Spark 源码解读(一)SparkContext的初始化之创建执行环境SparkEnv
Spark 源码解读(一)SparkContext的初始化之创建执行环境SparkEnv
SparkContext 概述
每一个Spark应用都是一个SparkContext实例,可以理解为一个SparkContext就是一个Spark application的生命周期。SparkContext是Spark功能的主要入口,一个SparkContext表示与一个Spark集群的连接,在Spark集群上,能创建RDDs累加器,广播变量。
sparkContext的初始化步骤如下:
- 创建Spark执行环境SparkEnv
- 创建RDD清理器metadataCleaner
- 创建并初始化SparkUI
- Hadoop相关配置及Excutor环境变量的设置
- 创建任务调度TaskScheduler
- 创建和启动DAGScheduler
- TaskScheduler的启动
- 初始化块管理器BlockManager
- 启动测量系统MetricsSystem
- 创建和启动Executor分配管理器ExecutorAllocationManager
- ContextCleaner的创建与启动
- Spark环境更新
- 创建DAGSchedulerSource和BlockManagerSource
- 将SparkContext标记为激活
创建执行环境SparkEnv
SparkEnv是Spark的执行对象,其中包括众多与Excutor执行相关的对象。SparkEnv拥有正在运行的Spark实例(master或者worker)的运行环境对象,包括序列化器,block管理器,map输出追踪器,RPC环境,spark代码通过一个全局变量查找SparkEnv,所以所有的线程都可以访问相同的SparkEnv,可以通过SparkEnv.get来访问(SparkContext创建之后)
代码如下:
private[spark] def createSparkEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus): SparkEnv = {
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master))
}
代码中conf是对SparkConf的复制,isLocal标识是否是单机模式,listenerBus表示采用监听器模式维护各类事件的处理
SparkEnv的方法createDriverEnv最终调用create创建SparkEnv,SparkEnv的构造步骤如下:
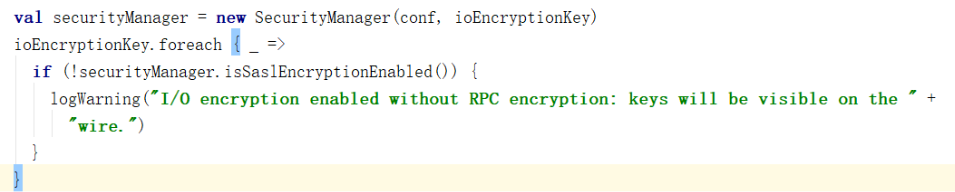
(1)创建安全管理器SecurityManager;
SecurityManager主要对权限、账号进行设置
(2)创建RPCEnv
RpcEnv实例化默认的是NettyRpcEnvFactory

(3)指定Spark序列化:org.apache.spark.serializer.JavaSerializer
val serializer = instantiateClassFromConf[Serializer](
"spark.serializer", "org.apache.spark.serializer.JavaSerializer")
logDebug(s"Using serializer: ${serializer.getClass}")
val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey)
val closureSerializer = new JavaSerializer(conf)
closureSerializer是专门做任务的序列化反序列化的,当然也负责对函数闭包的序列化反序列化
(4)创建广播管理器:broadcastManager
val broadcastManager = new BroadcastManager(isDriver, conf, securityManager)
(5)创建Map任务输出跟踪器mapOutputTracker
val mapOutputTracker = if (isDriver) {
new MapOutputTrackerMaster(conf, broadcastManager, isLocal)
} else {
new MapOutputTrackerWorker(conf)
}
// Have to assign trackerEndpoint after initialization as MapOutputTrackerEndpoint
// requires the MapOutputTracker itself
mapOutputTracker.trackerEndpoint = registerOrLookupEndpoint(MapOutputTracker.ENDPOINT_NAME,
new MapOutputTrackerMasterEndpoint(
rpcEnv, mapOutputTracker.asInstanceOf[MapOutputTrackerMaster], conf))
注册RpcEndPoint(也就是MapOutputTrackerEndPoint)到Dispatcher
(6)实例化ShuffleManager
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
实例化shuffleManager,默认为SortShuffleManager
(7)创建内存管理器:memoryManager
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores)
} else {
UnifiedMemoryManager(conf, numUsableCores)
}
默认内存管理器为UnifiedMemoryManager(动态内存管理器),通过设置spark.memory.useLegacyMode=true,将内存管理器设置为静态内存管理器
(8)创建块传输服务:BlockTransferService;
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, bindAddress, advertiseAddress,
blockManagerPort, numUsableCores)
默认为NettyBlockTransferService
(9)创建BlockManagerMaster
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
注册RpcEndPoint(也就是BlockManagerMasterEndpoint)到Dispatcher
(10)创建块管理器BlockManager
val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,
serializerManager, conf, memoryManager, mapOutputTracker, shuffleManager,
blockTransferService, securityManager, numUsableCores)
(11)创建测量系统:metricsSystem
val metricsSystem = if (isDriver) {
// Don't start metrics system right now for Driver.
// We need to wait for the task scheduler to give us an app ID.
// Then we can start the metrics system.
MetricsSystem.createMetricsSystem("driver", conf, securityManager)
} else {
// We need to set the executor ID before the MetricsSystem is created because sources and
// sinks specified in the metrics configuration file will want to incorporate this executor's
// ID into the metrics they report.
conf.set("spark.executor.id", executorId)
val ms = MetricsSystem.createMetricsSystem("executor", conf, securityManager)
ms.start()
ms
}
(12)注册outputCommitCoordinator,用于决定是否允许将task输出提交到HDFS
val outputCommitCoordinator = mockOutputCommitCoordinator.getOrElse {
new OutputCommitCoordinator(conf, isDriver)
}
val outputCommitCoordinatorRef = registerOrLookupEndpoint("OutputCommitCoordinator",
new OutputCommitCoordinatorEndpoint(rpcEnv, outputCommitCoordinator))
outputCommitCoordinator.coordinatorRef = Some(outputCommitCoordinatorRef)
(13)new SparkEnv()实例
val envInstance = new SparkEnv(
executorId,
rpcEnv,
serializer,
closureSerializer,
serializerManager,
mapOutputTracker,
shuffleManager,
broadcastManager,
blockManager,
securityManager,
metricsSystem,
memoryManager,
outputCommitCoordinator,
conf)

