Flume+Kafka+Spark Streaming
Flume
Flume的定位就是数据收集的技术
安装
1、下载 http://www.apache.org/dyn/closer.lua/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz 2、上传到指定的服务器(master)中的某个目录 3、解压 tar -xvf apache-flume-1.8.0-bin.tar.gz 4、cd apache-flume-1.8.0-bin/conf 5、cp flume-conf.properties.template flume-conf.properties 6、vi flume-conf.properties
配置
第六步配置conf文件,将netcat数据展示到 console
## 定义 sources、channels 以及 sinks ## 数据源配置 依次为 netcat数据源,收集的数据暂时放在内存中 agent1.sources = netcatSrc ## netcat数据源 agent1.channels = memoryChannel ## 收集的数据暂时放在内存中 agent1.sinks = loggerSink ## 数据放在哪里去, 以log console的方式打到控制台 ## netcatSrc 的配置 agent1.sources.netcatSrc.type = netcat ## source服务类型 agent1.sources.netcatSrc.bind = localhost ## 服务启在哪台机器上 agent1.sources.netcatSrc.port = 44445 ## 服务启动的端口 ## loggerSink 的配置 agent1.sinks.loggerSink.type = logger ## memoryChannel 的配置 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 100 ## 通过 memoryChannel 连接 netcatSrc 和 loggerSink agent1.sources.netcatSrc.channels = memoryChannel ## 源数据放入channel agent1.sinks.loggerSink.channel = memoryChannel ## 从channel中读取输出 这里是打印在控制台
启动
# 启动 一个agent conf读取配置文件,也就是我们上编辑的文件,并且通过logger打印INFO级别的日志到控制台 bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
表示启动成功 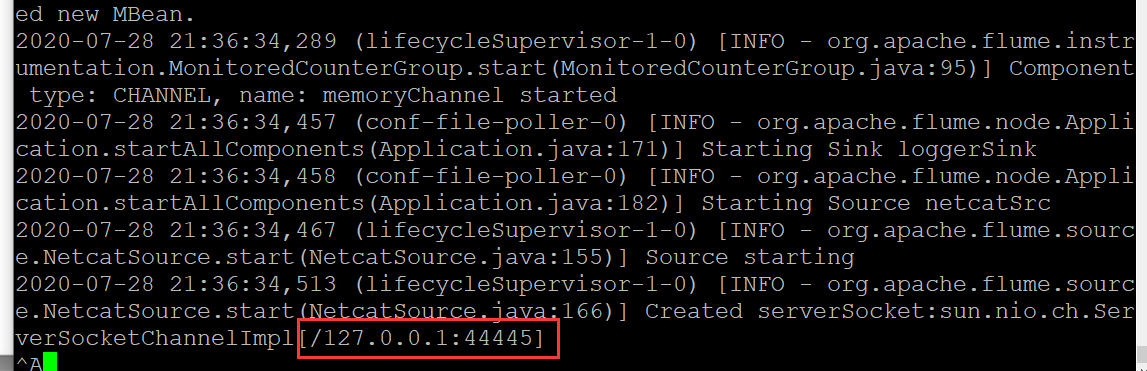
验证
在另外一个客户端上 通过telnet localhost 44445(地址和端口就是配置文件中 netcatSrc 的配置)
