

Kafka
Kafka
1、简介
1 在分布式场景中,相对于大量的用户请求来说,内部的功能主机之间、功能模块之间等,数据传递的数据量是无法想象的,因为一个用户请求,会涉及到各种内部的业务逻辑跳转等操作。那么,在大量用户的业务场景中,如何保证所有的内部业务逻辑请求都处于稳定而且快捷的数据传递呢? 消息队列(Message Queue)技术可以满足此需求
2 MQ使用场景
削峰填谷:业务流量过高时,系统可能会因为超负荷而崩溃,消息队列可提供削峰填谷的服务来解决该问题
异步解耦:当整体业务系统庞大而且复杂时,消息队列可实现异步通信和应用解耦,确保主站业务的连续性
顺序收发:在许多业务中需要保证顺序,与先进先出FIFO原理类似,消息队列提供的顺序消息即保证消息FIFO
分布式事务一致性:许多业务中需要保证数据的最终一致性,大量引入消息队列的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性
大数据分析:传统数据分析大多是基于批量计算模型,而无法做到实时的数据分析,利用消息队列与流式计算引擎相结合,可以很方便的实现业务数据的实时分析
蓄流压测:线上有些链路不方便做压力测试,可以通过堆积一定量消息再放开来压测
3 MQ软件:Kafka、RabbitMQ、RocketMQ等
4 由Scala和Java编写,用于构建实时数据管道和流应用程序,具有水平可伸缩性,容错性,快速性
5 特点:
分布式:支持多主机分布式部署
分区:一个消息可以拆分出多个,分别存储在不同位置
多副本:为防信息丢失,可以进行备份
多订阅:可以有多个应用连接kafka
2、Kafka角色及流程
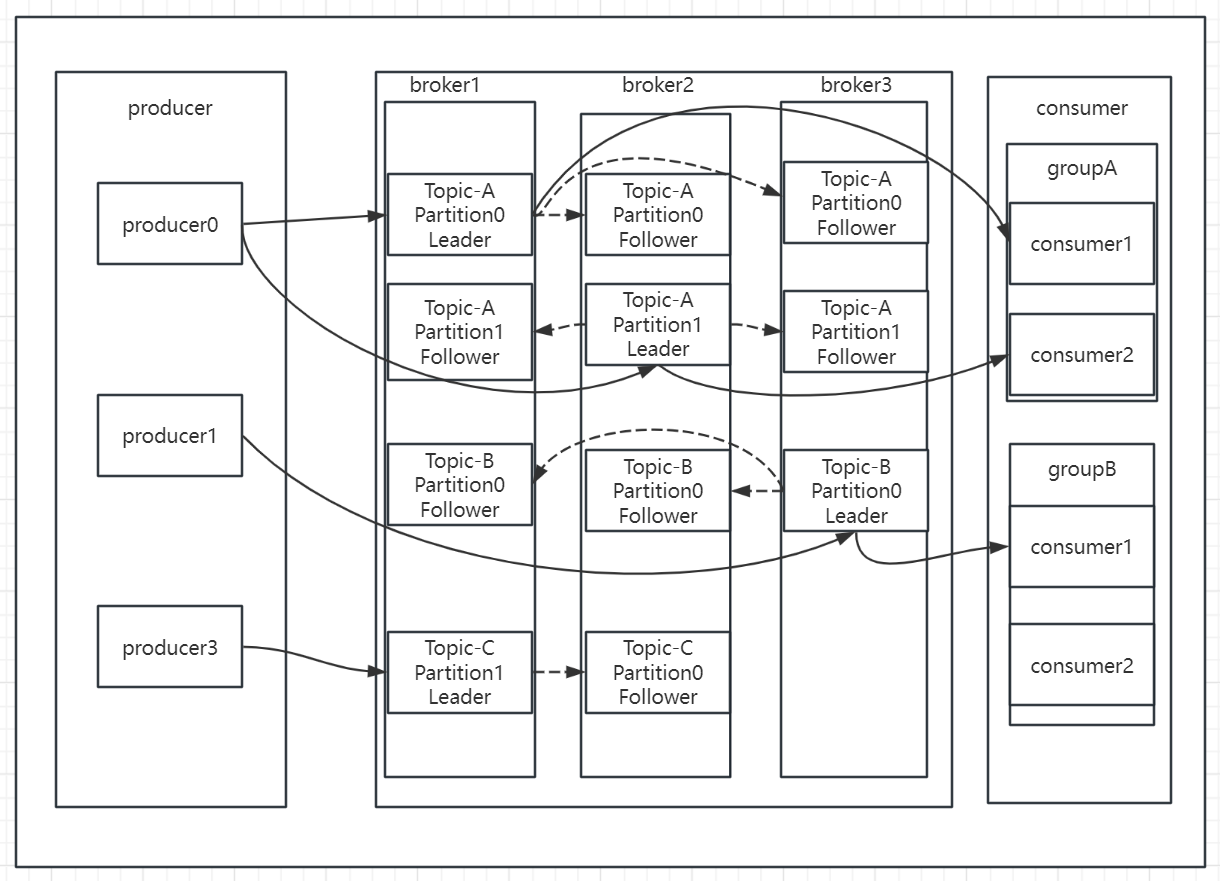
kafka是处于生产者和消费者之间的角色,用于传递消息
Broker:Broker是kafka实例,每个服务器上可以有一个或多个kafka的实例,假设每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如: broker-0、broker-1等……
Topic :消息的主题,可以理解为消息的分类,一个Topic相当于数据库中的一张表,一条消息相当于关系数据库的一条记录,消息即为列表中的一个元素。kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition :是物理上的概念,每个 topic 分割为一个或多个partition,即一个topic切分为多份, 当创建 topic 时可指定 partition 数量,partition的表现形式就是一个一个的文件夹,该文件夹下存储该partition的数据和索引文件,分区的作用还可以实现负载均衡,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,一般Partition数不要超过节点数,注意同一个partition数据是有顺序的,但不同的partition则是无序的
Consumer group: 每个consumer 属于一个特定consumer group(可为每个consumer 指定 group name,若不指定 group name 则属于默认的group),同一topic的一条消息只能被同一个consumer group 内的一个consumer 消费,类似于一对一的单播机制,但多个consumer group 可同时消费这一消息,类似于一对多的多播机制
Replication: 同样数据的副本,包括leader和follower的副本数,基本于数据安全,建议至少2个,是Kafka的高可靠性的保障,和ES的副本有所不同,Kafka中的副本数包括主分片数,而ES中的副本数不包括主分片数
Controller:是整个 Kafka 集群的管理者角色,任何集群范围内的状态变更都需要通过 Controller 进行,在整个集群中是个单点的服务,可以通过选举协议进行故障转移,负责集群范围内的一些关键操作:主题的新建和删除,主题分区的新建、重新分配,Broker 的加入、退出等,每个 Broker 里都有一个 Controller 实例,多个 Broker 的集群同时最多只有一个 Controller 可以对外提供集群管理服务,Controller 可以在 Broker 之间进行故障转移
选举流程
选举机制涉及到分区复制,每个kafka分区都有一个领导者和多个追随者,领导者负责读写操作,追随者负责复制领导者数据(kafka2.4之后,开始支持读)
当新的分区创建时,kafka会选择列表中的第一个副本作为领导者,当领导者失败时,会重新选举,被称为领导者故障转移
故障转移在2.8之前需要zookeeper的参与,当领导者发生故障,ZooKeeper将会检测到它的会话过期,ZooKeeper接着将通知所有的副本进行领导者选举,副本们会查看它们在ZooKeeper中存储的元数据并确定新的领导者,选择规则是选取副本集合中最新的副本, 一旦新的领导者被选出,ZooKeeper将通知所有的副本更新它们的元数据。2.8之后添加了KRft模式,通过KRft协议进行元数据存储及选举,可以浅显的理解为KRft顶替了zookeeper的位置
