


Hive
Hive其实是架设在HDFS之上的SQL解析执行框架,就是说我们使用Hive可以通过SQL来操作HDFS上的数据,而在之前提到Spark SQL也很好的兼容了SQL和HQL两种关系型查询语言,其中SQL代指Spark SQL中内置的 ,而HQL则代指Hive
另外访问Hive的方式主要有:1.终端或者连接ThriftServer 2.Spark应用程序代码写SQL
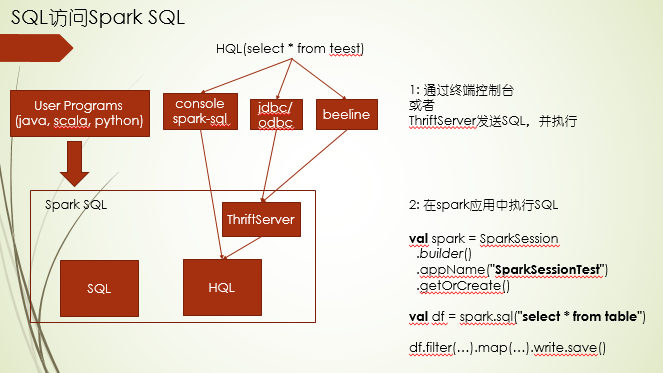
ThriftServer是基于socket cs架构实现网络通讯,相对socket,socket更偏底层,而ThriftServer更高层,对通讯协议再次封装,使得开发人员更多关注接口层编程,并且支持跨语言
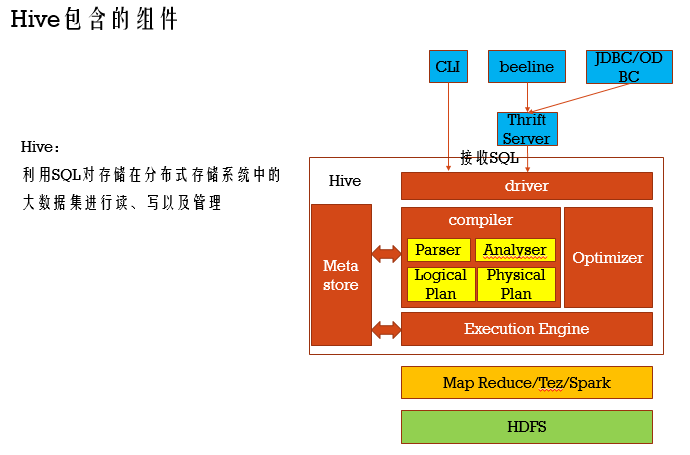
Hive架构详细
Hive有三种安装方式,本质上就是Hive里面的MetaStore安装方式的不同,主要分嵌入模式,本地模式,远程模式,嵌入式三者在同一JVM,采用Derby存储元数据,这种方式下的元数据不共享,一般实验玩玩还可以,生产上不会这么弄,远程模式下MetaStore都是单独的JVM,可以负载均衡
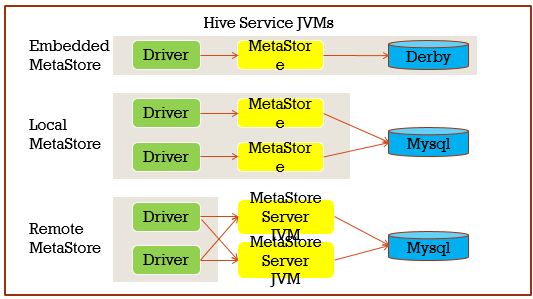
平时自己开发测试会选择本地模式,无论是本地模式还是远程模式,都依赖mysql服务,所以你需要先看下mysql服务是否启动了(service mysqld status),其中在hive-site.xml中会配置元数据存储的数据库名,那么在正常启动Hive服务时,就会去创建这个数据库,你可以到这里去查询元数据信息,我这里配置的就是hive
//hive依赖HDFS start-dfs.sh //启动hive hive // 如果是远程模式。则需要在master启动 metastore服务 nohup hive --service metastore > ~/bigdata/apache-hive-2.3.7-bin/logs/metastore.log 2>&1 & // 如果要用hiveserver2进行连接,在slave1启动hiveserver2服务 nohup ~/bigdata/apache-hive-2.3.7-bin/bin/hiveserver2 > ~/bigdata/apache-hive-2.3.3-bin/logs/hiveserver2.log 2>&1 & //默认走yarn,需要启动yarn start-yarn.sh //yarn占资源,可以在hive那设置本地模式 SET mapreduce.framework.name=local;
上面这种是比较老的连接方式,hive社区更推荐使用beeline连接ThriftServer的方式,这种方式本质上是用JDBC的方式去连接,当然代码中连接hive也是用jdbc连接ThriftServer
