
Spark环境搭建
开始之前,你需要先确认本地环境是否安装过Hadoop环境,因为Spark依赖Hadoop环境
怎么在本地安装Hadoop环境,后续更新TODO
新建第一个Spark Maven项目
File -> New Project -> Maven
新建好后,在src/main下新建scala目录,并点击下面图标配置,配置scala
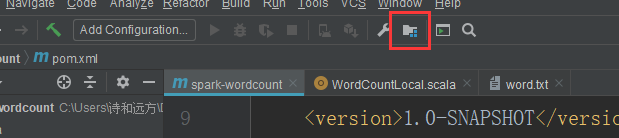
- 把scala目录置成Sources,版本改成8
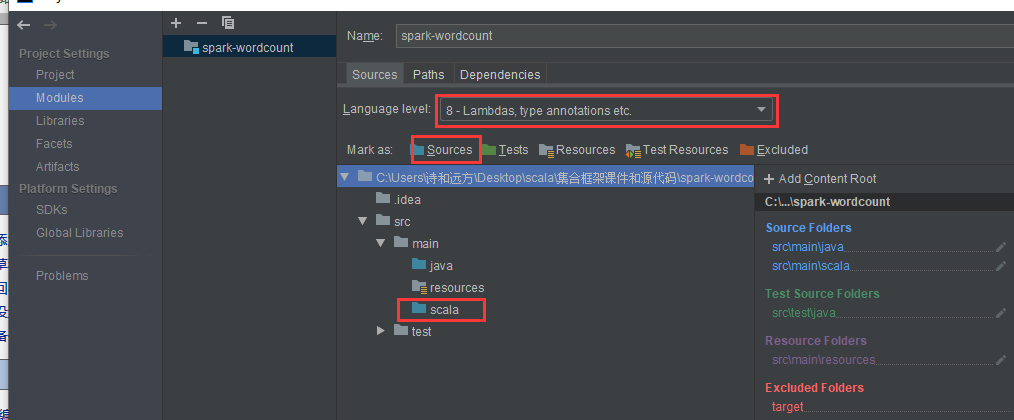
- 在Dependencies中,把安装scala sdk依赖进来,如果这里没有,需要通过右边的 + 号添加进来
- 在pom文件中添加spark依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
到此,相关依赖的都弄好,就可以开始你的spark开发了
package com.laoliu
import org.apache.spark.{SparkConf, SparkContext}
object WordCountLocal {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCount")
conf.setMaster("local")
val sparkContent = new SparkContext(conf)
val textFileRDD = sparkContent.textFile("src/main/resources/word.txt")
val wordRDD = textFileRDD.flatMap(_ split " ")
val pairWordRDD = wordRDD.map((_ -> 1))
val wordCountRDD = pairWordRDD.reduceByKey(_ + _)
wordCountRDD.saveAsTextFile("src/main/resources/wordcount")
}
}
Spark源码环境搭建
由于spark的源码放在GitHub上,使用前,需要先在本地安装git
安装好后,进行clone项目
git clone https://github.com/apache/spark.git
在idea设置你git的安装路径
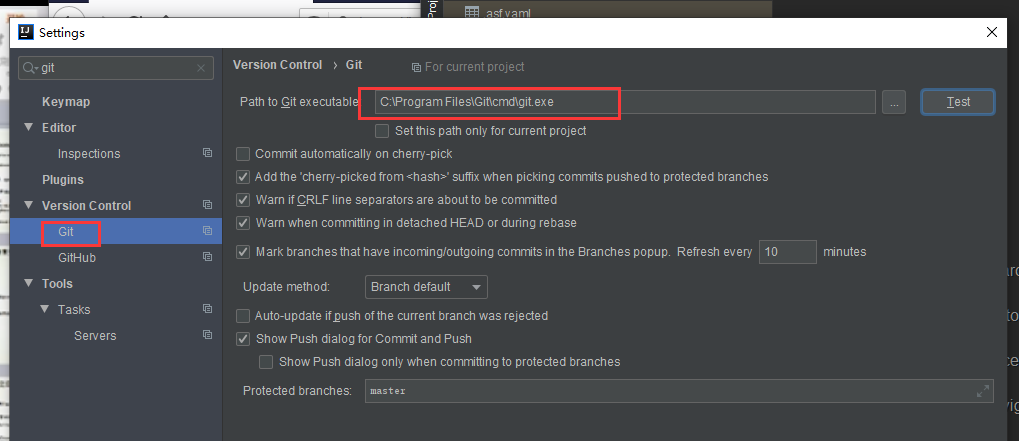
然后open git clone下来的项目,进行导入,刚开始需要下载maven库,需要一定的时间,完成后,我们就可以通过idea来查看spark的源码啦
Spark集群环境搭建(虚拟机上)
1.scala安装
下载 http://www.scala-lang.org/download/2.11.8.html 版本为2.11.8(scala-2.11.8.tgz) 上传:上传到master虚拟机上的目录/usr/local/lib/中(可以用FileZilla等ftp工具上传) 用root用户解压: tar -xvf scala-2.11.8.tgz 在root用户下,将解压后的JDK目录拷贝到slave1和slave2: scp -r scala-2.11.8 root@slave1:/usr/local/lib scp -r scala-2.11.8 root@slave2:/usr/local/lib 分别在三台虚拟机上切换到hadoop-twq用户修改环境变量: vi ~/.bash_profile export SCALA_HOME=/usr/local/lib/scala-2.11.8 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin source ~/.bash_profile which scala查看scala的安装目录是不是我们想要的 测试是否安装成功: scala
2.安装spark
下载 http://spark.apache.org/downloads.html Spark2.2 需要的环境: Java 8+, Scala 2.11.X 上传:上传到master机器节点的目录~/bigdata下(可以用FileZilla等ftp工具上传) 需要预先在每一个节点中的hadoop-laoliu用户下的根目录下创建bigdata目录 解压 tar -xf spark-2.2.0-bin-hadoop2.7.tgz 配置slaves cd spark-2.2.0-bin-hadoop2.7/conf cp slaves.template slaves vi slaves,写入如下内容 slave1 slave2 配置spark-env.sh cp spark-env.sh.template spark-env.sh vi spark-env.sh写入如下内容 export JAVA_HOME=/usr/local/lib/jdk1.8.0_151
