
Spark核心编程模型之RDD(一)
简介
Spark和MapReduce的功能差不多,主要做分布式计算的,而分布式存储还是由HDFS来做,其中Spark进行数据转换时最核心的概念就是RDD,既然是做分布式计算的,那就要搞懂
- Spark是怎么进行分布式计算的以及工作流程
- Spark各个模块解决的问题以及特点
- Spark RDD中API的使用场景
上面说了,spark进行分布式计算是基于HDFS的,所以不光要启动spark集群,还是要启动HDFS集群
//hdfs start-dfs.sh //spark sh ~/bigdata/spark-2.2.0-bin-hadoop2.7/sbin/start-all.sh //进入spark交互命令行 spark-shell --master spark://master:7077
查看一些spark任务的运行状态,可以到监控界面上查看http://master:8080/,监控界面更多详细信息阶段:戳这
重点
- RDD的特点
- RDD的Transformation API和Action API
- Spark依赖设计
- Spark的分区器
- Spark中stage划分
- 提交spark任务的运行模式以及Spark Job提交流程
- 延迟调度和动态资源管理
- Shuffle性能提升
重点详细:戳这里
RDD(Resilient Distributed Datasets):一个只读且分区的数据集
每个RDD都会有下面6个特性:
- 分区并行计算
- RDD分区计算都有自己的计算函数
- 维持RDD依赖列表,通过这个依赖列表进行容错
- 可以按照一定规则自行分区,这些在RDD分区元数据信息有体现
- 分区数据有机器存储地址,根据地址到对应的机器上计算,以实现计算任务的本地性
- spark的计算是流式计算
所以RDD具有如下优势:
- 高效容错
- 可以控制数据的分区来优化计算性能
- 并行处理
- 提供丰富的操作数据的api
- 可以显式的将中间结果数据存储到内存中
***RDD的创建
1.从一个稳定 的存储系统中,比如HDFS文件
val inputRdd = sc.hadoopFile("hdfs://master:9999/user/hadoop-laoliu/hello.txt", classOf[TextInputFormat], classOf[LongWritable], classOf[Text])
2.从一个存在的RDD上可以创建一个RDD
val wordSplits:RDD[String] = inputRdd.flatMap(_._2.toString.split(" "))
3.从内存中已经存储在序列列表中
val listRDD = sc.parallelize[Int](Seq(1,2,3,3,4), 2) //后面的2是分两个区 scala> listRDD.glom.collect //查看元素分区 res1: Array[Array[Int]] = Array(Array(1, 2), Array(3, 3, 4))
总结:RDD的创建主要按创建来源进行分类:hdfs文件,父RDD,内存
那么这边重点讲下从内存里进行创建
有三个常用的接口:parallelize、range、makeRDD
//3: 从一个已经存在于内存中的列表, 可以指定分区,如果不指定的话分区数为所有executor的cores数
val listRDD = sc.parallelize[Int](Seq(1, 2, 3, 3, 4), 2)
listRDD.collect()
listRDD.glom().collect()
val rangeRDD = sc.range(0, 10, 2, 4)
rangeRDD.collect()
val makeRDD = sc.makeRDD(Seq(1, 2, 3, 3))
makeRDD.collect()
val makeRDDWithLocations =
sc.makeRDD(Seq((Seq(1, 2), Seq("172.26.232.93")), (Seq(3, 3, 4), Seq("172.26.232.93"))))
makeRDDWithLocations.collect()
makeRDD.glom().collect()
val defaultPartitionRDD = sc.parallelize[Int](Seq(1, 2, 3, 3, 4))
defaultPartitionRDD.partitions
其中parallelize和makeRDD一样,都返回ParallelCollectionRDD,区别就是makeRDD可以数据在哪些位置,由于makeRDD本质上调用的就是parallelize,两个api在定义上都会给defaultParallelism(默认分区数),上面如果没有给分区数,那么会取这个默认值,而这个值会取spark.default.parallelism的配置值,否则取最大核心数
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
spark-shell默认是没有这个配置的,所以就会取最大核心数,如果要设置,可以在 启动的时候进行设置spark-shell --master spark://master:7077 --conf spark.default.parallelism=3
scala> sc.getConf.get("spark.default.parallelism")
java.util.NoSuchElementException: spark.default.parallelism
