大数据面试之Hadoop
HDFS
1、HDFS写流程
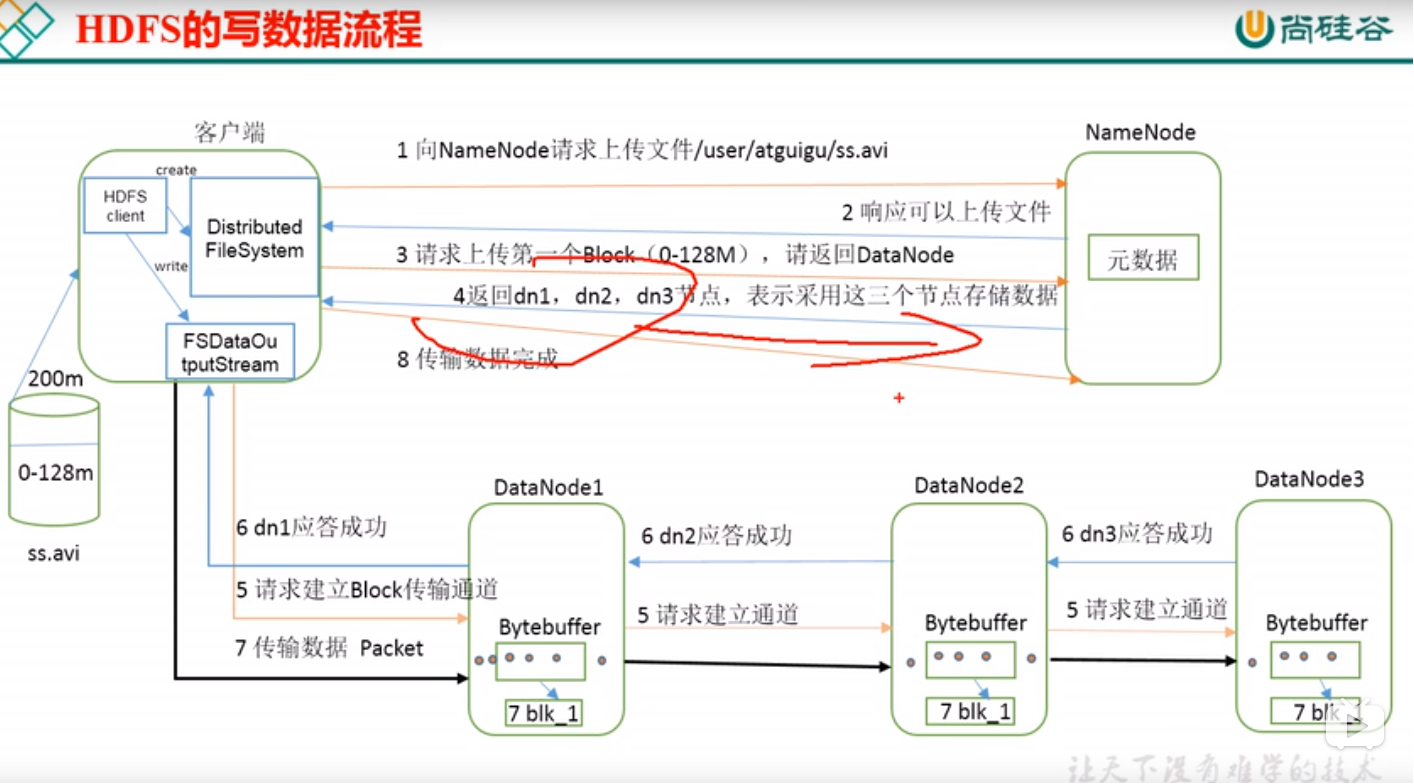
1、client向NameNode通信请求上传文件,NameNode响应可以上传文件
2、client向NameNode请求上传第一个block,请NameNode返回DataNode信息,NameNode向客户端反馈可以存储数据的DataNode信息(Namenode根据距离与负载选择DataNode)
3、client请求一台dataNode上传数据(本质上是一个RPC调用,建立Pipeline),,第一个datanode收到请求会继续调用第二个datanode,然后第二个调用第三个datanode,将整个pipeline建立完成,逐级返回客户端。
