
spark-submit提交spark应用
java启动JVM
JVM,你就可以理解成要运行java程序,需要启动一个进程,而这个进程就称为JVM,java程序启动JVM时,需要对java程序进行编译,编译后就会产生一个带.class java字节码文件,然后就可以用java命令加上刚才编译的字节码文件调用一个JVM进程
当然调用java命令时,它还提供很多参数进行调用执行,需要重点关注下这么几个参数:
- -cp(-classpath) 指定程序字节码文件目录
- -D<名称>=<值> 设置属性值,在程序里可以通过System.getProperty(名称)获取
- 虚拟机扩展参数
java -cp /Users/tangweiqun/spark/source/spark-course/spark-rdd/target/spark-rdd-1.0-SNAPSHOT.jar:/Users/tangweiqun/spark/source/spark-course/spark-submit-app/target/classes \ -Dname=yellow -DsleepDuration=5 \ -Xmx20M -XX:+UseParallelGC -XX:ParallelGCThreads=20 com.twq.submit.launcher.JvmLauncherTest
另外启动JVM,还支持java代码的方式启动(通过ProcessBuilder,维护一个cmd list):java code process
master和deploy-mode
--master 指定分布式资源管理的模式,主要spark,yarn
其中yarn的方式,需要先进行导入export hadoop conf的操作
--name 指定的名称会在Spark监控UI上显示


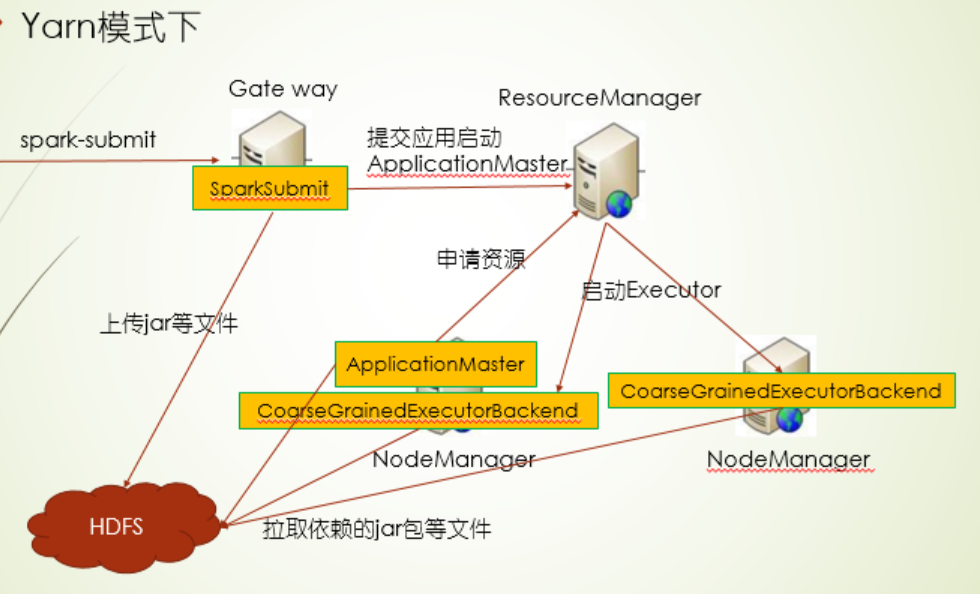
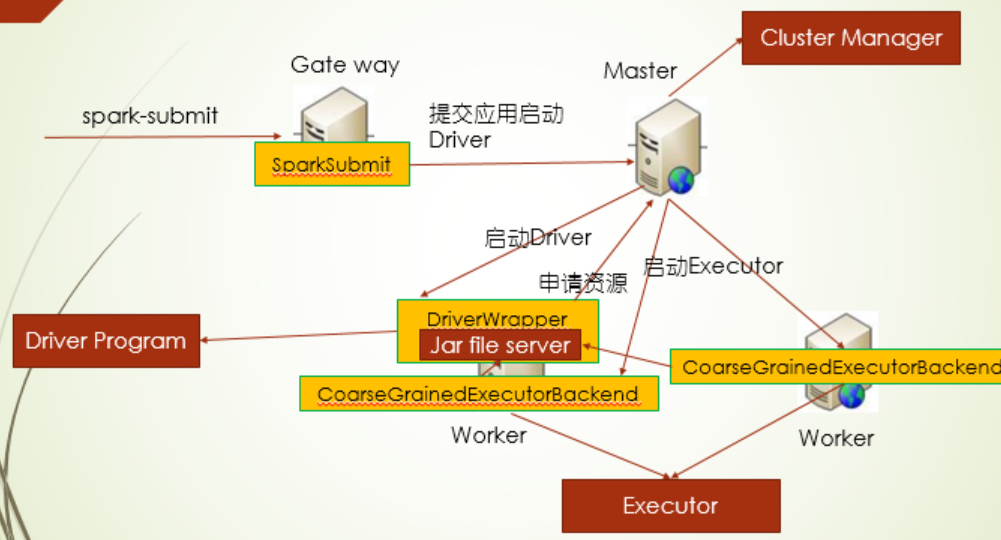
yarn作为master的模式下(client模式),spark-submit是向ResourceManager提交启动ExecutorLauncher申请,ResourceManager会挑选一台NodeManager启动ExecutorLauncher,由ExecutorLauncher向ResourceManager申请资源并启动Executor端程序,不过driver端程序还是在提交SparkSubmit的client上,架构上和yarn集群模式一致,就是driver程序放哪个地方不同,
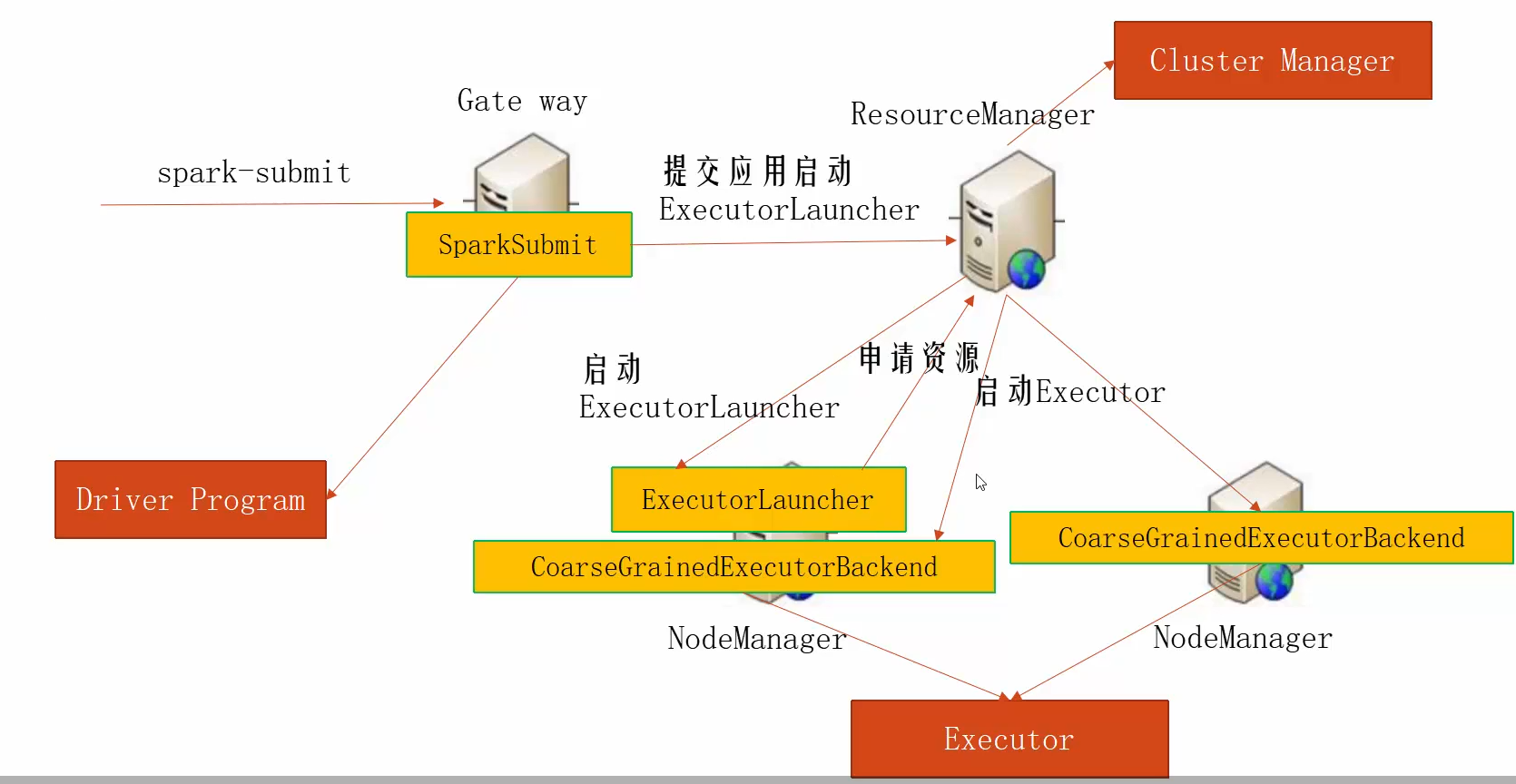
--deploy-mode 主要有两个模式,一个是client客户端模式,一个是cluster集群模式,通俗点讲,这个参数决定了driver端程序在哪里运行,如果是client模式,那么driver端程序运行在客户端上,如果是cluster模式,会在从节点(Worker Node)上随机选一台运行driver程序
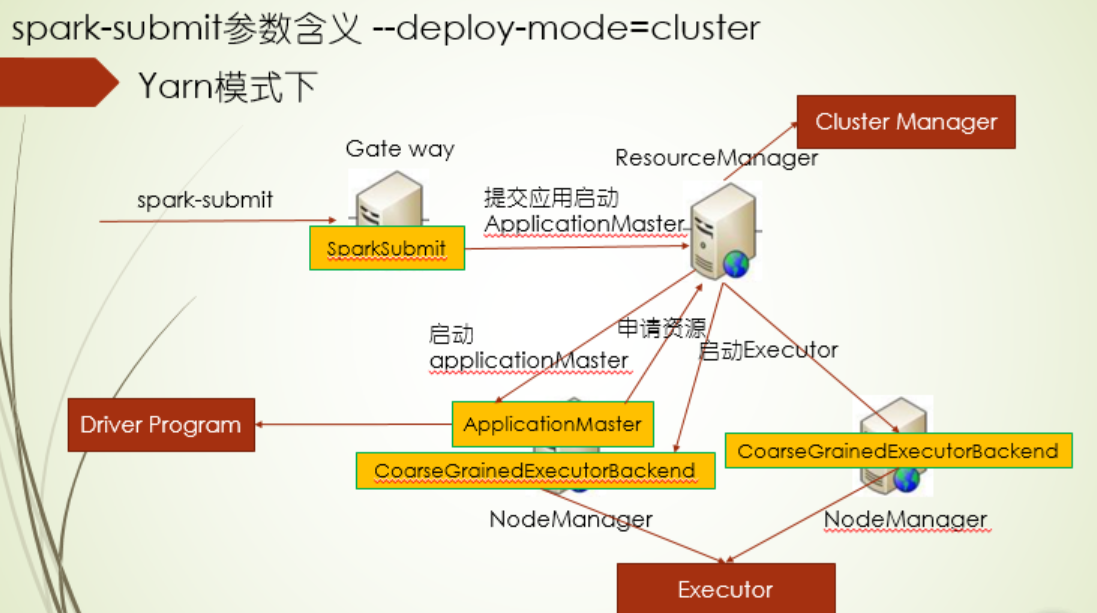
