复习(一)绪论线性表
1.NlogN2 and NlogN3 have the same speed of growth.
解析:二分查找适用条件为:1.必须采用顺序存储结构。2.必须按关键字大小有序排列。
平均复杂度是O(logN)没有错,一看到这个就跳坑了。然后知道陷阱来了!按顺序存放在单项链表中。二分查找是不可以用链表存储的:
这是由链表的特性决定的。链表是很典型的顺序存取结构,数据在链表中的位置只能通过从头到尾的顺序检索得到,即使是有序的,要操作其中的某个数据也必须从头开始。
这和数组有本质的不同。数组中的元素是通过下标来确定的,只要你知道了下标,就可以直接存储整个元素,比如a[5],是直接的。链表没有这个,所以,折半查找只能在数组上进行。
5.求整数n(n>=0)的阶乘的算法如下,其时间复杂度为(O(n))。
在fac算法中,参数n度量问题的规模,计算结果只不过是O(1)的常数时间。整体fac的时间复杂度递推方程如下:
T ( n ) = { O ( 1 ) , n ≤ 1 T ( n − 1 ) + O ( 1 ) , n > 1 T(n)=\left\{ \right.
T(n)={
O(1),n≤1
T(n−1)+O(1),n>1
采用迭代法递推:
T ( n ) = T ( n − 1 ) + O ( 1 ) = T ( n − 2 ) + 2 O ( 1 )
T(n)=T(n−1)+O(1)
=T(n−2)+2O(1)
=...=T(1)+(n−1)O(1)
=O(1)+(n−1)O(1)=O(n)
6.Suppose A is an array of length N with some random numbers. What is the time complexity of the following program in the worst case? 为O(n)
void function( int A[], int N ) {
7.在N个结点的顺序表中,算法的时间复杂度为O(1)的操作是:
8.若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用哪种存储方式最节省时间?
10.For a sequentially stored linear list of length N, the time complexities for query and insertion are O(1) and O(N), respectively.
顺序存储的线性表支持随机存取,所以查询的时间是常数时间,但插入需要把后面每一个元素的位置都进行调整,所以是线性时间。
11.已知二维数组 A 按行优先方式存储,每个元素占用 1 个存储单元。若元素 A[0][0] 的存储地址是 100,A[3][3] 的存储地址是 220,则元素 A[5][5] 的存储地址是:300
二维数组A按行优先存储,每个元素占用1个存储单元,由A[0][0]和A[3][3]的存储地址可知A[3][3]是二维数组A中的第121个元素,假设二维数组A的每行有n个元素,则nx3 +4= 121,求得n= 39,故元素A[5][5]的存储地址为100+ 39*5+6- 1=300
12.在具有N个结点的单链表中,实现下列哪个操作,其算法的时间复杂度是O(N)?
13.线性表L在什么情况下适用于使用链式结构实现?
h为不带头结点的单向链表。在h的头上插入一个新结点t的语句是:t->next=h; h=t;p所指的结点不是最后结点,在p之后插入s所指结点,则执行s->next=p->next; p->next=s;h为空的判定条件是:h->next == NULL;h和p分别指向链表的头、尾结点,则有:p->next == hp之后插入s的语句是:s->prior=p; s->next=p->next; p->next->prior=s; p->next=s;p所指的结点,相应语句为:p->prior->next=p->next; p->next->prior=p->prior;c的单链表在内存中的存储状态如下表所示:
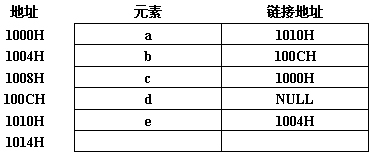
现将f存放于1014H处,并插入到单链表中,若f在逻辑上位于a和e之间,则a、e、f的“链接地址”依次是:1014H, 1004H, 1010H
解析:根据存储状态,单链表的结构如下图所示。其中“链接地址”是指结点next所指的内存地址。当结点f插入后,a指向f, f指向e, e指向b。显然a、e和f的“链接地址”分别是f、b和e的内存地址,即1014H、1004H和1010H。

22.链表 - 时间复杂度
在包含 n 个数据元素的链表中,▁▁▁▁▁ 的时间复杂度为 O(n)。
__EOF__

本文链接:https://www.cnblogs.com/xinhua23/p/16374987.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探
· 为什么 退出登录 或 修改密码 无法使 token 失效