Union-Find算法详解
Union-Find 算法,也就是常说的并查集算法,主要是解决图论中「动态连通性」问题的。
什么是动态连通性?

对于一幅图中,各个节点是否是相连的?如果不相连,就把他们连起来。涉及到几个操作:
union:连接节点p和节点q
find:查找节点p的父节点
connected:判断节点p和节点q是否是相连的
count:返回图中有多少个相连的树(连通分量)
主要API
class UF {
/* 将 p 和 q 连接 */
public void union(int p, int q);
/* 判断 p 和 q 是否连通 */
public boolean connected(int p, int q);
/* 返回图中有多少个连通分量 */
public int count();
}
连通的性质
1、自反性:节点p和p是连通的。
2、对称性:如果节点p和q连通,那么q和p也连通。
3、传递性:如果节点p和q连通,q和r连通,那么p和r也连通。
比如说之前那幅图,0~9 任意两个不同的点都不连通,调用connected都会返回 false,连通分量为 10 个。
如果现在调用union(0, 1),那么 0 和 1 被连通,连通分量降为 9 个。
再调用union(1, 2),这时 0,1,2 都被连通,调用connected(0, 2)也会返回 true,连通分量变为 8 个。

判断这种连通性关系有什么用呢?
比如说编译器判断同一个变量的不同引用,比如社交网络中的朋友圈计算等等。比如JVM中,利用可达性分析算法标记存活的变量。