1.在yarn的集群模式下,spark-submit向ResourceManager提交启动ApplicationMaster的申请,由ResourceManager挑选一台NodeManager启动ApplicationMaster,再由ApplicationMaster申请资源,启动 Executor端程序,其中driver程序在ApplicationMaster上
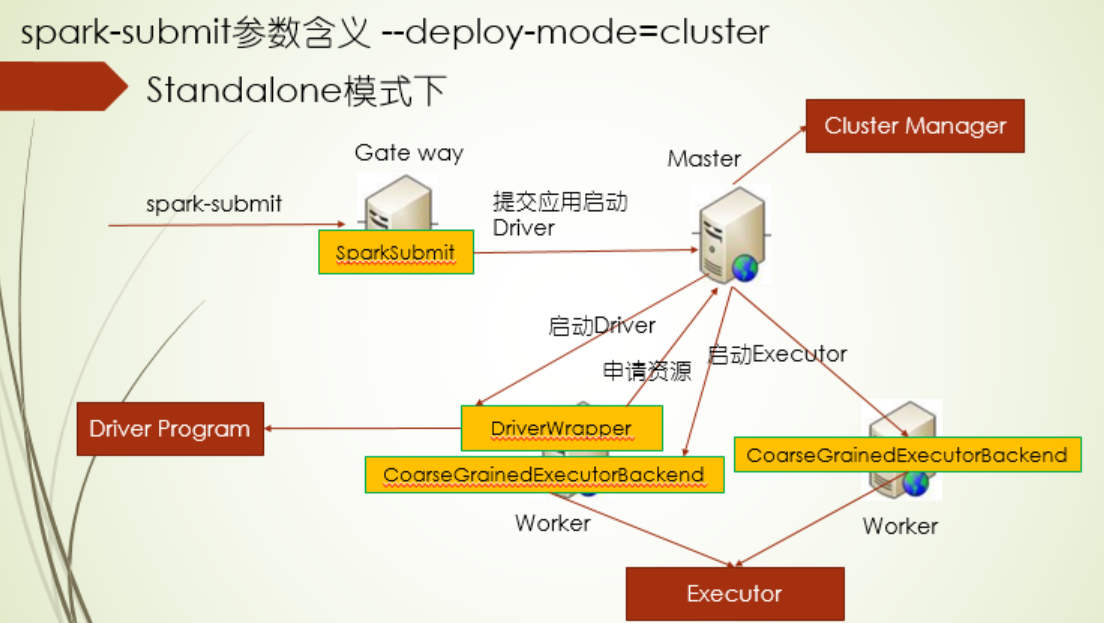
2.spark集群模式下,提交命令需要注意下面两点,这种模式下和yarn集群模式下,流程是一样的,只不过资源管理的变成Master,master在Worker节点上启动DriverWrapper,driver程序放在这,由DriverWrapper向master申请资源,启动Executor端程序
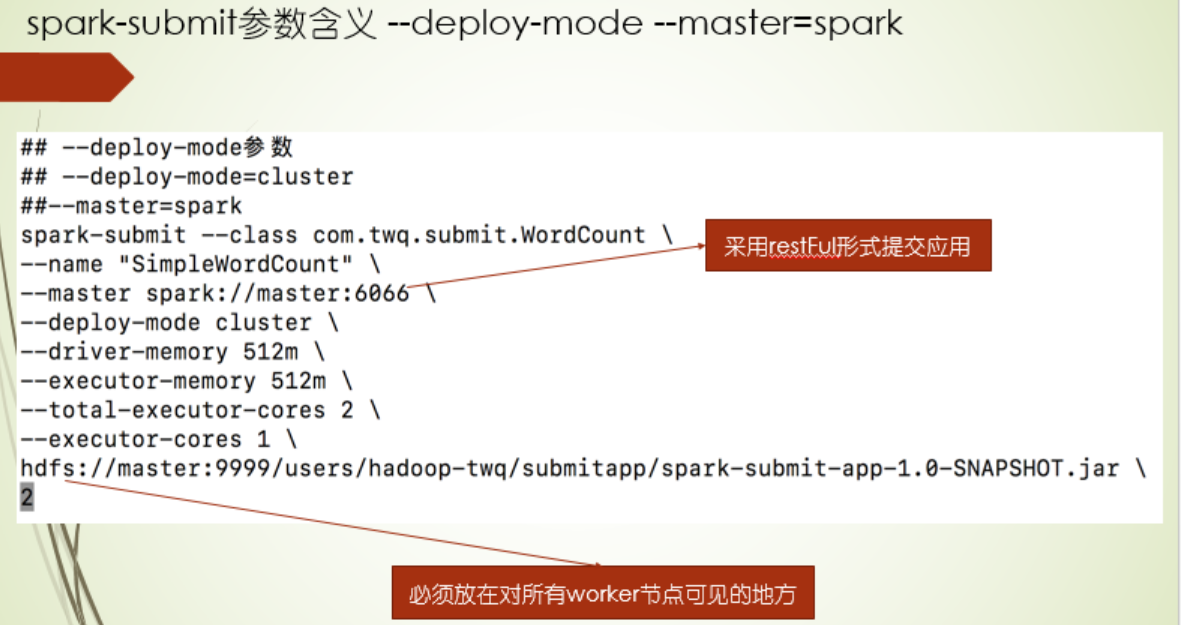
conf
可以用这个配置一些spark程序的一些可变参数,通过conf.getOption获取
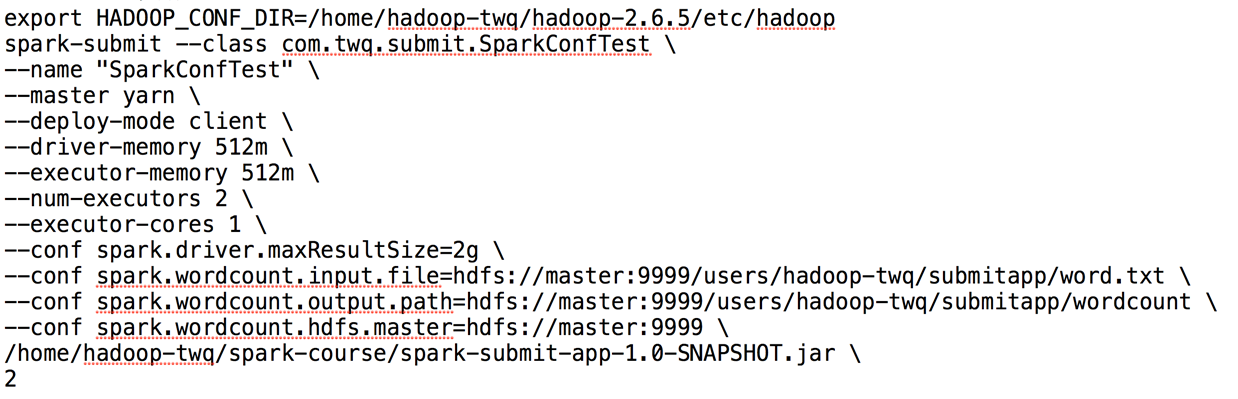
driver相关参数
这个主要控制driver端的一些参数,主要包括内存,cpu,driver端依赖的java字节码路径等
- --driver-memory 启动driver端需要的内存大小,比如1000m,1g,默认是1024m
- --driver-cores 启动driver程序时需要的core数量,默认1
