Spark流程与组件
参考文章链接:
前奏
分布式存储
在大数据时代,数据量大,这是一个很明显的特点,比如5PB的数据不好存储在单台机器上,那么分布式存储的出现就是给大数据场景提出的一套存储方案,它就是把大数据集打散成块,以块为单位存储在机器上,当然会有好多机器来进行存储,你可以这一群机器叫做存储集群,其中块的大小可以自己定义,比如256M,所以5PB的数据会划分成20977520块存储在多台机器上
当然这里会有一个问题,如果一台机器挂掉了,那存储在上面的块,就丢失了,那么就有些文件就不完整了,这个怎么解决了?
可以对每个数据块进行备份,冗余存储在多台机器上,就是同一数据块,复制多份,存储多态机器上,即使一台出现问题,那么还是可以从其他机器上获取备份数据,当然备份几份,有地方支持设置
所以分布式存储的特点:
- 数据分块存储在多台机器上
- 每一个数据块可以冗余存储在多台机器上,以提高数据块的高可用性
这里还有一个问题:就是数据都分块了,那怎么知道哪个块属于哪个文件?
这就要提到分布式存储集群架构模式了:主从结构(master/slave)
其中负责存储数据块具体内容的机器称为slave们,而在另外起一台机器负责管理所有slave和数据块,这台机器称为master,存在master上的文件,表示逻辑文件,它表示这个逻辑文件全路径名,与这个全路径对应的有数据块的存储信息(数据块位置等)
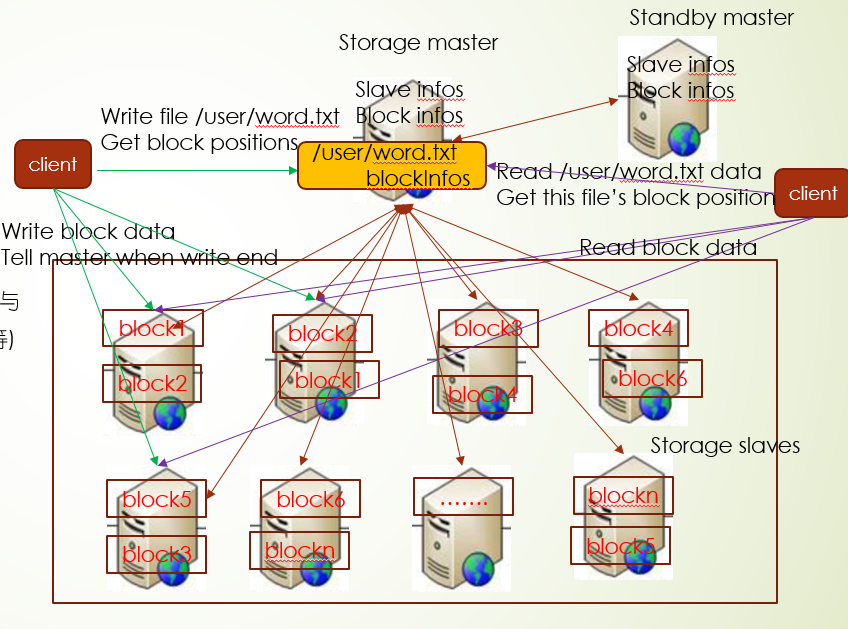
其中读写流程是这样的,客户端发起读写请求给master,master经一定计算,返回block的存储信息,客户端根据返回信息决定读哪些机器上信息或者写入到哪些机器上
其中HDFS就是实现分布式存储的,更多详细内容可以看文章头部文档
上面过程提到的操作

分布式计算
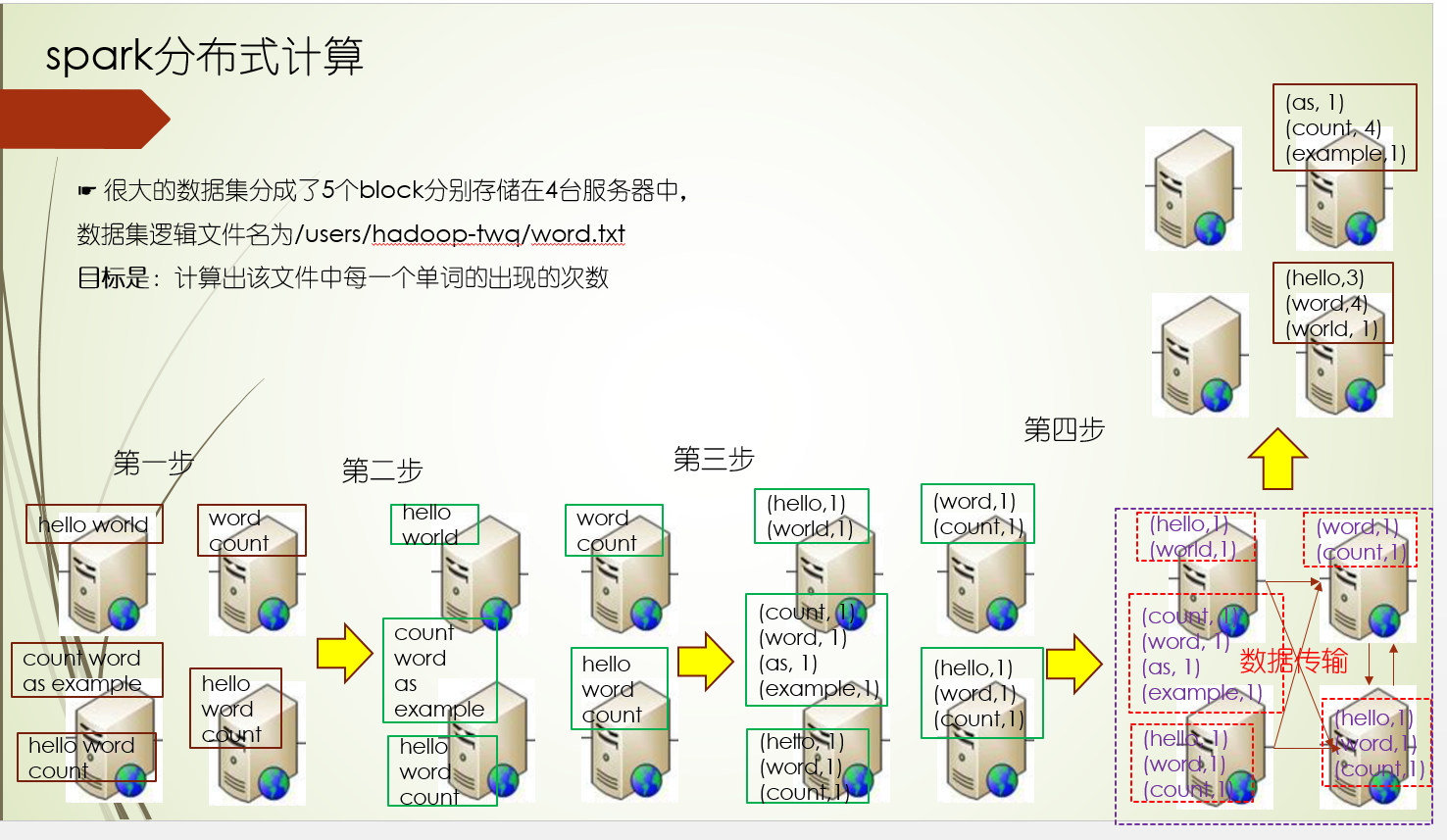