● 将配置好的spark拷贝到slave1和slave2节点上: scp -r ~/bigdata/spark-2.2.0-bin-hadoop2.7 hadoop-laoliu@slave1:~/bigdata scp -r ~/bigdata/spark-2.2.0-bin-hadoop2.7 hadoop-laoliu@slave2:~/bigdata ● 在master上配置环境变量: cd ~ vi ~/.bash_profile export SPARK_HOME=~/bigdata/spark-2.2.0-bin-hadoop2.7 source ~/.bash_profile ● 启动 sh ~/bigdata/spark-2.2.0-bin-hadoop2.7/sbin/start-all.sh http://master:8080/ 查看是否成功 ● 使用spark-shell --master spark://master:7077测试spark代码
3.在spark集群运行WordCount程序
我们拿着上面的在本地运行的程序简单改改,就可以在spark集群运行了
package com.laoliu
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCount")
val sparkContent = new SparkContext(conf)
val textFileRDD = sparkContent.textFile("hdfs://master:9999/user/hadoop-laoliu/word.txt")
val wordRDD = textFileRDD.flatMap(_ split " ")
val pairWordRDD = wordRDD.map((_ -> 1))
val wordCountRDD = pairWordRDD.reduceByKey(_ + _)
wordCountRDD.saveAsTextFile("hdfs://master:9999/user/hadoop-laoliu/wordcount")
}
}
并且我们需要进行打包,并上传到spark集群上执行,maven需要配置打包插件,这里需要注意的是:项目和配置的路径都尽量不要用中文
打包好的jar上传到spark集群,并且要把hdfs集群起起来start-dfs.sh
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<testExcludes>
<testExclude>/src/test/**</testExclude>
</testExcludes>
<encoding>utf-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.6</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
通过下面命令执行程序
执行前先清理输出路径 hadoop fs -rm -r hdfs://master:9999/user/hadoop-laoliu/wordcount 使用spark-submit提交任务 spark-submit \ --class com.laoliu.WordCount \ --master spark://master:7077 \ --deploy-mode client \ --driver-memory 1g \ --executor-memory 1g \ --num-executors 2 \ spark-wordcount-1.0-SNAPSHOT.jar
当然在spark集群也能在本地进行运行,master指定local,如果不指定,默认就是本地运行
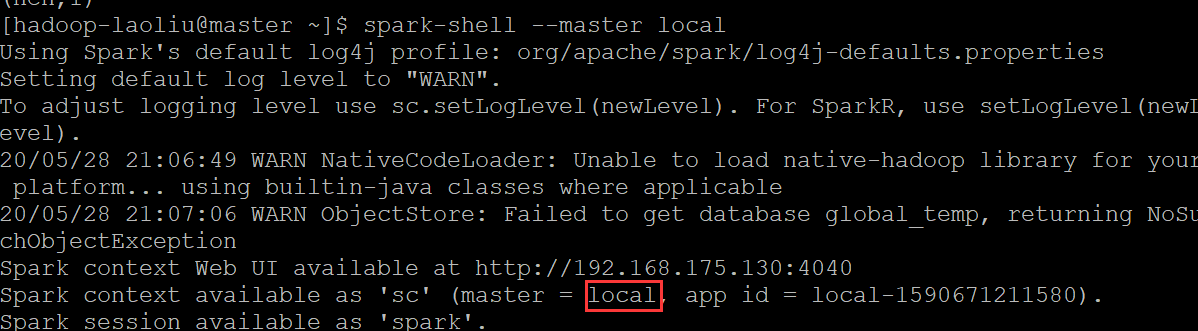
另外,我们发现spark程序运行时,会打印 很多日志,在程序里,我们也会加上我们的日志,那怎么程序打印的日志关掉,更好的关注自己的日志呢?
那么这里我们需要一个配置文件放在我们的运行程序里,配置文件可以从 spark的安装目录下获取spark-2.2.0-bin-hadoop2.7/conf/log4j.properties.template,把这个文件下下来,放在我们程序中
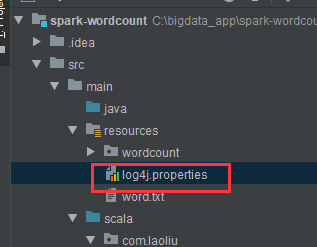
然后在这个 文件里进行如下修改,表示只会打印程序的error级别日志和我们的打印输出
log4j.rootCategory=ERROR, console
那么上面是对本地程序,spark集群上也是同样的道理,你可以把log4j.properties.template复制一份,去掉template,并按照上面修改
mysql安装
spark开发肯定要和数据库打交道,所以 我们需要安装下mysql
Mysql的安装(用root账号安装) yum install mysql-server -y, 如果报截图中的错,则执行下面两个命令: wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm rpm -ivh mysql-community-release-el7-5.noarch.rpm 然后再执行yum install mysql-server -y 启动mysql service mysqld start 验证 mysql -uroot -p 输入密码,进入到mysql 并执行以下语句(使得客户端可以以root账号连上mysql服务): 允许我们后面开发 spark程序可以通过root连接操作数据库 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; flush privileges;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号