- --driver-java-option driver JVM时的参数。主要包括-D参数。。。
- --driver-library-path 非java包的位置,比如dll,so等
- --driver-class-path driver程序运行依赖的字节码文件路径,比如jar包
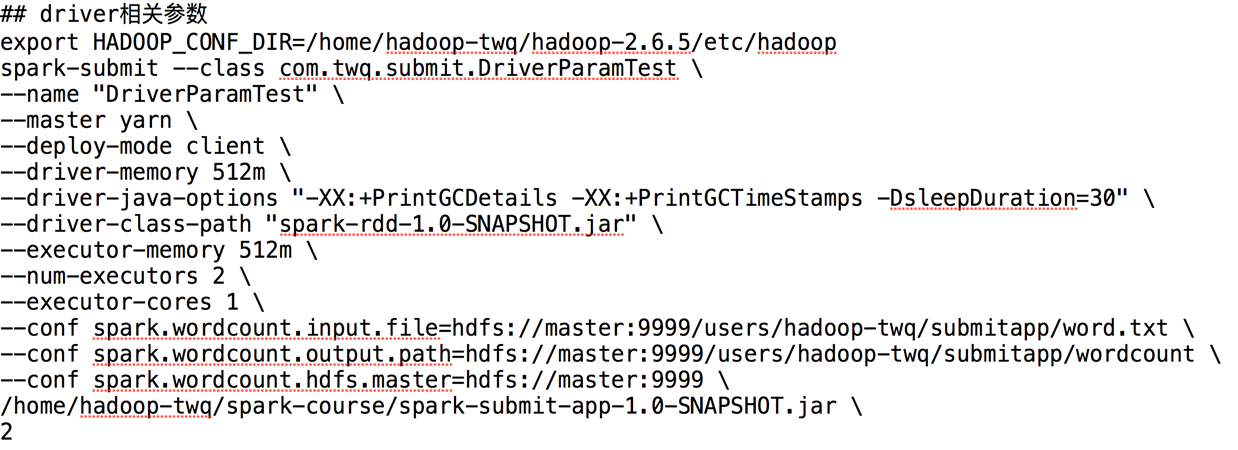
另外java-option的参数,还可以在conf里设置

executor相关参数
core和memory相关参数
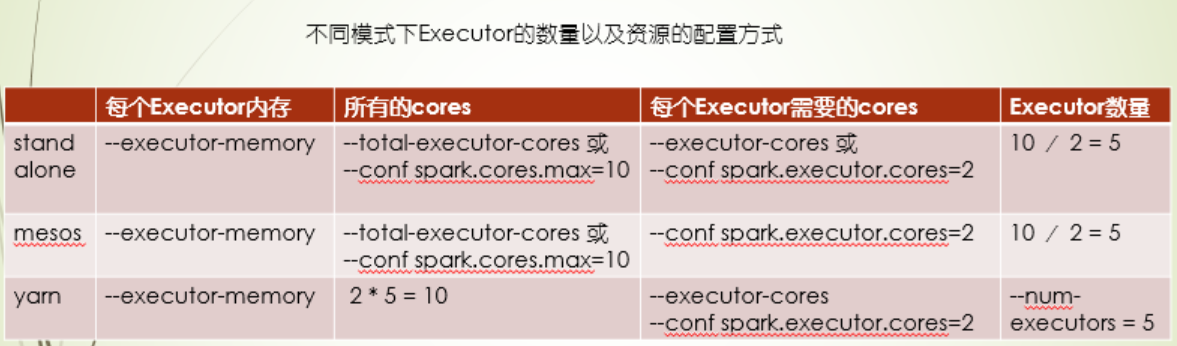

spark on Yarn的资源分配
实际应用场景中,Yarn的居多,下面这张图就是以yarn进行讲解的,当然其他的模式也是差不多的,其中在yarn的NodeManager会自己的一个内存,而Executor的内存肯定是小于NodeManager的内存,而Executor的内存不会全部都拿来给Executor端的程序代码运行的,它会留一部分,也就是Overhead这部分,用于防止内存溢出的,所以你通过参数配置的Executor端内存,需要加上一部分内存才才算是Executor端内存,会比配置值大

在下面场景的场景中,第二种方案是最佳的,首先core控制在5个,或者5个以下,那么这种情况读写HDFS是最优的,17个Executor,分摊到6台服务器上,5台上会有三个Executor,1台会有2个,落单的那台还可以运行ApplicationMaster,另外,每个Executor下预留了7%的内存,计算下来,每个Executor的内存19G,也是很合理的
