.x版本;但是你把程序放到集群上跑,还是报这样的错,你可以发现在spark安装目录下jars下,依赖的protobuf包还是2.5的,当然你也可以在spark UI的applicationMaster下点Environment查看依赖的jar包(这里还是看java scala等版本,传递的参数);集群上的环境我们是无法更改的,所以只能适配我们的代码,降级protobuf到2.5
9. Maven支持父子模块,所以你可以当前项目目录下新建Maven项目,新建的Maven项目你可以认为就是子模块,并且它也有pom文件对包进行管理,兄弟模块之间在pom文件是可以引用的,并且通过这种方式,对代码进行用途上的划分,对包进行综合管理,比如共用包可以放在父pom中,独有包就放在子pom中,父子模块包的管理,遵循一个原则,就是包和插件的版本在父pom中,子pom进行引用,父pom中定义的properties管理版本值,在dependencyManagement管理依赖,其中这里的依赖version通过${}引用properties中定义的标签名,在build下pluginManagement下管理插件,这做完后,在子pom中只要引用模块不用填版本,引用兄弟模块需要填version为${project.version},引用父定义的包是这样做,如果父没有,子独有,那你可以在子pom按之前pom管理的方式加
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.twq</groupId> <artifactId>map-tile</artifactId> <packaging>pom</packaging> <version>1.0-SNAPSHOT</version> <modules> <module>demo</module> <module>java-vector-tile</module> <module>backend</module> <module>utils</module> <module>api</module> </modules> <repositories> <repository> <id>ECC</id> <url>https://github.com/ElectronicChartCentre/ecc-mvn-repo/raw/master/releases</url> </repository> </repositories> <properties> <maven.compiler.target>1.8</maven.compiler.target> <maven.compiler.source>1.8</maven.compiler.source> <spark.version>2.2.0</spark.version> <hbase.version>1.2.6</hbase.version> <scala.binary.version>2.11</scala.binary.version> <scala.version>2.11.8</scala.version> <scala.version>2.11.8</scala.version> <protobuf.version>2.5.0</protobuf.version> <jts.version>1.15.1</jts.version> <spring.boot.version>2.0.1.RELEASE</spring.boot.version> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>org.locationtech.jts</groupId> <artifactId>jts-core</artifactId> <version>${jts.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> <exclusions> <exclusion> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> </exclusion> </exclusions> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>${protobuf.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-shaded-client</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <version>${spring.boot.version}</version> </dependency> </dependencies> </dependencyManagement> <build> <pluginManagement> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>${maven.compiler.source}</source> <target>${maven.compiler.target}</target> <testExcludes> <testExclude>/src/test/**</testExclude> </testExcludes> <encoding>utf-8</encoding> </configuration> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.1.6</version> <executions> <execution> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> </plugins> </pluginManagement> </build> </project>
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>map-tile</artifactId> <groupId>com.twq</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>backend</artifactId> <dependencies> <dependency> <groupId>com.twq</groupId> <artifactId>java-vector-tile</artifactId> <version>${project.version}</version> </dependency> <dependency> <groupId>com.twq</groupId> <artifactId>utils</artifactId> <version>${project.version}</version> </dependency> <dependency> <groupId>org.locationtech.jts</groupId> <artifactId>jts-core</artifactId> </dependency> <!--将java-vector-tile依赖的3.6.1的protobuf降级为2.5.0--> <!--<dependency> <groupId>no.ecc.vectortile</groupId> <artifactId>java-vector-tile</artifactId> <version>1.3.4</version> </dependency>--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> </dependency> <!--<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.2.6</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.5</version> </dependency>--> <!--加上HBase强依赖的protobuf-java:2.5.0版本--> <!--报错:java.lang.ClassNotFoundException: com.google.protobuf.GeneratedMessageV3$ExtendableMessageOrBuilder--> <!