
Hbase
在讲Hbase之前,可以先用一个生动例子来引入,百度在进行搜索的是怎么进行存储的呢?我们知道搜索引擎是根据关键词搜索来给到一批网页,所以它事先有一个爬取网页的操作,并进行存储,主要包括url,页面内容,页面语言等内容 ,这样用户在搜索时,搜索引擎根据自己的权重算法把相应的网页从存储库中取出来 给到客户,随着网页越来越多,网页量是非常大,传统数据库无法满足,主要是扩展性不好,因为大数据量,最好用分布式存储
另外上面的网页也不是一成不变,网页会随时发生变更,所以存储必须支持随机增改删,并且存储格式采用三级Map的格式,如下,并且每个value有多个时间版本
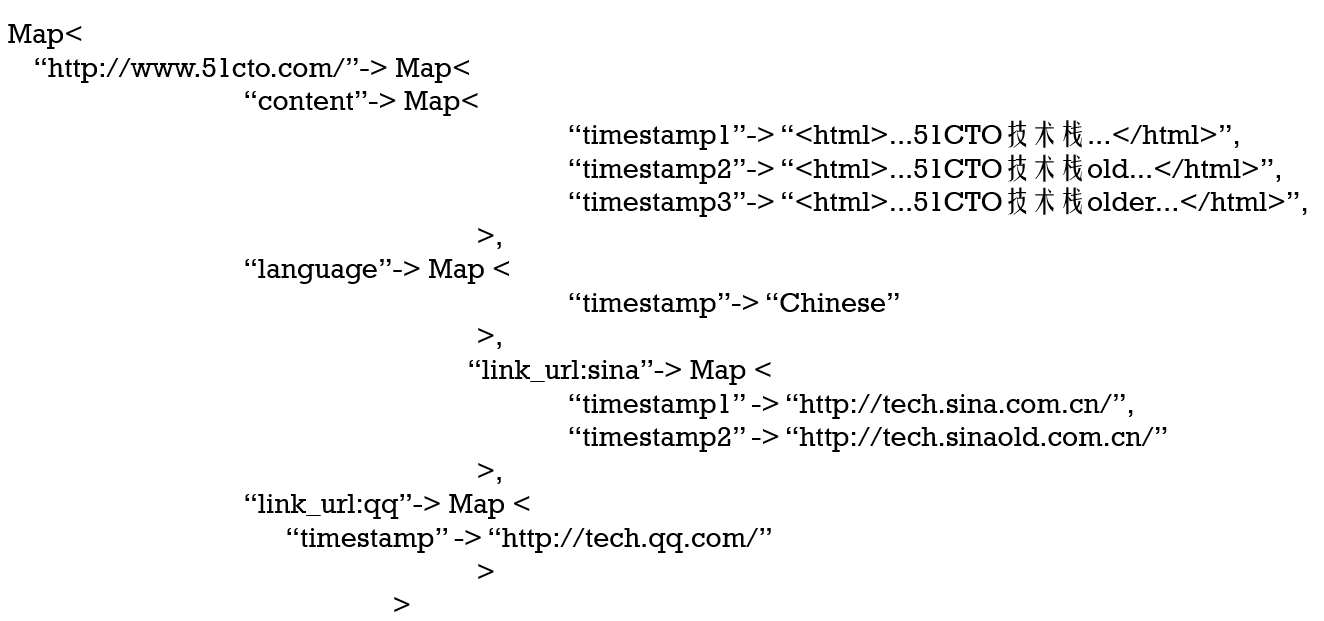
1.Hbase核心原理
上面讲过,满足上面的存储场景必要支持这么两个特点:1.分布式存储,2.支持高效随机读写,而分布式存储,我们首先会想到HDFS,没错,其中HBase能解决上面问题,它就是基于HDFS支持高效随机读写的数据存储,HBase是列式存储数据库
安装
前提是:安装java8、安装了hadoop2.7+以及安装了zookeeper3.4+
1、下载: http://mirrors.shu.edu.cn/apache/hbase/
hbase-1.2.6-bin.tar.gz 上传到master上的/home/hadoop-twq/bigdata下
2、以hadoop-twq的账号进入到master服务器,
cd bigdate
解压:tar -xvf hbase-1.2.6-bin.tar.gz
3、cd hbase-1.2.6/conf
vi hbase-env.sh 设置如下:
export JAVA_HOME=/usr/local/lib/jdk1.8.0_161/
export HBASE_CLASSPATH=/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop
export HBASE_MANAGES_ZK=false
vi regionservers 增加如下配置:
slave1
slave2
vi hbase-site.xml 增加如下配置
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9999/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
4、将hbase-1.2.6拷贝到slave1和slave2上
scp -r ~/bigdata/hbase-1.2.6 hadoop-twq@slave1:~/bigdata/
scp -r ~/bigdata/hbase-1.2.6 hadoop-twq@slave2:~/bigdata/