1: 打开hiveserver2的服务:nohup $HIVE_HOME/bin/hiveserver2 > /tmp/hiveserver2.log 2>&1 & 2: 执行beeline脚本:$HIVE_HOME/bin/beeline 3: !connect jdbc:hive2://master:10000 连接hiveserver2服务, 输入用户名:hadoop-twq,不需要密码
Spark SQL兼容Hive也就是以Spark SQL为入口,进行Hive操作,需要把Hive的配置复制到spark配置下,重启集群,通过$SPARK_HOME/bin/spark-sql进入操作hive命令行,另外Spark SQL有自己ThriftServer服务,如果需要通过beeline和JDBC的方式访问,需要启动这个服务

提交Spark应用到spark集群上查询Hive数据 注意两点:spark配置下是否有Hive的配置 以及 enableHiveSupport, 另外Spark SQL支持脱离Hive在本地运行,详细 直接通过spark.sql操作
当然你enable hive后,spark sql的table接口和saveAsTable接口默认操作就是Hive表的数据
既然Spark SQL也可以操作Hive表,那两者的使用场景是怎样的呢?首先Hive偏重仓库存储,并且DSL语言可读性高,如果是连表查询后过滤的结果需要保存到表中,使用 Hive,而Spark SQL,代码组织灵活,可以调用各种API,如果涉及复杂查询,比如调用AI算法,使用Spark SQL,当然简单的ETL,哪个方便就用哪个
命令行CLI(HQL)
DDL_db操作
DDL_table操作 :
- 行格式(ROW FORMAT):格式主要有两种,一个DELIMITED,一个SERDE,其中第一种常用于textfile和sequencefile,而第二种常用于自定义行格式,比如正则和json,DELIMITED本质上还是SERDE,serde就是序列化和反序列化的意思
- 表的种类:主要分外部表和内部表,临时表,另外视图一般不包括在内,因为视图为逻辑表,不会在HDFS上存储;那么对于这三种类型的表有什么不同点呢?(1)定义上,加了EXTERNAL的就是外部表,没加就是内部表 (2)导入数据时,内部表一般都要有个load data的动作,而外部表不需要,会自动加载location下的数据,location对应目录一般在创建表的时候会指定 (3)删除表时的反应上,内部表会删除数据,而外部表不会 (4)对于临时表,只要记住它跟会话绑在一起,会话关闭时,表也消失,定义时使用TEMPORARY关键词,定义时也分内部表和外部表
- 分区表:也是分内部表和外部表,所以对于分区的操作,也是从这两个维度进行对比,定义表时,使用PARTITIONED BY就是分区表,(1)创建分区,内部表通过load data加载数据时,指定分区进行添加数据,而外部表事先已经在location目录按分区字段创建好目录并放好数据,外部表还需要做就是通过ADD PARTITION动作把分区和数据对应上 (2)分区重命名,内部表的数据路径会发生改变,而 外部表则不变 (3)删除分区时,外部表数据不会删除,内部表会删除