由于分布式存储是分块存储在多台机器上,那你会不会有这么一个疑问:比如我想对一个文件统计各个单词出现的次数?怎么计算的规则?是把所有的数据块拿到一台机器上,然后计算?还是先在数据块所在的机器进行初步的计算,然后把计算的结果汇集某台机器上进行计算呢?那么这里就涉及到一个分布式计算的问题
因为采用分布式存储,所以才会有分布式计算的问题
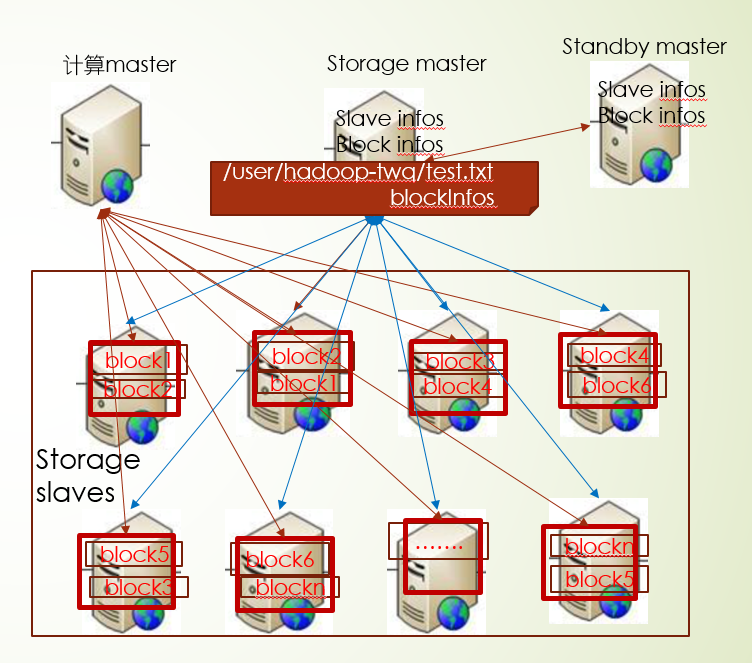
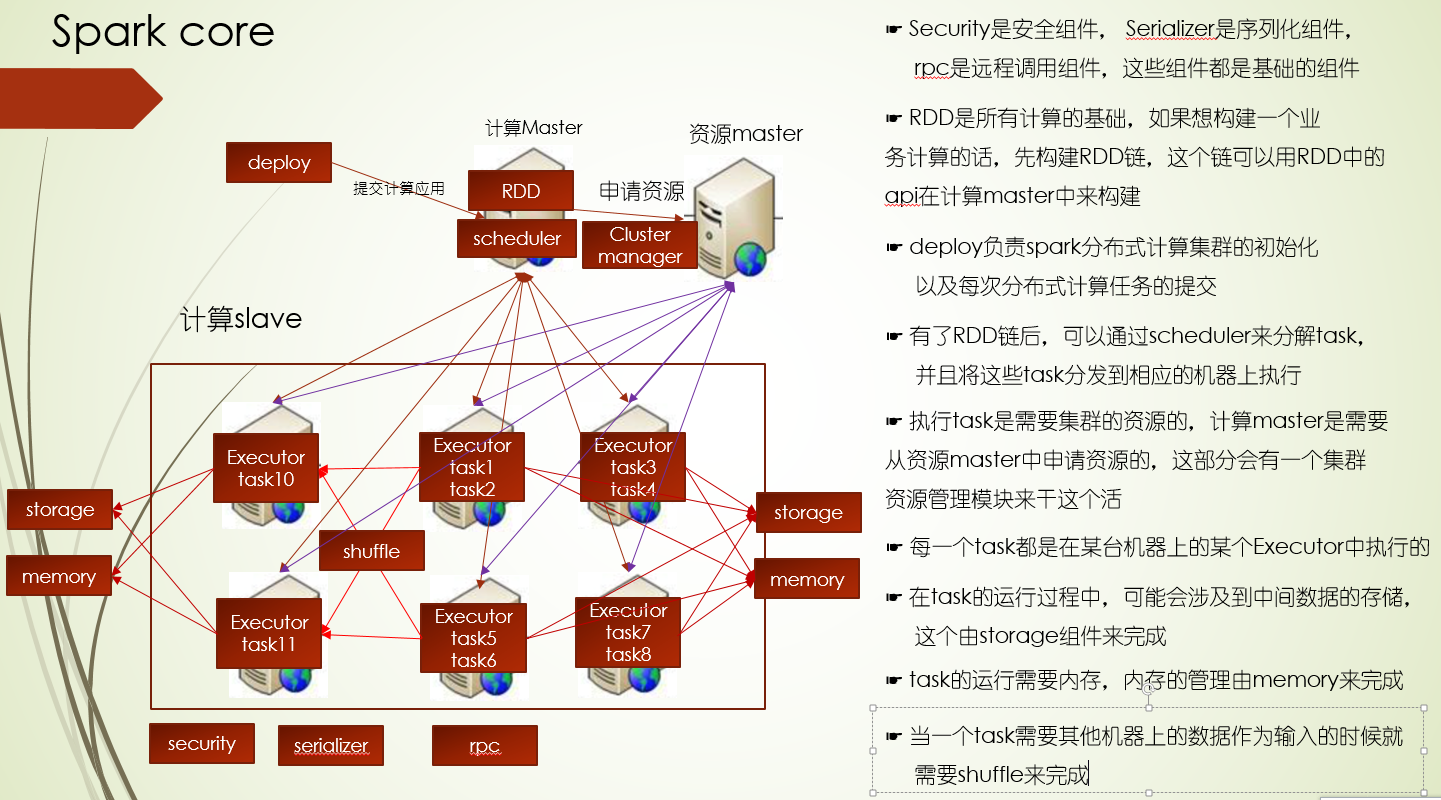
在原有的分布式存储架构上,会有一台机器担任起计算master的角色,主要指导各个数据块所在的机器进行计算,并汇总计算结果,所以分布式计算采用了多台机器并行计算的方式,并遵循移动计算而尽可能少的移动数据的原则
上面原则上尽可能少移动数据,当然还是存在需要移动数据进行计算的场景:比如当前机器计算资源(CPU,内存)不够,另外计算过程中Shuffle过程会移动数据,需要把每个数据块机器上计算的结果汇总某台机器,再进行计算
