HBase重点总结
HBase的存储特点为三层Map,第一层为rowKey,第二层为列名(包括列族和列后缀),第三层就是版本(也就是时间戳),不仅支持分布式存储,还支持高效随机读写
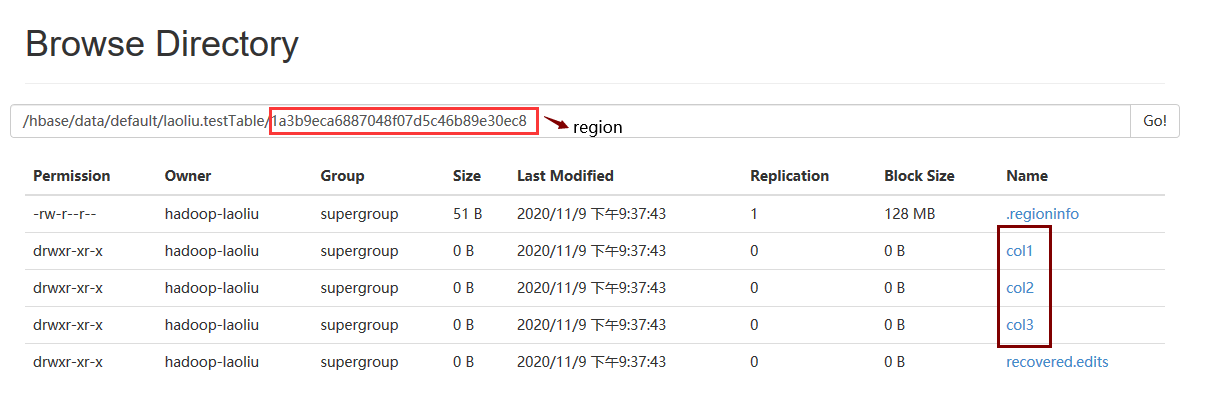
并且采取是列式存储,怎么体现的呢?这可以看hbase表在HDFS的存储目录结构,HBase的表是由多个region组织的,每个region负责存储基于rowKey一定范围的数据,其中每个region在HDFS上的体现也是一个目录,而region目录下都有以列命名的目录
由于HBase表的元数据信息管理依赖zookeeper,数据存储依赖HDFS,所以使用HBase服务之前,你需要先把zookeeper服务和HDFS启动起来
#三台都启动 zkServer.sh start zkServer.sh status # 启动HDFS start-dfs.sh #启动 hbase start-hbase.sh
进入命令行:hbase shell, 查看HBase表格元数据信息页面:http://master:16010,另外HBase表格存储数据的情况可以看HDFS监控页面:http://master:50070
多版本查询和TTL设置
单个值是怎么存储在HBase的表中:单个值,它是存储在HRegionServer的region下面的column family下面的HFile下面的block,然后在block中是以keyvalue的形式存储
数据块存储的编译和压缩:HBase在创建表时提供了两个配置选项(都是针对列级别进行设置),其中关注索引信息存储,比如rowKey过长或者某个column family含有很多column,则需要关注Block Encoder,创建表时通过DATA_BLOCK_ENCODING指定,并且推荐使用 FAST_DIFF, 如果是关注value信息存储,比如Value很大,则需要关注Compressors,创建表时通过COMPRESSION指定,一般推荐Snappy,如果不是热点数据,推荐GZ,因为这个压缩率高,但是压缩率高也意味着要更多cpu资源
数据检索过程过滤查询问题,也就是Bloom Filter,也是针对列进行设置的,创建表通过BLOOMFILTER指定,关注两个值,ROW和ROWCOL,我们知道每个ColumnFamily下的store会有多有HFile,默认情况下是会扫描所有的HFile的,但是如果设置Row,那么不含目标rowKey的 HFile就不会去扫描,而如果设置成ROWCOL,那么只包含目标rowKey和列后缀HFile才会去扫描,但是越精准就越需要存储空间和内存
HBase读缓存:在进行查询的过程中,优先会获取MemoryStore里缓存的值,这里面其实就之前写请求缓存的值,如果没有就获取Block Cache里的值,再没有,就会访问磁盘文件HFile中的值,在读频繁的场景下,你需要关注BlockCache的配置。。。。。读缓存有两种缓存策略:1.LruBlockCache,内存分配上是堆内存 2.BucketCache,内存分配上是系统内存,对于读缓存,缓存不可能是无限的,所以读缓存会有一个过期策略,分三种:1.FIFO(先进先出) 2.LRU(最近最少使用淘汰) 3.LFU(过去访问频率最低淘汰) ,并且这种策略下会给访问数据(Block)设定三个Block priority:1.Single access priority 第一次从HDFS加载到缓存 2.Muti access priority 再次访问 3.In-memory access priority:你可以理解为最高级别,访问多少次都不会被淘汰,比如hbase:meta表的列,这个在创建表格时,可以通过IN_MEMORY设置为true。。。。。