4、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(一个packet为64kb),当然在写入的时候datanode会进行数据校验,它并不是通过一个packet进行一次校验而是以chunk为单位进行校验(512byte),第一台datanode收到一个packet就会传给第二台,第二台传给第三台;第一台每传一个packet会放入一个应答队列等待应答 。
5、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
2、HDFS读流程
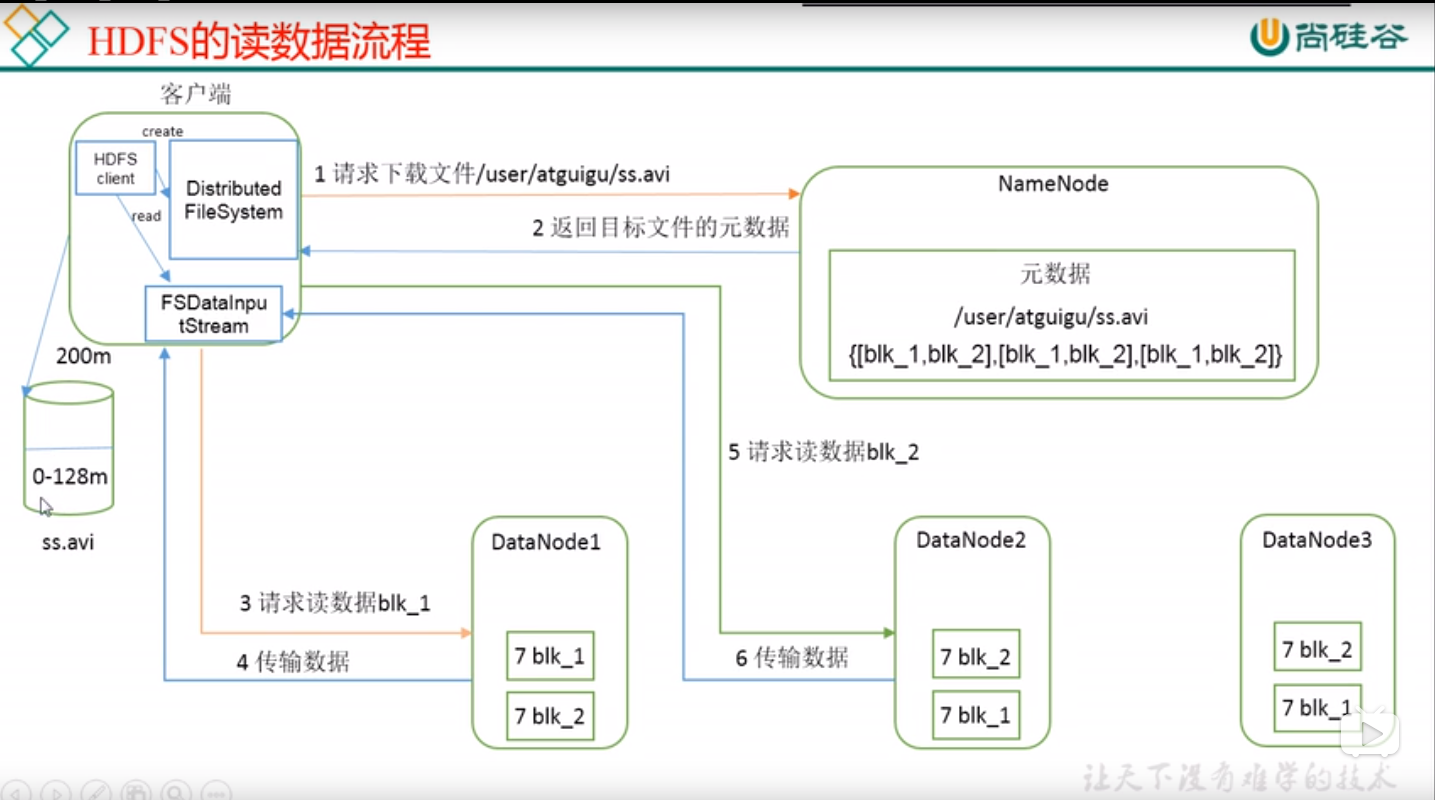
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