消息写流程
该流程和MySQL的同步复制流程类似,生产者先从集群中获取到分区的leader信息,然后将消息发送给leader,leader写入本地文件,follower将leader新写入的信息拉到本分区,写入成功后向leader发送写入成功ACK确认,leader接收到所有follow的确认后,向消费者发送确认。这样的流程导致性能有些降低,但却实现了强一致性,有利有弊。
kafka还允许和MySQL类似的半同步复制,只需要将参数中的min.insync.replicas设置为大于1,在生产者端还需要设置ack为all或者-1,这样就可以确保至少有1个副本确认数据写入才认为写操作成功,这样就可以保证高性能,数据也不会丢失,看业务需要选择
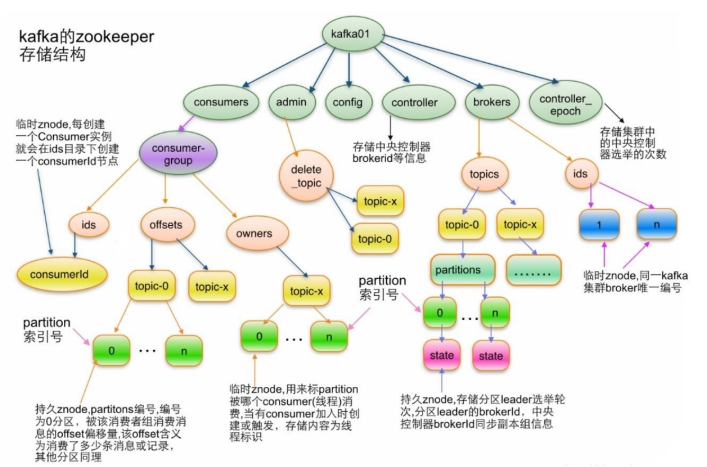
kafka在zookeeper内的存储结构
#topic 结构
/brokers/topics/[topic]
#partition结构
/brokers/topics/[topic]/partitions/[partitionId]/state
#broker信息
/brokers/ids/[o...N]
#控制器
/controller
存储center controller中央控制器所在kafka broker的信息
#消费者
消费者信息:
/consumers/[groupId]/ids /[consumerIdstring]
每个consumer都有一个唯一的ID,此id用来标记消费者信息
消费者管理者:
/consumers/[groupId]/owners/[topic]/[partitionid]
3、安装部署
kafka的版本格式:
kafka_2.13-2.7.0.tgz
前一个是scala的版本,后面一个是kafka的版本
kafka的下载链接:
http://kafka.apache.org/downloads
scala官网:
scala语言和Java语言及其类似,甚至可以和Java互操作,在编译时,scala文件会转换为Java字节码并在jvm上运行,具体
关系可以在网上进行查找,这里不再赘述
单机部署
#安装Java环境,需要注意的是Java必须要在8及以上
apt update && apt -y install openjdk-8-jdk
#解压运行
tar -xzf kafka_2.13-3.4.0.tgz
cd kafka_2.13-3.4.0
bin/zookeeper-server-start.sh config/zookeeper.properties
#修改相关配置文件
grep zookeeper /usr/local/kafka/config/server.properties
# Zookeeper connection string (see zookeeper docs for details).该配置指定的zookeeper服务器地址信息
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
集群部署
集群部署低版本需要zookeeper的,高版本不需要zookeeper,下面会展示两种部署
依赖zookeeper
本次系统采用的是ubuntu系统,其它系统和本系统的部署方式类似
node1:10.0.0.101
node2:10.0.0.102
node3:10.0.0.103
#三个节点都装了zookeeper及kafka,生产环境要分开部署
#各节点部署kafka
apt install openjdk-8-jdk -y
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.3.1/kafka_2.13-3.3.1.tgz
tar xf kafka_2.13-3.3.1.tgz -C /usr/local/
ln -s /usr/local/kafka_2.13-2.7.0/ /usr/local/kafka
echo 'PATH=/usr/local/kafka/bin:$PATH' > /etc/profile.d/kafka.sh
. /etc/profile.d/kafka.sh
#修改配置文件
vim /usr/local/kafka/config/server.properties
broker.id=1 #每个broker在集群中每个节点的正整数唯一标识,此值保存在log.dirs下的meta.properties文件
listeners=PLAINTEXT://10.0.0.101:9092 #指定当前主机的IP做为监听地址,注意:不支持0.0.0.0