--查看发现com.google.protobuf.GeneratedMessageV3这个类是protobuf-java:3.6.1--> <!--结论是:protobuf-java版本冲突,我靠!!!!--> <!--<dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>2.5.0</version> </dependency>--> <!--百度搜索关键词:protobuf-java版本不兼容--> <!--google关键词:protobuf java version Compatibility--> <!--google关键词:hbase protobuf-java--> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-shaded-client</artifactId> </dependency> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <!-- this is used for inheritance merges --> <phase>package</phase> <!-- 指定在打包节点执行jar包合并操作 --> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
10. RowKey设计不能一蹴而就,需要一步一步来,刚开始进行一个初步设计进行编写程序,后续重新设计,主要考虑读写场景,主要读的场景是否高效,比如走rowkey过滤,而写考虑并行写,并且避免热点写,在数据量大时,多个region并行写高效,所以要预切分,预切分规则需要跟rowKey结合避免热点写,其中UniformSplit和HexStringSplit只对字母很有效,而1_2_3这种不行(这个结论需要重新另外验证),rowKey设计一定要结合业务场景的数据特点,比如某个关键数据反转后是随机的数字,那么就可以用SPLITS=>['2','4','6','8']
11. 性能点:常用RDD缓存
篮球球员价值分析
1. 删除数据输出目录,由于spark程序在输出数据时会判断输出目录是否存在,存在则会报错退出,所以可以先对输出目录进行删除
val fs = FileSystem.get(new Configuration()) // hdfs api可以操作本地目录
fs.delete(new Path(outpath), true) // true 表示递归删除
//但是这种方式在集群跑会有问题,报路径错误,主要就是上面空config时,不会去找hdfs路径,如果要让去找//hdfs,那么需要你在程序里做判断在哪运行,如果在集群运行,额外给config设置这个
configuration.set("fs.defaultFS","hdfs://master:9999")
2. DataFrame一行row转化成 Map:通过getValuesMap + schema里的name
row.getValuesMap[Double](row.schema.map(_.name).filterNot(_.equals("year")))
3. 把case class对象中的所有属性值转成迭代器,就可以像集合一样累加所有属性的值,productIterator
zScoreStats.productIterator.map(_.asInstanceOf[Double]).reduce(_ + _)
4. Spark SQL在shuffle分区默认是200个,这个值需要结合场景进行调节
spark.conf.set("spark.sql.shuffle.partitions", 4)
5. 从array中创建row
Row.fromSeq(Array(player.name, player.year, player.age, player.position,
player.team, player.GP, player.GS, player.MP))
6. zeppelin:和Hue一样,都是提供Hive数据可视化的技术,其中它还支持图的方式显示hive查询的结果 以及在界面上运行spark,spark sql,python等代码
7. Spark SQL和Hive本地调试: 1.依赖spark-hive_2.11 jar包 2.代码需要打开enableHive 3.数据存储,本地会创建一个warehouse目录 4.spark sql默认写hive存储文件格式parquet
网站分析
1.批量开启kryo序列化
conf.set("spark.serializer", classOf[KryoSerializer].getName)
conf.set("spark.kryo.registrator", classOf[WebRegistrator].getName)
package com.laoliu.spark.web import com.esotericsoftware.kryo.Kryo import com.laoliu.dataobject.dim.{AdInfo, BrowserInfo, ReferrerInfo, SiteResourceInfo, TargetPageInfo} import com.laoliu.dataobject.{BaseDataObject, EventDataObject, HeartbeatDataObject, McDataObject, PvDataObject} import com.laoliu.ipLocation.IpLocation import com.laoliu.objectbuilder.TargetPageDataObject import org.apache.spark.serializer.{KryoRegistrator, KryoSerializer} /** * 使用Kryo序列化机制 */ class WebRegistrator extends KryoRegistrator { override def registerClasses(kryo: Kryo): Unit = { kryo.register(classOf[BaseDataObject]) kryo.register(classOf[PvDataObject]) kryo.register(classOf[HeartbeatDataObject]) kryo.register(classOf[EventDataObject]) kryo.register(classOf[McDataObject]) kryo.register(classOf[TargetPageDataObject]) kryo.register(classOf[AdInfo]) kryo.register(classOf[BrowserInfo]) kryo.register(classOf[ReferrerInfo]) kryo.register(classOf[SiteResourceInfo]) kryo.register(classOf[TargetPageInfo]) kryo.register(classOf[IpLocation]) } }
IDEA技巧
1.函数萃取:选中代码 -> 右键 -> Refactor -> Extract -> Method
2.去掉无效导入:curl + alt + o
Maven技巧
1.打依赖包
如果想把所有的依赖都打进一个包里,可以用下面的插件
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- 指定在打包节点执行jar包合并操作 -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
如果环境已经提供了某个包,不想把这个包打进去,可以用provided,但是本地运行时记得注释掉
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
<!-- <scope>provided</scope>-->
</dependency>
需要理解的点:
1. 文件输入输出流总结,以及线程池使用
2. 不同场景RDD的分区数确定,比如local模式下,默认1core,就是1个分区,2core两分区,3的话取最小值2个分区
3. java和scala中的正则使用
4. java和scala跟os打交道,就拿python的os的模块对比
5. scala各种集合的区别与使用场景