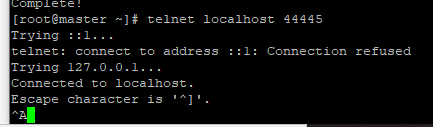
这样就表示连接上了,可以在上面随便输出内容,然后在Flume中就会接收到并打印在控制台

上面过程使用命令启动,启动的是一个agent,而接收一条记录,称为一个event
下面的从netcat中获取数据,不是输出到控制台,而是写在hdfs里
## 定义 sources、channels 以及 sinks agent1.sources = netcatSrc agent1.channels = memoryChannel ## 内存不稳定 agent挂掉,数据就丢了,可以用fileChannel,保存在文件中 agent1.sinks = hdfsSink ## netcatSrc 的配置 agent1.sources.netcatSrc.type = netcat agent1.sources.netcatSrc.bind = localhost agent1.sources.netcatSrc.port = 44445 ## hdfsSink 的配置 agent1.sinks.hdfsSink.type = hdfs agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9999/user/hadoop-twq/spark-course/steaming/flume/%y-%m-%d agent1.sinks.hdfsSink.hdfs.batchSize = 5 ## 到5条记录才写一次 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true ## memoryChannel 的配置 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 100 ## 通过 memoryChannel 连接 netcatSrc 和 hdfsSink agent1.sources.netcatSrc.channels = memoryChannel agent1.sinks.hdfsSink.channel = memoryChannel
从实时查看日志中获取数据源,并保存到 HDFS中
## 定义 sources、channels 以及 sinks agent1.sources = logSrc agent1.channels = fileChannel agent1.sinks = hdfsSink ## logSrc 的配置 数据源配置是从exec 执行命令中获取,就是实时查看日志 agent1.sources.logSrc.type = exec agent1.sources.logSrc.command = tail -F /home/hadoop-twq/spark-course/steaming/flume-course/demo3/logs/webserver.log ## hdfsSink 的配置 