log.dirs=/usr/local/kafka/data #kakfa用于保存数据的目录,所有的消息都会存储在该目录当中
num.partitions=1 #设置创建新的topic时默认分区数量,建议和kafka的节点数量一致
default.replication.factor=3 #指定默认的副本数为3,可以实现故障的自动转移
log.retention.hours=168 #设置kafka中消息保留时间,默认为168小时即7天
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 #指定连接的zk的地址,zk中存储了broker的元数据信息
zookeeper.connection.timeout.ms=6000 #设置连接zookeeper的超时时间,单位为ms,默认6秒钟
#详细配置项下文会有详细说明
mkdir /usr/local/kafka/data
#与Java一样,启动时可以通过配置文件调整内存大小
vim /usr/local/kafka/bin/kafka-server-start.sh
if[ " x$KAFKA_HEAP_OPTS"="x"] ; then
export KAFKA_HEAP_OPTS=" -Xmx1G -Xms1G"
fi
#三台都是这样部署
#启动
#启动方式一
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
#启动方式二
#设置service文件
vim /lib/systemd/system/kafka.service
[unit]
Description=Apache kafka
After=network.target
[service]
Type=simple
#Environment=JAVA_HOME=/data/server/java
PIDFile=/usr/local/kafka/kafka.pid
Execstart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server. properties
Execstop=/bin/kill -TERM ${MAINPID}
Restart=always
RestartSec=20
[Install]
wantedBy=multi-user.target
systemctl daemon-load
systemctl restart kafka.service
#各节点部署zookeeper
wget -P /usr/local/src https://downloads.apache.org/zookeeper/stable/apache-zookeeper-3.6.3-bin.tar.gz
tar xf /usr/local/src/apache-zookeeper-3.6.3-bin.tar.gz -C /usr/local/
ln -s /usr/local/apache-zookeeper-3.6.3-bin /usr/local/zookeeper
echo 'PATH=/usr/local/zookeeper/bin:$PATH' > /etc/profile.d/zookeeper.sh
. /etc/profile.d/zookeeper.sh
mkdir /usr/local/zookeeper/data
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
vim /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000 #服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
initLimit=10 #集群中leader 服务器与follower服务器初始连接心跳次数,即多少个 2000 毫秒
syncLimit=5 #leader 与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果该follower在设置的时间内(5*2000)不能与leader 进行通信,那么此 follower将被视为不可用。
dataDir=/usr/local/zookeeper/data #自定义的zookeeper保存数据的目录
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求
maxClientCnxns=128 #单个客户端IP 可以和zookeeper保持的连接数
autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,最小值为3
autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能