at org.apache.spark.SparkConf$$anonfun$get$1.apply(SparkConf.scala:243)
at org.apache.spark.SparkConf$$anonfun$get$1.apply(SparkConf.scala:243)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.SparkConf.get(SparkConf.scala:243)
... 48 elided
java代码进行设置
val conf = new SparkConf().setAppName("word count")
val sc = new SparkContext(conf)
sc.getConf.remove("spark.default.parallelism")
//spark-shell --master spark://master:7077 --conf spark.default.parallelism=3
sc.getConf.set("spark.default.parallelism", "3")
上面对于makeRDD没有给分区数时候的情况,当然makeRDD还支持指定分区存储数据,这个时候分区数怎么计算的呢?
//这个是调用代码
val makeRDDWithLocations =
sc.makeRDD(Seq((Seq(1, 2), Seq("172.26.232.93")), (Seq(3, 3, 4), Seq("172.26.232.93"))))
//调用接口
//其中T类型 在这里对应seq类型, 而ParallelCollectionRDD的第三参数就是对应分区数
// 就是获取seq长度 确定分区数
// 其中第二参数就是 一个数据seq, 而indexToPrefs 索引和机器的map
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), math.max(seq.size, 1), indexToPrefs)
}
这两个Api都返回ParallelCollectionRDD,这个类继承了RDD,并且在这个类下,实现了getPartitions和compute和getPreferredLocations三个方法,而partitioner和getDependencies方法在RDD类中
***RDD依赖
RDD依赖中有种父子的关系,父RDD的输出数据就是子RDD的输入数据
了解RDD的关系 ,需要明确窄依赖和宽依赖的概念:
- 窄依赖:父亲RDD的一个分区数据只能被子RDD的一个分区消费(但是RDD的一个子分区可以对应父亲RDD的多个分区),其中一对一的又被称为OneToOneDependency(比如map,filter),而多对一则被称为RangeDependency(比如union,join),它的特点:不用等所有分区计算才计算,只要依赖的分区计算完就可以开始计算,在容错上,也是这样,只要重新计算出错的分区
- 宽依赖:父RDD的一个分区的数据同时被子RDD多个分区消费,这个称为ShuffleDependency(比如reduceByKey),它的特点:需要等所有的分区计算完才能计算,而它的容错上,就要对所有的分区重新计算
综上:宽依赖意味着会发生shuffle过程,也就是会发生数据传输过程,是很影响性能的,所以要尽量避免的,所以优化上可以从宽依赖的定义出发,就是父RDD的一个分区被子RDD多个分区消费,可以使用预分区试图破坏这个关系,比如让多个父RDD的多个分区对应一个子分区,并且这些RDD partitioner一样的,那么这种情况不会发生shuffle,这个情况其实变成了窄依赖
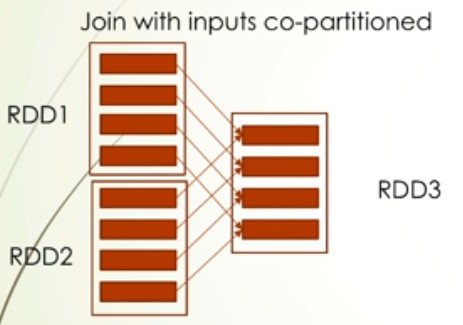
RDD分区
***HashPartitioner原理
RDD Partitioner就是给RDD数据进行分区的分区器
对于数据分区一般分下面三种情况:
- 从存储系统创建RDD的分区
- 非key-value RDD分区
- key-value RDD分区
对于第一种情况,我们没必要给它指定分区器,因为数据进行存储的时候就已经分了多少块了,默认按这个块进行分区就可以了,最多我们就是指定下最少分区数
对于第二种情况 ,我们也没必要指定分区器,比如map操作,一般父RDD多少分区,子RDD多少分区即可
所以我们主要针对key-value这种情况进行重新分区,一般对key按照某种规则进行分区
spark分区后的计算规则:数据量占的比较多机器上进行计算,由于分区的过程会发生数据的网络传输,所以这样做可以减少网络传输来提供性能
比如按照key的hash值进行分区
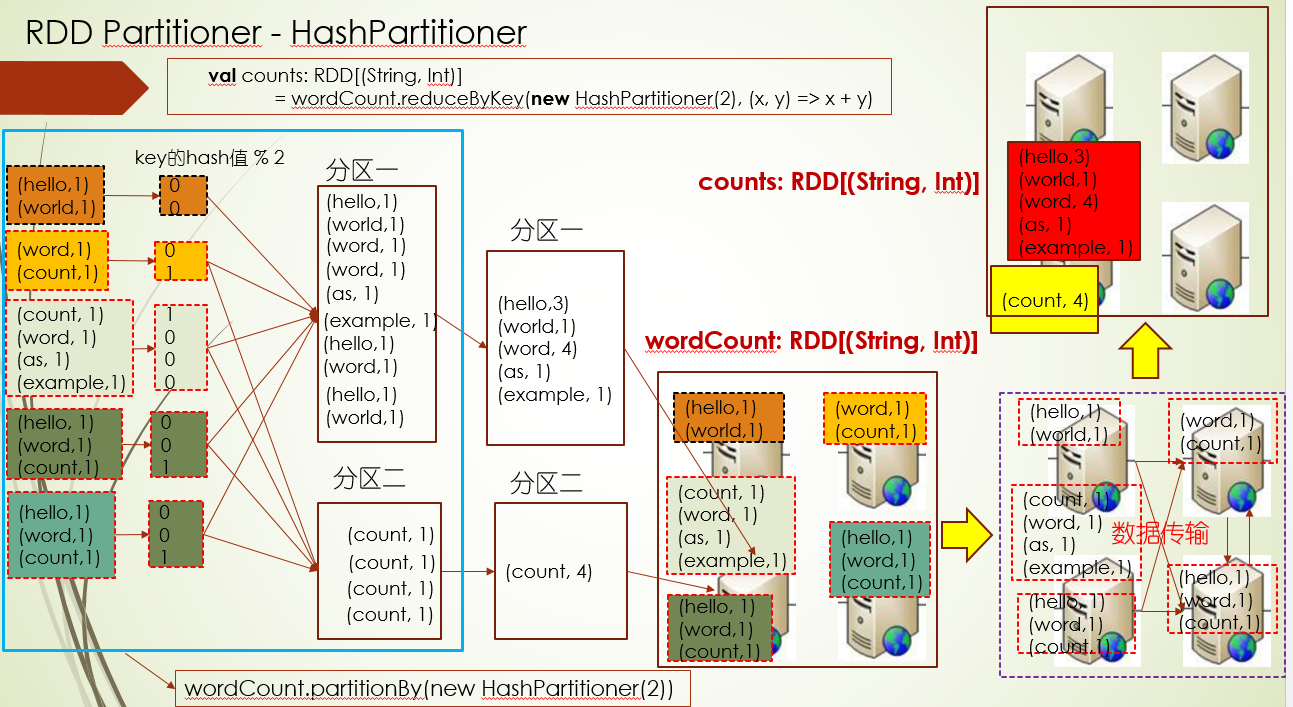
上面的reduceByKey过程是分区后进行计算了,如果只是想进行分区的话,可以用partitionBy(new HashPartitioner(2))
***Partitioner性能优化
先RDD预分区并缓存,把宽依赖变成窄依赖
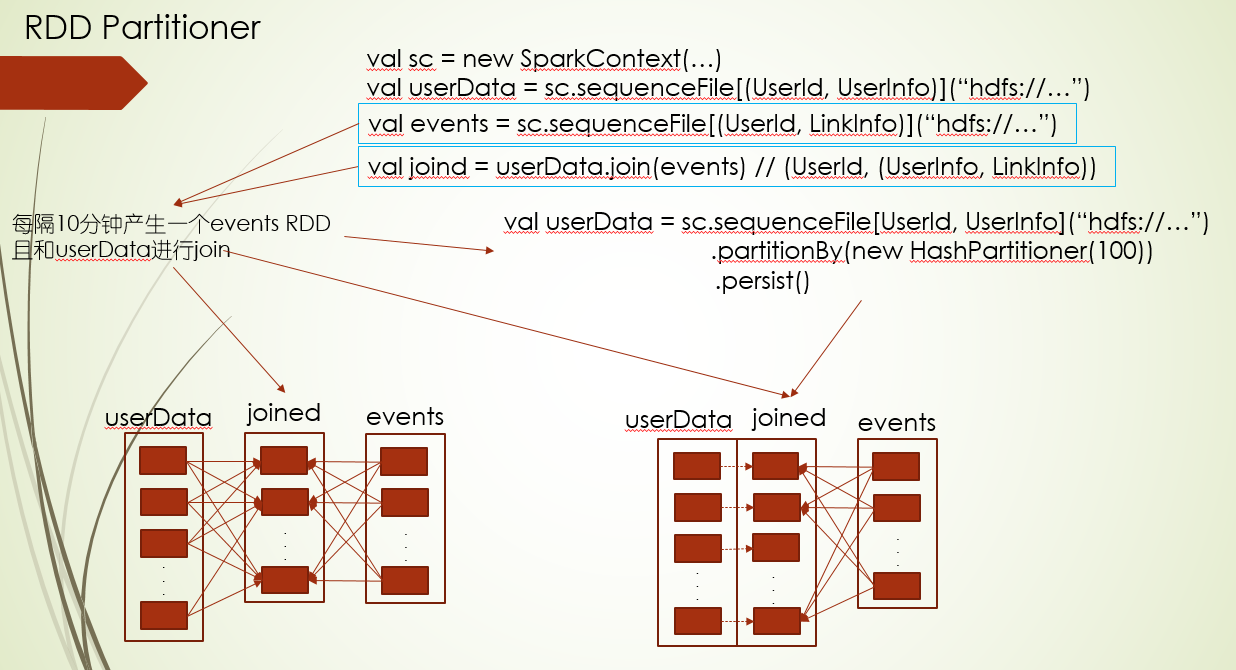
是否保留父RDD分区器(mapValue, flatMapValue),你就可以理解为这两个函数不会动用key,所以为会保留分区器给子RDD,因为动用key就会涉及重新分区的问题,所以有可能会出之前的窄依赖又变成了宽依赖
package com.twq.spark.rdd.partition
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* Created by tangweiqun on 2017/8/21.
