
https://www.jb51.net/article/209042.htm
0.VMware克隆虚拟机(准备工作,克隆3台虚拟机,一台master,两台node)
- 先在虚拟机中关闭系统
- 右键虚拟机,点击管理,选择克隆
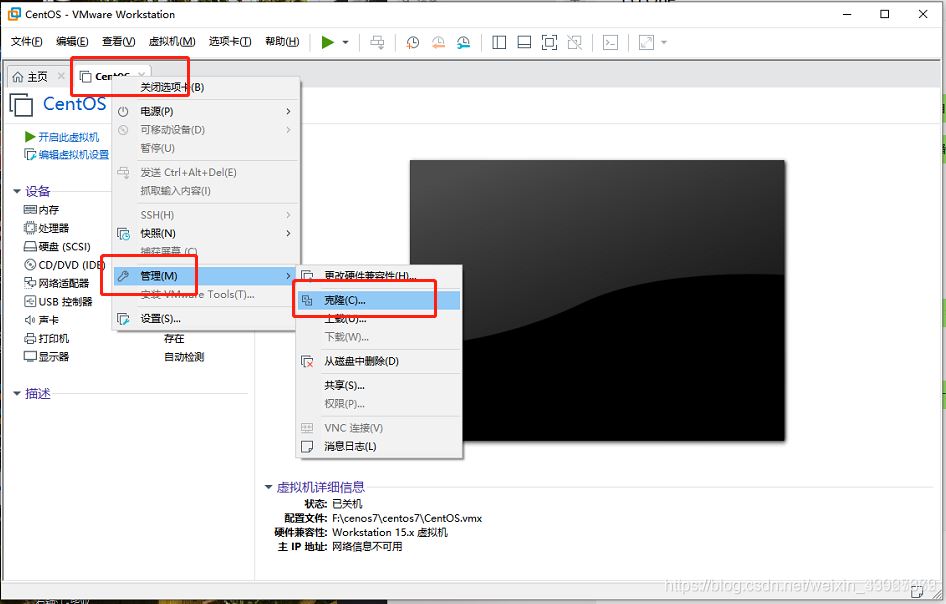
3.点击下一步,选择完整克隆,选择路径即可
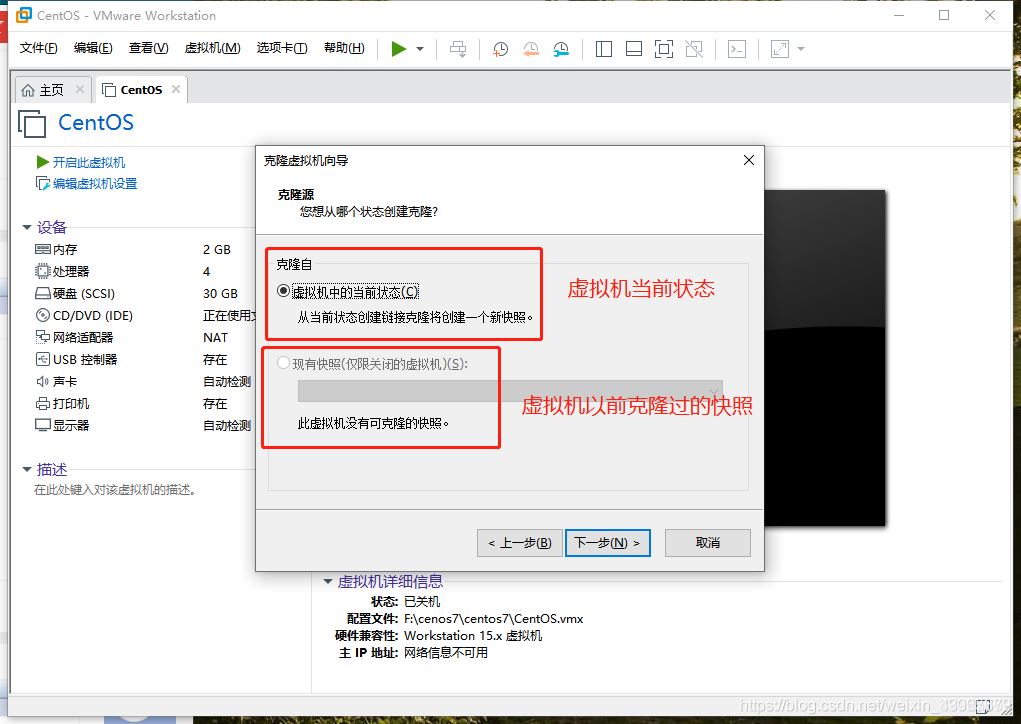
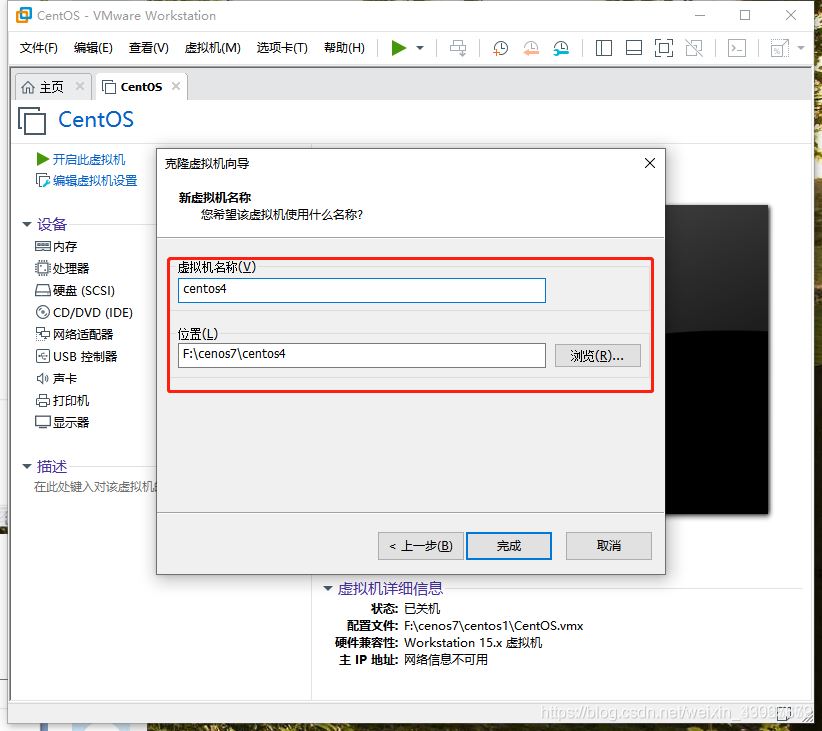