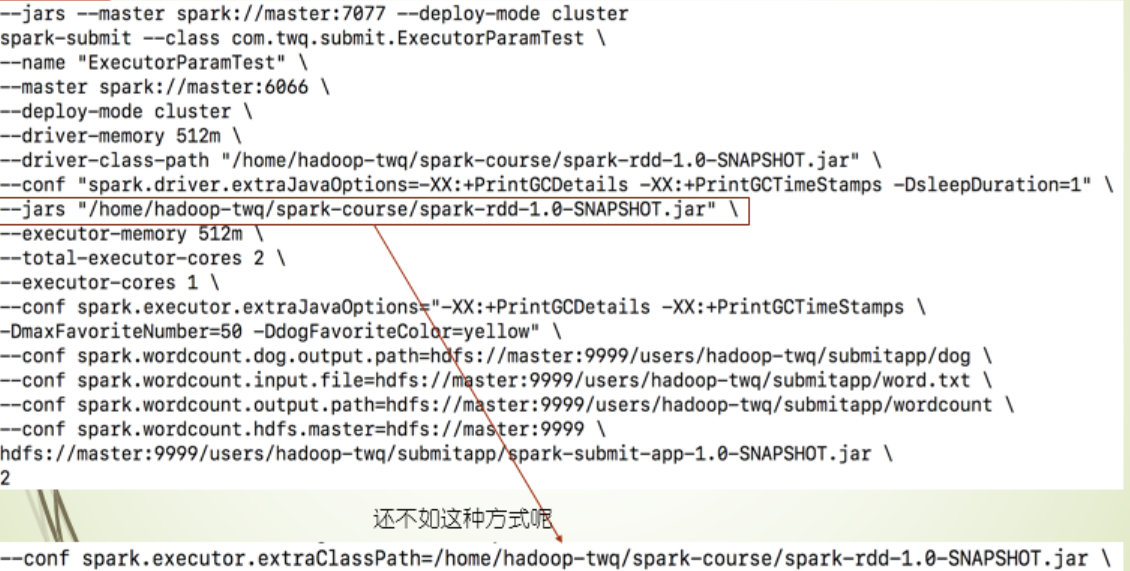
***--jars
在下面的示例命令中,发现 driver端和Executor端共用同一jar包,并且Executor端还要求jar需要在同一目录下,这个过程需要进行一个分发的过程,多一部分运维的工作,那么--jars就帮我们简化这一部分工作
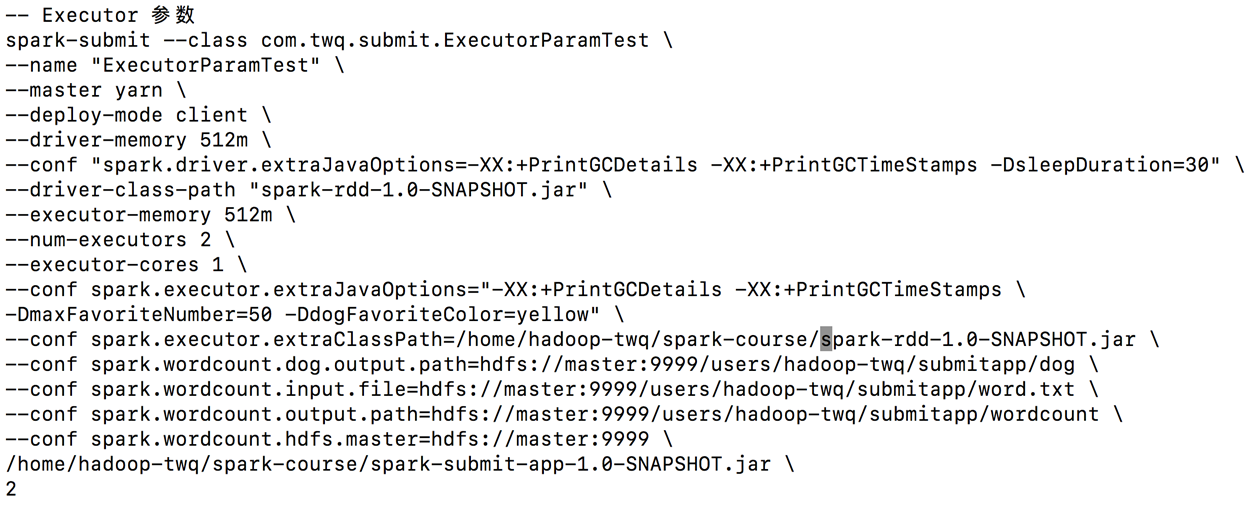
首先yarn模式,jar包分发机制,无论是client模式还是cluster模式,在程序提交时,会把jar包上传到HDFS上,Executor端到HDFS上获取jar包
下面是cluster模式下
Standalone client模式
在这种模式下,提交spark程序的时候,会起一个Jar file server的服务,用于管理jar包,而Executor端从这个上面获取jar包
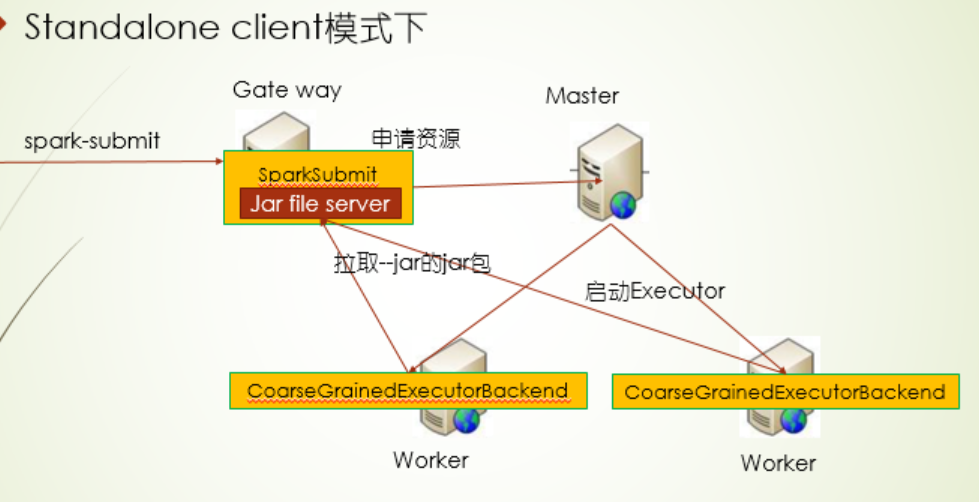
Standalone cluster模式下有点特殊,因为Jar file server是跟driver端的,等同在集群模式下,是随机挑的Worker作为Driver端,所以有很大的不确定性,在这种情况下,需要保证每台Worker下有,所以Driver端jar包保证,还是需要你手动分发到各Worker机器上,在这种情况,使用 conf指定Executor端的jar,效率还更高,因为--jar的方式还会启动一个Jar file server
