大型网站技术架构,6网站的伸缩性架构之分布式缓存集群的伸缩性设计
和所有服务器都部署相同应用的应用服务器集群不同,分布式缓存服务器集群中不同的服务器中缓存的数据各不相同,缓存访问请求不可以在缓存服务器集群中的任意一台处理,必须先找到缓存有需要数据的服务器,然后才能访问。
这个特点制约了分布式缓存集群的伸缩性设计,因为新上线的缓存服务器没有缓存任何数据,而已下线的缓存服务器还缓存这网站的许多热点数据。
必须让新上线的缓存服务器对整个分布式缓存集群影响最小,也就是说新加入的缓存服务器应使整个缓存服务器集群中已经缓存的数据尽可能还被访问到,这是分布式缓存集群伸缩性设计的最主要目标。
6.3.1 Memcached分布式缓存集群的访问模型
以Memcached为代表的分布式缓存,访问模型如下图所示:
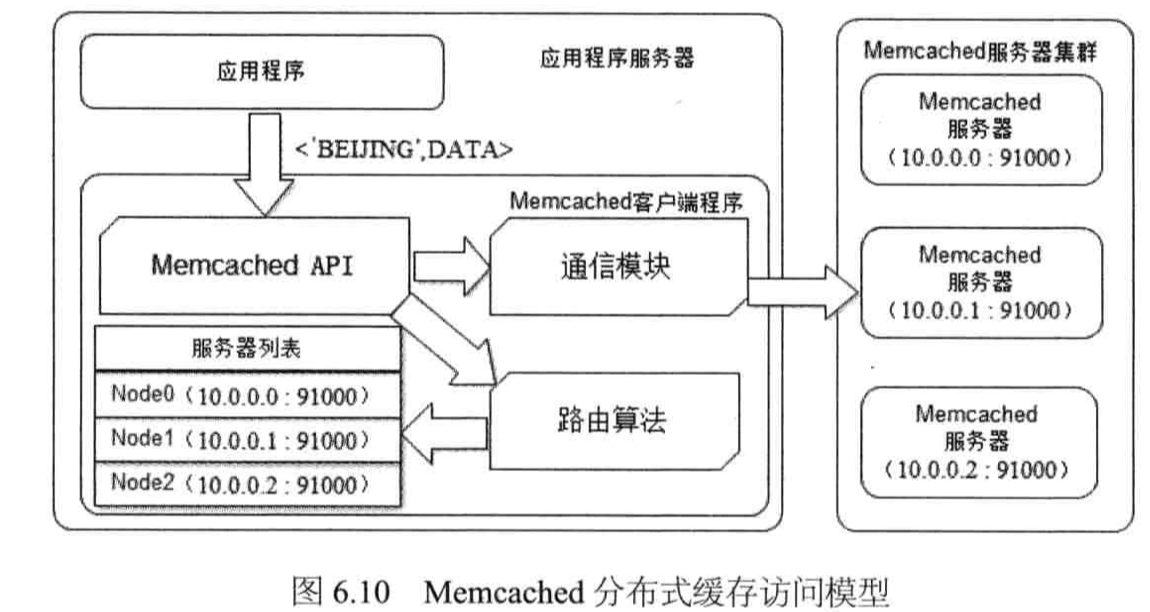
应用程序通过Memcached客户端访问Memcached服务器集群,
Memcached客户端由一组API、Memcached服务器集群路由算法、Memcached服务器集群列表及通信模块构成。
其中路由算法负责根据应用程序输入的缓存KEY计算得到应该将数据写入到Memcache的哪台服务器(写缓存)或者应该从哪台服务器读数据(读缓存)。
缓存写入流程:
缓存读取流程:
6.3.2 Memcached分布式缓存集群的伸缩性挑战
余数Hash:用服务器数据除以缓存数据Key的Hash值,余数为服务器列表下标编号。
由于HashCode具有随机性,因此使用余数Hash路由算法可以保证缓存数据在整个Memcached服务器集群中比较均衡地分布。
如果不考虑缓存服务器集群伸缩性,可以满足绝大多数地缓存路由需求。
但是,当分布式缓存集群需要扩容的时候,事情就变得棘手了。