- 不同分区是支持不同格式数据的,通过对分区进行文件格式设置 SET FILEFORMAT(目前外部表是可以的,内部表要试下)
DML操作 :
- 加载数据(load data):加了local表示本地数据,没加就是HDFS上的 数据,其中HDFS上的数据进行加载时,本质动作是进行move, 如果是OVERWRITE INTO是覆盖写,没加overwrite只是into则是追加写
- 插入数据(insert data):由于load data的方式会删除源数据文件,如果不希望这样,可以使用insert data的方式,这种方式就是把查询某个表的结果进行插入到当前表,其中INSERT OVERWRITE表示覆盖写,INSERT INTO表示追加写,这种方式还有一个经常使用的场景,就是给同一张表加载不同格式的数据,通过外部临时表自动加载数据,再通过insert data的方式插入到我们想要插入的表里
- 动态分区:通过insert data的方式插入到指定分区里,这个分区字段不给值,只是给定字段名,如果这样做了,后面select就要把没给值的字段放最后,这样就能动态分区了
- 直接输出文件(insert directory):hive支持通过命令把表里的数据写入本地文件或者HDFS文件,其中需要注意的,数据量大写HDFS,量少可以写本地
DML_bucket和skew操作:
- 分桶(bucket):语法CLUSTERED BY(字段名) INTO 几 BUCKETS,它的出现主要考虑到如果一个分区的数据量还是很大,查询性能肯定不高,所以可以在一个分区数据的基础上,基于某个字段在分多少桶,这个桶在HDFS存储路径上是有体现的,分桶的本质是字段值的哈希值对桶数取模,另外分桶时(定义表时)还是通过SORTED BY指定字段对分桶数据排序
- 分桶的作用:数据分析时的数据采样, 提高查询效率,比如mapside join
- 数据倾斜(skew):这个主要是针对一张表中某些列的值占比特别大,语法SKEWED BY(字段名) ON (列值1...),这个本质上不会在HDFS数据路径上进行创建对应值的路径,它只是把这些倾斜信息更新元数据信息里(mysql中),在进行查询操作时会进行相应的优化
- List Bucketing Table:它就是Skewed Table,只不过它弥补了Skewed Table的不足,就是在HDFS上不会为倾斜值创建目录,List Bucketing Table就会这么做,从而过滤查询时减少扫描提高性能,语法SKEWED BY(字段名) ON (列值1...) STORED AS DIRECTORIES, 另外查询时,需要进行下面的设置才能查询出数据
--需要设置下面的属性才可以查询 set hive.mapred.supports.subdirectories=true; set mapred.input.dir.recursive=true;