*/
object PageRankTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("word count")
val sc = new SparkContext(conf)
val links =
sc.parallelize[(String, Seq[String])](Seq(("baidu.com", Seq("jd.com", "ali.com")),
("ali.com", Seq("test.com")),
("jd.com", Seq("baidu.com")))).partitionBy(new HashPartitioner(3)).persist()
var ranks = links.mapValues(v => 1.0)
for(i <- 1 until 10) {
val contributions = links.join(ranks).flatMap {
case (pageId, (links, rank)) =>
links.map(dest => (dest, rank / links.size))
}
ranks = contributions.reduceByKey((x, y) => x + y).mapValues(v => 0.15 + 0.85 * v)
}
ranks.saveAsTextFile("hdfs://master:9999/users/hadoop-twq/ranks")
val testRDD = sc.parallelize[(String, Int)](Seq(("baidu", 2),
("ali", 2), ("jd", 3), ("hhh", 4), ("hhh", 2),
("ali", 2), ("jd", 2), ("mmss", 5))).partitionBy(new HashPartitioner(3)).persist()
val reduceByKeyRDD = testRDD.reduceByKey(new HashPartitioner(3), (x, y) => x + y)
val joined = testRDD.join(reduceByKeyRDD)
joined.collect()
val mapValuesRDD = testRDD.mapValues(x => x + 1)
mapValuesRDD.collect()
mapValuesRDD.partitioner
val nonShuffleJoined = mapValuesRDD.join(reduceByKeyRDD)
val mapRDD = testRDD.map { case (key, value) => (key, value + 1) }
mapRDD.collect()
mapRDD.partitioner //None
val shouldShuffleJoin = mapRDD.join(reduceByKeyRDD)
}
}
总结:分区器的性能优化主要从两个方面考虑:1.把宽依赖变窄依赖,可以通过预分区+缓存的方法 2.防止窄依赖变成宽依赖,避免对key进行更改,比如mapValues的应用,保留分区器
***RangePartitioner原理
RangePartitioner,从单词字面意思很好理解,就是按照范围,一般它有这么几个特点
- 要求key可以排序
- 所有的分区数据大概相等
具体实现步骤如下:
- 对每一个分区进行数据采样并计算每一个采样到的数据的权重
- 根据采样到的数据 和权重计算每一个分区的最大key值
- 用需要分区的key和上面计算到每一个分区最大的key值对比决定这个key划入哪个分区
比如一个有10个分区的RDD[(Int, String)]需要按照RangePartitioner重分区为3个分区: 分区一接受 >=0且<=10 的key的数据 分区二接受 >10且<=30的key的数据 分区三接受 >30的key的数据
实现细节


package com.twq.spark.rdd.partition
import org.apache.spark.{HashPartitioner, RangePartitioner, SparkConf, SparkContext}
/**
* Created by tangweiqun on 2017/8/19.
*/
object PartitionerTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("word count")
val sc = new SparkContext(conf)
val pairRDD = sc.parallelize[(String, Int)](Seq((("hello",1)), ("world", 1),
("word", 1), ("count", 1), ("count", 1), ("word", 1), ("as", 1),
("example", 1), ("hello", 1), ("word", 1), ("count", 1),
("hello", 1), ("word", 1), ("count", 1)), 5)
val hashPartitionedRDD = pairRDD.partitionBy(new HashPartitioner(2))
hashPartitionedRDD.glom().collect()
val partitionedRDD = pairRDD.partitionBy(new RangePartitioner[String, Int](2, pairRDD))
partitionedRDD.glom().collect()
val partitionedDescRDD = pairRDD.partitionBy(new RangePartitioner[String, Int](2, pairRDD, false))
partitionedDescRDD.glom().collect()
val hdfsFileRDD = sc.textFile("hdfs://master:9999/users/hadoop-twq/word.txt", 1000)
hdfsFileRDD.partitions.size // 1000
//我们通过coalesce来降低分区数量的目的是:
//分区太多,每个分区的数据量太少,导致太多的task,我们想减少task的数量,所以需要降低分区数
//第一个参数表示我们期望的分区数
//第二个参数表示是否需要经过shuffle来达到我们的分区数
val coalesceRDD = hdfsFileRDD.coalesce(100, false)
coalesceRDD.partitions.size //100
//从1000个分区一下子降到2个分区
//这里会导致1000个map计算只在2个分区上执行,会导致性能问题
hdfsFileRDD.map(_ + "test").coalesce(2, true)
}
}
***HashPartitioner和RangePartitioner对比
- hash分区器不支持类型为Array(_)的key,因为数组的hash值是根据内存地址来的,一直在变,而range分区器不支持不能排序的key
- hash分区器可能导致分区的数据倾斜,而range分区器可以解决这个问题
- hash分区器分区后的数据不会排序,而range分区器分区后,分区之间的数据是排序,分区里的数据没排序,不过range分区器分区后的重新进行排序,效率非常高的,因为只要对分区内的数据进行排序
- 一般情况还是使用hash分区器,它可以解决80%的问题
***自定义Partitioner
如果key为url,我们希望域名相同的key进入到同一个分区,那就需要我们自定义DomainNamePartitioner
需要继承Partitioner,并重写numPartitions和getPartition方法
package com.twq.spark.rdd.partition
import java.net.URL
import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext}
/**
* Created by tangweiqun on 2017/8/22.