5、在master上配置HBASE_HOME以及环境变量
6、start-hbase.sh 启动HBase
jps验证
访问HBase的Web UI:http://master:16010
7、hbase shell 连接HBase集群,进行命令操作
HBase操作命令
先来一张图解释下HBase存储结构下的概念
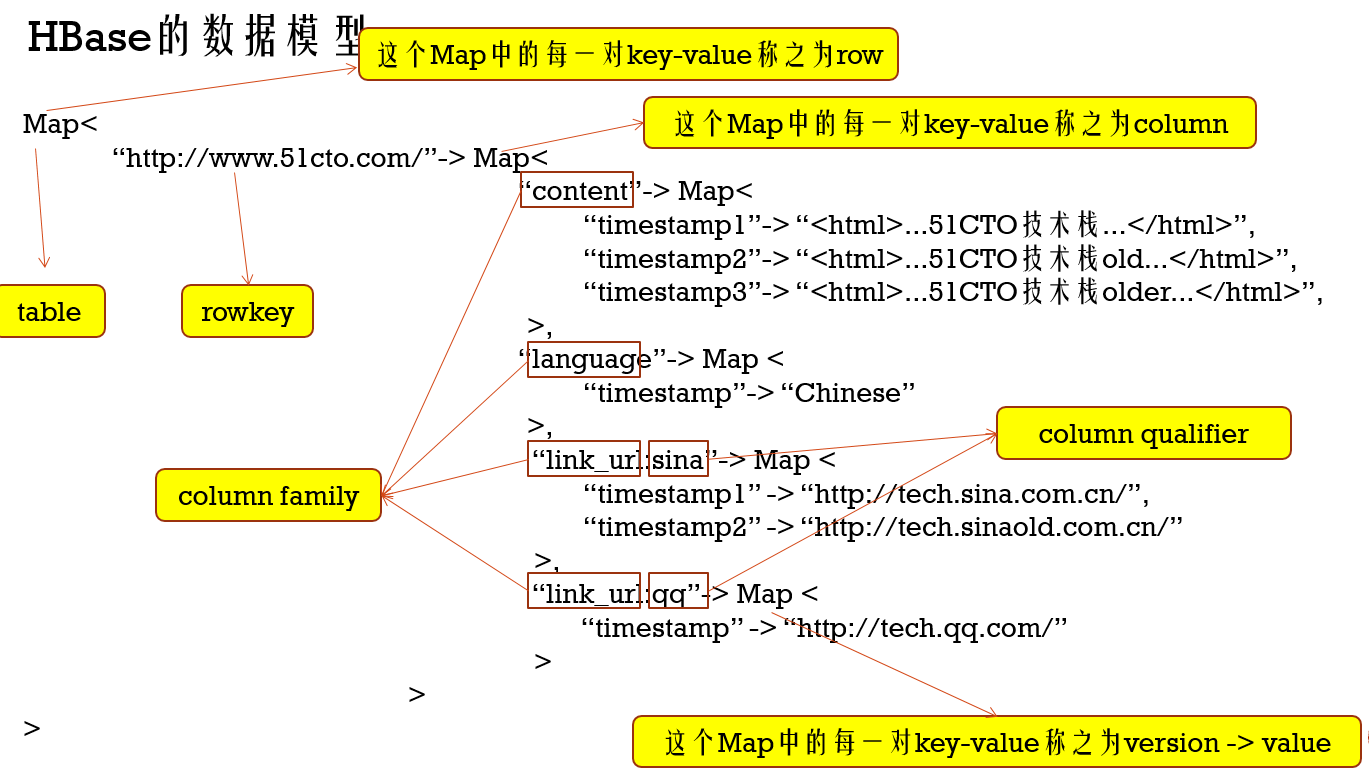
hbase shell
create 'webtable','content','language','link_url' => 创建一个名字为webtable的HBase表
list => 列出HBase表
向HBase表中webtable中put数据
put 'webtable','http://www.51cto.com/','content','<html>...51CTO技术栈...</html>'
put 'webtable','http://www.51cto.com/','language', 'Chinese'
put 'webtable','http://www.51cto.com/','link_url:sina','http://tech.sina.com.cn/'
put 'webtable','http://www.51cto.com/','link_url:qq','http://tech.qq.com/'
scan 'webtable' {LIMIT => 3}
put 'webtable','http://www.51cto.com/','content','<html>...51CTO技术栈_NEW1...</html>'
put 'webtable','http://www.51cto.com/','content','<html>...51CTO技术栈_NEW2...</html>'
get 'webtable','http://www.51cto.com/','content'
get 'webtable','http://www.51cto.com/',{COLUMN => 'content',VERSION => 10}
put 'webtable','http://www.51cto.com/','content','<html>...51CTO技术栈_NEW3...</html>'
get 'webtable','http://www.51cto.com/',{COLUMN => 'content',VERSION => 10}
put 'webtable','http://hbase.apache.org/','content','<html>...Welcome to Apache HBase...</html>'