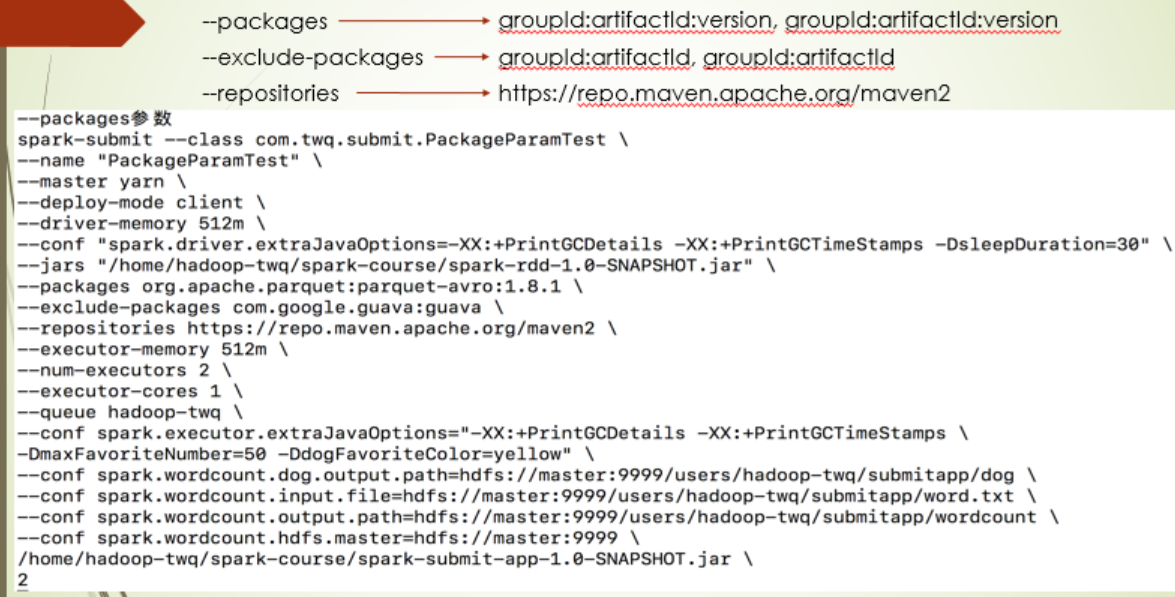
--package
这参数主要是让你可以在提交应用的时候,自己去拉一些依赖的jar包,比如图中第一个参数,就是指定去拉某个包,而第二个参数则相反,不拉某个包,比如spark里会自带一些包,就不用去拉,第三参数指定去哪个仓库里拉,这里可以填公司自建的maven仓库
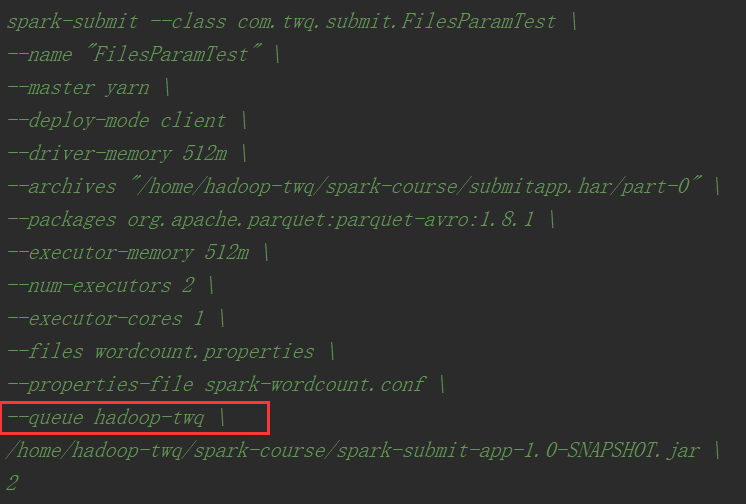
--files与--properties-file
对于--file, 你可以把jvm进程中的属性放在这,-D<name>=val,driver端和executor端的属性都可以放在--files的文件里,不过采用这样的方式,就都不支持System.getProperty获取,都要进行读文件操作
而对于--properties-file,则conf选项都放着,可以通过conf.getOption获取,当然--file中的进程参数,也可以通过conf的spark.driver.extraJavaOptions和spark.executor.extraJavaOptions进行控制,这样是支持System.getProperty获取的
git地址:https://github.com/caijingkuangmo/bigdata-summary/blob/master/spark-submit-study/spark-submit-app/src/main/scala/com/twq/submit/FilesParamTest.scala