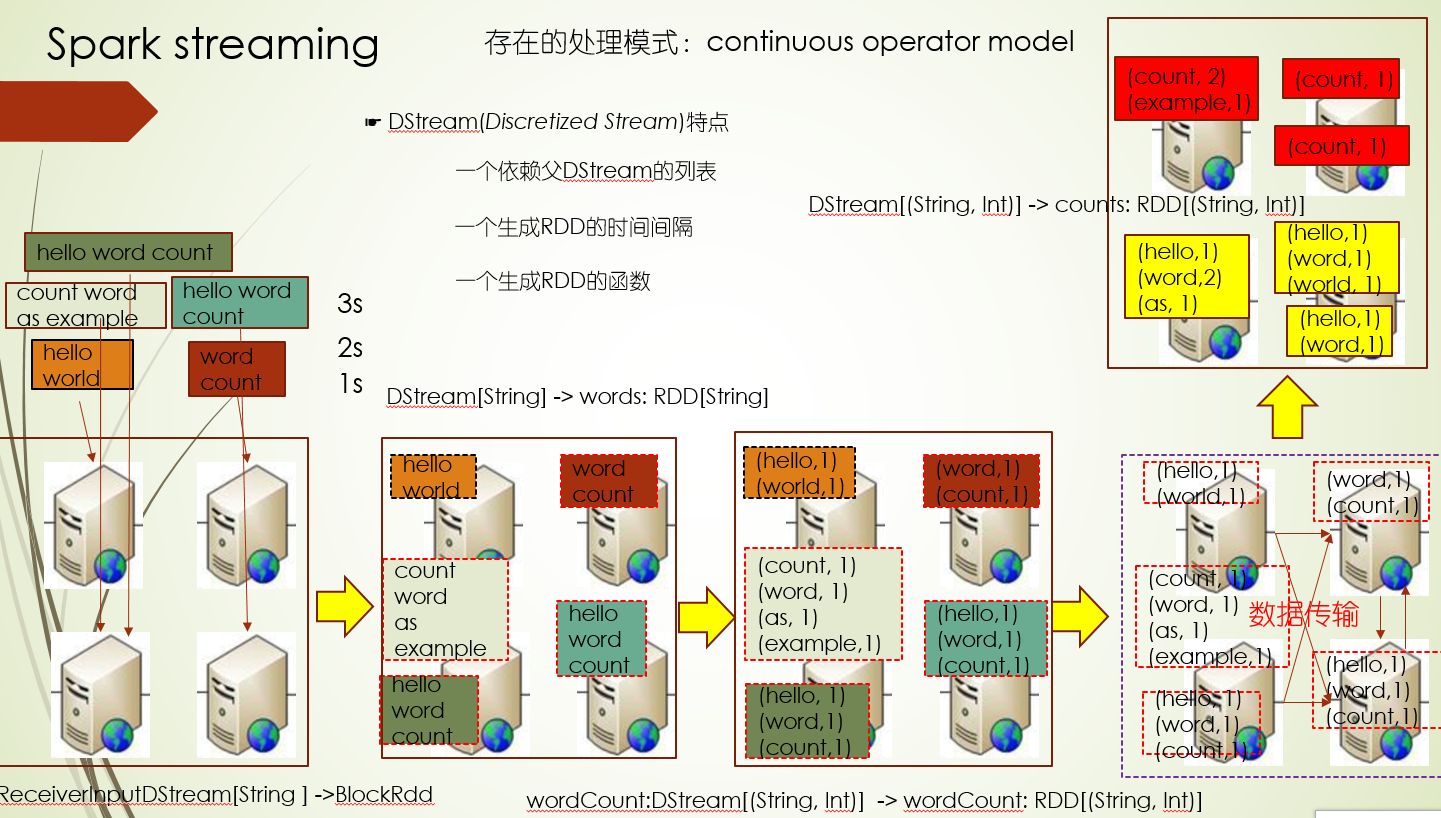
简单的WordCount程序
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("word count")
val sc = new SparkContext(conf)
val inputRdd: RDD[(LongWritable, Text)] =
sc.hadoopFile("hdfs://master:9999/users/hadoop-twq/word.txt",
classOf[TextInputFormat], classOf[LongWritable], classOf[Text])
val words: RDD[String] = inputRdd.flatMap(_._2.toString.split(" "))
val wordCount: RDD[(String, Int)] = words.map(word => (word, 1))
val counts: RDD[(String, Int)] = wordCount.reduceByKey(new HashPartitioner(2), (x, y) => x + y)
counts.saveAsTextFile("hdfs://master:9999/users/hadoop-twq/wordcount") }
sc.stop()
}
1.并行计算怎么进行的?
并行计算是按照分区进行的,比如1个文件分了5个数据块,那它就会对应5个分区,每个数据块就是一个分区的计算输入数据集,并且每个数据块的计算是独立并行计算的
而在Shuffle过程,也就是在对各个数据块计算结果汇总聚合的结果,需要按照相同的key聚合,可以根据数据特点进行重新分区,比如对key的hashcode对2取模,分两个区
2.每一步计算过程怎么理解?