put 'webtable','http://hbase.apache.org/','link_url:hadoop','http://hadoop.apache.org/'
scan 'webtable'
get 'webtable','http://www.51cto.com/'
get 'webtable','http://www.51cto.com/','link_url:qq'
delete 'webtable', 'http://www.51cto.com/', 'link_url:sina'
scan 'webtable'
创建namespace:
list_namespace => 列出有哪些namespace
create_namespace 'my_ns'
create 'my_ns:my_table','fam'
drop_namespace 'my_ns'
disable 'webtable'
drop 'webtable'
create_namespace 'twq'
exit
create 'webtable',{NAME => 'content'},{NAME => 'language'},{NAME => 'link_url'}
# 创建表格时默认只保存一个时间版本的值,如果需要多个版本的值,再创建表格时,给列指定VERSIONS保存多少个,在get时,给列指定获取多个版本的值
create 'webtable_version',{NAME => 'content'},{NAME => 'language', VERSIONS => 1},{NAME => 'link_url'}
put 'webtable_version', 'http://www.51cto.com/','language', 'English'
put 'webtable_version', 'http://www.51cto.com/','language', 'Chinese'
get 'webtable','http://www.51cto.com/',{COLUMN => 'language',VERSIONS => 10}
# ttl指定某列的值过期时间,单位为秒
create 'webtable_ttl',{NAME => 'content'},{NAME => 'language', VERSIONS => 1},{NAME => 'link_url', TTL => 5}
put 'webtable_ttl','http://www.51cto.com/','link_url:sina','http://tech.sina.com.cn/'