- UDF(User Defined Function):单行函数,输入一行输出一行 (1)数学函数round (2)集合函数array_contains,map_keys,map_values (3)类型转换函数cast (4)时间函数year,month,day (5)字符串函数format_number,concat (6)自定义函数:首先 代码实现,然后打包 其次在hive通过add jar添加打的包,通过list jars可以确认是否添加上 最后通过create function 函数名 as 'jar里定义的类名',这样操作后就可以使用这个函数了
- case when:两种用法,case后面跟字段,这个一般用于值相等判断比较,如果case后不跟字段,那么when的情况就会跟判断语句,代表一个范围
- 嵌套查询和CTE查询:(1)嵌套查询,你就可以理解为from 表提前,后面的select就不用跟from (2)CTE查询:让复杂查询变的更清晰,也就是多条件查询时,我们可以使用with 别名 as 子查询 的方式先声明好,在select的时候,使用别名进行查询过滤
- UDAF(User Defined Aggregation Function):多行函数,输入多行但是输出一行 (1)计算函数max,avg,min,sum,count (2)集合函数collect_list,collect_set
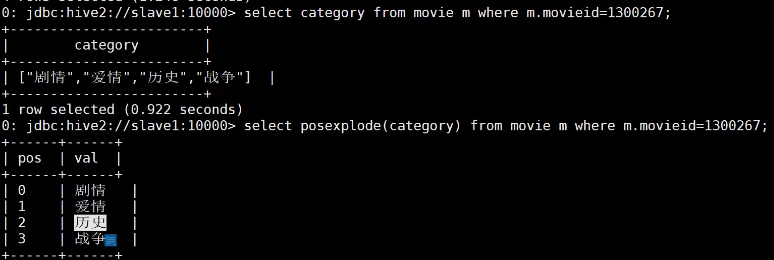
- UDTF(User Defined Table Function):输入是一行但是输出是多行,explode,posexplode
explode展平列表项或者字典项
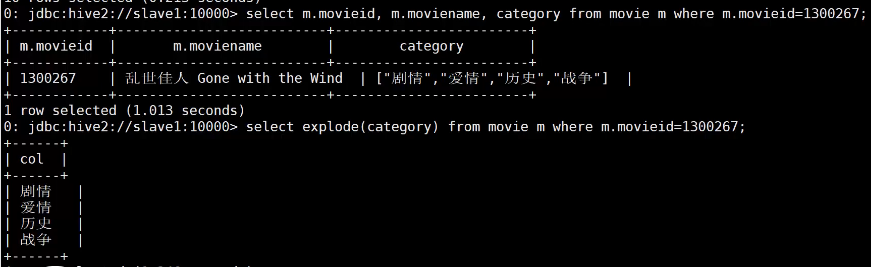
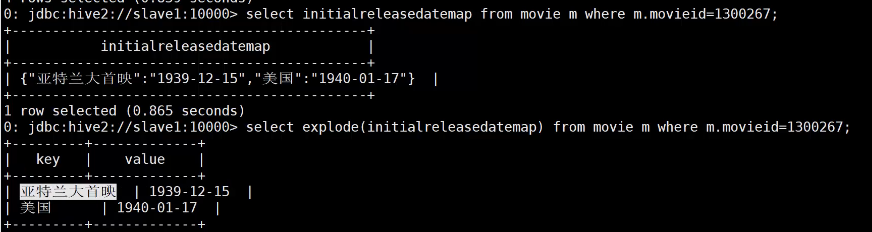
posexplode除了展平项,还有一列索引
6.连表查询:常用的连表操作这里就不赘述了,说点hive里不一样,能提高性能的 (1)left semi join代替in子句,会提高性能,但是有些情况 不能使用,就不能 在select或者where中出现join的右表的字段 (2)map-side join在大表join小表时性能好,会把小表缓存起来 (3)bucket map join就是两张表都很大的场景使用,但是使用是有前提:两张表对join字段分桶,bucket数量成倍数关系 (4)bucket sort merge map join 要求两表内分桶数据排序,并且两表bucket数量一样多