扩容的时候,集群规模越大,不能命中的概率越高。当100台服务器的集群中加入一台新服务器,不能命中的概率使99%(N/(N+1))。
而网站业务中的大部分读操作是通过缓存获取的,数据库的负载能力是以有缓存为前提而设计的。当大部分被缓存的数据不能正确读取时,会导致数据库压力猛增,甚至宕机(而这个情况宕机,还无法通过简单的重启数据库解决,网站需要较长时间才能逐渐恢复正常,详见第13章。)
6.3.3 分布式缓存的一致性Hash算法
一致性Hash算法通过一个叫作一致性Hash环的数据结构实现KEY到缓存服务器的Hash映射,如下图所示:
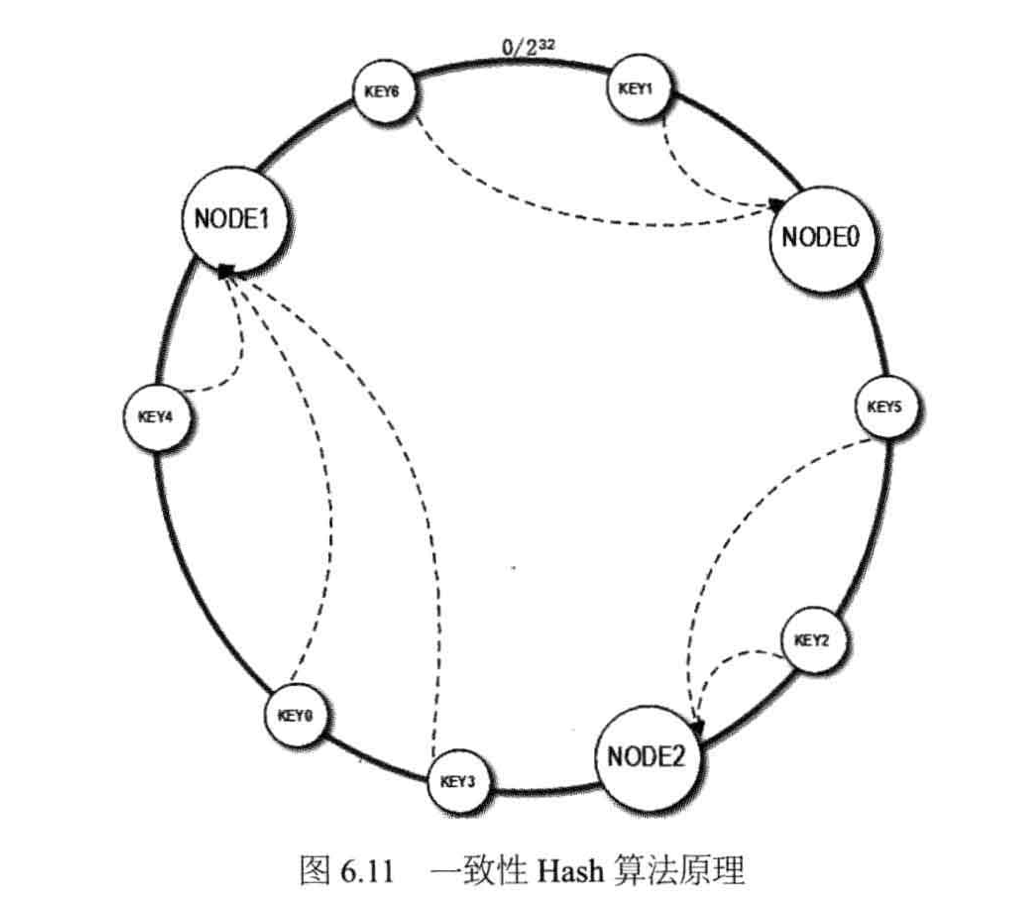
具体算法过程:
先构造一个长度为2^32的整数Hash环,根据节点名称的Hash值(其分布范围同样为0~2^32-1)将缓存服务器节点放置在这个Hash环上。
然后根据需要缓存的数据的KEY的Hash值取余2^32,得到0~2^32-1这个范围之间的一个整数值,然后在Hash环上顺时针查找距离这个KEY的hash值最近的缓存服务器节点。
当缓存服务器集群需要扩容的时候,只需要将新加入的节点名称(NODE3)的Hash值放入一致性Hash环中,由于KEY是顺时针查找距离其最近的节点,因此新加入的节点只影响整个环中的一小段。
具体应用中,这个长度为2^32的一致性Hash环通常使用二叉查找树实现,Hash查找过程实际上是在二叉查找树中查找不小于查找数的最小数值。当然这个二叉查找树的最右边叶子节点和最左边的叶子节点相连接,构成环。
hash倾斜
上面的一致性Hash算法存在hash倾斜的问题,即当服务器节点在环中不均匀的位置上时,位置是倾斜的,服务器节点集中的较近,环的大部分圆弧上没有被映射到服务器节点。