get 'webtable_ttl','http://www.51cto.com/',{COLUMN => 'link_url:sina'}
alter 'webtable_ttl',{NAME => 'link_url', TTL => 3}
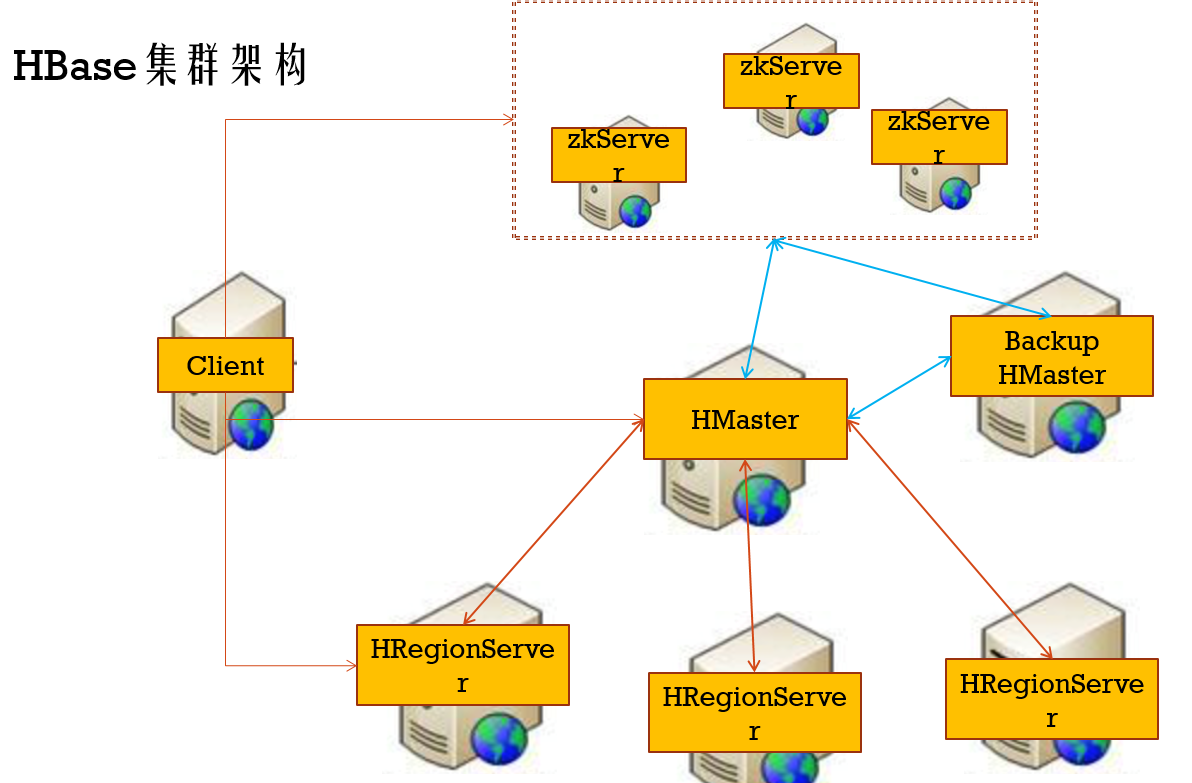
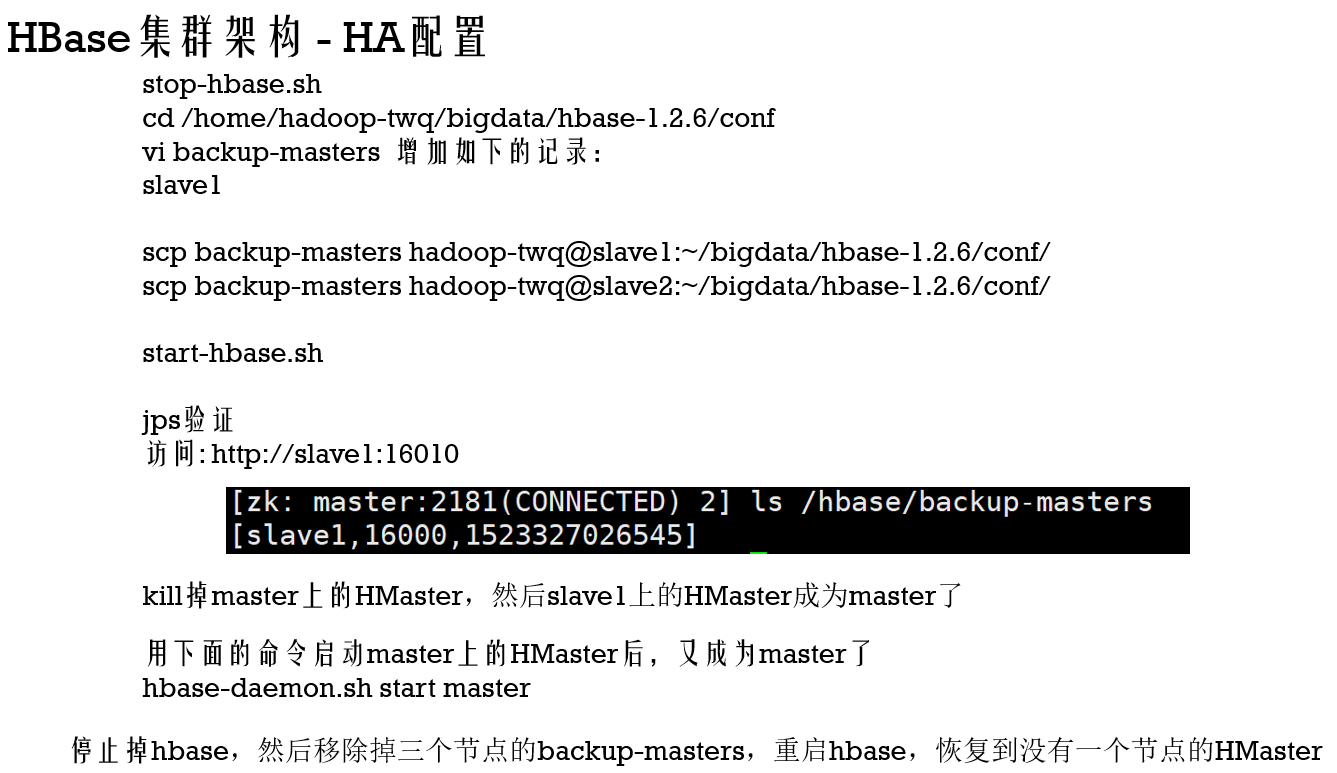
HA配置
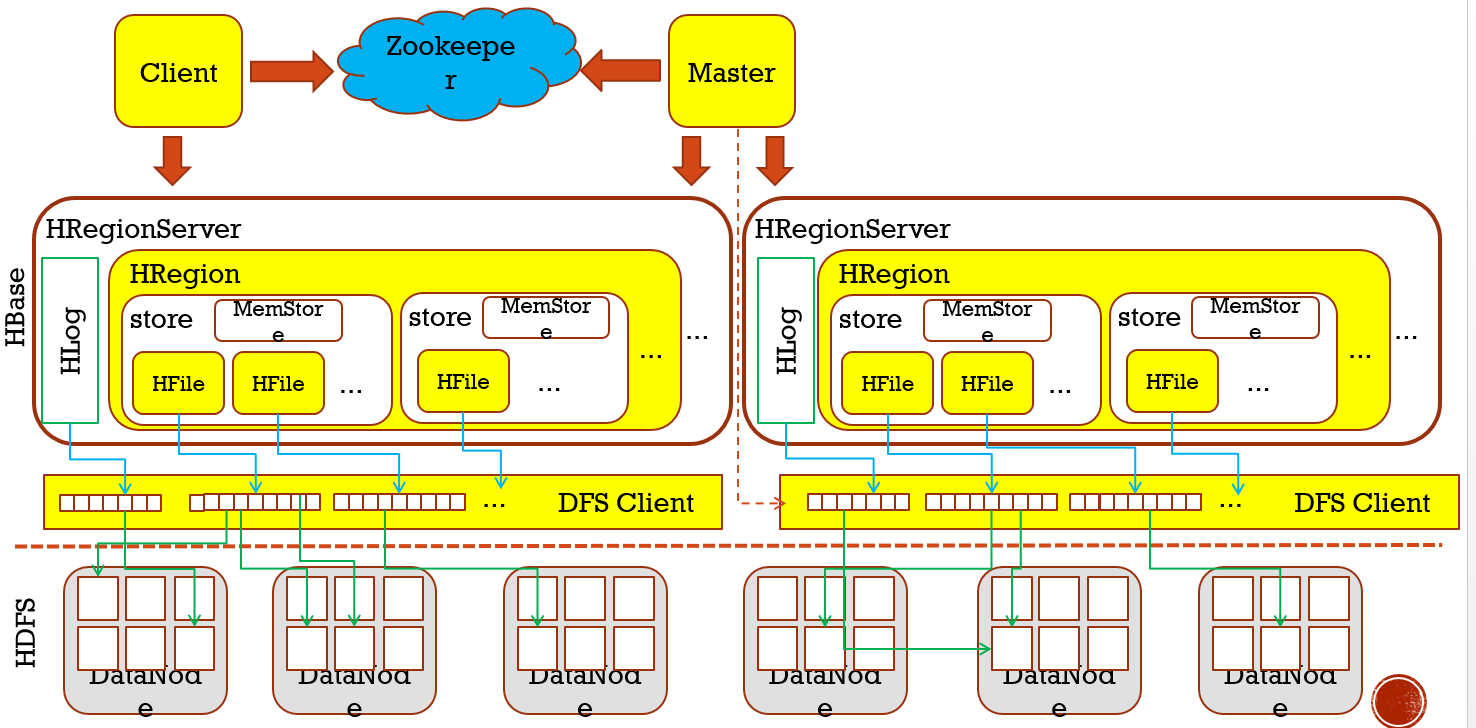
***HBase的表格组织形式
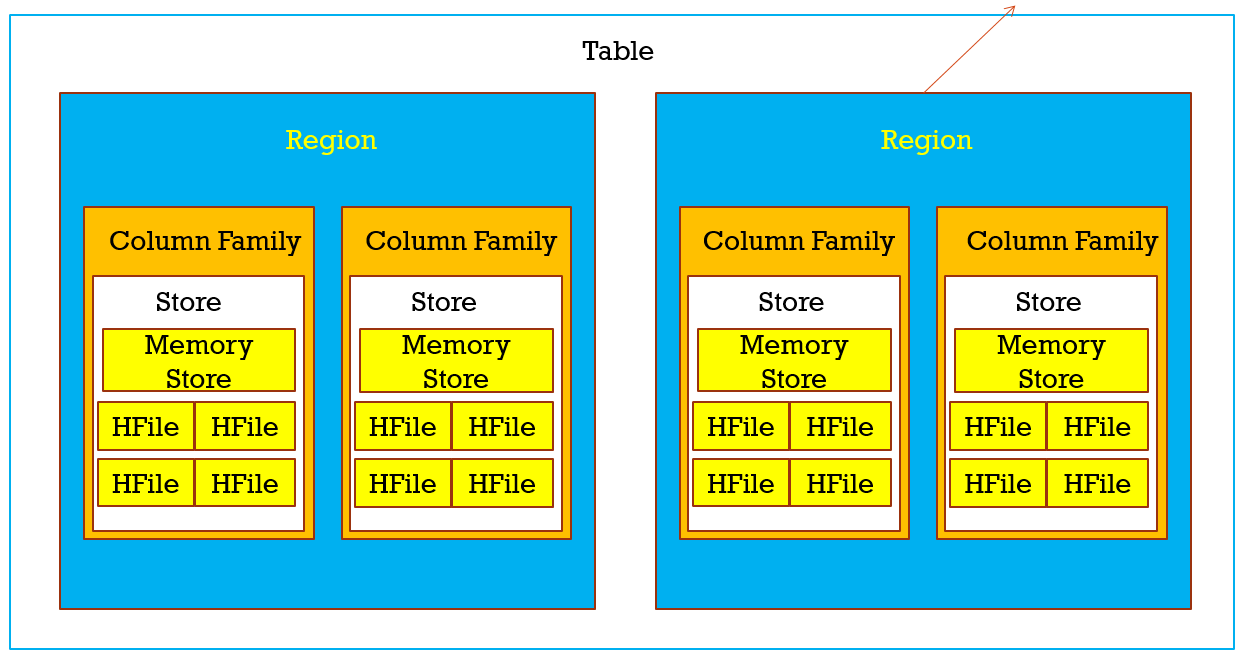
看下面这张图,它存在如下组织关系 :
- 每张Table由多个Region组成(这里的region可以理解为像HDFS中的块),HBase是采用HMaster-HRegionServer主从 架构模式,所以region会采用分布式的方式存储在HRegionServer上,每个Region负责管理和存储一个Table中的某段数据,并且每个table的RowKey是按照字符串的自然顺序升序排列,你可以在Hbase的UI查看每个region的管理范围,StartKey和EndKey
- 每个Region下,有多个Column Family,一般table在创建时有几个列,那么Region就会有几个Column Family,所以会是一个或者多个,这个你可以HDFS UI的hbase/data目录找到自己的namespace和table,可以table有几个随机字符串的目录,有几个这样 的目录就有几个region,每个region下,又能 看到各个列,,,
- 一个Column Family对应一个Store,每个Store包含一个MenoryStore和若干个HFile
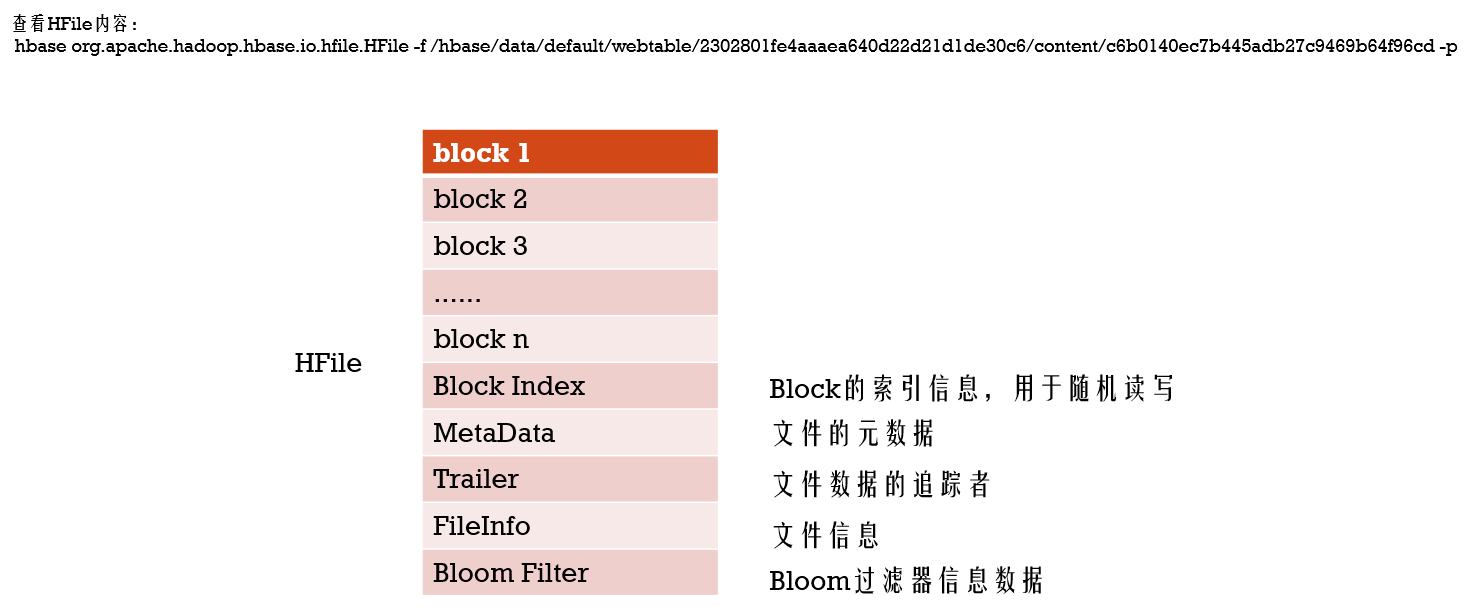
- 每个HFile会有若干个不同类型的Block(Block的大小通常为8K到1MB,默认的大小是64KB),其中Block类型分为:Data Blocks,Index Blocks,Bloom filter Blocks以及Trailer block
这个配置控制每一个Region的大小:
<property>
<name>hbase.hregion.max.filesize</name>
<value>52428800</value> # 50M 默认是10G
</property>
***HFile格式
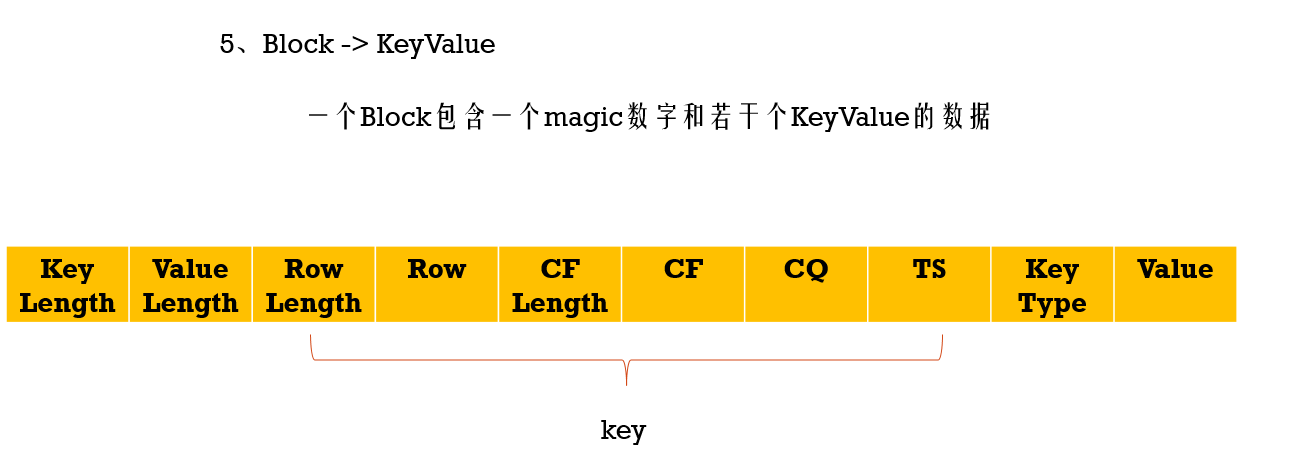
HFile下会有多个Block,而Block下存储的就是KeyValue数据,而且下面的数据是按照key排序的,查找是会根据Block索引找到对应的 block数据