agent1.sinks.hdfsSink.type = hdfs agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9999/user/hadoop-twq/spark-course/steaming/flume/%y-%m-%d agent1.sinks.hdfsSink.hdfs.batchSize = 5 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true ## fileChannel 的配置 注意channels把数据临时存储,所以在这些本地目录下,会有数据产生,最终存入HDFS中 agent1.channels.fileChannel.type = file agent1.channels.fileChannel.checkpointDir = /home/hadoop-twq/spark-course/steaming/flume-course/demo2-2/checkpoint agent1.channels.fileChannel.dataDirs = /home/hadoop-twq/spark-course/steaming/flume-course/demo2-2/data ## 通过 fileChannel 连接 logSrc 和 hdfsSink agent1.sources.logSrc.channels = fileChannel agent1.sinks.hdfsSink.channel = fileChannel
其中启动命令的name要和配置文件中agent名称对应上
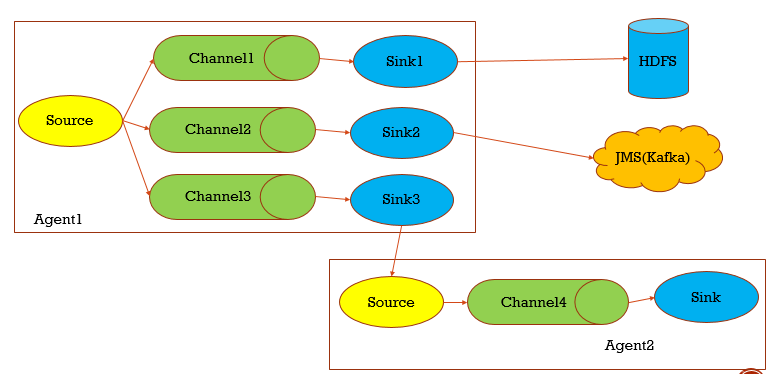
Flume架构
Flume主要分三个部分,Source主要把源数据进行采集,临时存在放在Channel,Sink则负责从Channel取出临时数据进行输出
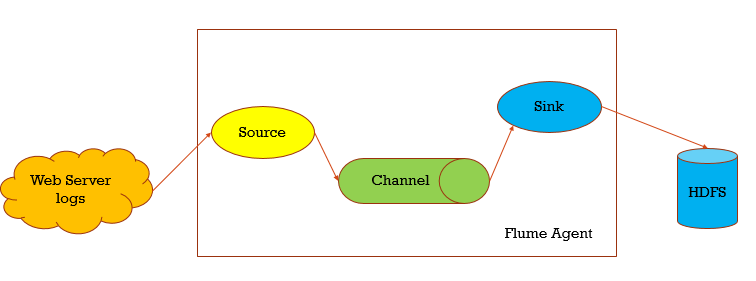
当然Flume内部是比较灵活的,可以配置多个Source或者Channel或者Sink,输出上也比较灵活,可以输出到HDFS kafka,也可以再输给Flume(多个值,比如多个source,用逗号隔开)
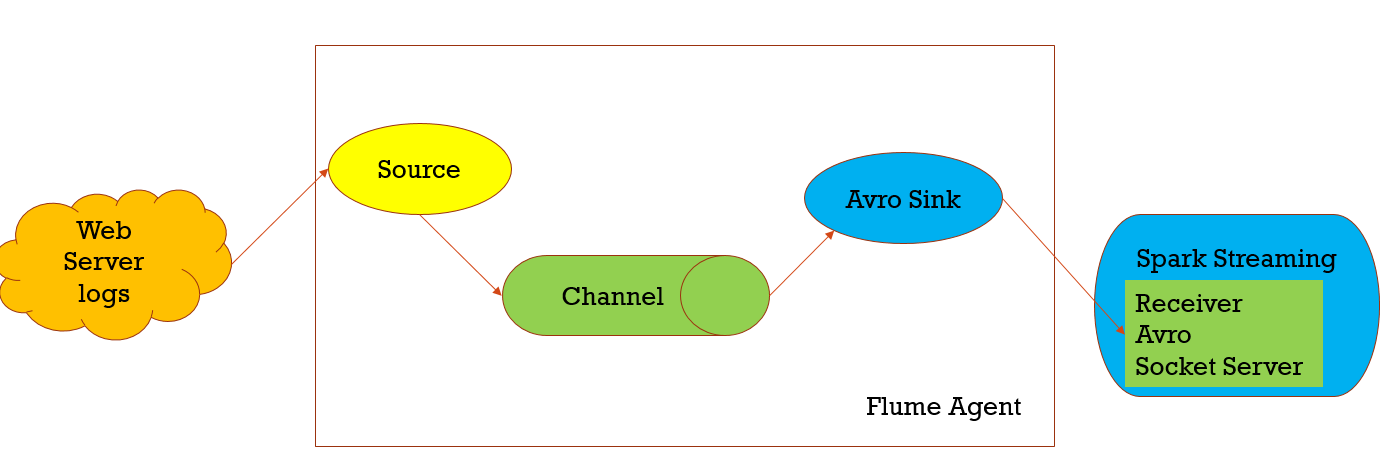
Flume收集的日志, 可以给到Spark streaming消费,其中由Avro Sink做为client的,而Spark Streaming的Receiver是Avro Socket Server,它也做为Flume进行push给spark streaming的服务端消费数据,这种模式是push模式
运行:
第一个,需要打jar包,因为Flume的jar在spark里是没有提供的,打包的jar包进行上传
第二个,启动agent,启动spark-streaming程序