#格式: server.MyID服务器唯一编号=服务器IP:Leader和Follower的数据同步端口(只有leader才会打开):Leader和Follower选举端口(L和F都有)
server.1=10.0.0.101:2888:3888
server.2=10.0.0.102:2888:3888
server.3=10.0.0.103:2888:3888
#如果添加节点,只需要在所有节点上添加新节点的上面形式的配置行,在新节点创建myid文件,并重启所有节点服务即可
echo 1 > /usr/local/zookeeper/data/myid
#myid需要根据上面去配置
#启动
zkServer.sh start
#kafka配置文件详细说明
############################# Server Basics###############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1
############################# Socket ServerSettings ######################
# kafka监听端口,默认9092
listeners=PLAINTEXT://10.0.0.101:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics###################################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log FlushPolicy #############################
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s,单位是ms
log.flush.interval.ms=1000
############################# Log RetentionPolicy #########################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper ####################################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
# 是否允许删除topic,默认为false,topic只会标记为marked for deletion
delete.topic.enable=true
KRaft部署
不像基于ZooKeeper的模式,(zk去做的事情,我们手动配置不了)任何服务器都可以成为控制器。这带来了一个非常优秀的好处,即如果我们认为 controller 节点的负载会比其他只当做broker节点高,那么可以为 controller 节点使用高配的机器。这就解决了在1.0, 2.0架构中, controller 节点会比其他节点负载高,却无法控制哪些节点能成为 controller 节点的问题。
尽管 controller 进程在逻辑上与 broker 进程是分离的,但它们不需要在物理上分离。即在某些情况下,部分或所有 controller 进程和 broker 进程是可以是同一个进程,即一个broker节点即是broker也是controller。
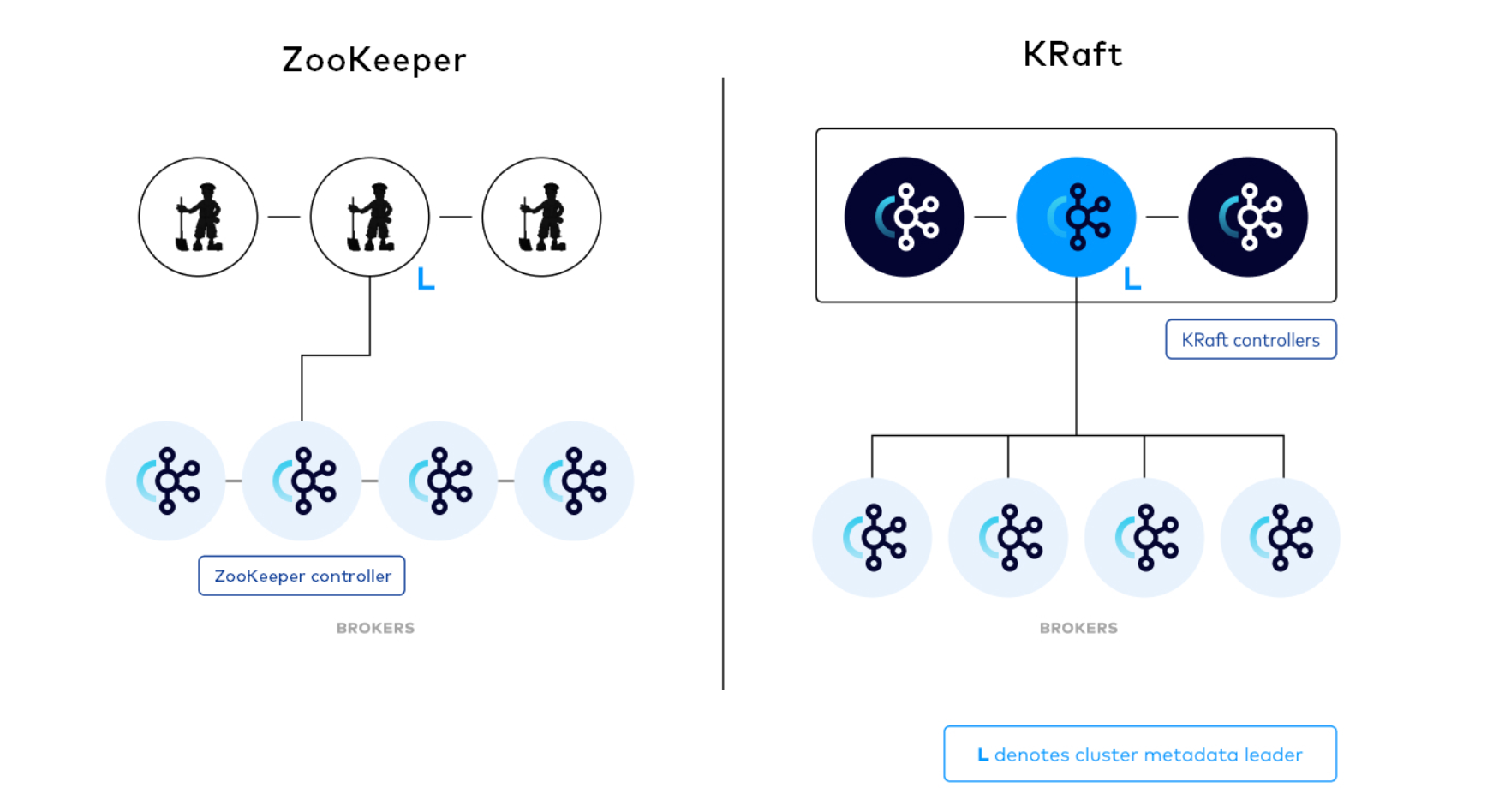
在KRaft模式下,每个Kafka服务器都有一个新的配置项,叫做process.roles, 这个参数可以有以下值:
如果process.roles = broker, 服务器在KRaft模式中充当 broker。
如果process.roles = controller, 服务器在KRaft模式下充当 controller。
如果process.roles = broker,controller,服务器在KRaft模式中同时充当 broker 和controller。
需要注意:如果process.roles 没有设置。那么集群就假定是运行在ZooKeeper模式下
系统中的所有节点都必须设置 controller.quorum.voters 配置。用于配置所有想成为controller的节点。
如果你有10个broker和 3个controller1,分别命名为controller1、controller2、controller3,你可能在 controller1上有以下配置:
process.roles=controller
node.id=1
listeners=CONTROLLER://controller1.example.com:9093
controller.quorum.voters=1@controller1.com:9093,2@controller2.com:9093,3@controller3.com:9093