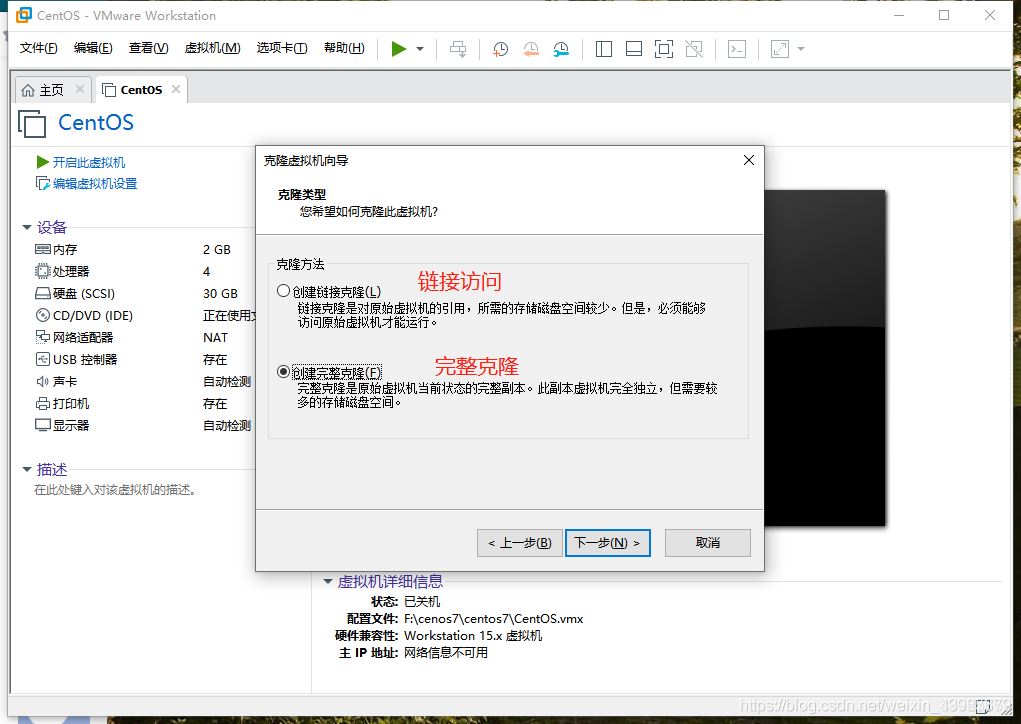
注:以上步骤是模拟了三台计算机
1.创建Hadoop用户(在master,node1,node2执行)
顺序执行以下命令即可
1.创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
设置用户密码(输入两次)
sudo passwd hadoop
添加权限
sudo adduser hadoop sudo
切换到hadoop用户(这里要输入刚刚设置的hadoop密码)
suhadoop
运行截图展示(以master虚拟机为例)