上面提到的两种缓存策略中,HBase中默认是LruBlockCache,而BucketCache需要额外配置,其中这种缓存策略下还是依赖Lru缓存,当然BucketCache有种两种缓存模式,第一种,LRU缓存用于缓存Index Bloom等Meta block数据,BucketCache则用于缓存Data Block, 第二种则是LRU作为一级缓存,Bucket作为二级缓存(承接LRU淘汰下来的block)
StoreFile合并机制:HBase有一个写缓存机制,满足条件后才flush数据到HFile,一旦时间一长,很容易产生很多小文件,而HBase是基于HDFS上实现高效随机读写的,小文件影响HDFS的性能,所以就有这个HFile的合并机制,在Major compactions合并过程中,这个时间就会真正删除数据,比如多余版本和过期数据,Major操作默认7天自动执行 一次 ******手动操作*****
Region管理:主要是对region合理的切分以及合并region,其中避免热点写一个region,我们需要设置region的切分规则,这里主要包括预切分和自动切分两种机制,预切分等同 创建表格时就指定规则进行切分region,比如通过SPLITS或者SPLITS_FILE指定区间进行切分, 或者通过NUMREGIONS 和 SPLITALGO来指定region数据和切分规则,比如切分规则HexStringSplit,就是按照rowKey的十六进制进行切分。。。。。另外就是自动切分了,它也有两种自动切分策略:1.ConstantSizeRegionSplitPolicy(达到指定大小切分,默认10G) 2.IncreasingToUpperBoundRegionSplitPolicy(根据region数和配置的region值决定切分,这个是默认的策略) 3.KeyPrefixRegionSplitPolicy(前缀相同的rowKey放在同一region) 除了上面两种切分机制,你还可以自己执行切分命令, split 表 rowKey。。。。。当然region太多也不好,很容易触发StoreFile合并机制,也不利于元数据表格管理,很影响性能,造成region太多的原因就是预切分或者自动切分的规则不合理,比如Region file size太小,另外为了避免一个RegionServer上 太多region,合并region可以通过手动执行merge_region,HBase有个Balancing机制,HMaster每隔5分钟会进行一次
HBase schema设计原则:1.每个region大小控制在10G和50G 2.每个table控制在50-100个region 3.每个table控制在1-3个column family(设计原则:从数据存储特性出发,比如这些数据要压缩) 4.每个column family命名最好要短,节省磁盘和内存空间
RowKey设计原则:建议短,控制在10-100字节,这样做可以提高HFile和MemStore内存的存储效率,另外设计时可以考虑操作系统的最佳性能,把RowKey设计成8字节的倍数(64位系统),另外还需要考虑大量相似key的请求对同一region热点写的问题:常见手段就是加盐(随机添加前缀,但是这种查询时不太方便)和Hashing(对rowKey取md5值),除了这两种手段,当然在特殊场景下,比如时间戳,可以反转RowKey,除此外当然要考虑业务场景了,如果要把同一主域的网站放在同一region里,也可以反转RowKey

 浙公网安备 33010602011771号
浙公网安备 33010602011771号