如果你只有三个节点,每个节点都是controller,broker角色,那么每个节点都这样配置
process.roles=broker,controller
listeners=CONTROLLER://controller1.example.com:9093
controller.quorum.voters=1@controller1.com:9093,2@controller2.com:9093,3@controller3.com:9093
集群具体原理详见https://developer.confluent.io/learn/kraft/
本次系统采用的是ubuntu系统,其它系统和本系统的部署方式类似
node1:10.0.0.101
node2:10.0.0.102
node3:10.0.0.103
#安装jdk
apt install openjdk-8jdk
#下载kafka
wget https://kafka.apache.org/downloads
tar -xf kafka_2.12-3.5.1.tgz
#将文件夹重命名为kafka
mv kafka_2.12-3.5.1 kafka
#生成集群随机uuid
[root@iamdemo1 ~ ]cd /opt/kafka/bin
[root@iamdemo1 bin]# sh kafka-storage.sh random-uuid
COY-4PxTT82yfvGKqAepwQ
#配置kraft模式相关参数
#参数位置:/opt/kafka/config/kraft/server.properties
##角色可同时为broker和controller
process.roles=broker,controller
##node.id为当前服务器作为节点的id
node.id=1
##定义投票节点,用于选举Master,每个节点都必须配置
controller.quorum.voters=1@10.0.0.101:9093,2@10.0.0.102:9093,3@10.0.0.103:9093
##9092为每个broker的通信端口,9093为controller节点的通信端口,如果一个节点是混合节点那就需要同时监听两个端口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093 #,EXTERNAL://172.29.145.157:9094
##broker内部监听协议
inter.broker.listener.name=PLAINTEXT
##对外公开的端口
#advertised.listeners=EXTERNAL://172.29.145.157:9094,PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://10.0.0.101:9092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL,EXTERNAL:PLAINTEXT
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
##kafka数据默认存储的地方
log.dirs=/opt/kafka/kraft-combined-logs
##每一个topic默认的分区
num.partitions=6
##恢复线程
num.recovery.threads.per.data.dir=2
##用于存储消费者组的消费偏移量信息的特殊主题,用于在发生故障时或者重新加入时能够恢复到之前的消费位置
offsets.topic.replication.factor=3
##用于存储事务状态信息的特殊主题,kafka支持事务性写入,当生产者使用事务模式写入数据时,信息会写入这个主题
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
auto.create.topics.enable=false
default.replication.factor=3
##数据的存储时间
log.retention.hours=168
##设置kafka一个数据段最大值1G
log.segment.bytes=1073741824
##检查数据过期时间300s一次
log.retention.check.interval.ms=300000
#使用集群uuid格式化kafka数据存储目录
[root@iamdemo1 bin]# sh kafka-storage.sh format -t COY-4PxTT82yfvGKqAepwQ -c ../config/kraft/server.properties
Formatting /opt/kafka/kraft-combined-logs with metadata.version 3.5-IV2.