每一步计算过程都会给定计算函数,对于每条数据都经过这个计算函数处理成指定格式的数据,处理的结果集可以做为下一步计算过程的输入,比如计算函数map把每个单词进行1次统计
val wordCount: RDD[(String, Int)] = words.map(word => (word, 1))
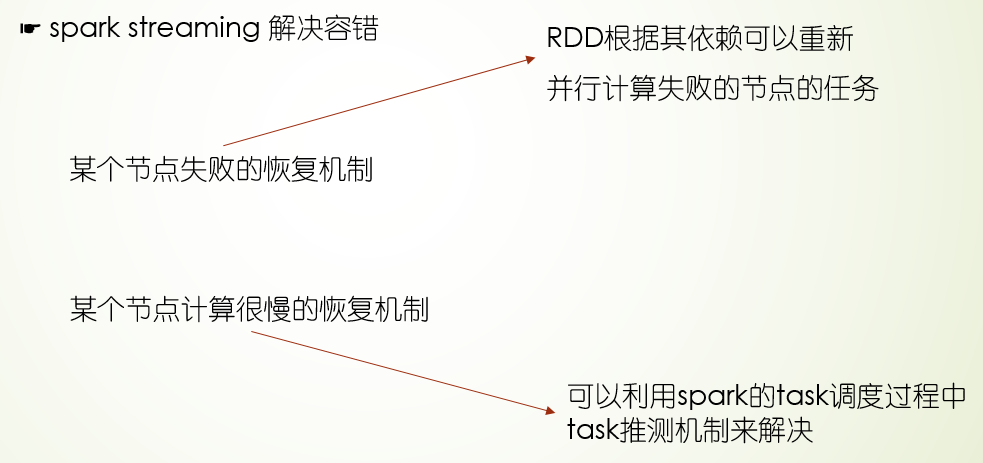
3.如果计算过程中,计算任务因为网络原因挂掉,怎么处理?
在spark分布式计算里,会为维持一个计算过程依赖链,比如在第四步计算过程,计算任务挂了,可以重新从其依赖的第一步和第二步以及第三步计算得出第四步的需要数据
4.数据的分区方式是怎么样的?
对于一开始的计算,也就是数据块的分区计算,一个数据块block就是一个分区,当然我们也可以设置成2个block一个分区,在Shuffle过程key-value数据分区,可以按照某个规则设置分区器,比如按照key的hash值来分区
5.在计算伊始读取分区数据的时候,会发生从其他机器节点通过网络传输读取数据吗 ?
可能会发生,但要尽量避免,每个数据块都包含各自的机器信息,我们要做的就是把计算任务发到对应机器上,让计算任务实现本地执行,又叫计算任务的本地性
6.每一步计算过程出现的数据都是一份存储吗?
不是,数据的存储只有一份,就是一开始的数据存储,在Shuffle的时候会有中间临时数据的存储
上面所有的这些实现细节,都基于Spark RDD来实现的

RDD Api实例
RDD的创建方式
方式一:从存储在存储系统中的数据上来创建,比如:
val inputRdd = sc.hadoopFile("hdfs://master:9999/user/hadoop-laoliu/hello.txt", classOf[TextInputFormat], classOf[LongWritable], classOf[Text])
这个就是从hdfs存储系统中的数据创建一个RDD
方式二: 可以基于一个已经存在的RDD来创建一个RDD,比如:
val words: RDD[String] = inputRdd.flatMap(_._2.toString.split(" ")) 就是从已经存在的inputRdd上创建一个新的RDD
方式三: 可以基于一个已经在spark内存中的列表数据来创建一个RDD,比如:
val words: RDD[Int] = sc. parallelize[Int](Seq(1,2,3,4,5,6,7,8,9))
Api实例
以下的实践都是基于spark-shell这个shell工具
import org.apache.spark.rdd.RDD
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
//表示从hdfs上读取文件word.txt中的数据,格式为text型,生成了一个
//org.apache.spark.rdd.RDD[(org.apache.hadoop.io.LongWritable, org.apache.hadoop.io.Text)],实际是HadoopRDD
val inputRdd = sc.hadoopFile("hdfs://master:9999/user/hadoop-laoliu/hello.txt", classOf[TextInputFormat], classOf[LongWritable], classOf[Text])
scala> inputRdd.partitions.size
res2: Int = 3
有两个分区
inputRdd.dependencies
res12: Seq[org.apache.spark.Dependency[_]] = List()
没有依赖,即没有父RDD
inputRdd.partitioner
res13: Option[org.apache.spark.Partitioner] = None
没有分区元数据
//将上面读取到的数据的每一行按照空格切割,生成一个新的RDD,类型为String,实际上是生成了MapPartitionsRDD
val words: RDD[String] = inputRdd.flatMap(_._2.toString.split(" "))
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:29
scala> words.partitions.size
res15: Int = 3
有两个分区
words.dependencies
res23: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@1a874ebf)
有一个一对一窄依赖
words.dependencies.map(_.rdd)
res18: Seq[org.apache.spark.rdd.RDD[_]] =