****--queue
yarn是一种资源管理集群,yarn会按队列划分资源,每个队列都有自己的资源和限制,提交应用到yarn上,都要指定队列,做到资源隔离,防止竞争
配置yarn多队列,在hadoop的配置目录下,有个etc/hadoop/capacity-scheduler.xml
,在这里配置队列资源占比,以及状态
其他方式提交
怎么提交python spark程序,以shell,java,scala提交spark应用
python:https://github.com/caijingkuangmo/bigdata-summary/tree/master/spark-submit-study/spark-rdd-python
SparkLauncher:https://github.com/caijingkuangmo/bigdata-summary/tree/master/spark-submit-study/spark-submit-app/src/main/java/com/twq/submit/launcher
spark-submit原理
待更新。。。
总结:
1.分布式资源管理,spark和yarn都能做,所以在提交应用时,可以通过--master来指定谁来做,当然提交时又会有两种模式,分别为Client和Cluster模式,通过--deploy-mode来指定,这个主要决定了driver端程序在哪个地方(Client还是节点),其中在spark client模式和另外三个模式架构上稍微有点不同,spark client模式不会启动类似计算JVM,而其他三个:yarn client模式 => ExecutorLauncher,yarn cluster模式 => ApplicationMaster, Spark cluster模式 => DriverWrapper,这三个在提交应用时都向资源管理器申请启动上面对应的计算中心,然后有计算中心向资源管理器申请资源启动Executor,而在spark client模式,提交时直接向资源管理器申请启动Executor,对于这个资源管理器,yarn和spark分别对应为ResourceManager和Master,yarn和spark节点分别对应为NodeManager和Worker
2.在提交时,刚开始,yarn需要比spark多做一步,需要export hadoop conf dir
3.Standalone 集群模式下 --master采用6066端口,restful api的方式
4.--jar参数的作用就是减少对Executor端jar包的运维工作,不过yarn和Standalone的运行机理不一样,yarn主要是把jar上传HDFS,Executor到HDFS上取,而Standalone则是会启动一个Jar File Server来管理,但是Standalone的集群模式又有点特殊,因为集群模式的driver端不定,所以需要把所有的Worker节点分发好jar包,这样再用--jar来指定,反而会多启动Jar管理服务,效率反而更低,这个时候用--conf指定 更好