#修改启动脚本,暴露JMX端口,配置JVM内存大小
##注意,jdk必须为64位jdk,否则JVM内存大小设置为4G会报错启动失败,查看方法java --version如果没有显示64bit的都是32位
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx4G -Xms4G"
export JMX_PORT="9999"
fi
#修改kafka日志配置参数,避免一小时生成一个日志文件
#文件位置:/opt/kafka/config/log4j.properties
##添加两条日志最大量
log4j.appender.kafkaAppender.MaxFileSize=100MB
log4j.appender.kafkaAppender.MaxBackupIndex=5
##修改DatePattern
log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd
#使用脚本启动kafka集群
[root@iamdemo1 bin]# sh kafka-server-start.sh -daemon ../config/kraft/server.properties
#查看集群状态
通过jps即可看到kafka进程是否在运行,也可通过ps aux查看
查看topic副本分布情况可以通过
./kafka-topics.sh --describe --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092
Topic: test-topic1 TopicId: U3-YpQ4QQqWM7jQ-8uAxjA PartitionCount: 6 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test-topic1 Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: test-topic1 Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: test-topic1 Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: test-topic1 Partition: 3 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: test-topic1 Partition: 4 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: test-topic1 Partition: 5 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
4、Kafka读写数据
常见命令:
kafka-topics.sh #消息的管理命令
kafka-console-producer.sh #生产者的模拟命令
kafka-console-consumer.sh #消费者的模拟命令
创建topic
创建名为chen,partitions(分区)为3,replication(每个分区的副本数/每个分区的分区因子)为2
#新版命令,通过--bootstrap-server指定kafka的地址
[root@knode1 ~]#/usr/local/kafka/bin/kafka-topics.sh --create --topic chen --bootstrap-server 10.0.0.101:9092 --partitions 3 --replication-factor 2
#在各节点上观察生成的相关数据
[root@knode1 ~]#ls /usr/local/kafka/data/
[root@knode2 ~]#ls /usr/local/kafka/data/
[root@knode3 ~]#ls /usr/local/kafka/data/
#旧版命令,通过zookeeper指定zookeeper的地址
[root@knode1 ~]#/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 --partitions 3 --replication-factor 2 --topic chen Created topic chen.