7.高级聚合函数,主要是各种分类汇总 (1)lateral view和explode函数结合使用,实现行转列,也就是一行变成多行 (2)grouping sets可以指定按什么维度来汇总,并且还提供了grouping__id字段,如果是多维度字段聚合,用小括号括起grouping sets(year, ctgy, (year, ctgy)) (3)cube,可以理解为grouping_sets的全量版,覆盖了每个单独字段统计,字段组合统计以及整个汇总,用法就是with cube代替grouping sets (4)rollup,统计覆盖按group by字段,依次减少字段总结,减到最后就是整个汇总,用法就是with rollup代替grouping sets
8.hive表数据直接导入本地或者HDFS上:insert overwrite local directory 本地路径 row format delimited fields terminated by "\t" select查询
分析函数:分析函数主要有两大场景,一个是分组分析,一个就是窗口分析,通过分析函数可以在当前表基础上增加分析列, 增加列的使用格式:Function(arg1, ..., argn) OVER ([PARTITION BY <...>] [ORDER BY <...>] [<window_clause>])
1.PARTITION BY,如果加了就按分组分析,没加时则是按整个数据分析
2.ORDER BY会对窗口范围产生影响,没加时是对整个分组,加了但是没给窗口范围,默认就是起始到当前行,这个和指定范围的ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW有点不一样,指定范围的才是真正意义上从起始到当前行,没指定的,如果order的字段值一样,那后面相同值的行计算得的值会覆盖之前同值的行
3.窗口指定:语法如ROWS BETWEEN 起始 AND 结束,其中CURRENT ROW表示当前行,边界使用UNBOUNDED,上边界就是UNBOUNDED PRECEDING(前面),下边界就是UNBOUNDED FOLLOWING, 如果是前3行,就用3 PRECEDING,后1行,1FOLLOWING
4.ROW_NUMBER,分组内按照某个字段排序进行编行号
5.first_value对分组内取最大最小值,如果order是desc就是最大,asc就是最小, 而last_value则是分组内起始到当前行取最大最小
6.lead表示向下偏移多少行取值,而lag则是向上偏移,默认是1行,没有的行取值时填null,这两个默认值你可以传参改变
7.RANK和DENSE_RANK都是对某个字段进行排名,其中rank你可以理解为人头排,而dense_rank按名次排,具体表现对相同名字的处理,如果有两个并列第二,那rank认定为已经有三个人头,那么后一个排名就是4,dense_rank就认为第二之后就是第三
8.NTILE按照分组以及对某个字段排序好后切片,也就是分成多少块,通过这个切片值,可以求前百分之多少的数据统计值
Impala
Impala底层是用C++写的,相对Java写的Hive更快些,也就是执行引擎不一样,语法和Hive语句语法大体一致,并且他们都是公用一个metastore,当然在Hue界面Impala下面如果没有表,你需要使用INVALIDATE METADATA 表名,刷新页面后,就可以在Impala下看到表