*/
class DomainNamePartitioner(val numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int = {
val domain = new URL(key.toString).getHost
val code = (domain.hashCode % numParts)
if (code < 0) {
code + numParts
} else {
code
}
}
override def equals(obj: scala.Any): Boolean = obj match {
case dnp: DomainNamePartitioner =>
dnp.numParts == numParts
case _ => false
}
override def hashCode(): Int = numParts
}
object DomainNamePartitioner {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("word count")
val sc = new SparkContext(conf)
val urlRDD = sc.makeRDD(Seq(("http://baidu.com/test", 2),
("http://baidu.com/index", 2), ("http://ali.com", 3), ("http://baidu.com/tmmmm", 4),
("http://baidu.com/test", 4)))
//Array[Array[(String, Int)]]
// = Array(Array(),
// Array((http://baidu.com/index,2), (http://baidu.com/tmmmm,4),
// (http://baidu.com/test,4), (http://baidu.com/test,2), (http://ali.com,3)))
val hashPartitionedRDD = urlRDD.partitionBy(new HashPartitioner(2))
hashPartitionedRDD.glom().collect()
//使用spark-shell --jar的方式将这个partitioner所在的jar包引进去,然后测试下面的代码
// spark-shell --master spark://master:7077 --jars spark-rdd-1.0-SNAPSHOT.jar
val partitionedRDD = urlRDD.partitionBy(new DomainNamePartitioner(2))
partitionedRDD.glom().collect()
}
}
*****控制分区数coalesce
coalesce接口就是改变RDD的分区数,主要在这么几个场景下用到:
1.将一个含有1000个分区的RDD的分区数降为100个
//我们通过coalesce来降低分区数量的目的是:
//分区太多,每个分区的数据量太少,导致太多的task,我们想减少task的数量,所以需要降低分区数
//第一个参数表示我们期望的分区数
//第二个参数表示是否需要经过shuffle来达到我们的分区数
val coalesceRDD = hdfsFileRDD.coalesce(100, false)
2.将一个含有100个分区的RDD的分区数升为1000个
//发现没有升上去 scala> coalesceRDD.coalesce(1000, false).partitions.size res4: Int = 100 // 如果把shuffle 改成true,就可以 coalesceRDD.coalesce(1000, true)
3.将一个含有1000个分区的RDD的分区数降为2个,在map场景下,降的太猛,所有的map task在两个分区下计算,会降低性能,所以我们可以把shuffle参数置为true,这样就会先在1000分区并行运行map task,然后把所有的计算结果进行shuffle,分成两个区
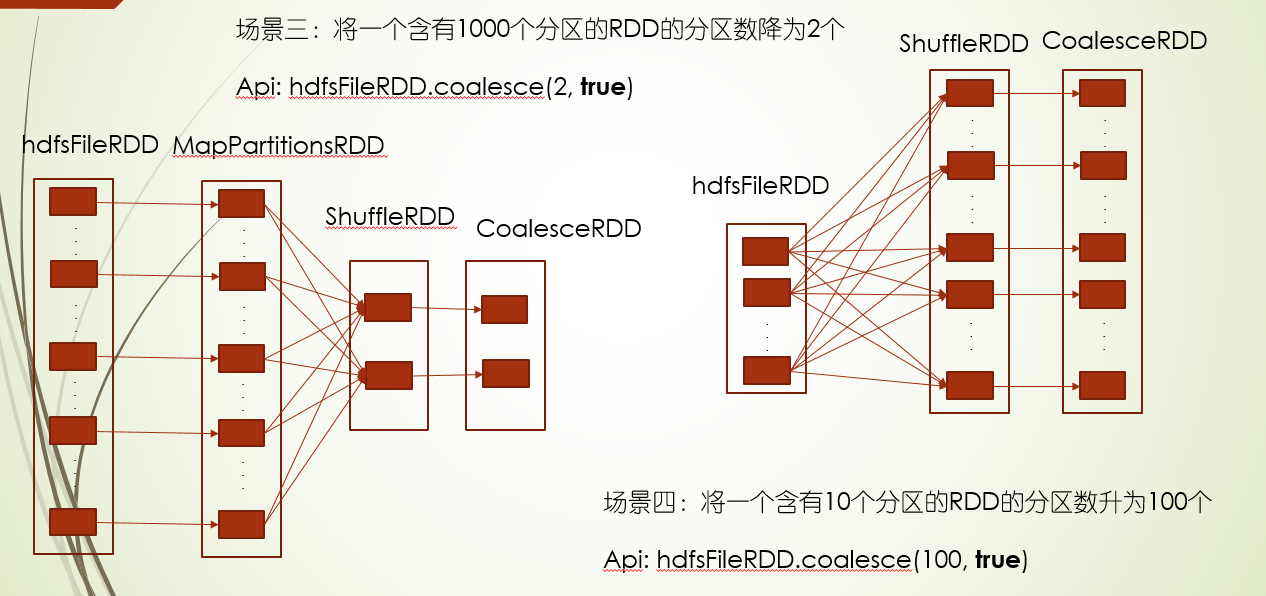
其中repartition有如下对等关系,所以是在需要shuffle的场景下使用,比如猛降分区数,以及提供分区数
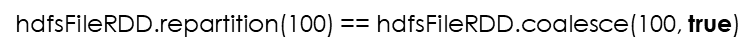
coalesce实现原理
场景一:100分区数降为10
一般分为这么两个步骤:
- 设置PartitionGroup, 就是要分多少区,就有多少个group,这里10个
- 为每一个父亲RDD分区选择一个PartitionGroup
我们明确下场景:就是RDD分区部分含有存储位置信息
首先会先对是否有存储位置信息分组,有位置的分为一组,无位置的分为一组,其中会对有位置的按照存储位置展平,展平后的数据,你就可以理解类似seq,元素为(host, 分区号),然后循环遍历这个seq,给每个group设定host,先判断当前host有没有在哪个group设定过,没有才进行设定,如果分区已经给了某个group,那么这个group的分区暂时设置为空,没给的话,就把这个分区给这个group,循环完整个seq,发现还有group没有设定host,那么就再进行循环seq,直到设定完
还要循环seq把没有分的分区,分到group里,原则上往少的或者没有的里面分,这里是大概的分下,保证每个group有一个分区(需要再次确认)

如果没有没有位置信息的
Setup partitionGroup PartitionGroup1(None, Array(0到9)) PartitionGroup2(None, Array(10到19)) PartitionGroup3(None, Array(20到29)) PartitionGroup4(None, Array(30到39)) PartitionGroup5(None, Array(40到49)) PartitionGroup6(None, Array(50到59)) …… PartitionGroup10(None, Array(90到99))
上面过程只是对设定group,还没进行真正的分区
比如分区3来了,应该进入到哪个新的分区(也就是group)
首先它根据分区3获取host信息,也就是host1,再根据host去找paritionGroup,找到两,pg1和pg4,其中pg1分区数少,pg1进入待定区域
其次会随机取两个PartitionGroup,假设pg2和pg10,比较两个分区数,其中pg2少,pg2进入待定区域
最后根据因子公式对pg1和pg2进行比较,确定哪个group
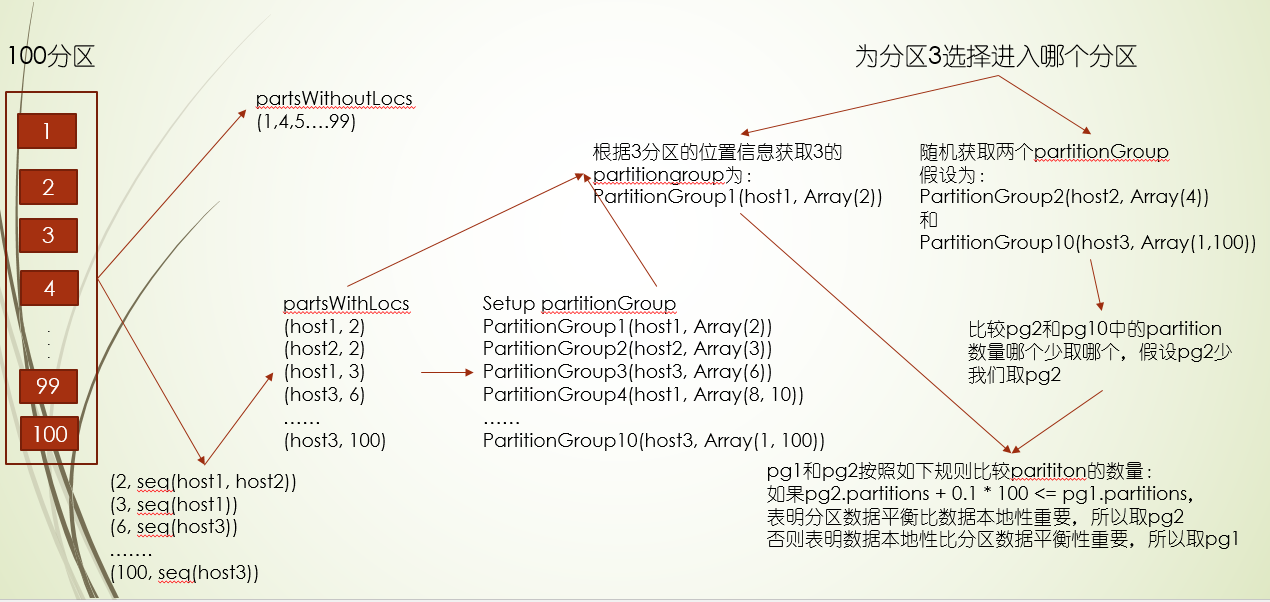
RDD基本操作
***单类型transformation api
常见的接口有map,flatMap,filter,mapPartition,mapPartitionWithIndex,glom
前三个接口就不多讲了,这三个在scala的集合中常见,主要讲下后三个
- mapPartition和map的作用差不多,就是对每个元素进行处理,返回处理结果,只不过map按数据为单元循环,而mapPartition则是以分区为单元循环,那它有什么好处呢?就是在map过程开始的时候有非常的耗时的操作(比如连接数据库),用mapPartition比较省时,因为每个分区开始连接一次
- glom 查看RDD的数据分区情况
- mapPartitionWithIndex 不仅循环分区数据 还是 带上分区 索引
package com.twq.spark.rdd
import java.util.concurrent.TimeUnit
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
/**
* Created by tangweiqun on 2017/8/24.
*/
object MapApiTest {
def getInitNumber(source: String): Int = {
println(s"get init number from ${source}, may be take much time........")