## 定义 sources、channels 以及 sinks agent1.sources = netcatSrc agent1.channels = memoryChannel agent1.sinks = avroSink ## netcatSrc 的配置 agent1.sources.netcatSrc.type = netcat agent1.sources.netcatSrc.bind = slave1 agent1.sources.netcatSrc.port = 44445 ## avroSink 的配置 agent1.sinks.avroSink.type = avro agent1.sinks.avroSink.hostname = slave1 agent1.sinks.avroSink.port = 44446 ## memoryChannel 的配置 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 100 ## 通过 memoryChannel 连接 netcatSrc 和 hdfsSink agent1.sources.netcatSrc.channels = memoryChannel agent1.sinks.avroSink.channel = memoryChannel
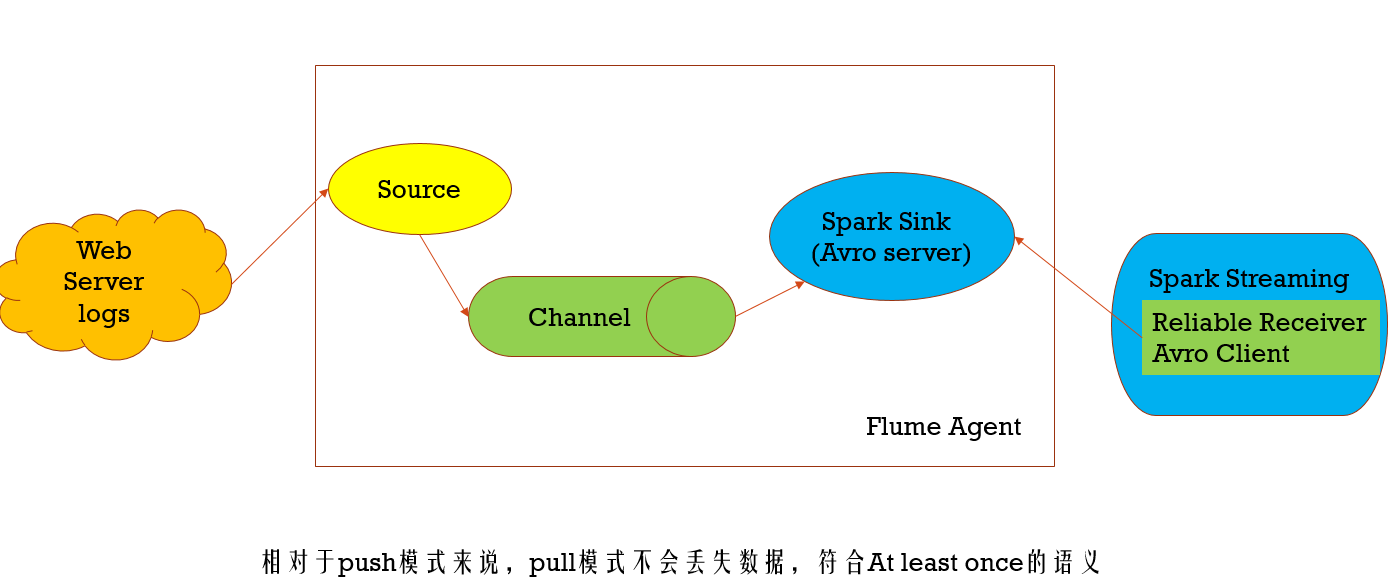
pull模式,在这种模式下Sink是spark的Sink,而此时它做为服务端,Spark Streaming的Receiver则做为client端,去Spark Sink拉取数据进行消费,数据存储在Flume中,不会丢失,想对push模式更可靠
另外使用spark sink,需要依赖几个jar(scala-library_2.11.8.jar(这里一定要注意flume的classpath下是否还有其他版本的scala,要是有的话,则删掉,用这个,一般会有,因为flume依赖kafka,kafka依赖scala)、 commons-lang3-3.5.jar、spark-streaming-flume-sink_2.11-2.2.0.jar)
## ���� sources��channels �Լ� sinks agent1.sources = netcatSrc agent1.channels = memoryChannel agent1.sinks = sparkSink ## netcatSrc ������ agent1.sources.netcatSrc.type = netcat agent1.sources.netcatSrc.bind = localhost agent1.sources.netcatSrc.port = 44445 ## avroSink ������ agent1.sinks.sparkSink.type = org.apache.spark.streaming.flume.sink.SparkSink agent1.sinks.sparkSink.hostname = master