List(hdfs://master:9999/users/hadoop-twq/word.txt HadoopRDD[3] at hadoopFile at <console>:27)
其有一个依赖就是上面第一步产生的HadoopRDD
words.partitioner
res19: Option[org.apache.spark.Partitioner] = None
没有分区元数据
//将上面一步的RDD中的每一条记录转换成二元组,生成一个RDD[(String, Int)],实际上是生成了MapPartitionsRDD
val wordCount: RDD[(String, Int)] = words.map(word => (word, 1))
wordCount: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[6] at map at <console>:31
scala> wordCount.partitions.size
res20: Int = 3
有两个分区数
wordCount.dependencies
res24: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@c889c1f)
有一个一对一窄依赖
scala> wordCount.dependencies.map(_.rdd)
res21: Seq[org.apache.spark.rdd.RDD[_]] = List(MapPartitionsRDD[4] at flatMap at <console>:29)
有一个依赖父RDD,其实就是上面一步产生的MapPartitionsRDD
wordCount.partitioner
res22: Option[org.apache.spark.Partitioner] = None
仍然没有分区元数据
import org.apache.spark.HashPartitioner
//将上面的数据按照key进行统计,生成一个RDD[(String, Int)],实际上是ShuffledRDD
val counts: RDD[(String, Int)] = wordCount.reduceByKey(new HashPartitioner(1), (x, y) => x + y)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[7] at reduceByKey at <console>:34
scala> counts.partitions.size
res26: Int = 1
只有一个分区数
counts.dependencies
res27: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@8538bb8)
有一个宽依赖
counts.dependencies.map(_.rdd)
res28: Seq[org.apache.spark.rdd.RDD[_]] = List(MapPartitionsRDD[6] at map at <console>:31)
父亲rdd其实就是上一步的MapPartitionsRDD
scala> counts.partitioner
res29: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@1)
有一个分区器,按照key的hash值进行分区,分区数为1
//将结果保存在hdfs上
counts.saveAsTextFile("hdfs://master:9999/users/hadoop-twq/wordcount")
结果为:
(this,11100003)
(is,11100003)
(first,11100003)
(my,11100003)
(hdfs,11100003)
(file,11100003)
(test,11100003)
RDD Api计算的lazy特性

RDD 缓存Api
缓存api: persist() 和 cache() 清理缓存api : unpersist()
Spark基于内存分布式计算
什么是分布式内存?
这里分为两个层面:
- 第一个层面是集群层面的,就是集群计算资源的管理,其实道理和分布式存储是一样的,只不过分布式存储是管理整个集群所有slave的磁盘大小,那么分布式内存则是管理整个集群中每台机器的内存大小
- 第二个层面是app应用层面,就是计算master对单个应用的计算资源管理,每个应用先申请需要的计算资源,然后在申请到资源的节点上启动计算服务,这个服务同时负责对这个节点上申请到的资源进行管理,并且使用资源的时候要向计算master汇报
Spark的Shuffle过程是基于内存的?MapReduce是基于磁盘的?