2.更新apt下载源(在master,node1,node2执行)
sudo apt-get update
截图展示(以master为例)

3. 安装SSH、配置SSH免密登录 (在master,node1,node2执行)
1.安装SSH
sudo apt-get install openssh-server
2.配置SSH免密登录
ssh localhost exit cd ~/.ssh/ ssh-keygen -t rsa #一直按回车 cat ./id_rsa.pub >> ./authorized_keys
3.验证免密
ssh localhost exit cd ~/.ssh/ ssh-keygen -t rsa #一直按回车 cat ./id_rsa.pub >> ./authorized_keys
截图展示(以master为例)

4.安装Java环境 (在master,node1,node2执行)
1.下载 JDK 环境包
sudo apt-get install default-jre default-jdk
2.配置环境变量文件
vim ~/.bashrc
3.在文件首行加入
export JAVA_HOME=/usr/lib/jvm/default-java
4.让环境变量生效
source ~/.bashrc
5.验证
java -version
截图展示(以master为例)

5.修改主机名(在master,node1,node2执行)
1.将文件中原有的主机名删除,master中写入master,node1中写入node1,node2…(同理)
sudo vim /etc/hostname
重启三个服务器
reboot
重启成功后,再次连接会话,发现主机名改变了
截图展示(以node1为例)

6.修改IP映射(在master,node1,node2执行)
查看各个虚拟机的ip地址
ifconfig -a
如果有报错,则下载 net-tools ,然后再运行即可看到
sudo apt install net-tools
如下图,红色方框内的就是 本台虚拟机的 ip 地址

3台虚拟机中都需要在 hosts 文件中加入对方的ip地址
sudo vim /etc/hosts
以master为例截图展示

7.SSH免密登录其他节点(在master上执行)
在Master上执行
cd ~/.ssh rm ./id_rsa* # 删除之前生成的公匙(如果有) ssh-keygen -t rsa # 一直按回车就可以 cat ./id_rsa.pub >> ./authorized_keys scp ~/.ssh/id_rsa.pub hadoop@node1:/home/hadoop/ scp ~/.ssh/id_rsa.pub hadoop@node2:/home/hadoop/

在node1,node2都执行
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys rm ~/id_rsa.pub # 用完就删掉

验证免密登录
ssh node1
exit
ssh node2
exit
以master为例截图展示

8.安装hadoop3.2.3(在master中执行)
有些镜像的下载网址失效了,这里贴出官网的下载地址。
下载网址:https://www.apache.org/dyn/closer.cgi/hadoop/common/
注:官网下载速度比较慢,通过清华镜像下载的
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.3/
下载好,之后通过VMware-Tools上传到master的/home/hadoop中
注:通过设置共享盘解决上传路径的问题


下载好,之后通过VMware-Tools上传到master的/home/hadoop中
解压
cd /home/hadoop sudo tar -zxf hadoop-3.2.3.tar.gz -C /usr/local #解压 cd /usr/local/ sudo mv ./hadoop-3.2.3/ ./hadoop # 将文件夹名改为hadoop sudo chown -R hadoop ./hadoop # 修改文件权限
验证
cd /usr/local/hadoop
./bin/hadoop version

9.配置hadoop环境(这一步需要很仔细)
配置环境变量
vim ~/.bashrc
在首行中写入
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使得配置生效
source ~/.bashrc
创建文件目录(为后面的xml做准备)
cd /usr/local/hadoop mkdir dfs cd dfs mkdir name data tmp cd /usr/local/hadoop mkdir tmp
配置hadoop的java环境变量
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vim $HADOOP_HOME/etc/hadoop/yarn-env.sh
两个的首行都写入
export JAVA_HOME=/usr/lib/jvm/default-java
(master中)配置nodes
cd /usr/local/hadoop/etc/hadoop
删除掉原有的localhost,因为我们有2个node,就把这2个的名字写入
vim workers
node1
node2
配置 core-site.xml
vim core-site.xml
因为我们只有一个namenode,所以用fs.default.name,不采用fs.defalutFs
其次确保/usr/local/hadoop/tmp这个目录存在