TimeUnit.SECONDS.sleep(2)
1
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test")
val sc = new SparkContext(conf)
val listRDD = sc.parallelize[Int](Seq(1, 2, 3, 3), 2)
val mapRDD = listRDD.map(x => x + 1)
mapRDD.collect()
val users = listRDD.map { x =>
if (x < 3) User("小于3", 22) else User("大于3", 33)
}
users.collect()
val l = List(List(1,2,3), List(2,3,4))
l.map(x => x.toString())
l.flatMap(x => x)
val flatMapRDD = listRDD.flatMap(x => x.to(3))
flatMapRDD.collect()
val filterRDD = listRDD.filter(x => x != 1)
filterRDD.collect()
//将rdd的每一个分区的数据转成一个数组,进而将所有的分区数据转成一个二维数组
val glomRDD = listRDD.glom()
glomRDD.collect() //Array(Array(1, 2), Array(3, 3))
val mapPartitionTestRDD = listRDD.mapPartitions (iterator => {
iterator.map(x => x + 1)
})
mapPartitionTestRDD.collect()
val mapWithInitNumber = listRDD.map(x => {
val initNumber = getInitNumber("map")
x + initNumber
})
mapWithInitNumber.collect()
val mapPartitionRDD = listRDD.mapPartitions (iterator => {
//和map api的功能是一样,只不过map是将函数应用到每一条记录,而这个是将函数应用到每一个partition
//如果有一个比较耗时的操作,只需要每一分区执行一次这个操作就行,则用这个函数
//这个耗时的操作可以是连接数据库等操作,不需要计算每一条时候去连接数据库,一个分区只需连接一次就行
val initNumber = getInitNumber("mapPartitions")
iterator.map(x => x + initNumber)
})
mapPartitionRDD.collect()
val mapPartitionWithIndexRDD = listRDD.mapPartitionsWithIndex((index, iterator) => {
iterator.map(x => x + index)
})
mapPartitionWithIndexRDD.collect()
}
}
case class User(userId: String, amount: Int)
MapPartitionsRDD概念:将自定义的函数应用到父亲rdd每一个分区输出数据中
它一般具备如下特点
- 有且只有一个窄依赖,即只依赖一个父亲RDD
- 分区器,可以选择是否保留父亲RDD的分区器,比如过滤操作,没有对key进行操作,可以选择保留
- 计算分区列表,继承父亲RDD的分区列表
- 将用户定义的函数应用到父亲RDD的每一个分区数据中
- 父亲RDD分区数据在哪里就在哪里执行第四步的计算
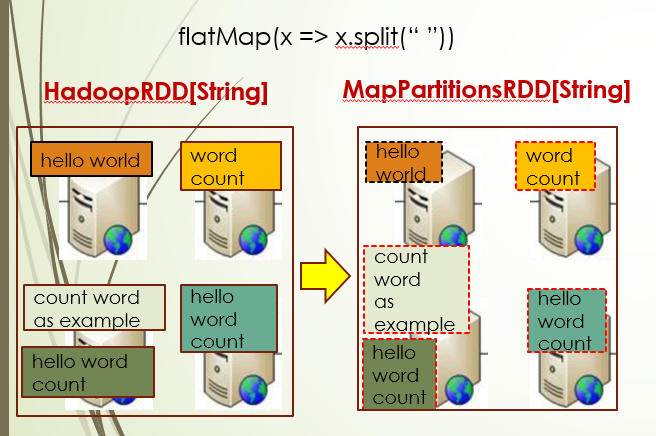
采样
sample,takeSample,randomSplit
package com.twq.spark.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by tangweiqun on 2017/8/24.
*/
object SampleApiTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test")
val sc = new SparkContext(conf)
val listRDD = sc.parallelize[Int](Seq(1, 2, 3, 3), 2)
//第一个参数为withReplacement
//如果withReplacement=true的话表示有放回的抽样,采用泊松抽样算法实现
//如果withReplacement=false的话表示无放回的抽样,采用伯努利抽样算法实现
//第二个参数为:fraction,表示每一个元素被抽取为样本的概率,并不是表示需要抽取的数据量的因子
//比如从100个数据中抽样,fraction=0.2,并不是表示需要抽取100 * 0.2 = 20个数据,
//而是表示100个元素的被抽取为样本概率为0.2;样本的大小并不是固定的,而是服从二项分布
//当withReplacement=true的时候fraction>=0
//当withReplacement=false的时候 0 < fraction < 1
//第三个参数为:reed表示生成随机数的种子,即根据这个reed为rdd的每一个分区生成一个随机种子
val sampleRDD = listRDD.sample(false, 0.5, 100)
sampleRDD.glom().collect()
//按照权重对RDD进行随机抽样切分,有几个权重就切分成几个RDD
//随机抽样采用伯努利抽样算法实现
val splitRDD = listRDD.randomSplit(Array(0.2, 0.8))
splitRDD.size
splitRDD(0).glom().collect()
splitRDD(1).glom().collect()
//随机抽样指定数量的样本数据
listRDD.takeSample(false, 1, 100)
val pairRDD = sc.parallelize[(Int, Int)](Seq((1, 2), (3, 4), (3, 6), (5, 6)), 4)
//分层采样
val fractions = Map(1 -> 0.3, 3 -> 0.6, 5 -> 0.3)
val sampleByKeyRDD = pairRDD.sampleByKey(true, fractions)
sampleByKeyRDD.glom().collect()
val sampleByKeyExac = pairRDD.sampleByKeyExact(true, fractions)
sampleByKeyExac.glom().collect()
}
}
分层采样:sampleByKey,sampleByKeyExact

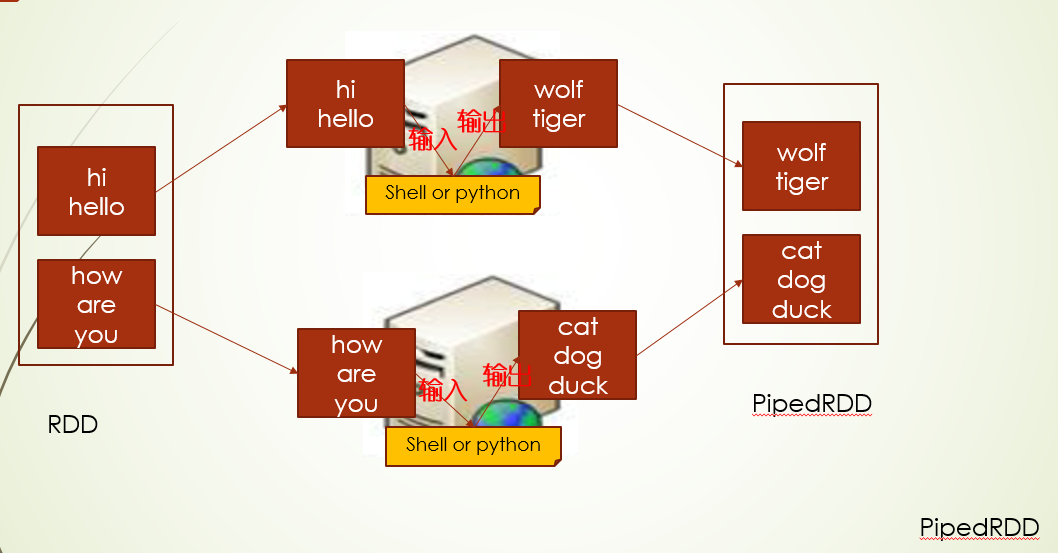
RDD pipe api调用python脚本
pipe接口,你就可以理解为在进行RDD转换的中间过程,可以使用脚本来灵活处理数据
其中和脚本交互要求是标准输入输出流
源代码细节(主要是compute):
- 实例执行脚本进程句柄,设置环境变量
- 判断任务工作目录,是否要同一目录
- 启动脚本进程,获取输出标准流句柄,然后循环split(分区)的数据,通过输出流句柄printIn数据
- 打印的数据给到脚本执行,脚本标准输出给 输入流句柄,最终获取所有的lines,闭包给一个Iterator实例返回
注:这个里输入输出句柄相对运行程序本身而言,也就是spark app
package com.twq.spark.rdd
import java.io._
import org.apache.spark.{SparkConf, SparkContext, SparkFiles}
/**
* Created by tangweiqun on 2017/8/24.