Union-Find 算法的关键就在于union和connected函数的效率。那么用什么模型来表示这幅图的连通状态呢?用什么数据结构来实现代码呢?
基本思路
我们从数据结构和算法实现两个方面来讲一下并查集的实现方式。
我们用森林(若干棵树)来表示图的动态连通性,用数组来具体实现这个森林。
怎么用森林来表示连通性呢?
我们设定树的每个节点有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。比如说刚才那幅 10 个节点的图,一开始的时候没有相互连通,就是这样:
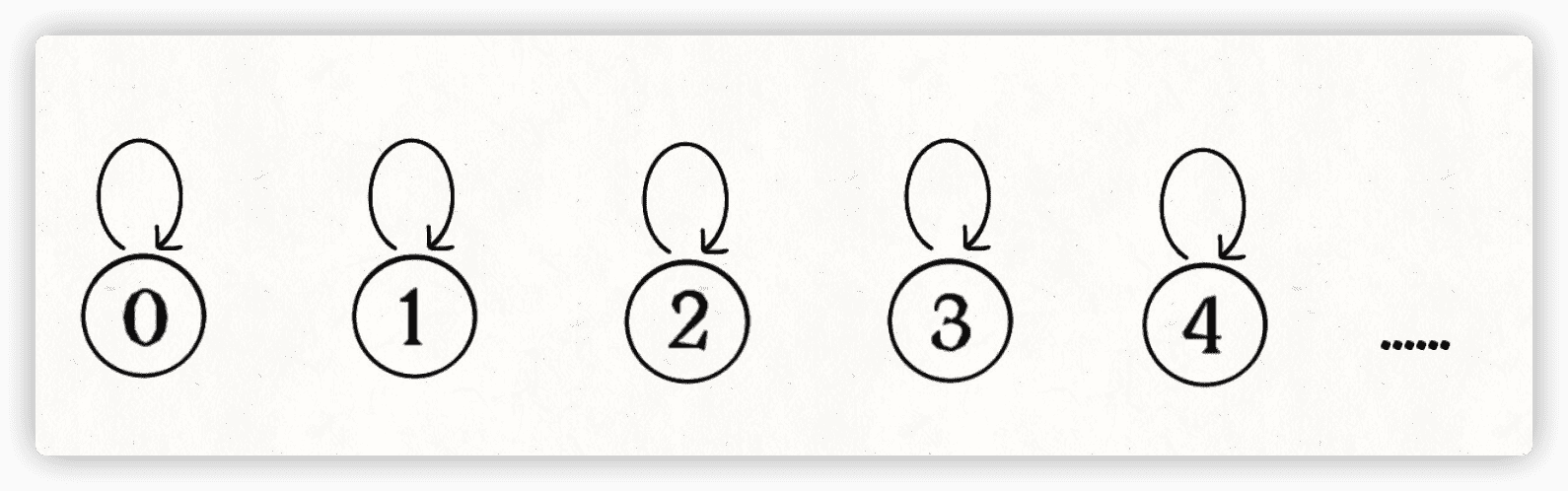
class UF {
// 记录连通分量
private int count;
// 节点 x 的节点是 parent[x]
private int[] parent;
/* 构造函数,n 为图的节点总数 */
public UF(int n) {
// 一开始互不连通
this.count = n;
// 父节点指针初始指向自己
parent = new int[n];
for (int i = 0; i < n; i++)
parent[i] = i;
}
/* 其他函数 */
}
如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上:
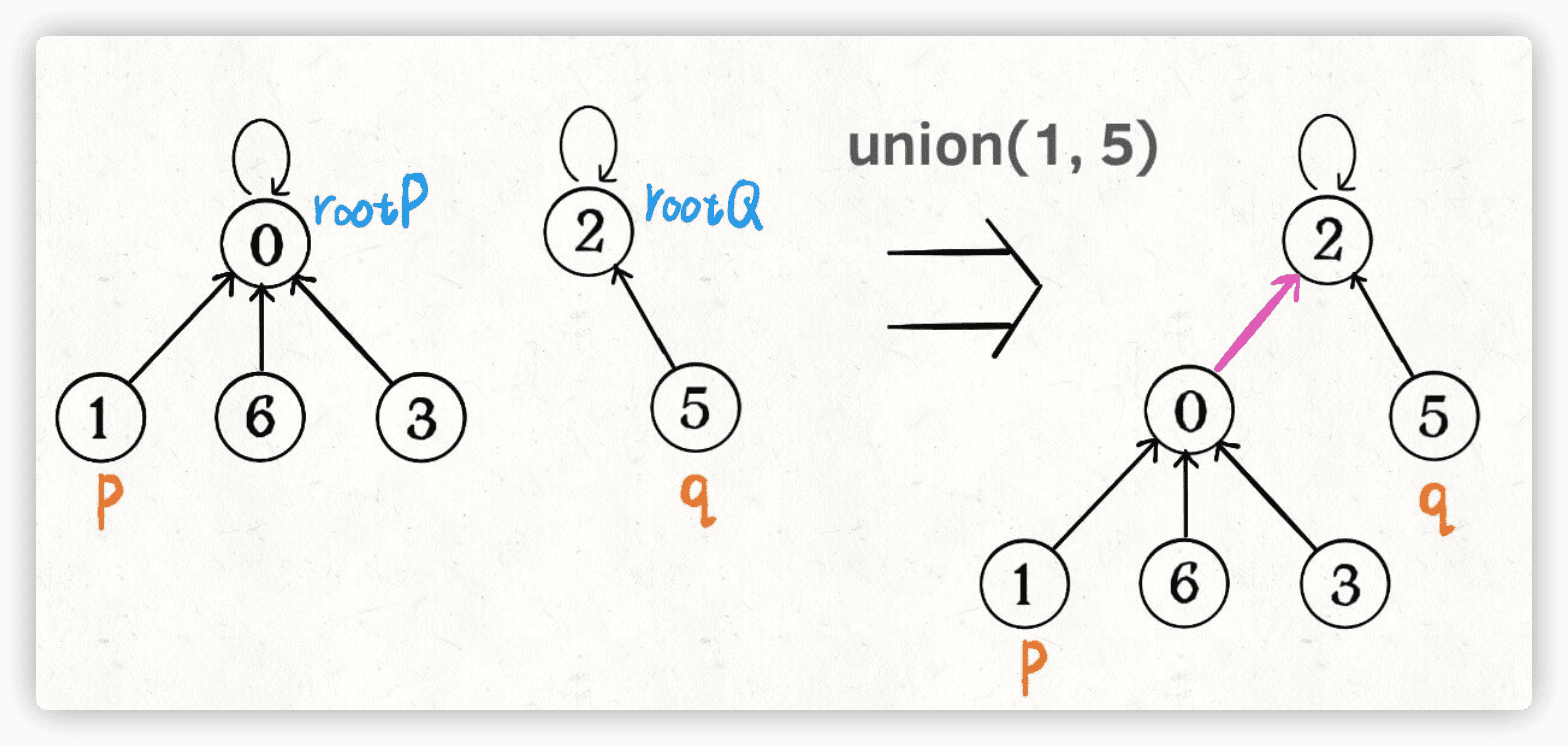