<configuration> <property> <name>fs.default.name</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration>
配置 hdfs-site.xml
vim hdfs-site.xml
dfs.namenode.secondary.http-address确保端口不要和core-site.xml中端口一致导致占用
确保/usr/local/hadoop/dfs/name :/usr/local/hadoop/dfs/data 存在
因为我们只有2个node,所以dfs.replication设置为2
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
配置mapred-site.xml
vim mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
配置 yarn-site.xml
vim yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
将hadoop压缩
cd /usr/local tar -zcf ~/hadoop.master.tar.gz ./hadoop #压缩 cd ~
复制到node1中
scp ./hadoop.master.tar.gz node1:/home/hadoop
复制到node2中
scp ./hadoop.master.tar.gz node2:/home/hadoop
在node1、node2上执行
解压
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在) sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local #解压 sudo chown -R hadoop /usr/local/hadoop #修改权限
首次启动需要先在 Master 节点执行 NameNode 的格式化,之后不需要
hdfs namenode -format
(注意:如果需要重新格式化 NameNode ,才需要先将原来 NameNode 和 DataNode 下的文件全部删除!!!!!!!!!)
#看上面的文字,不要直接复制了 rm -rf $HADOOP_HOME/dfs/data/* rm -rf $HADOOP_HOME/dfs/name/*
10.启动 (在master上执行)
start-all.sh
mr-jobhistory-daemon.sh start historyserver
master中,出现Warning不影响
jps
运行截图展示

11.关闭hadoop集群(在master上执行)
stop-all.sh
mr-jobhistory-daemon.sh stop historyserver
运行截图展示

注:搭建过程中遇到的两个小问题
1.ubuntu 解决“无法获得锁 /var/lib/dpkg/lock -open (11:资源暂时不可用)”的方法
在ubuntu系统的termial下,用apt-get install 安装软件的时候,如果在未完成下载的情况下将terminal close。此时 apt-get进程可能没有结束。结果,如果再次运行apt-get install 命令安装如今,可能会发生下面的提示:
无法获得锁 /var/lib/dpkg/lock - open (11: 资源暂时不可用)
无法锁定管理目录(/var/lib/dpkg/),是否有其他进程正占用它?
强制解锁,命令
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
2.yum install 没有已启用的仓库

ubuntu默认软件包管理器不是yum,而是dpkg,安装软件时用apt-get你说的网上常见法解决方法,命令改为代码:sudo apt-get install net-tools,这样就安装好了。

3.VMware中Ubuntu18配置静态IP地址
https://www.shuzhiduo.com/A/KE5QN2aMdL/
1. VMware:编辑 -> 虚拟网络编辑器 -> 更改设置
2. 取消选中:使用本地DHCP服务将IP地址分配给虚拟机,并记住子网ip

3. 点击NAT设置,记住网关地址
正常情况下VMware的网关IP是以 192.168.x.2结尾的,因为 x.1是绑定在物理机的虚拟网卡上的,而 x.2是用于转发数据的
4. 记住网卡名称
ifconfig

5. 配置静态IP
注意:Ubuntu18固定IP的方式跟Ubuntu18之前版本的的配置方式不同,Ubuntu18之前在/etc/network/interfaces进行配置,Ubuntu18及之后版本在/etc/netplan/*.yaml进行配置,如/etc/netplan/01-network-manager-all.yaml,如果/etc/netplan目录下没有yml文件,则可以新建一个
sudo vim /etc/netplan/01-network-manager-all.yaml
修改成以下形式:
# Let NetworkManager manage all devices on this systemnetwork:version: 2renderer: NetworkManagerethernets:ens33: # 网卡名称dhcp4: nodhcp6: noaddresses: [192.168.100.101/24] # 本机ip及掩码,最后一段不要取1或2gateway4: 192.168.100.2 # 前面记录的网关地址nameservers:addresses: [192.168.100.2] # DNS跟随网关地址一致,也可以改别的,如[114.114.114.114,8.8.8.8]
6. 应用更改
sudo netplan apply
7. 查看是否配置成功
ifconfigping www.baidu.com

4.Ubuntu18.04修改IP地址的方法(error in network definition ......is missing /prefixlength)
https://blog.csdn.net/m0_37052320/article/details/100107557


5.找不到或无法加载主类

解决方法:
在命令行下输入hadoop classpath,复制返回的内容,然后在yarn-site.xml(/opt/module/hadoop-3.1.3/etc/hadoop)的<configuration>下加上
<property>
<name>yarn.application.classpath</name>
<value>输入刚才返回的Hadoop classpath路径</value>
</property>
运行成功

查看运行结果



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)
2019-04-02 00centos安装