到现在就可以回答第一个问题了,单个值是怎样存储在HBase的表中的,它是存储在HRegionServer下的region里的colum family下的 HFile下的 block下的keyvalue数据
Compressors
create 'test_encoder_compress', {NAME => 'c', COMPRESSION => 'SNAPPY', DATA_BLOCK_ENCODING => 'FAST_DIFF'}, {NAME => 'l'}
create 'test_encoder_compress', {NAME => 'c', COMPRESSION => 'GZ', DATA_BLOCK_ENCODING => 'FAST_DIFF'}, {NAME => 'l'}
Bloom Filter

这些值是怎么一起存储在文件中而组成一张表的?
多个KeyValue存储成 一个HFile下的一个block,多个block(包括Data Block,Index Block等)组成一个HFile,多个HFile组成一个Column Family,多个Column Family组成Region,多个Region组成一张table
2.Hbase读写路径
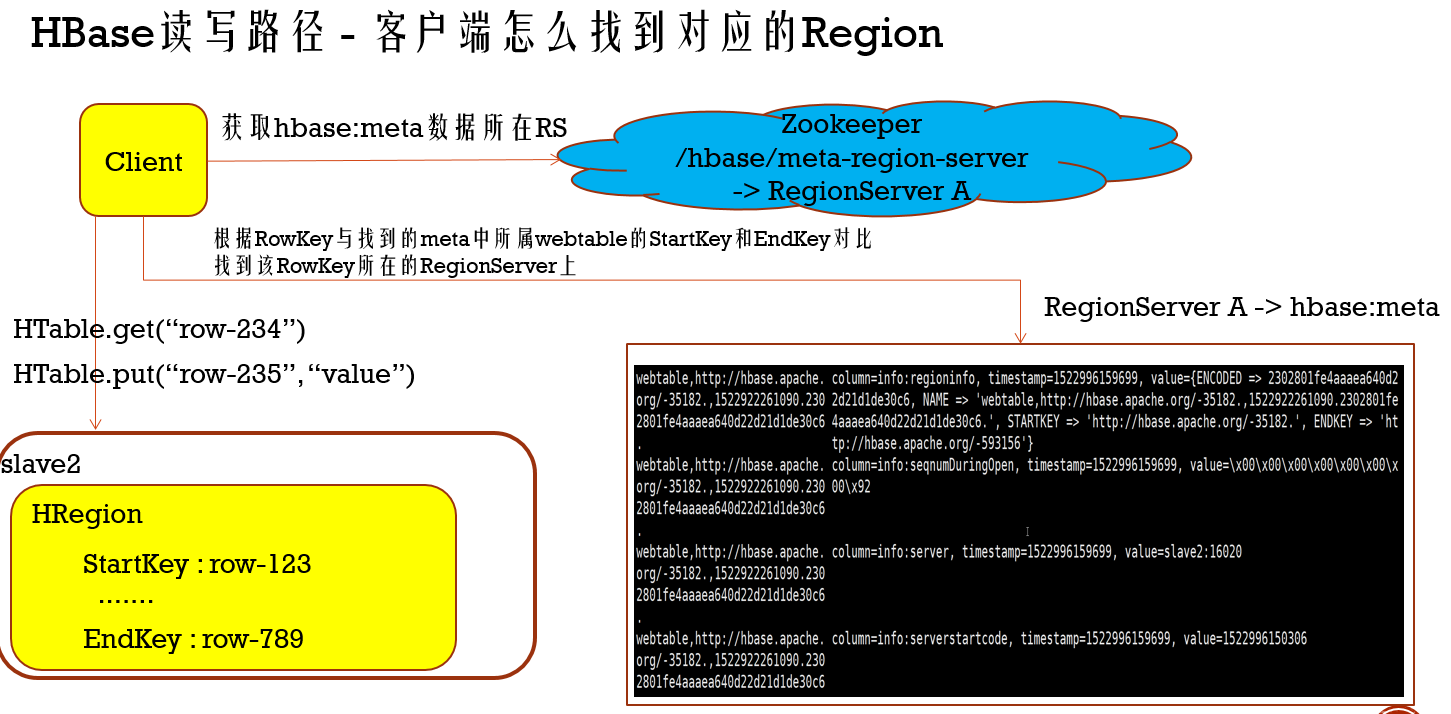
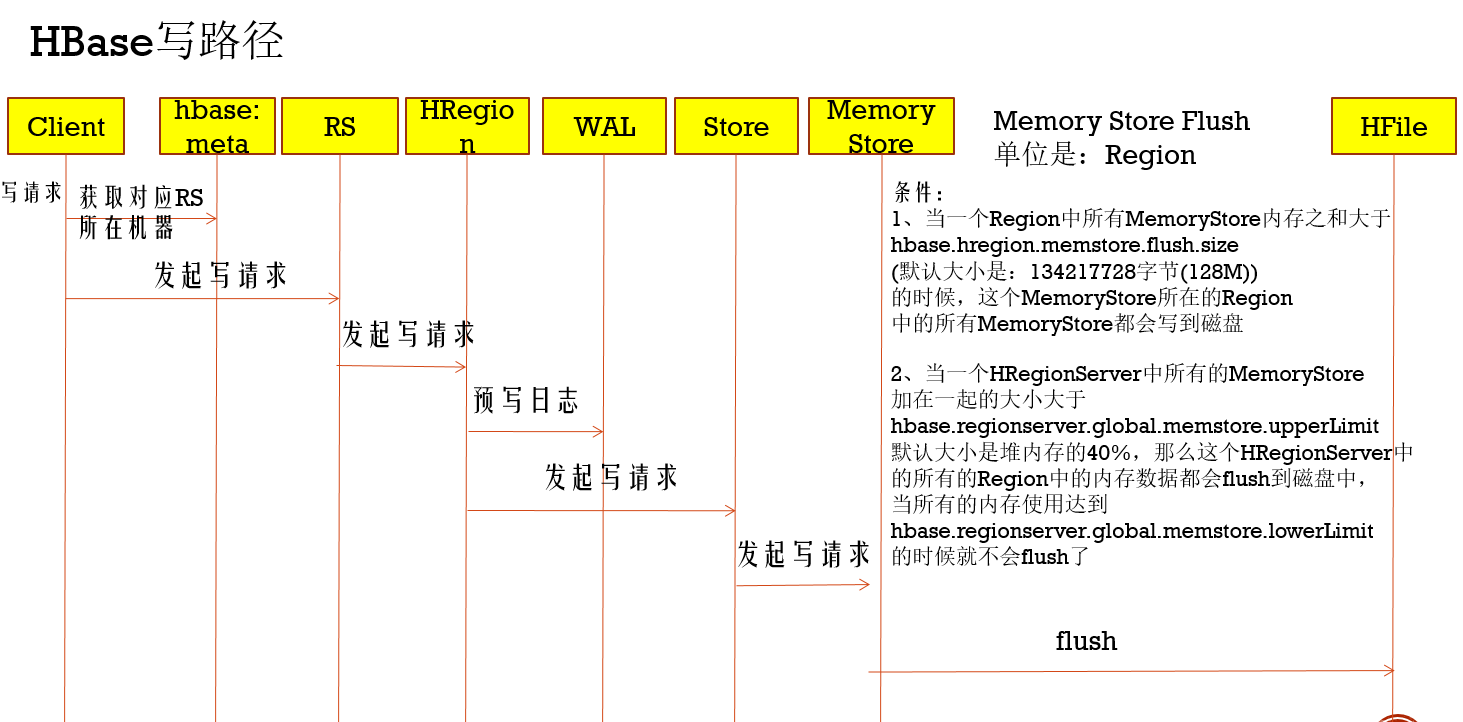
***Hbase读写流程大概是这个样子(3次请求模型):
- 获取元数据表的RegionServer,第一次请求是请求Zookeeper,在/hbase/meta-region-server下会记录元数据表是在哪个RegionServer
- 获取RowKey的数据所在region,第二请求是请求元数据表的RegionServer,这里会记录每个table的RegionServer和region信息,根据传过来的RowKey和每个Region的范围(就是StartKey和EndKey)比较,从找对应的region
- 向对应的Region里进行读写操作
写缓存机制
在对HBase写入操作过程中,有Memory Store的,用于写数据临时缓存,等达到一定条件的写入量后就会写入到HFile中,并且通过这个写缓存机制可以提高写的效率,所以如果在频繁写的场景,可以提高这个缓存内存
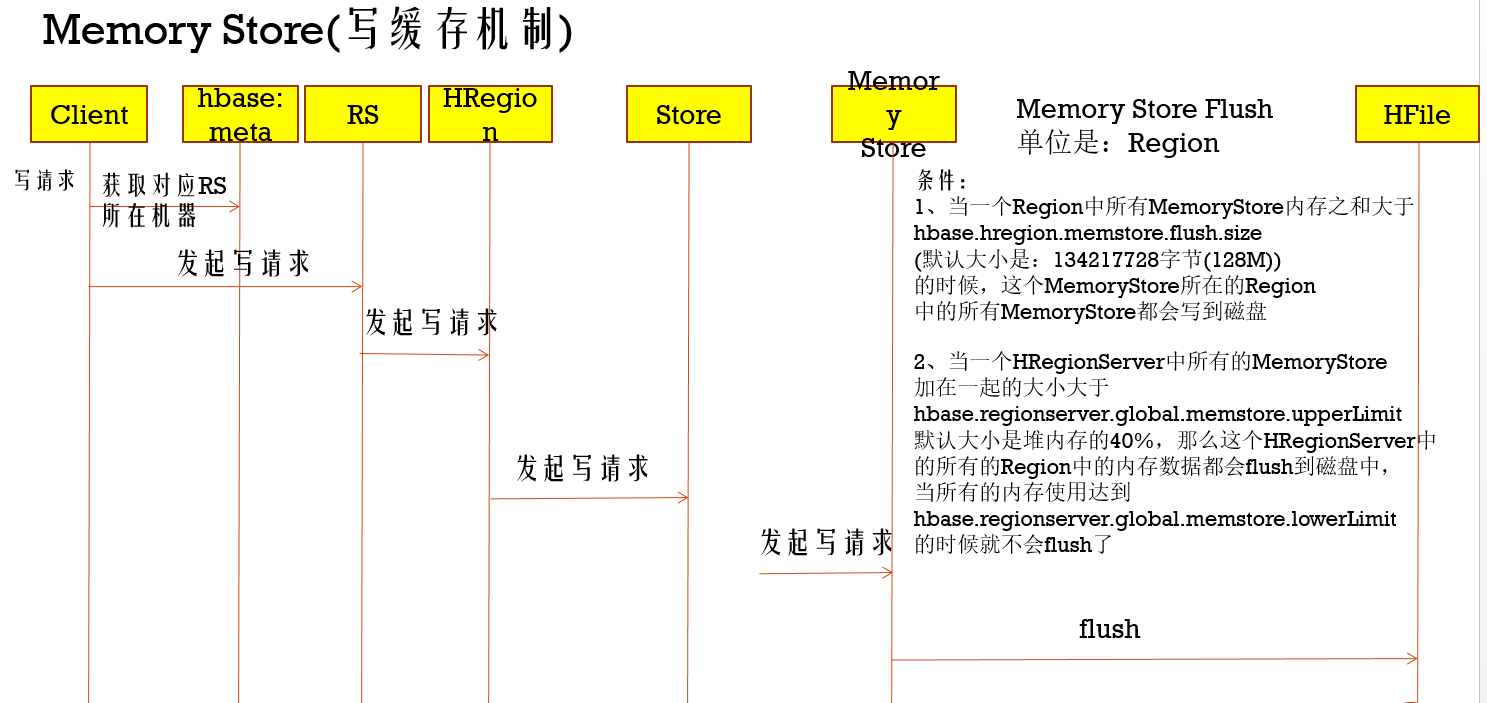
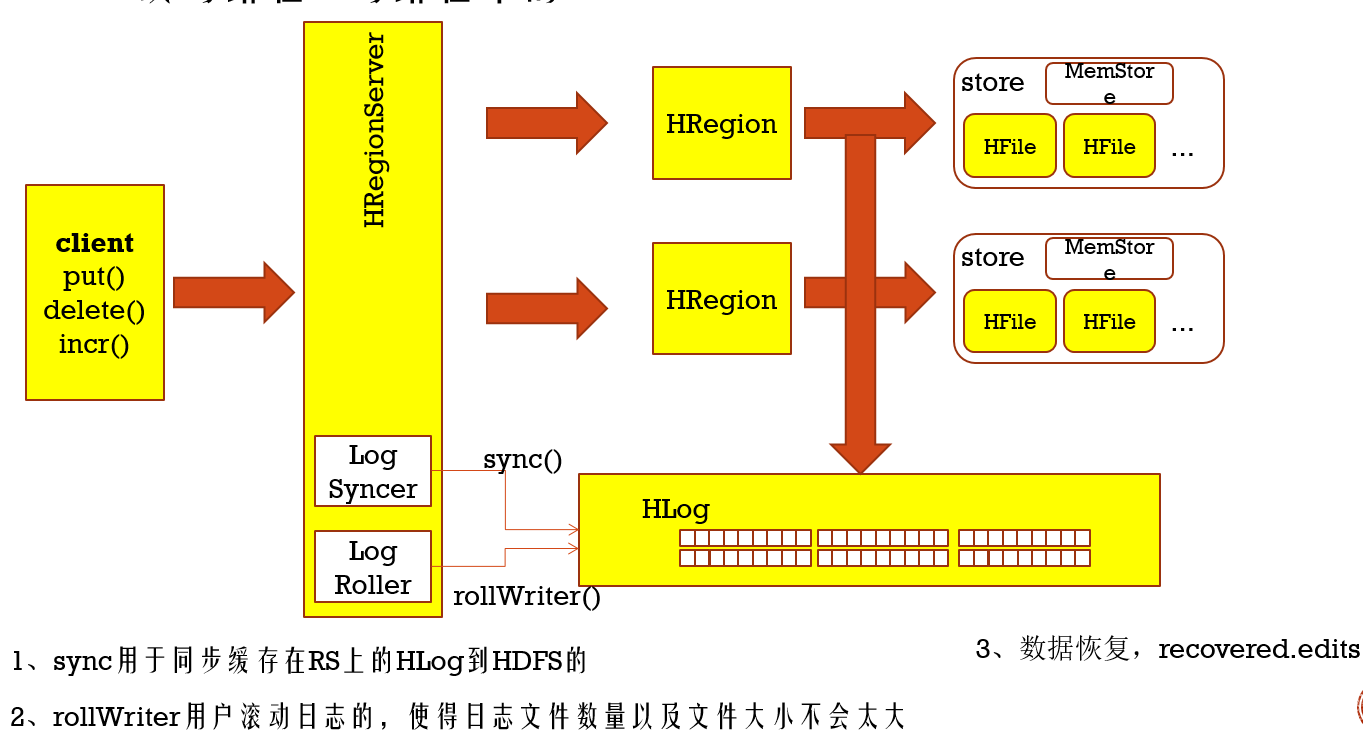
在上面写缓存过程,由于要等一定时间才会写入磁盘中,一旦RegionServer挂掉了,那么数据就丢失了,别慌了,Hbase提供预写机制WAL,就是在写入Memory Store之前,先写入HDFS中