*/
object PipeApiTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(List("hi", "hello", "how", "are", "you"), 2)
//运行进程需要的环境变量
val env = Map("env" -> "test-env")
//在执行一个分区task且处理分区输入元素之前将这个分区的全局数据作为脚本的输入的话,则需要定义这个函数
// 上面这句话 我没理解 但是这里的实现效果 就是在每个分区的数据前 加了this is task context data per partition
def printPipeContext(func: String => Unit): Unit = {
val taskContextData = "this is task context data per partition"
func(taskContextData)
}
//在执行分区task的时候,需要对每一个输入元素做特殊处理的话,可以定义这个函数参数
def printRDDElement(ele: String, func: String => Unit): Unit = {
if (ele == "hello") {
func("dog")
} else func(ele)
}
//表示执行一个本地脚本(可以是shell,python,java等各种能通过java的Process启动起来的脚本进程)
//dataRDD的数据就是脚本的输入数据,脚本的输出数据会生成一个RDD即pipeRDD
val pipeRDD = dataRDD.pipe(Seq("python", "/home/hadoop-twq/spark-course/echo.py"),
env, printPipeContext, printRDDElement, false)
pipeRDD.glom().collect()
val pipeRDD2 = dataRDD.pipe("sh /home/hadoop-twq/spark-course/echo.sh")
pipeRDD2.glom().collect()
// 你的python脚本所在的hdfs上目录
// 然后将python目录中的文件代码内容全部拿到
val scriptsFilesContent =
sc.wholeTextFiles("hdfs://master:9999/users/hadoop-twq/pipe").collect()
// 将所有的代码内容广播到每一台机器上
val scriptsFilesB = sc.broadcast(scriptsFilesContent)
// 创建一个数据源RDD
val dataRDDTmp = sc.parallelize(List("hi", "hello", "how", "are", "you"), 2)
// 将广播中的代码内容写到每一台机器上的本地文件中
dataRDDTmp.foreachPartition(_ => {
scriptsFilesB.value.foreach { case (filePath, content) =>
val fileName = filePath.substring(filePath.lastIndexOf("/") + 1)
val file = new File(s"/home/hadoop-twq/spark-course/pipe/${fileName}")
if (!file.exists()) {
val buffer = new BufferedWriter(new FileWriter(file))
buffer.write(content)
buffer.close()
}
}
})
// 对数据源rdd调用pipe以分布式的执行我们定义的python脚本
val hdfsPipeRDD = dataRDDTmp.pipe(s"python /home/hadoop-twq/spark-course/pipe/echo_hdfs.py")
hdfsPipeRDD.glom().collect()
//我们不能用如下的方法来达到将hdfs上的文件分发到每一个executor上
sc.addFile("hdfs://master:9999/users/hadoop-twq/pipe/echo_hdfs.py")
SparkFiles.get("echo.py")
}
}
# -*- coding:utf-8 -*-
#! /usr/bin/env python
# __author__ = 'seven'
import os,sys
inp = sys.stdin
env = os.environ.get("env", "")
out_file = open("/home/hadoop-laoliu/spark-course/output.txt", "w")
for ele in inp:
output = "slave1-" + ele.strip('\n') + "-" + env
print(output)
out_file.write(output)
inp.close()
out_file.close()
可以看到这个结果对比,两个Array,代表还是两个分区,每个分区数据最前面都加了this is task。。。,其中每个数据都经过python的脚本处理,加上了slave以及环境变量env,其中分区一的hello被特殊处理成dog了

Action Api
单类型RDD的基本action
其中foreach,foreachPartition,collect,take,first,top,max,min这些api,比较常见,看代码就能理解,不用赘述
先看下reduce,fold,treeReduce的区别:
- reduce 对所有的结果进行累加
- fold 可以指定初始值累加,这里不是只在所有的元素累加前,加上这个初始值,而是在每个分区数据累加前,都会加上这个初始值,以及最后对所有分区的计算结果累加前,也会加上
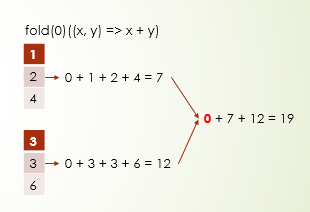
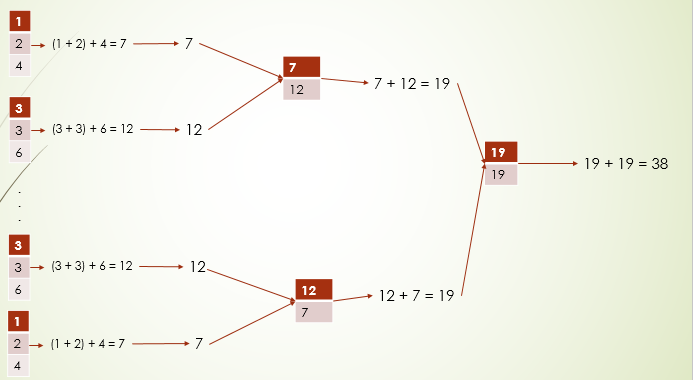
- treeReduce 你就可以理解为在分区数非常多的时候,使用这个性能更好,它不是把所有分区计算结果,一下子拿到一个地方计算,而是会进行逐级合并,比如8个分区(这里只是举例,这个分区数不算多)计算完后,先两两合并,得到4个计算结果,再两个合并。。每次合并数据量较少,可以提高性能
package com.twq.spark.rdd
import java.util.concurrent.TimeUnit
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by tangweiqun on 2017/8/24.
*/
object BaseActionApiTest {
def getInitNumber(source: String): Int = {
println(s"get init number from ${source}, may be take much time........")
TimeUnit.SECONDS.sleep(2)
1
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test")
val sc = new SparkContext(conf)
val listRDD = sc.parallelize[Int](Seq(1, 2, 4, 3, 3, 6), 2)
listRDD.collect() //收集rdd的所有数据
listRDD.take(2) // 取前两个元素
listRDD.top(2) // 取最大的两个
listRDD.first() // 取第一个
listRDD.min() //取最小
listRDD.max()(new MyOrderingNew) //排序后取第一个元素,默认是从大到小,所以取最大
listRDD.takeOrdered(2)(new MyOrderingNew) //排序后 取前两个
listRDD.foreach(x => {
val initNumber = getInitNumber("foreach")
println(x + initNumber + "==================")
})
listRDD.foreachPartition(iterator => {
//和foreach api的功能是一样,只不过一个是将函数应用到每一条记录,这个是将函数应用到每一个partition
//如果有一个比较耗时的操作,只需要每一分区执行一次这个操作就行,则用这个函数
//这个耗时的操作可以是连接数据库等操作,不需要计算每一条时候去连接数据库,一个分区只需连接一次就行
val initNumber = getInitNumber("foreachPartition")
iterator.foreach(x => println(x + initNumber + "================="))
})
listRDD.reduce((x, y) => x + y)
listRDD.treeReduce((x, y) => x + y)
//和reduce的功能类似,只不过是在计算每一个分区的时候需要加上初始值1,最后再将每一个分区计算出来的值相加再加上这个初始值
listRDD.fold(0)((x, y) => x + y)
//先初始化一个我们想要的返回的数据类型的初始值
//然后在每一个分区对每一个元素应用函数一(acc, value) => (acc._1 + value, acc._2 + 1)进行聚合
//最后将每一个分区生成的数据应用函数(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)进行聚合
listRDD.aggregate((0, 0))(
(acc, value) => (acc._1 + value, acc._2 + 1),
(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
)
listRDD.treeAggregate((0, 0))(
(acc, value) => (acc._1 + value, acc._2 + 1),
(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
)
}
}
class MyOrderingNew extends Ordering[Int] {
override def compare(x: Int, y: Int): Int = {
y - x
}
}
aggregate和treeAggregate聚合,可以一个元组初始值,给定两个函数,一个是对分区内数据计算,一个是对最后的结果进行计算,比如可以通过对求和,次数进行计算



总结:reduce,fold,treeReduce都是对单个维度进行统计,常见的就是求和,三个接口在运算过程不能改变原来的数据类型,而fold需要指定初始值,这个初始值会在分区开始计算前加进去,最后在所有分区汇总前再一次加进去,另外treeReduce逐级合并,所以在分区比较多的情况下,比reduce性能高,而aggregate和treeAggregate则是fold的升级版,就是可以同时进行统计多个维度,这两个接口不仅需要指定初始值,还要指定两个函数,分别是分区内的数据累加计算函数和分区间的汇总计算函数,而treeAggregate也是逐级合并的,所以分区多时,比aggregate的性能更高,另外treeAggregate在最会汇总时不会加初始值
key-value RDD操作
创建
package com.twq.spark.rdd.keyvalue
import com.twq.spark.rdd.User
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by tangweiqun on 2017/8/19.