agent1.sinks.sparkSink.port = 44446 ## memoryChannel ������ agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 100 ## ͨ�� memoryChannel ���� netcatSrc �� sparkSink agent1.sources.netcatSrc.channels = memoryChannel agent1.sinks.sparkSink.channel = memoryChannel
Kafka
安装Kafka需要把zookeeper启起来,到三台机器上用zkServer.sh start, zkServer.sh status查看选举的结果
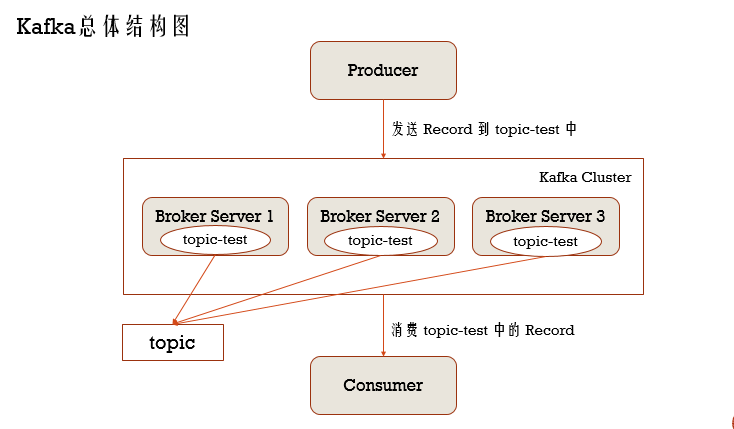
Kafka也会有一个集群,用于接收生产者app发送过来的消息 ,存在Kafka的消息又被消费者app进行消费,这个过程,Kafka做为消息中间件,当然还可以从一个数据库导入另外一个数据库,这个叫数据库间的转换,它还可以做实时流处理,当然集成在Spark Streaming,主要是使用它的消息中间件功能
Kafka集群会有若干个Broker Server,而生产者发送Record给到topic,而消费者消费topic中的Record
安装步骤
1、下载上传解压
下载: https://www.apache.org/dyn/closer.cgi?path=/kafka/1.0.0/kafka_2.11-1.0.0.tgz
上传到master机器的~/bigdata/下
解压: tar -xzf kafka_2.11-1.0.0.tgz
2、在master上修改配置
cd ~/bigdata/kafka_2.11-1.0.0/config
vi server.properties
修改两个参数:
log.dirs=/home/hadoop-twq/bigdata/kafka-logs-new
zookeeper.connect=master:2181
创建一个目录:mkdir ~/bigdata/kafka-logs-new
3、将master上的安装包scp到slave1和slave2
scp -r ~/bigdata/kafka_2.11-1.0.0 hadoop-twq@slave1:~/bigdata/
scp -r ~/bigdata/kafka_2.11-1.0.0 hadoop-twq@slave2:~/bigdata/
scp -r ~/bigdata/kafka-logs-new hadoop-twq@slave1:~/bigdata/
scp -r ~/bigdata/kafka-logs-new hadoop-twq@slave2:~/bigdata/
4、修改slave1和slave2上的配置
cd ~/bigdata/kafka_2.11-1.0.0/config
vi server.properties