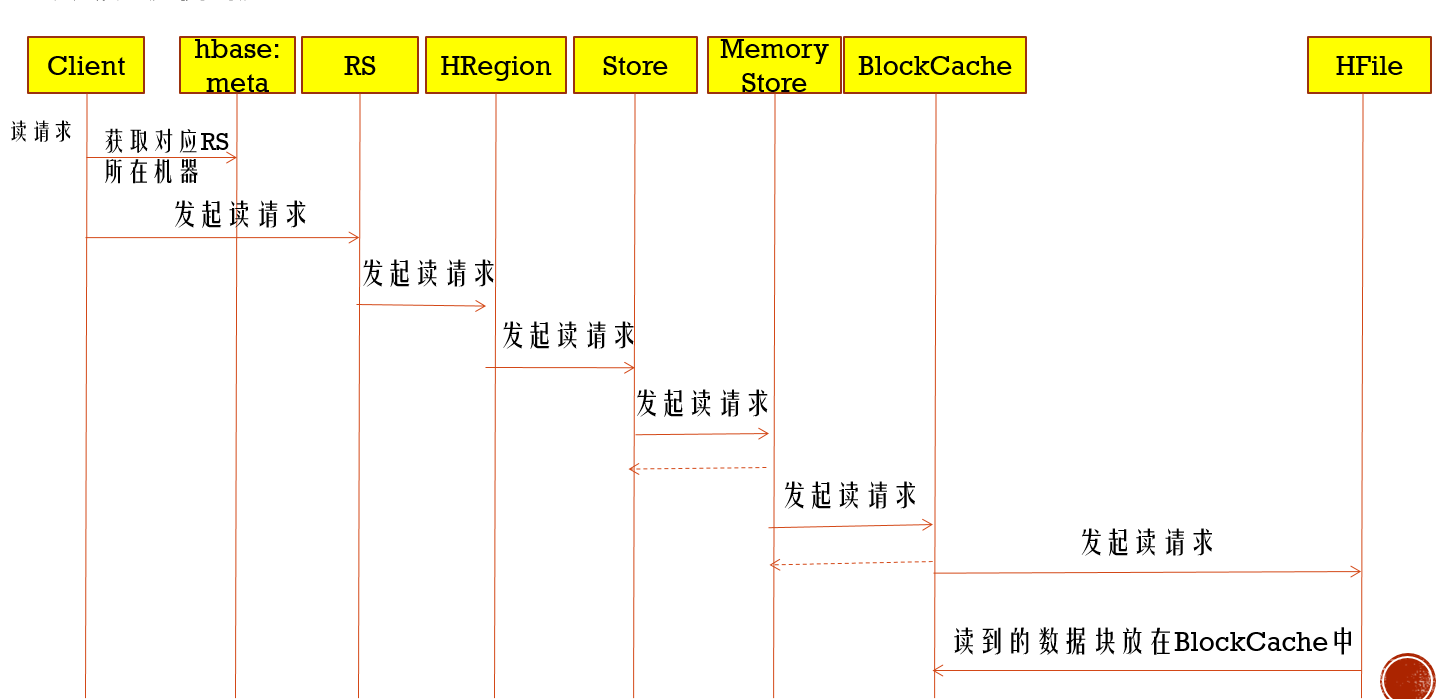
读缓存机制
读的时候,有两个地方稍微需要注意下:就是在读取Column Family里Store时,会先去读Memory Store里的数据(写时候缓存的数据),如果这里没有,就会去读Block Cache,要是再没有,只能读磁盘文件HFile,所以在读频繁的场景,可以把提高Block Cache内存
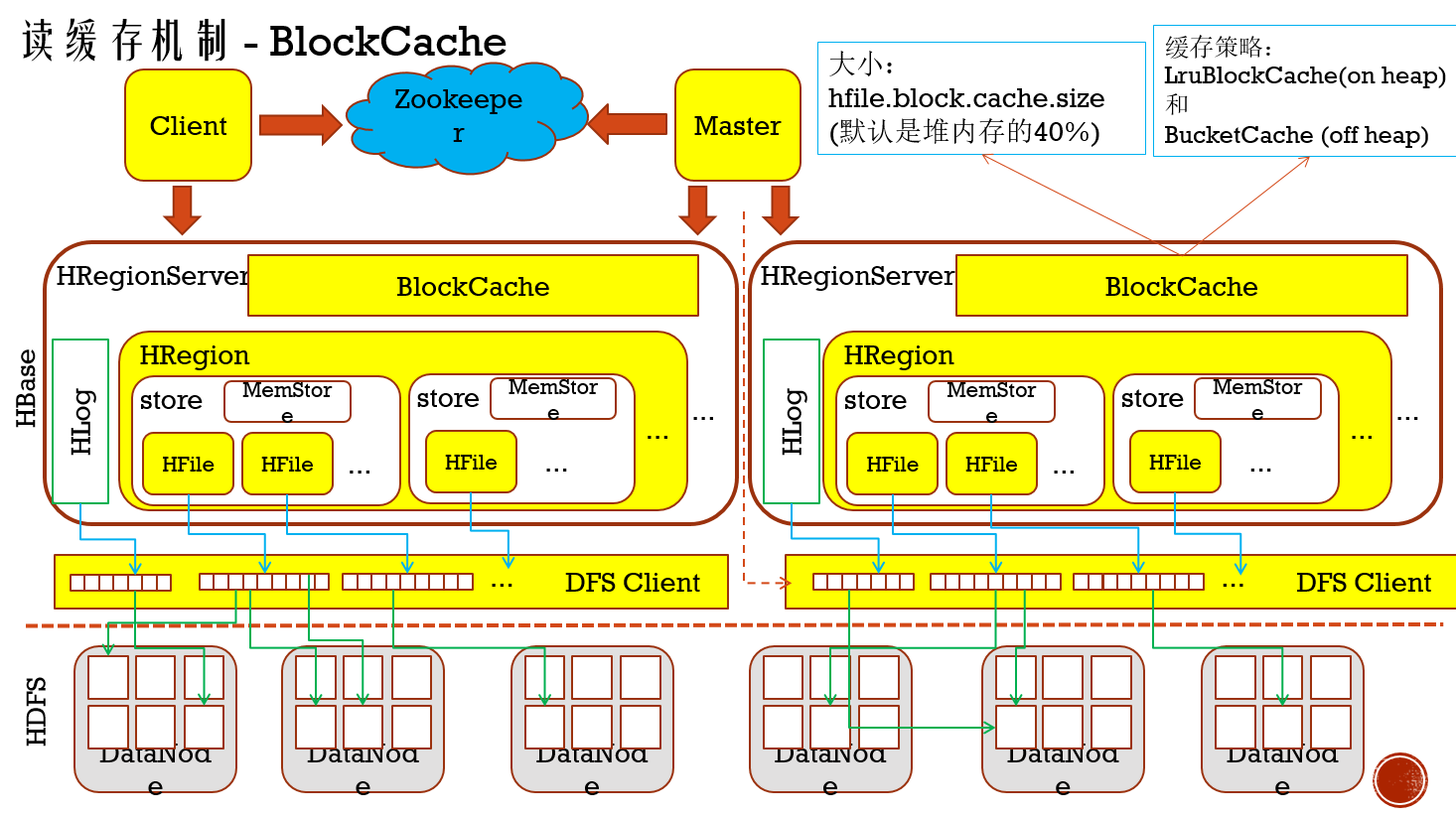



LruBlockCache是默认的缓存策略,下面BucketCache

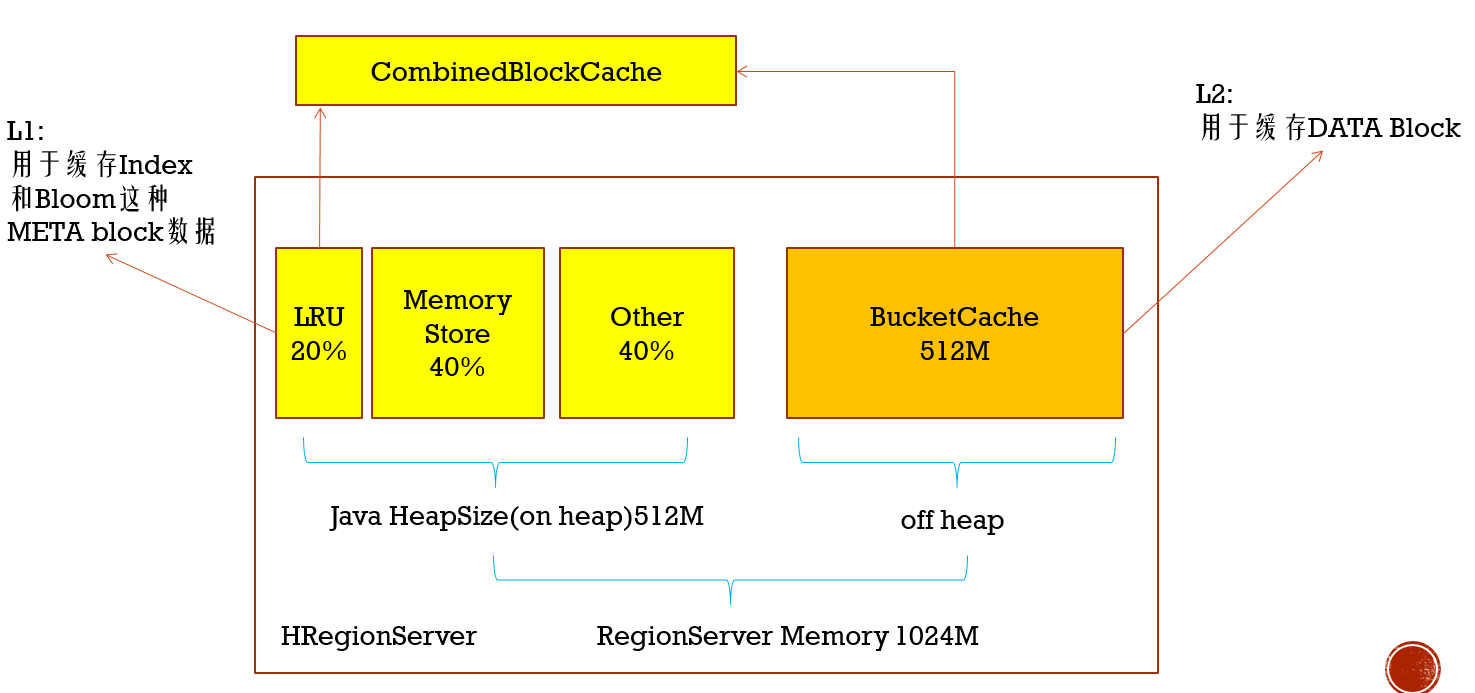
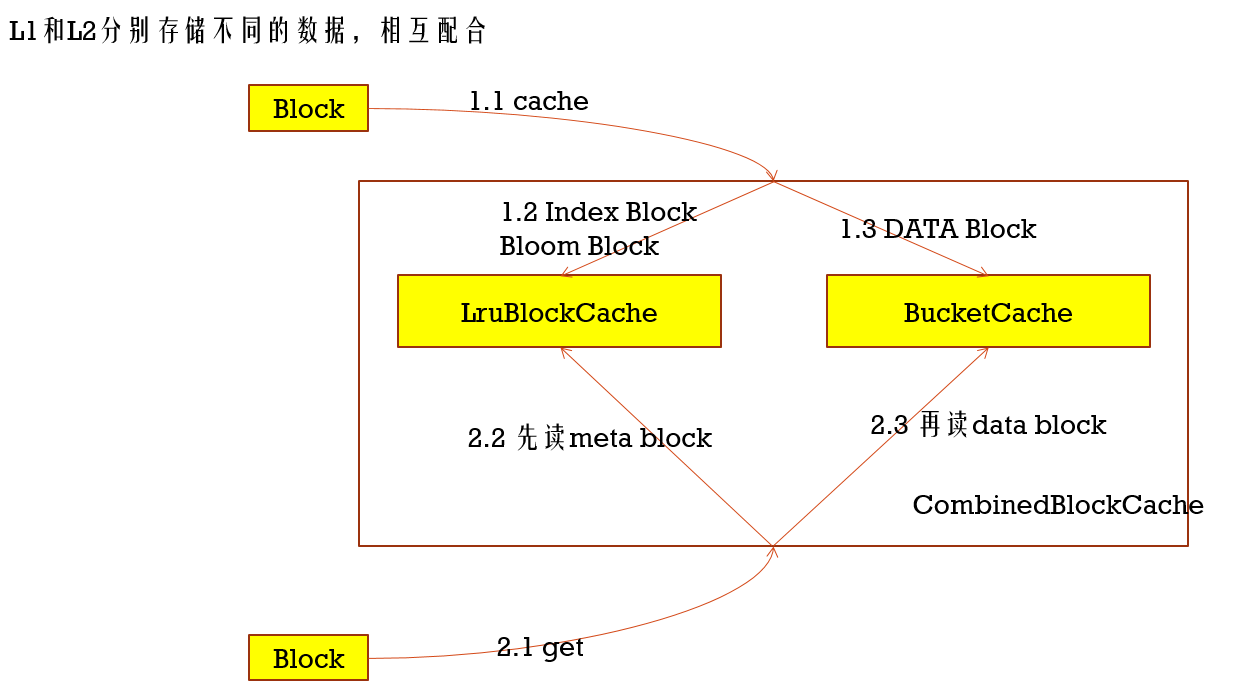
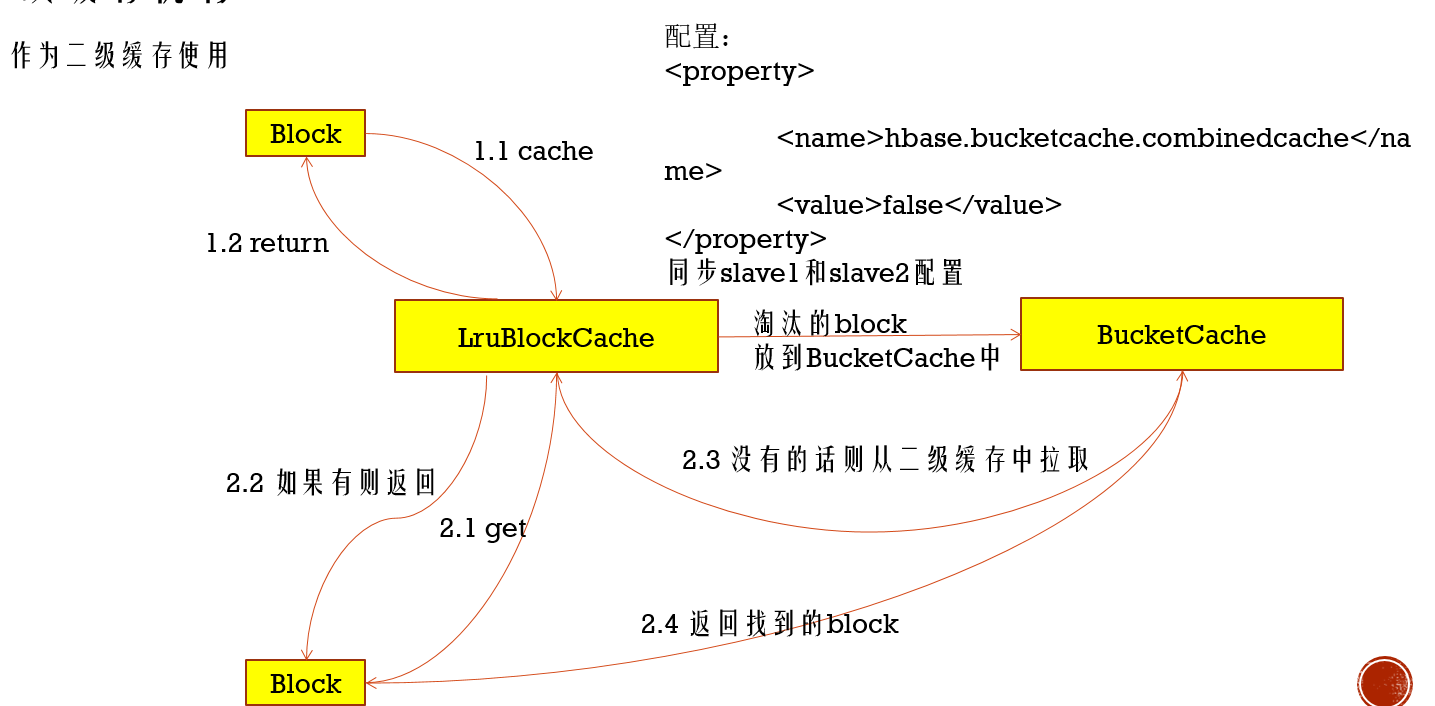
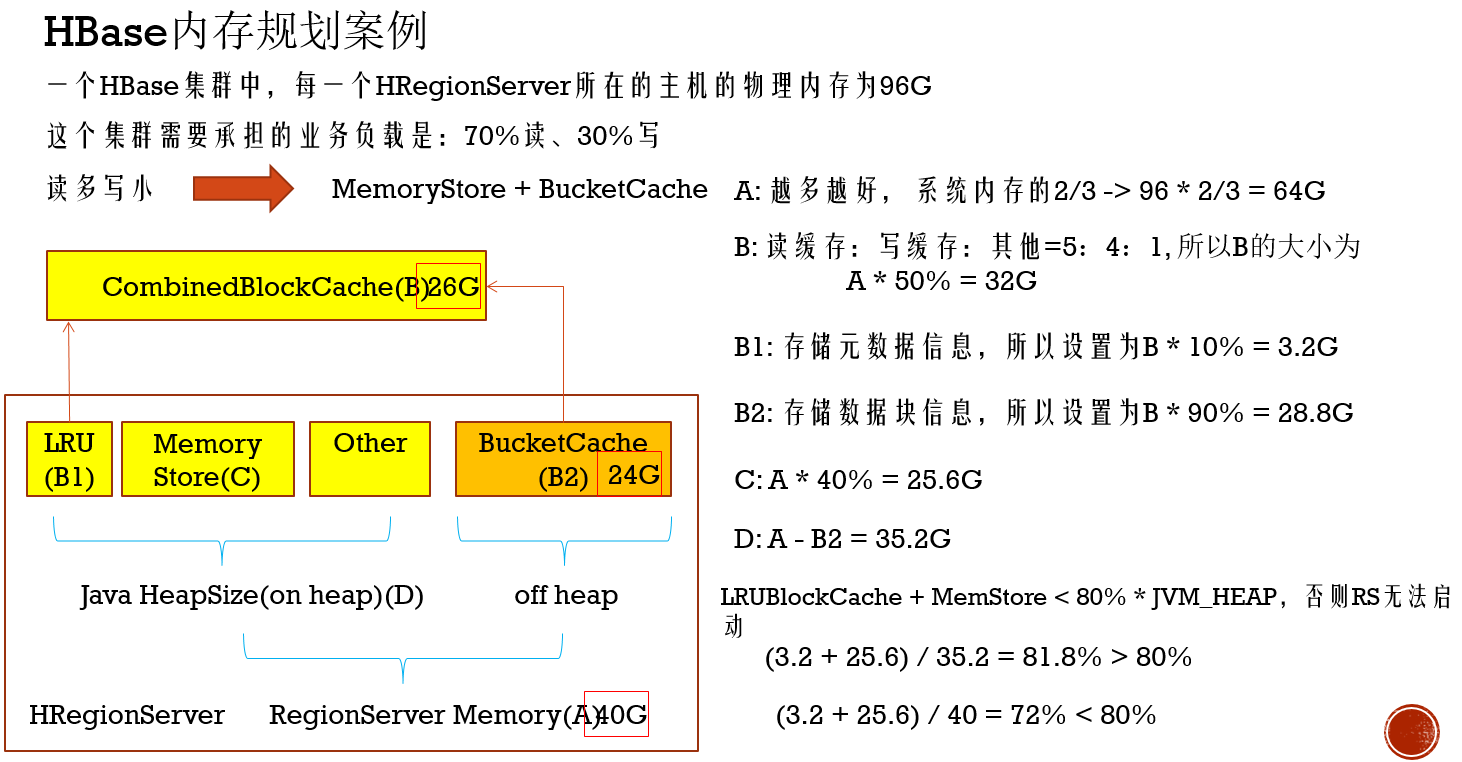
HBase内存规划案例


3.Hbase高级特性
Compaction(StoreFile合并机制)
在写Hbase过程中,有一个写缓存机制,数据暂时写在MemStore中,只有满足两个条件中其一,就会flush到磁盘中,但是随着时间一长,Store中的小HFile会越来越多,这样性能是会下降的,那Compaction机制就对HFile进行合并
其中上面说过,在进行删除操作时,本质上 没有对数据进行删除,只是把删除的数据标了一个状态,数据的删除(包括多余版本,过期数据)是这里进行的

create 'test_compaction','f1','f2' put 'test_compaction','row-1','f1','test-f1' put 'test_compaction','row-1','f2','test-f2' flush 'test_compaction' put 'test_compaction','row-2','f1','row2tese' delete 'test_compaction','row-1','f1' deleteall 'test_compaction','row-1' flush 'test_compaction' 手工major compaction: major_compact 'test_compaction' 也可以在监控界面中进行手工compaction
Region Split
在创建表格完后,我men在HBase UI上可以看到,这张表格默认分配一个Region,如果在刚开始的时候,有大量数据写入,那么Region的Server承受的压力非常大,那么这个时候就需要对Region进行切分了,一般分预切分和自动切分两种机制