不是的,MapReduce是基于磁盘的,没错,但是spark不完全是基于内存的,spark的Shuffle中间结果也是需要写文件的,只是对内存的利用比较充分而已
所以Spark非常适用存在大量的中间结果数据复用场景,因为中间结果数据可以存储在分布式内存中,而且spark支持了api让你进行调用,并存储到分布式内存里
☛ spark调用RDD中的rdd.persist(StorageLevel.MEMORY_ONLY) 方法来缓存这个中间rdd结果数据
val points = spark.textFile(...).map(parsePoint).persist()
var w = // random initial vector
for (i <- 1 to ITERATIONS) {
val gradient = points.map{ p =>
p.x * (1/(1+exp(-p.y*(w dot p.x)))-1)*p.y
}.reduce((a,b) => a+b)
w -= gradient
}
spark适用场景:
- 迭代式计算应用
- 交互型数据挖掘应用
各个框架对中间结果复用的处理:
1: MapReduce以及Dryad等 将中间结果写到分布式文件系统中,需磁盘IO 2: Pregel和HaLoop等 将一些特定的中间结果数据隐式的存储在分布式内存中 3: spark可以将任何类型的中间结果数据显示的调用api存储在分布式内存中
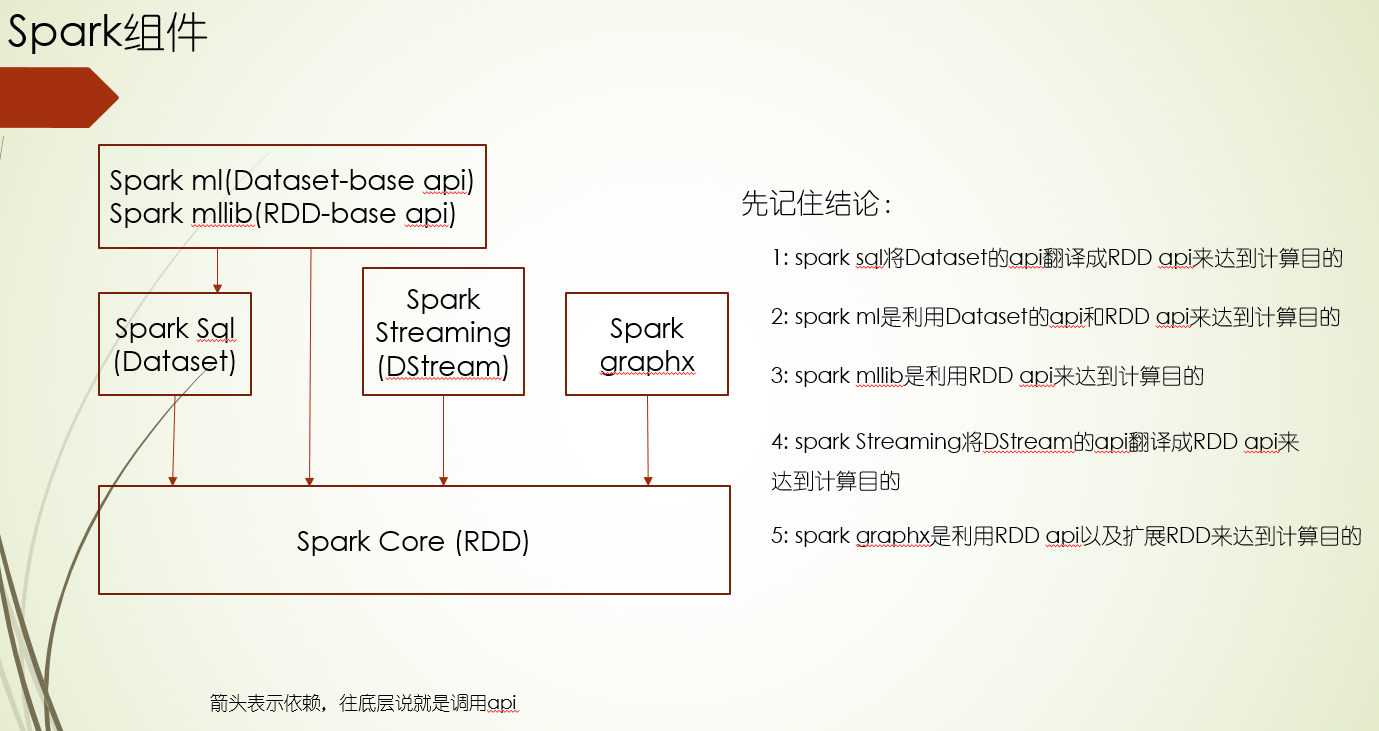
Spark组件
Spark core

Spark sql




Spark streaming