修改一个参数:
slave1上为:broker.id=1
slave2上为:broker.id=2
5、分别在master、slave1和slave2伤启动broker server
cd ~/bigdata/kafka_2.11-1.0.0
mkdir logs
nohup bin/kafka-server-start.sh config/server.properties >~/bigdata/kafka_2.11-1.0.0/logs/server.log 2>&1 &
6、创建topic
cd ~/bigdata/kafka_2.11-1.0.0
bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic test-1
7、查看topic
cd ~/bigdata/kafka_2.11-1.0.0
bin/kafka-topics.sh --list --zookeeper master:2181
8、启动producer发送消息
cd ~/bigdata/kafka_2.11-1.0.0
bin/kafka-console-producer.sh --broker-list master:9092 --topic test-1
9、启动consumer消费消息
cd ~/bigdata/kafka_2.11-1.0.0
bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic test-1 --from-beginning
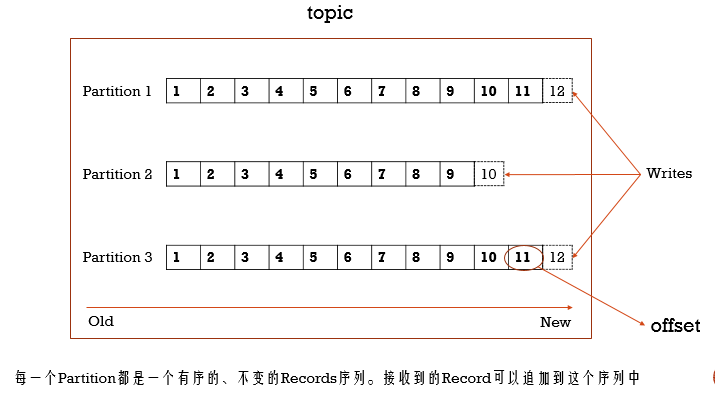
Kafka基本术语 - topic
topic里对应着一系列的消息数据,而这些数据是存在Kafka的磁盘里,并且有一定的期限,默认是存储7天,而topic是通过Partition分区来组织的
消息发过来,是追加到分区Records序列的后面,并且每条记录是通过offset来唯一标识,并且分区的数据是以分布式存储的方式存储在kafka集群的Broker Server上,在吞吐量上很高,当然分区也是可以在Broker Server间进行备份
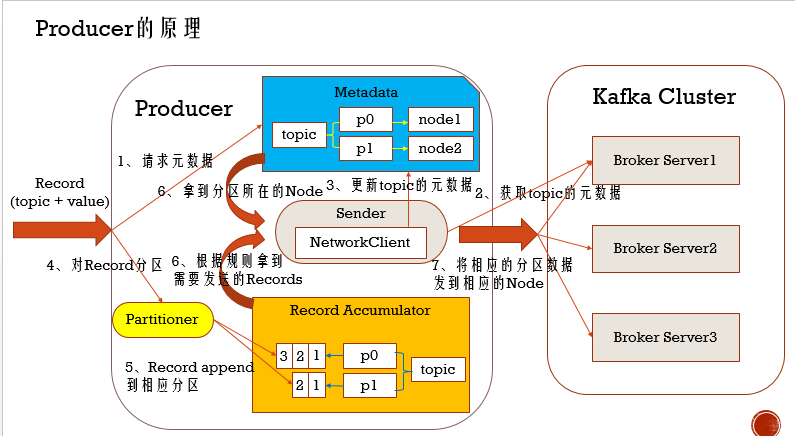
Producer原理
在Producer有这么几个组件,Metadata,主要存放topic的元数据信息,Sender,发送消息的,由它下面的NetworkClient和Kafka集群Broker Server进行通信,Record Accumulator,主要是组织分区好了的数据,而负责给数据分区的是Partitioner
- 当一条记录过程,会携topic和value信息,请求元数据信息,刚开始Metadata中没有元数据信息的
- 从broker Server上获取topic的元数据信息
- 然后就更新topic信息到Metadata