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 将两棵树合并为一棵
parent[rootP] = rootQ;
// parent[rootQ] = rootP 也一样
count--; // 两个分量合二为一
}
/* 返回某个节点 x 的根节点 */
private int find(int x) {
// 根节点的 parent[x] == x
while (parent[x] != x)
x = parent[x];
return x;
}
/* 返回当前的连通分量个数 */
public int count() {
return count;
}
这样,如果节点p和q连通的话,它们一定拥有相同的根节点:
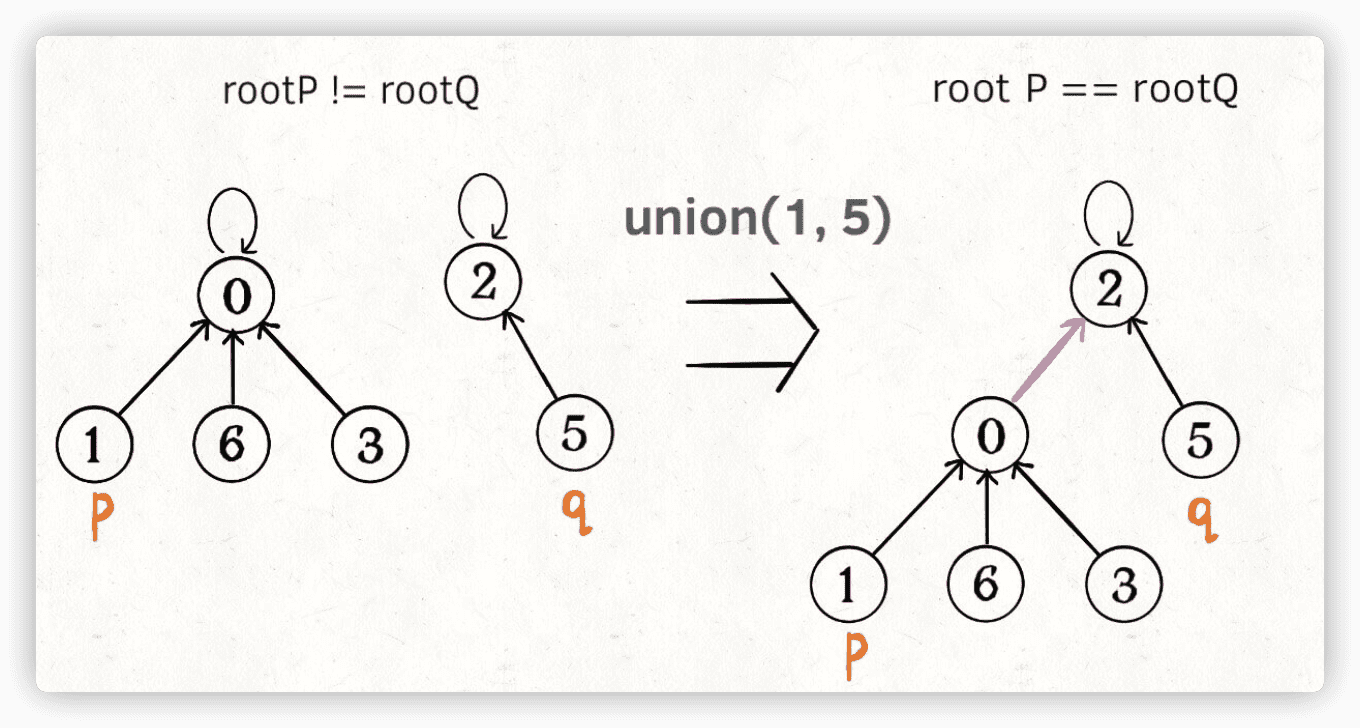
public boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
至此,Union-Find 算法就基本完成了。
那么这个算法的复杂度是多少呢?我们发现,主要 APIconnected和union中的复杂度都是find函数造成的,所以说它们的复杂度和find一样。
find主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是logN,但这并不一定。logN的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得「树」几乎退化成「链表」,树的高度最坏情况下可能变成N。