获取所有的topic
#新版命令
[root@knode1 ~]#/usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 10.0.0.101:9092
#旧版命令
[root@knode1 ~]#/usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 chen
查看topic详情
状态说明:chen有三个分区分别是0、1、2,分区0的leader是3(broker.id),分区0有2 个副本,并且状态都为 lsr(ln-sync,表示可 以参加选举成为 leader)。
#新版命令
[root@knode1 ~]#/usr/local/kafka/bin/kafka-topics.sh --describe --bootstrap-server 10.0.0.101:9092 --topic chen
Topic: chen TopicId: beg6bPXwToW1yp7cuv7F8w PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: chen Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: chen Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: chen Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3
#旧版命令
[root@knode1 ~]#/usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 --topic chen
Topic: chen PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: chen Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2
Topic: chen Partition: 1 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: chen Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1
生产topic
kafka-console-producer.sh 格式
#发送消息命令格式:
kafka-console-producer.sh --broker-list <kafkaIP1>:<端口>,<kafkaIP2>:<端口> --topic <topic名称>
#范例:
#交互式输入消息,按Ctrl+C退出
[root@knode1 ~]#/usr/local/kafka/bin/kafka-console-producer.sh --broker-list 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic chen
>message1
>message2
>message3
>
#或者下面方式
[root@knode1 ~]#/usr/local/kafka/bin/kafka-console-producer.sh --topic chen --bootstrap-server 10.0.0.101:9092
消费topic
kafka-console-consumer.sh 格式
#接收消息命令格式:
kafka-console-consumer.sh --bootstrap-server <host>:<post> --topic <topic名称> --from-beginning --consumer-property group.id=<组名称>
#范例:
#交互式持续接收消息,按Ctrl+C退出
[root@knode1 ~]#/usr/local/kafka/bin/kafka-console-consumer.sh --topic chen --bootstrap-server 10.0.0.102:9092 --from-beginning
message1
message3
message2
#一个消息同时只能被同一个组内一个消费者消费(单播机制),实现负载均衡,而不能组可以同时消费同一个消息(多播机制)
[root@knode2 ~]#/usr/local/kafka/bin/kafka-console-consumer.sh --topic chen --bootstrap-server 10.0.0.102:9092 --from-beginning --consumer-property group.id=group1
需要注意的是:
1、生产者先生产消息,消费者后续才启动,也能收到之前生产的消息
2、同一个消息在同一个group内的消费者只有被一个消费者消费,比如:共100条消息,在一个group内有A,B两个消费者,其中A消费 50条,B消费另外的50条消息。从而实现负载均衡,不同group内的消费者则可以同时消费同一个消息
3、--from-beginning 表示消费前发布的消息也能收到,默认只能收到消费后发布的新消息
删除topic
#范例
#注意:需要修改配置文件server.properties中的delete.topic.enable=true并重启
#新版本
[root@knode3 ~]#/usr/local/kafka/bin/kafka-topics.sh --delete --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic chen
#旧版本
[root@knode3 ~]#/usr/local/kafka/bin/kafka-topics.sh --delete --zookeeper 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 --topic chen
Topic chen is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
#范例
#删除zk下面 topic test
#无需修改配置文件server.properties,此方法很危险
[root@zookeeper-node1 ~]#zkCli.sh -server 10.0.0.103:2181
[zk: 10.0.0.103:2181(CONNECTED) 0] ls /brokers/topics
[zk: 10.0.0.103:2181(CONNECTED) 0] deleteall /brokers/topics/test
[zk: 10.0.0.103:2181(CONNECTED) 0] ls /brokers/topics
查看消息积压
#发现当前消费的offset和最后一条的offset差距很大,说明有大量的数据积压
格式: kafka-consumer-groups.sh --bootstrap-server {kafka连接地址} --describe --group {消费组}
#范例:
#下面命令查看消费组中每个Topic的堆积消息数。“LAG”表示每个Topic的总堆积数
[root@knode1 ~]#/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --group <组名> --describe
5、Kafka图形工具
Kafka-GUI管理程序
Offset Explorer ,旧称Kafka Tool,是一个 GUI 应用程序,用于管理和使用 Apache Kafka 群集。它提供了一个直观的 UI,允许人们快 速查看 Kafka 群集中的对象以及存储在群集主题中的消息。它包含面向开发人员和管理员的功能。一些关键功能包括:
1、快速查看您的所有 Kafka 集群,包括其经纪人、主题和消费者
2、查看分区中邮件的内容并添加新邮件