- 对Record进行分区,kafka会有一个默认分区器,如果Record是有分区序号的,不做 任何处理,如果携带的value是Map类型,则以map的key的哈希值进行分区,如果都不是,那就依次轮询分配给相应的分区
- 在Record Accumulator上维护一个topic和分区的映射关系,Record在经过分区器后,就确定好添加哪个分区,然后进行追加
- Record Accumulator会起定时器,只有满足规则了,把满足规则的Records发给Sender(比如批量发送,满足多少条才发),另外这个过程还要去Metadata中拿到分区对应的Node
- 最后,Sender把Records发送给对应的Node
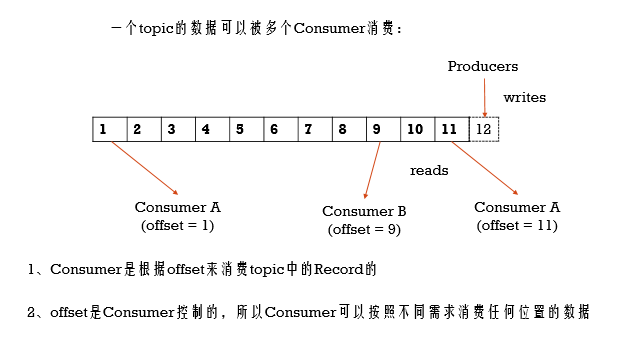
Consumer和Consumer Group
每条Record都会被Consumer Group消费,但实际是给到Consumer Group下的Consumer消费,如果下面有多个Consumer,那么Consumer之间会分担着消费,并且可以通过offset来灵活控制消费topic的数据

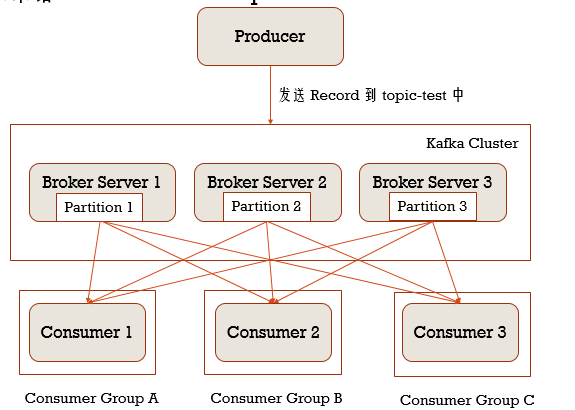
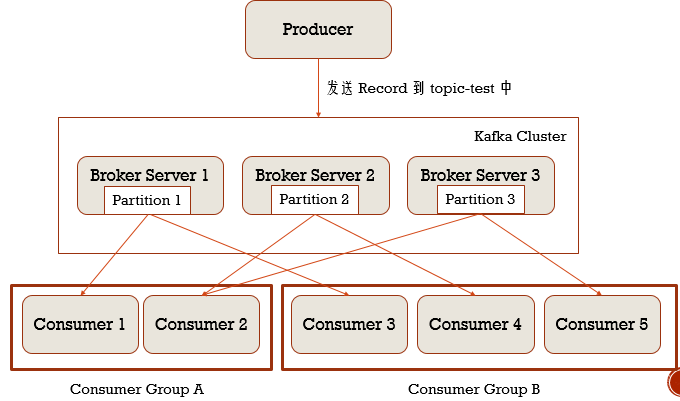
Kafka与Spark Streaming集成
Receiver模式
你就可以理解为Spark Streaming里的Receiver就是Kafka的消费者,它里面会有Consumer Group,当某些分区数据量大的时候,只有一个Consumer处理不过来时,可以启多个Receiver,同一个Consumer Group,这样可以把多个分区的数据分发给多个消费者进行消费,增加Spark Streaming的吞吐量
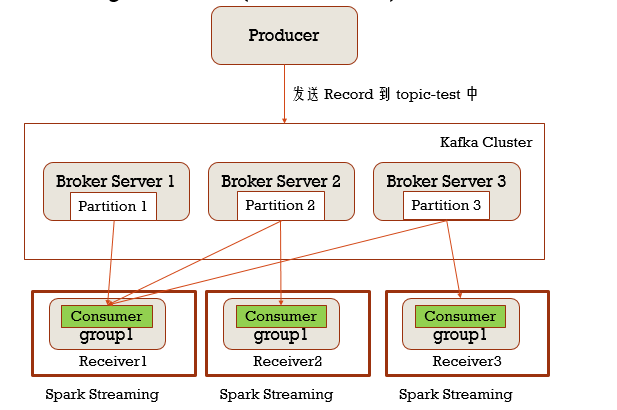
Direct模式
这个模式下就不在有Consumer的说法,让DStream直接去读topic分区的数据,InputDStream也是分区的,那么在读取的时候,和topic的分区对应着去读
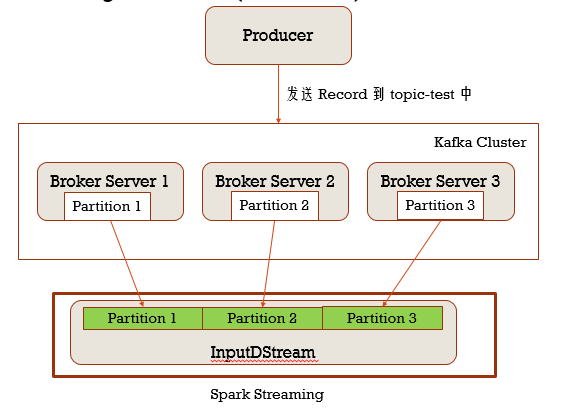
两种 模式对比:无论从高可用和效率上看,Direct模式都更好,需要注意的是,Direct模式Spark Streaming自己跟踪数据消费情况,从而达到一条数据只被消费一次,而Receiver模式则是通过zk跟踪的,所以Direc模式t的不足主要是在利用zk和Receiver两个方面,不过Direct模式优势足以掩盖这两个方面

注意direct模式的Kafka监控,需要做如下代码处理,而接收速率调节换成下面的参数
var offsetRanges = Array.empty[OffsetRange]
directKafkaStream.print()
directKafkaStream.transform { rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}.map(_._2)
.flatMap(_.split(" "))