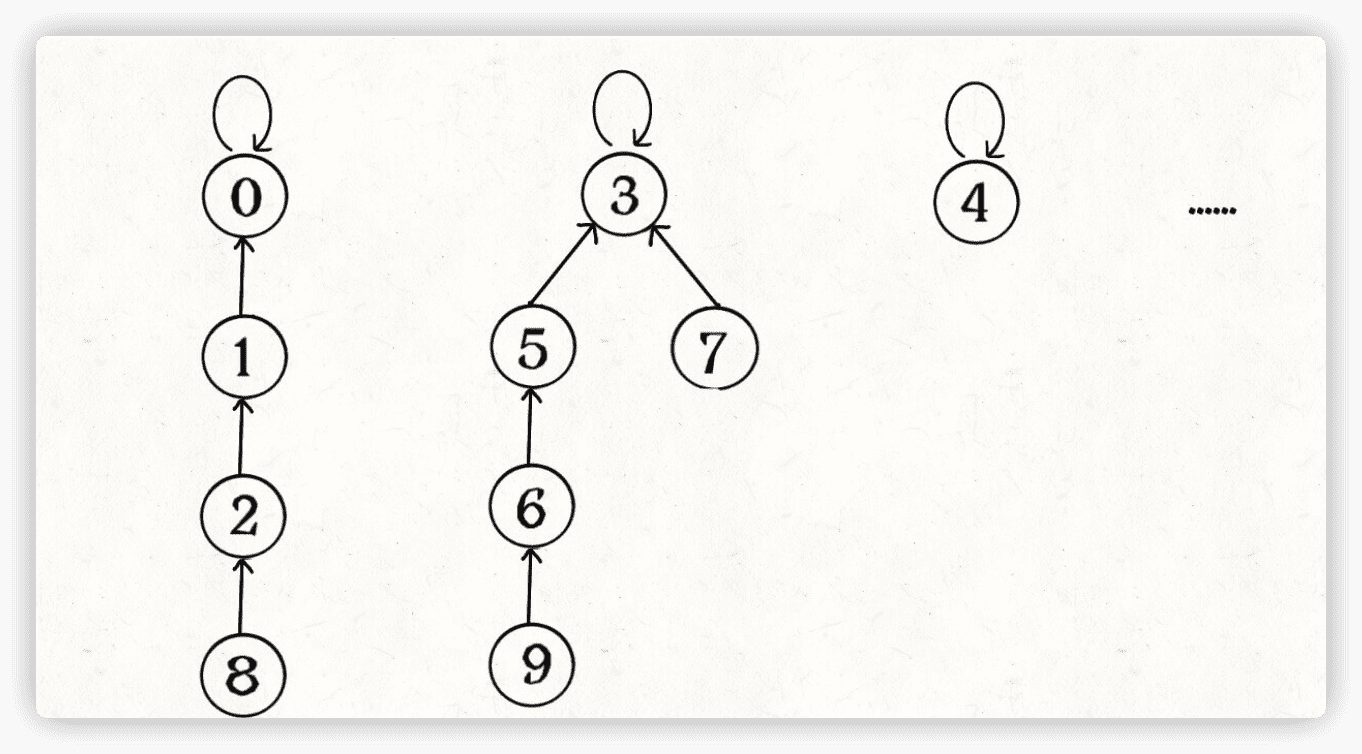
所以说上面这种解法,find,union,connected的时间复杂度都是 O(N)。这个复杂度很不理想的,你想图论解决的都是诸如社交网络这样数据规模巨大的问题,对于union和connected的调用非常频繁,每次调用需要线性时间完全不可忍受。
问题的关键在于,如何想办法避免树的不平衡呢?只需要略施小计即可。
平衡性优化
我们要知道哪种情况下可能出现不平衡现象,关键在于union过程:
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 将两棵树合并为一棵
parent[rootP] = rootQ;
// parent[rootQ] = rootP 也可以
count--;
我们一开始就是简单粗暴的把p所在的树接到q所在的树的根节点下面,那么这里就可能出现「头重脚轻」的不平衡状况,比如下面这种局面:
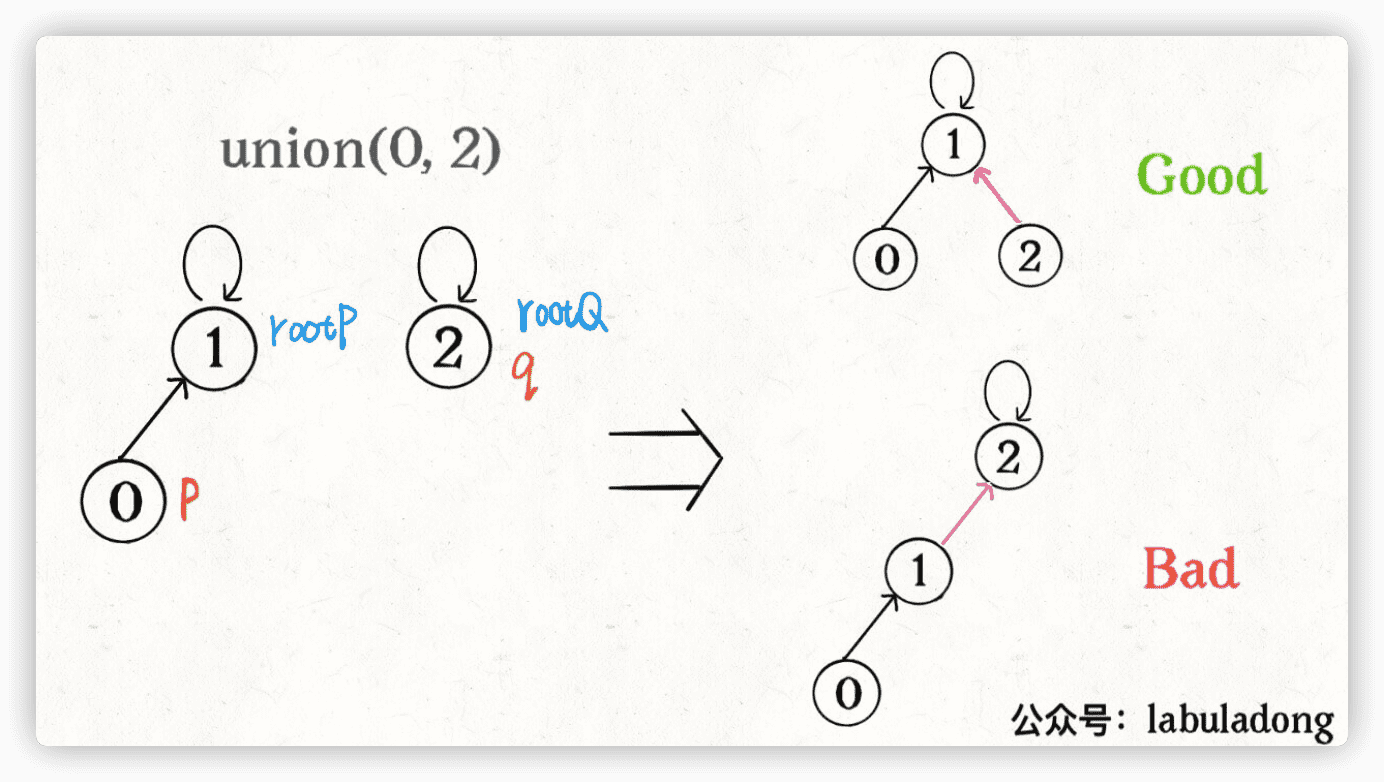
长此以往,树可能生长得很不平衡。我们其实是希望,小一些的树接到大一些的树下面,这样就能避免头重脚轻,更平衡一些。解决方法是额外使用一个size数组,记录每棵树包含的节点数,我们不妨称为「重量」:
class UF {
private int count;
private int[] parent;
// 新增一个数组记录树的“重量”
private int[] size;
public UF(int n) {
this.count = n;
parent = new int[n];
// 最初每棵树只有一个节点
// 重量应该初始化 1
size = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
size[i] = 1;
}
}
/* 其他函数 */
}
比如说size[3] = 5表示,以节点3为根的那棵树,总共有5个节点。这样我们可以修改一下union方法:
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 小树接到大树下面,较平衡
if (size[rootP] > size[rootQ]) {
parent[rootQ] = rootP;
size[rootP] += size[rootQ];
} else {
parent[rootP] = rootQ;
size[rootQ] += size[rootP];
}
count--;
}
这样,通过比较树的重量,就可以保证树的生长相对平衡,树的高度大致在logN这个数量级,极大提升执行效率。
此时,find,union,connected的时间复杂度都下降为 O(logN),即便数据规模上亿,所需时间也非常少。
路径压缩
这步优化特别简单,所以非常巧妙。我们能不能进一步压缩每棵树的高度,使树高始终保持为常数?