*/
object KeyValueCreationTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("word count")
val sc = new SparkContext(conf)
val kvPairRDD =
sc.parallelize(Seq(("key1", "value1"), ("key2", "value2"), ("key3", "value3")))
kvPairRDD.collect()
val personSeqRDD =
sc.parallelize(Seq(User("jeffy", 30), User("kkk", 20), User("jeffy", 30), User("kkk", 30)))
//将RDD变成二元组类型的RDD
val keyByRDD = personSeqRDD.keyBy(x => x.userId) //keyBy 函数的返回值作为key
keyByRDD.collect()
val keyRDD2 = personSeqRDD.map(user => (user.userId, user)) //类似于上面keyBy的效果
val groupByRDD = personSeqRDD.groupBy(user => user.userId) // 按照函数返回值进行分组,这个值相同的元素放入同一组中,这里就是名字相同的,user放一起
groupByRDD.glom().collect()
val rdd1 = sc.parallelize(Seq("test", "hell"))
rdd1.map(str => (str, 1))
rdd1.collect()
}
}
总结:key-value RDD的元素组成本质就是二元组,所以key-value RDD的构造本质上就是围绕怎么把RDD中的元素构造成二元组,单元素RDD最简单 的 方式就是通过map返回二元组,另外就是keyBy,效果上和map过程类似,还有groupBy也能实现构造key-value RDD,这个API是把同一key的元素划分到同一组里
combineByKey
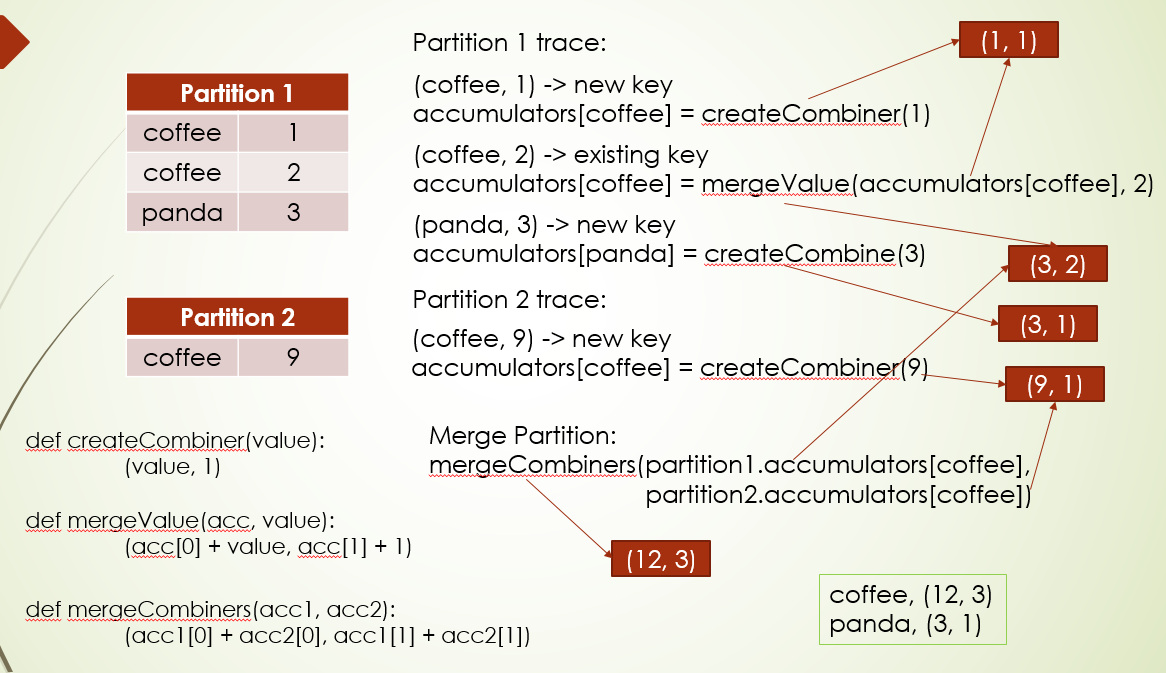
对Map类型数据进行聚合,先讲前三个参数:
createCombiner:主要第一次遇到的key会进行这个函数计算
mergeValue: 已经遇到过的key会进行这个函数计算
mergeCombiners: 分区数据累加计算用这个函数计算
val pairStrRDD = sc.parallelize[(String, Int)](Seq(("coffee", 1),
("coffee", 2), ("panda", 3), ("coffee", 9)), 2)
def createCombiner = (value: Int) => (value, 1)
def mergeValue = (acc: (Int, Int), value: Int) => (acc._1 + value, acc._2 + 1)
def mergeCombiners = (acc1: (Int, Int), acc2: (Int, Int)) =>
(acc1._1 + acc2._1, acc1._2 + acc2._2)
//功能:对pairStrRDD这个RDD统计每一个相同key对应的所有value值的累加值以及这个key出现的次数
//需要的三个参数:
//createCombiner: V => C, ==> Int -> (Int, Int)
//mergeValue: (C, V) => C, ==> ((Int, Int), Int) -> (Int, Int)
//mergeCombiners: (C, C) => C ==> ((Int, Int), (Int, Int)) -> (Int, Int)
val testCombineByKeyRDD =
pairStrRDD.combineByKey(createCombiner, mergeValue, mergeCombiners)
testCombineByKeyRDD.collect()

看到到下图:假如有两个分区,他们并行计算