这种情况大部分的缓存对象会落到其中某台服务器上,导致缓存分布不均匀。由于缓存较多的服务器压力较大,易发生故障,一旦宕机,失效的缓存太多,大部分缓存请求又会落到其下一个节点,极端情况会导致系统崩溃。
计算机的任何问题都可以通过增加一个虚拟层来解决。计算机网络的7层协议,每层都可以看作是下一层的虚拟层;计算机操作系统可以看作是计算机硬件的虚拟层;Java虚拟机可以看作是操作系统的虚拟层;分层的计算机软件架构事实上也是利用虚拟层的概念。
解决一致性Hash算法带来的负载不均的问题,也可以使用虚拟层的手段:
将每台物理缓存服务器虚拟为一组虚拟缓存服务器,将虚拟服务器的hash值放置在hash环上,key在环上先找到虚拟服务器节点,再得到物理服务器的信息。
新加入物理服务器节点时,是将一组虚拟节点加入环中,如果虚拟节点的数目足够多,这组虚拟节点将会影响同样多数目的已经在环上存在的虚拟节点,这些已经存在的虚拟节点又对应不同的物理节点。最终的结果是:新加入一台缓存服务器,将会较均匀地影响原来集群中已经存在的所有服务器,也就是说分摊原有缓存服务器集群中所有服务器地一小部分负载。
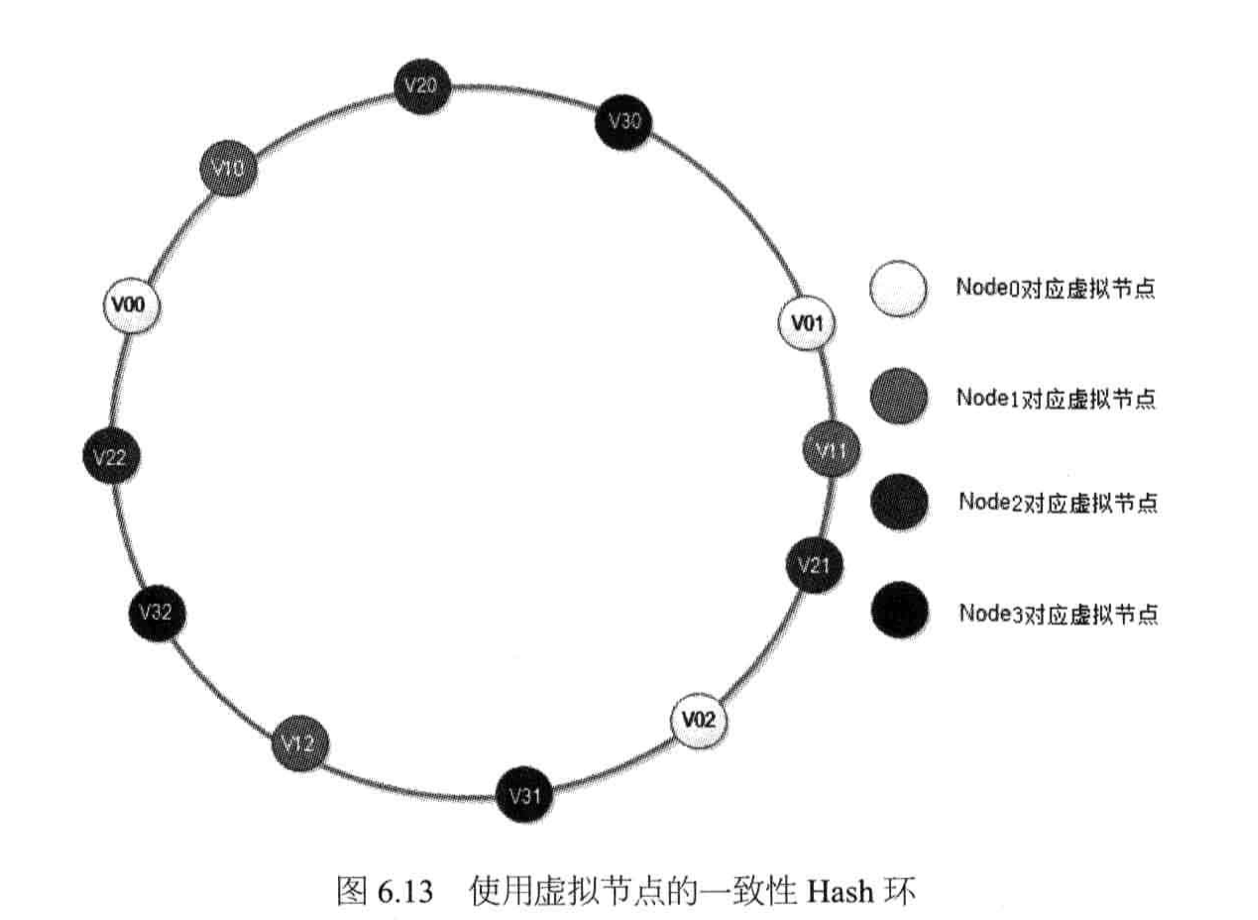
每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入服务器对原有的物理服务器的影响越保持一致。
实践中,一台物理服务器可以虚拟为150个虚拟服务器节点,当然根据集群规模和负载均衡的精度需求,这个值应该根据具体情况具体对待。
总结
本节主要讲解了分布式缓存伸缩性设计利器:一致性Hash算法。必须对这个算法理解和掌握。
作者: 元宝爸爸
出处:https://www.cnblogs.com/wozixiaoyao/p/11965398.html
版权:本文采用「署名-非商业性使用-相同方式共享 4.0 国际」知识共享许可协议进行许可。
觉得文章不错,点个关注呗!