3、查看消费者的偏移量,包括Apache风暴、Kafka喷口
4、以漂亮的打印格式显示 JSON和 XML 消息
5、添加和删除主题以及其他管理功能
6、将单个邮件从分区保存到本地硬盘驱动器
6、编写自己的插件,允许查看自定义数据格式 Kafka 工具在Windows、Linux 和 Mac 操作系统上运行
#官网
https://www.kafkatool.com/
#下载地址
https://www.kafkatool.com/download.html
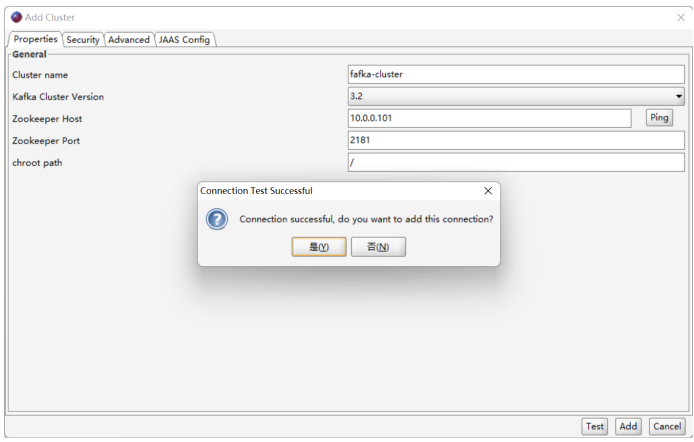
Kafka集群监控系统 kafka-eagle
Kafka eagle(kafka鹰) 是一款由国内公司开源的Kafka集群监控系统,可以用来监视kafka集群的broker状态、Topic信息、IO、内存、consumer线程、偏移量等信息,并进行可视化图表展示。独特的KQL还可以通过SQL在线查询kafka中的数据。
#官网
http://www.kafka-eagle.org/
安装
#参考链接
https://www.cnblogs.com/smartloli/p/16728995.html
#安装Java(不支持jdk11)
直接yum或者编译安装,此处不再赘述
#下载安装
wget https://github.com/smartloli/kafka-eagle-bin/archive/refs/tags/v3.0.2.tar.gz
tar zxf kafka-eagle-bin-3.0.2.tar.gz
cd kafka-eagle-bin-3.0.2/
tar -zxvf kafka-eagle-web-3.0.2-bin.tar.gz -C /usr/local/
ln -s /usr/local/kafka-eagle-web-3.0.2 /usr/local/kafka-eagle-web
#设置全局变量KE_HOME
vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export KE_HOME=/usr/local/kafka-eagle-web
export PATH=$PATH:$KE_HOME/bin
. /etc/profile
#修改相关配置文件
vim /usr/local/kafka-eagle-web/conf/system-config.properties
######################################
# 填写 zookeeper集群列表
#kafkazookeeper节点配置属性多个可以添加一个cluster1,如果有多套kafka集群加多个名称
efak.zk.cluster.alias=cluster1,cluster2
######################################
#zookeeper地址
######################################修改此处
cluster1.zk.list=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
#cluster2.zk.list=10.0.0.201:2181,10.0.0.202:2181,10.0.0.203:2181 此行必须注释掉,否则无法启动
######################################
# broker 最大规模数量
######################################
cluster1.efak.broker.size=20
######################################
# zk 客户端线程数#####################
#################
kafka.zk.limit.size=32
######################################
# EFAK webui 端口
######################################
efak.webui.port=8048
######################################
# kafka offset storage
######################################
cluster1.efak.offset.storage=kafka
cluster2.efak.offset.storage=zk
######################################
# kafka jmx uri
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jn di/rmi://%s/jmxrmi
######################################
# kafka metrics 指标,默认存储15天
######################################
efak.metrics.charts=true
efak.metrics.retain=15
######################################
# kafka sql topic records max
######################################
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
######################################
# delete kafka topic token
######################################
efak.topic.token=keadmin
######################################
# kafka sqlite 数据库地址(需要修改存储路径)
######################################修改此处,取消下面四行注释
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/usr/local/kafka-eagle-web/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org
######################################
# kafka mysql 数据库地址(需要提前创建ke库)
######################################修改此处添加注释下面四行
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
#efak.username=ke
#efak.password=123456
#启动
/usr/local/kafka-eagle-web/bin/ke.sh start
#登录
http://localhost:8048
默认账号:admin
默认密码:123456
默认 kafka 没有开启JMX,无法监控到Kafka的相关数据
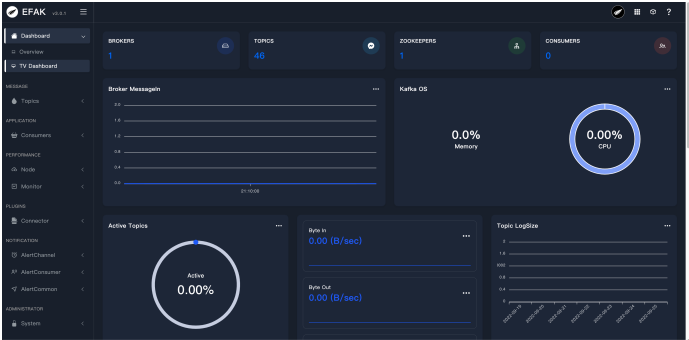
修改和监控Kafka
#所有kafka节点修改配置
[root@knode1 ~]#vim /usr/local/kafka/bin/kafka-server-start.sh
......
if[ " x$KAFKA_HEAP_OPTS"="x"] ; then
export KAFKA_HEAP_OPTS=" -Xmx1G-Xms1G"
export JMX_PORT="9999" #添加此行
fi
......
[root@knode1 ~]#systemctl restart kafka


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通