先说分区1,首先进来的数据(coffee,1),coffee是第一遇到的key,所以会运行createCombiner函数,其中传给这个函数value参数也就是数据的value值,就是1,经函数计算返回(1,1),这个元组会传给同一key的mergeValue函数的第一个参数acc,那现在循环到到分区第二条数据(coffee,2),发现这个key不是新的,那么它就进入mergeValue进行计算,value参数值就是2,所以返回值(3, 2), 而循环到第三条数据则是新的key,返回(3,1)
分区二里循环第一条,coffee也是新的key,所以会返回(9,1)
最后分区累加,会用mergeCombiners,它会把key相同的,进行聚合累加,比如这里的coffee,分区1(3,2)和分区2(9,1),他们累加后最终得到(12,3), 而panda只有一个分区里有,直接返回(3,1)
接口的第四个参数,是否进行重分区,那么会不会分区还分这么几种场景
父RDD没有分区器,在进行聚合指定了分区器,那么这个时候会发生shuffle重分区
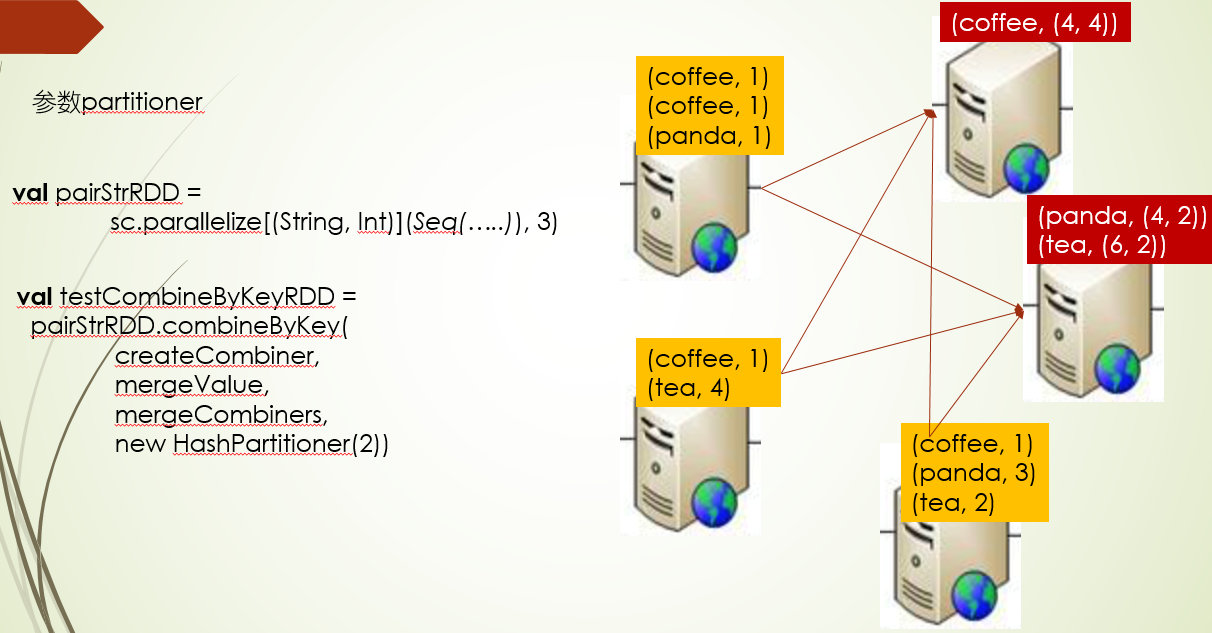
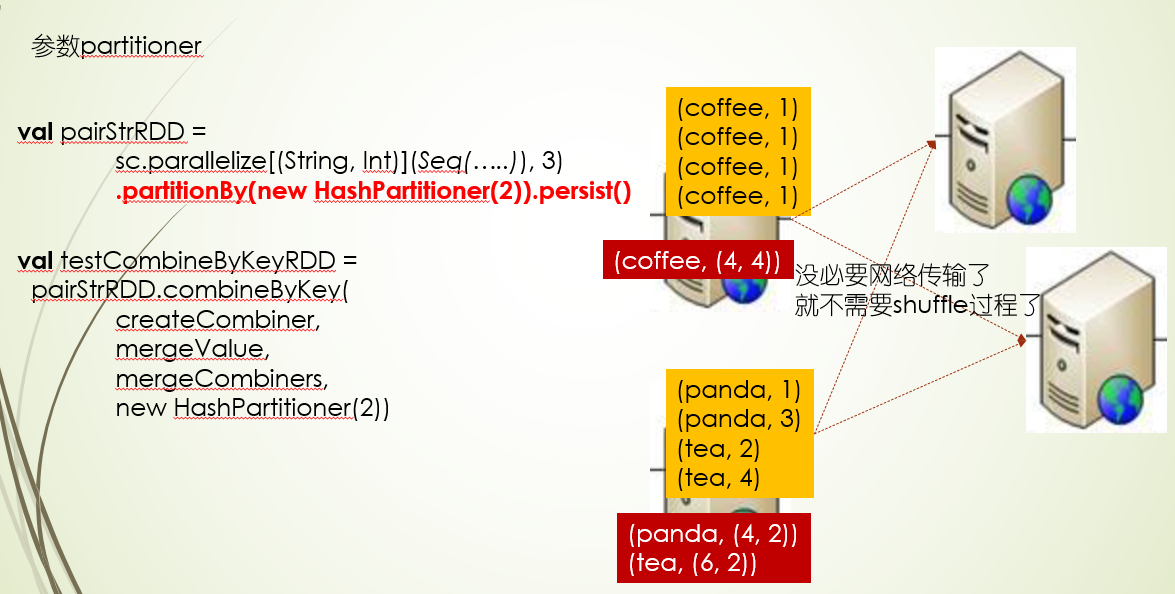
如果RDD重分区过还缓存了,那么这是传入分区都没用,不会进行网络传输,直接聚合计算就可以了(这里还没确定是否重分区有关系,还是缓存)
如果没传分区器,它会循序下面三个原则

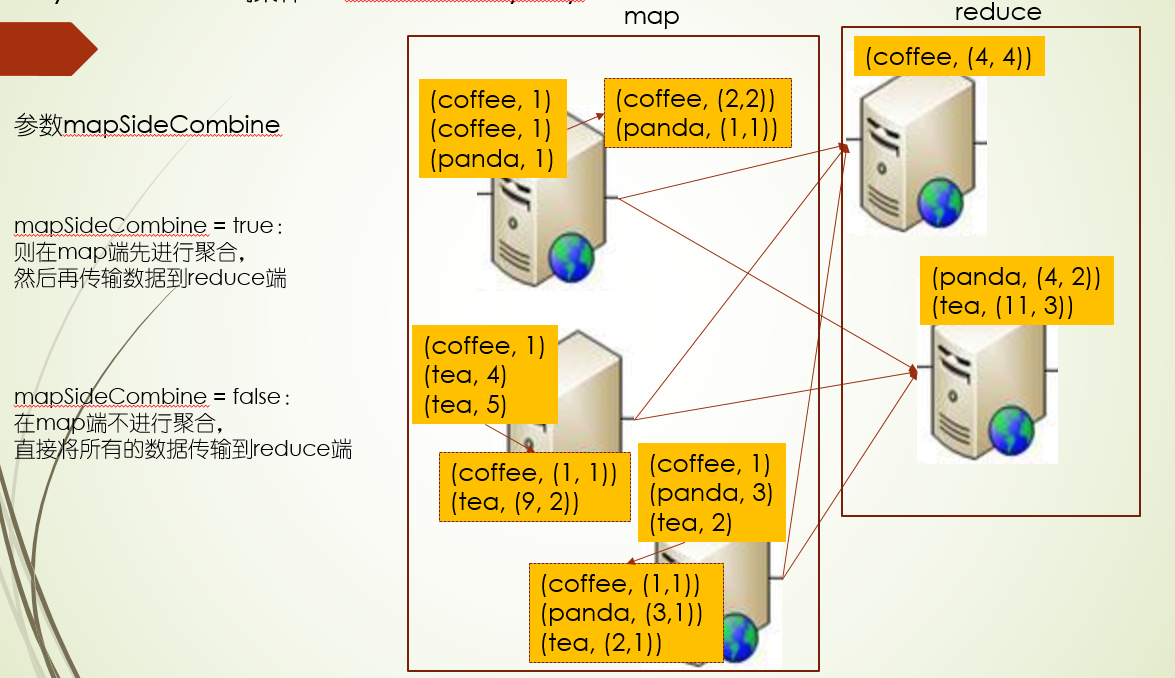
参数mapSideCombine,是否在map端先聚合下,再进行传输到reduce端,默认为true,map端聚合
参数serializer,序列化,在shuffle中间数据序列化后存储到磁盘中或者从磁盘中反序列化数据
import org.apache.spark.serializer.JavaSerializer
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
val pairStrRDD = sc.parallelize[(String, Int)](Seq(("coffee", 1),
("coffee", 2), ("panda", 3), ("coffee", 9)), 2)
def createCombiner = (value: Int) => (value, 1)
def mergeValue = (acc: (Int, Int), value: Int) => (acc._1 + value, acc._2 + 1)
def mergeCombiners = (acc1: (Int, Int), acc2: (Int, Int)) =>
(acc1._1 + acc2._1, acc1._2 + acc2._2)
//功能:对pairStrRDD这个RDD统计每一个相同key对应的所有value值的累加值以及这个key出现的次数
//需要的三个参数:
//createCombiner: V => C, ==> Int -> (Int, Int)
//mergeValue: (C, V) => C, ==> ((Int, Int), Int) -> (Int, Int)
//mergeCombiners: (C, C) => C ==> ((Int, Int), (Int, Int)) -> (Int, Int)
val testCombineByKeyRDD =
pairStrRDD.combineByKey(createCombiner, mergeValue, mergeCombiners)
testCombineByKeyRDD.collect()
val pairRDD = sc.parallelize[(Int, Int)](Seq((1, 2), (3, 4), (3, 6), (5, 6)), 2)
//.partitionBy(new HashPartitioner(2))
val combineByKeyRDD = pairRDD.combineByKeyWithClassTag[(Int, Int)](
createCombiner, mergeValue, mergeCombiners,
new HashPartitioner(2), true, new JavaSerializer(sc.getConf))
combineByKeyRDD.collect()