查询分区表时,在Hue上,Impala显示内容会比Hive更丰富,并且在hive增加分区后,需要在Impala下REFRESH 表名,才能看到新的分区
如果在Impala中新增表,Hive那边是实时同步的,不用做任何操作就能看到新增表
Impala在查询复杂字段(array,map等)时需要注意:直接select *查询不出这些字段,你需要在from表名后面,在加上表名.字段名
Impala在给内部分区表导数据时有区别,Hive直接load data操作就可以了,但是Impala load data前,需要先alter add partition操作,另外Impala不支持将表的数据按格式导出到本地或者HDFS上
Impala一般用在实时查询,因为查询速度快,那为什么呢?1.它直接读取HDFS磁盘内容,不走HDFS的api 2.使用内存更充分,Hive则是基于磁盘的; 另外你就理解为每个Impala d都是一个数据库,Impala类似分布式数据库
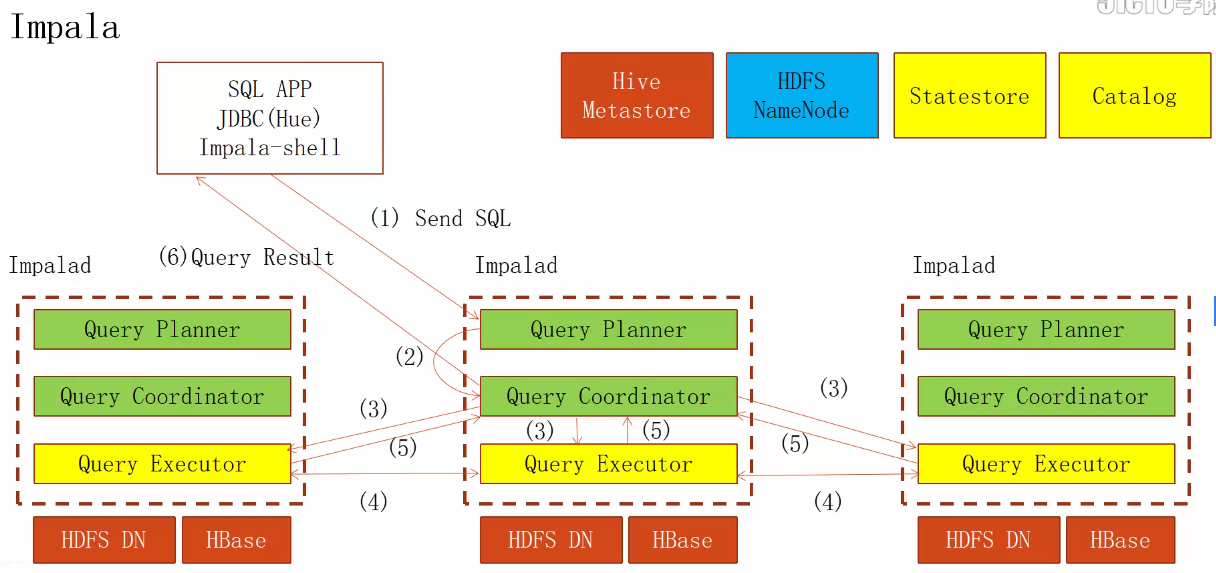
CDH
一般在公司里,使用的都是CDH版本的环境,它基本集成了所有常用的大数据组件,相对原生环境,CDH不用考虑组件之间的兼容性,CDH会做好,并且它也做到基本的运维和机器进行分离,比如查看服务的运行日志 或者 修改配置,都可以在CDH上操作;另外比原生的还多了一些服务,比如Security,集群的安全机制,另外需要多说一下的,就是Kudu,你可以理解这个就是兼顾改善HDFS不能随机读写和Hbase不能高吞吐两个缺点的技术组件,所以Kudu不仅利于高效随机读写,又利于SQL分析,另外CDH还改善了,让你可以在job运行完还能查看到运行日志,因为它里面会有JobHistory Server
CDH相关概念
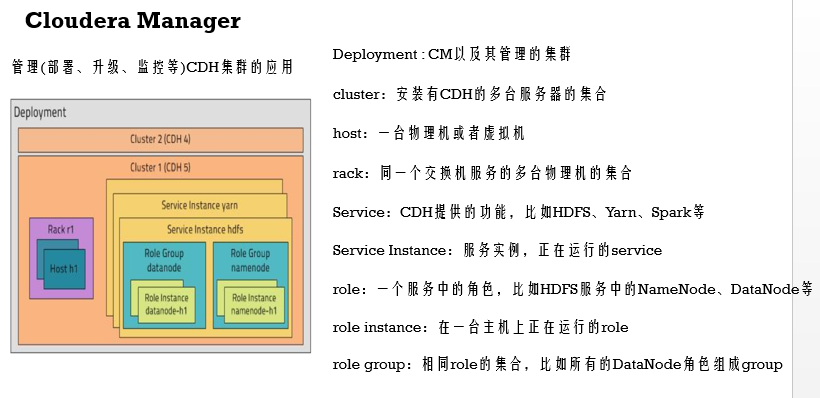
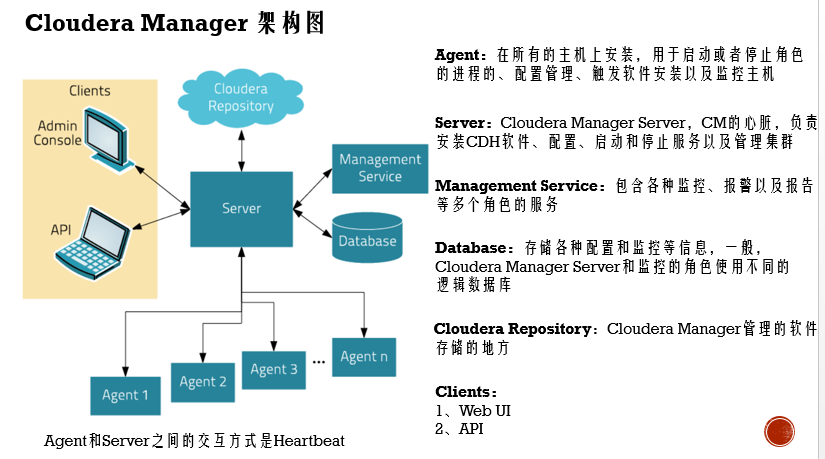
CDH能提供更简便服务,主要它自己还有额外一些服务组件来支撑的,比如启停各个服务,就需要CM的Server 和 Agent配合,这两个是通过心跳机制来控制的
CDH部署时的角色分布,集群需要资源计算方式,包每个角色最小需要的资源和生产资源配置建议,查看ppt和word文档
在版本选择上,企业通用是CM 5.14.3,CDH 5.14.2,注意版本兼容性的问题,这两者版本只允许在小版本上有差异才兼容,并且这个版本支持的os系统,我们用的是centos7.4
在CDH上你可以进行修改服务的配置,查看日志,查询hive/impala数据,任务调度等
另外需要注意的是:CDH是使用hdfs用户搭建集群的,所以在提交job时,切换到hdfs下执行,并且在启动集群时,优先启动基础服务,zk,hdfs,然后再启动其他服务,停掉集群则相反