预切分就是在创建表格就切分好,而自动切分则是按照某些规则,在数据增长过程中切分
预切分在创建表格需要给定一个范围list,下面会有给的三个值表示四个范围,就会有4个region,其中几个值也决定了每个region的StartKey和EndKey,当然也可以指定文件把范围传进来
create table with four regions based on random bytes keys:
create 't2','f1', { NUMREGIONS => 4 , SPLITALGO => 'UniformSplit' }
//节省空间,但是可读性比较差,用于rowkey是随机的字节的情况
最小值为(byte)0x00
最大值为(byte)0xFF
create table with five regions based on hex keys
create 't3','f1', { NUMREGIONS => 4, SPLITALGO => 'HexStringSplit' }
//需要更多的空间,但是可读性比较好,用于十六进制字符串的rowkey
最小值为00000000
最大值为FFFFFFFF
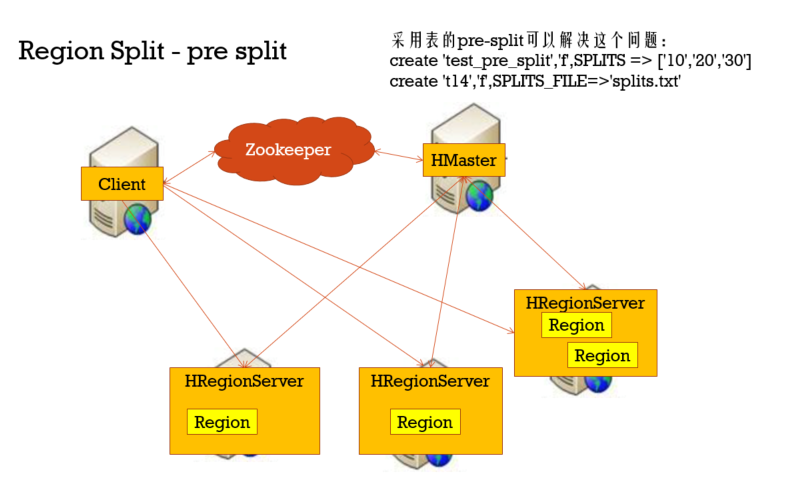
自动切分

1、在hbase-site.xml中配置全局默认的切分策略
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>
2、使用Java API在创建table的时候指定切分策略
HTableDescriptor tableDesc = new HTableDescriptor("test");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, ConstantSizeRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("cf1")));
admin.createTable(tableDesc);
----
3、使用hbase shell在创建table的时候指定切分策略
hbase> create 'test', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},{NAME => 'cf1'}
当然有些场景并不希望进行region的切分,我也可以关闭它
关闭auto-split: 将hbase.hregion.max.filesize设置很大,且将切分的策略设置为:ConstantSizeRegionSplitPolicy
命令行强制切分