.map(x => (x, 1L))
.reduceByKey(_ + _)
.foreachRDD { rdd =>
for (o <- offsetRanges) {
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
}
rdd.take(10).foreach(println)
}

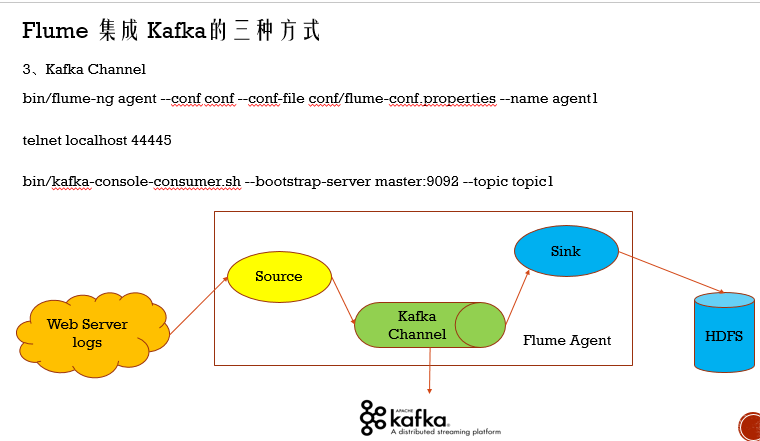
Kafka集成Flume
Kafka既可以作为Flume的source,也可以是Sink,还可以是Channel,非常 的灵活
1.Kafka做为数据来源


2.Kafka做为Flume的数据输出对象

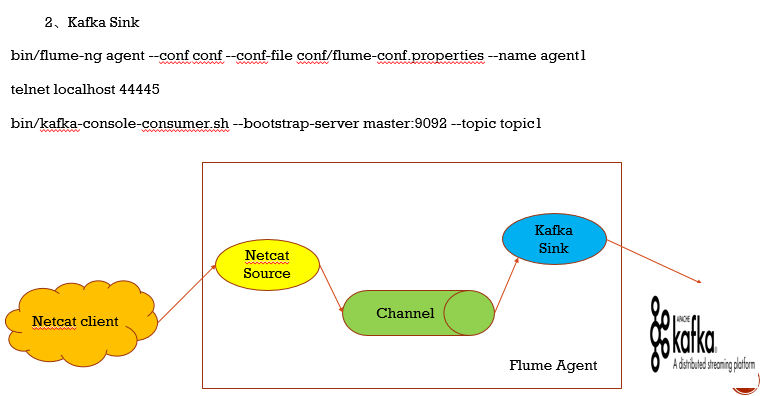
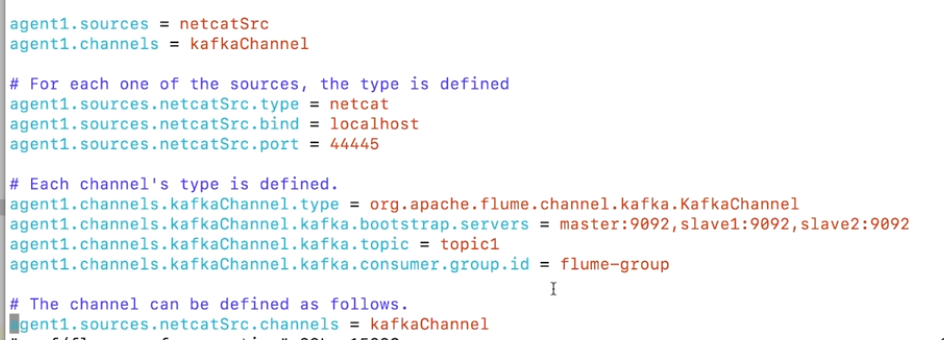
3.Kafka做Flume的中间存储,此时Kafka既当消费者,又当生产者

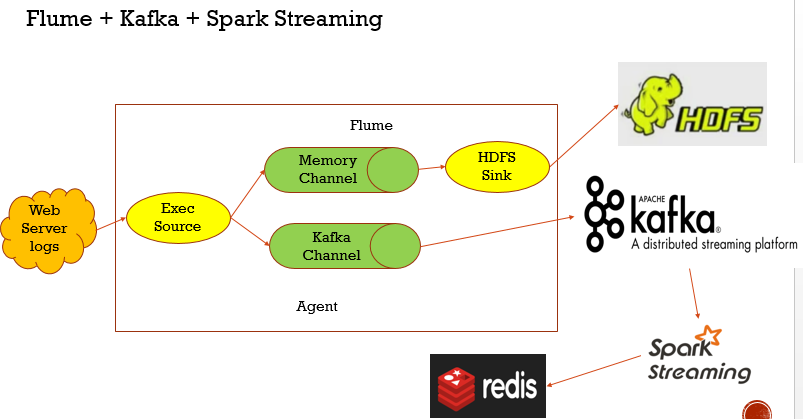
Flume + Kafka + Spark Streaming
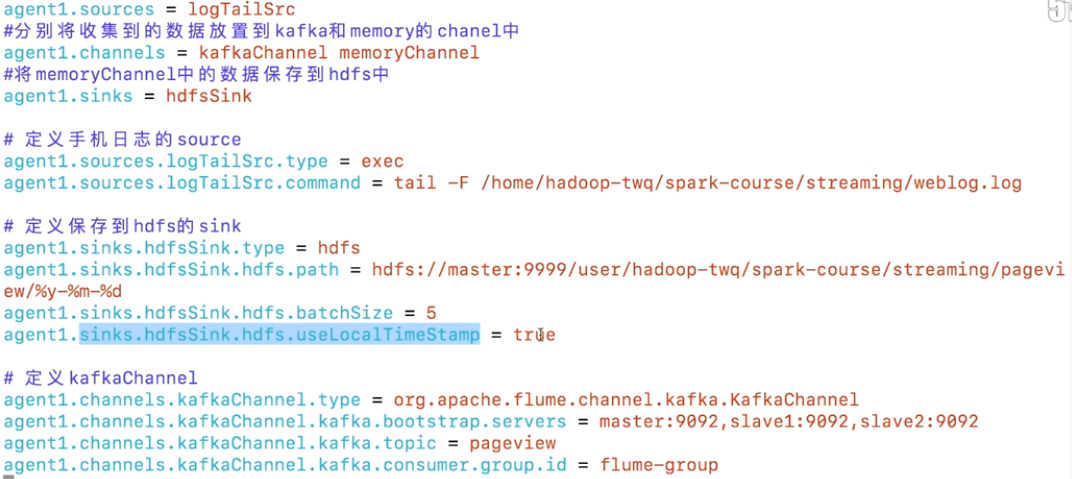
假如我们是tail -f 去读取日志文件的实时数据,也就是Flume的Source是Exec Source,source把数据给Memory Channel和KafkaChannel,内存中间存储的数据最后存储在HDFS,而Kafka中间存储的数据推给Kafka,而Spark Streaming从Kafka上获取数据,把最终处理的结果存储在redis中

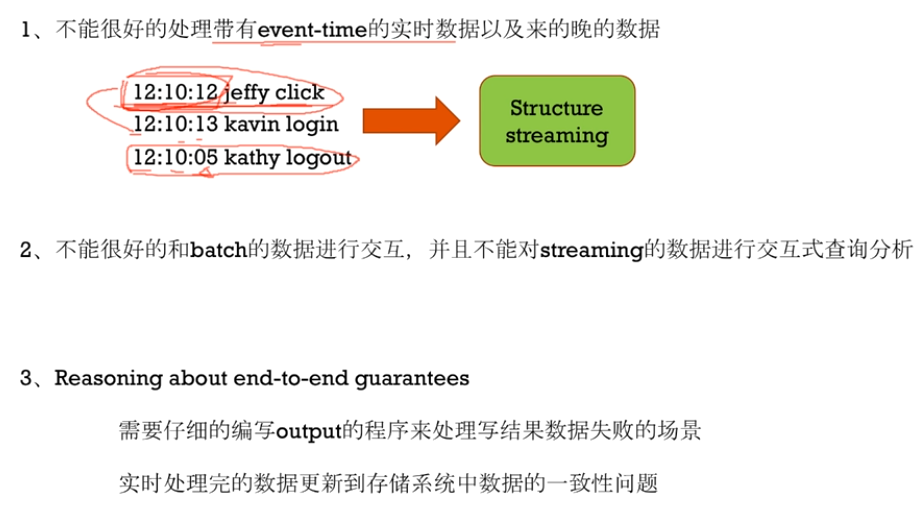
Spark Streaming优点有很多:比如效率高,扩展性强,分布式存储,可以处理大量的数据,并且RDD和Spark SQL接口上交互都是非常友好,还提供了Direct模式消费数据,保证一条记录只被消费一次的语义,适应性也强,有压力反馈和动态扩展两个机制

当然也有不完美的地方,就是Spark Streaming在处理数据时,是以Spark Streaming服务器的时候为准,而不是数据源的时间,有些场景下我们是要根据数据源的时间来处理的,并且生产场景下的数据时间不一定完全有序的,这种 实时处理能力,Spark Streaming不能胜任,就是因为它是基于自己的batch time来做的
第二个就是和静态数据(batch数据)交互不友好,虽然可以通过transform + RDD的方式做到,另外用SQL交互查询也支持的不够好
第三个就是output环节程序处理复杂,需要考虑各种失败场景和数据一致性(比如输出给mysql时,需要考虑事务,批量写入,连接池等)
最后针对这三个问题,可以用Structured Streaming,它通过Continuous Applications来实现,一般情况下,我们用Spark Streaming就够了