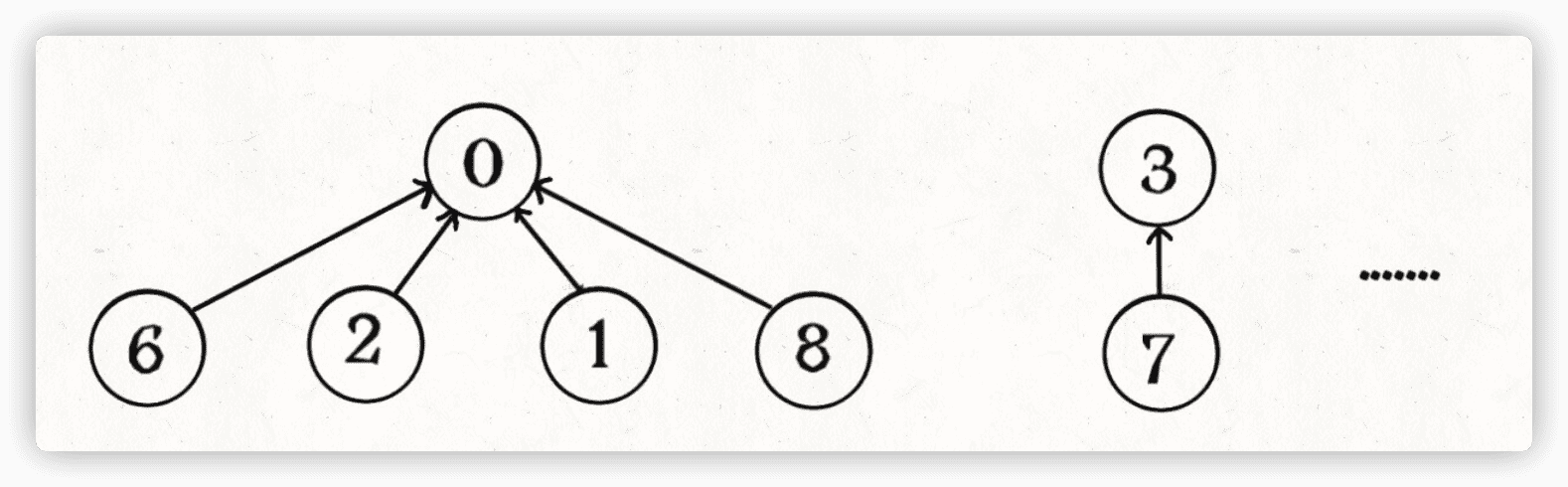
这样find就能以 O(1) 的时间找到某一节点的根节点,相应的,connected和union复杂度都下降为 O(1)。
要做到这一点,非常简单,只需要在find中加一行代码:
private int find(int x) {
while (parent[x] != x) {
// 进行路径压缩
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
调用find函数每次向树根遍历的同时,顺手将树高缩短了,最终所有树高都不会超过 3(union的时候树高可能达到 3)。
最后总结
我们先来看一下完整代码:
class UF {
// 连通分量个数
private int count;
// 存储一棵树
private int[] parent;
// 记录树的“重量”
private int[] size;
public UF(int n) {
this.count = n;
parent = new int[n];
size = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
size[i] = 1;
}
}
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 小树接到大树下面,较平衡
if (size[rootP] > size[rootQ]) {
parent[rootQ] = rootP;
size[rootP] += size[rootQ];
} else {
parent[rootP] = rootQ;
size[rootQ] += size[rootP];
}
count--;
}
public boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
private int find(int x) {
while (parent[x] != x) {
// 进行路径压缩
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
public int count() {
return count;
}
}
Union-Find 算法的复杂度可以这样分析:构造函数初始化数据结构需要 O(N) 的时间和空间复杂度;连通两个节点union、判断两个节点的连通性connected、计算连通分量count所需的时间复杂度均为 O(1)。
作者: 元宝爸爸
出处:https://www.cnblogs.com/wozixiaoyao/p/11965398.html
版权:本文采用「署名-非商业性使用-相同方式共享 4.0 国际」知识共享许可协议进行许可。
觉得文章不错,点个关注呗!