force-split : 在hbase shell中执行: split 'test_split','b' split 'twq:webtable','http://hbase.apache.org/' split 'twq:webtable','http://www.51cto.com/' 也可以在控制界面中进行强制split
另外如果太多region也会有问题:之前可能数据量比如128M在一个Region就触发了一次Flush产生一个128M的HFile文件(Region级别的Flush条件),但是过多Region导致128M分散多个Region(比如128个),此时MenStore里只有1M,那么此时不会触发Region级Flush条件,随着后面数据增多,在没达到Region Flush条件就先触发了RegionServer级别的Flush,比如在50M时触发了,等同一下子就会有128个50M的HFile,这样在后面会频繁触发compaction机制,compaction频繁是会影响性能的
并且Region太多不利于元数据表格管理

造成太多Region的原因主要两个:一个预切分不合理,一个就是对Region切分规则不合理,比如Region的file size配置过小
Region太多时可以进行Region合并
#Region id 可以在Hbase UI上看 merge_region 'ENCODED_REGIONNAME','ENCODED_REGIONNAME' merge_region 'ENCODED_REGIONNAME','ENCODED_REGIONNAME',true //强制合并
另外Region切分时,可能发生:很多Region在同一个RegionServer上,为了解决这个问题,均匀分布region,HBase会有个Balancing机制
HMaster每隔: hbase.balancer.period(默认是300000ms即5分钟) 会进行一次Balance
Snapshot
对HBase的表格进行备份保存
在hbase-site.xml中配置如下参数,然后开启snapshot功能
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>
hbase> snapshot 'myTable', 'myTableSnapshot-122112'
hbase> list_snapshots
hbase> clone_snapshot 'myTableSnapshot-122112', 'myNewTestTable'
disable 'myTable'
restore_snapshot 'myTableSnapshot-122112'
enable 'myTable'
hbase> delete_snapshot 'myTableSnapshot-122112'

