数据库连接池实现
欢迎访问的另一个博客: https://xingzhu.top/
源码链接: https://github.com/xingzhuz/MysqlLinkPool
前置知识:
相关的环境配置: https://xingzhu.top/archives/shu-ju-ku-lian-jie-chi-huan-jing-pei-zhi
MySQL API: https://subingwen.cn/mysql/mysql-api/
Jsoncpp API: https://xingzhu.top/archives/jsoncpp
C++多线程: https://xingzhu.top/archives/duo-xian-cheng-xian-cheng-chi
概述
- 数据库连接池的作用是管理和复用数据库连接,以提高应用程序的性能和资源利用率
- 通过预先创建一定数量的连接并将它们存储在池中,应用程序可以快速获取连接,而无需每次都进行昂贵的连接创建和销毁过程
- 这不仅减少了延迟,还能有效控制数据库连接的数量,防止资源耗尽,从而提升整体系统的稳定性和响应速度
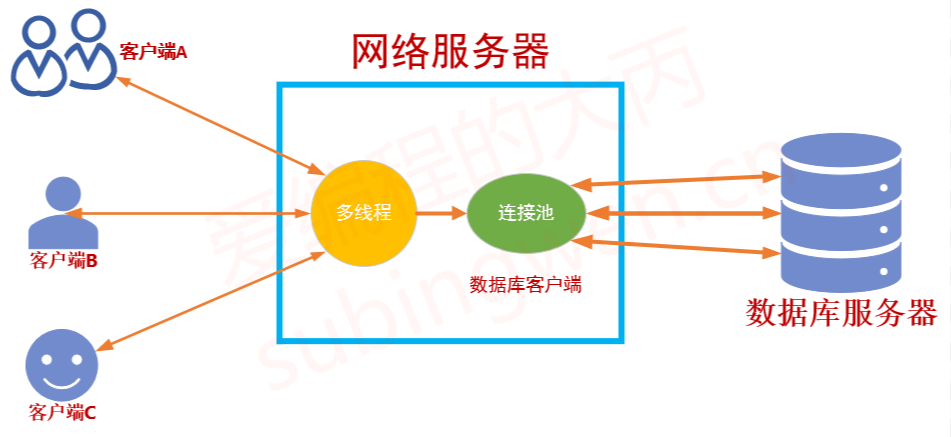
具体实现
- 连接池只需要一个实例,所以连接池类应该是一个单例模式的类
ConnectionPool *ConnectionPool::getConnectPool()
{
// 创建静态布局变量,访问范围就只有这个函数作用域,但是生命周期是到程序结束
// 第一次调用,会在创建内存地址,但是第二次就直接使用这个地址了,不会再次创建,就返回之前创建的实例了
// 这里使用的是单例模式中的懒汉模式,调用时创建
static ConnectionPool pool;
return &pool;
}
- 所有的数据库连接应该维护到一个队列中,使用队列的目的是方便连接的添加和删除
- 由于队列是连接池共享资源,需要使用互斥锁来保护队列数据的读写
- 由于数据库有连接上限,过多会压力过大,导致性能降低,所以需要设置一个最大连接上限;为了应对突然的高并发操作,需要设置一个最小连接数,这个最小连接数是维护队列的最小数量,保证有这么多连接供使用
- 客户端在满足条件的情况下,从连接池取连接,然后从进行使用,使用完毕后,归还这个连接,让这个连接重新加入队列中,不是销毁掉
- 因此队列存储的是一个数据库连接的对象,即
MYSQL*,为了便于使用,先封装一个MYSQL类,用于连接
封装数据库头文件
#pragma once
#include <iostream>
#include <mysql.h>
#include <chrono>
using namespace std;
using namespace chrono;
class MysqlConn
{
public:
// 初始化数据库连接
MysqlConn();
// 释放数据库连接
~MysqlConn();
// 连接数据库
bool connect(string user, string passwd, string dbName, string ip, unsigned short port = 3306);
// 更新数据库: insert, update, delete
bool update(string sql);
// 查询数据库 select 语句
bool query(string sql);
// 遍历查询得到的结果集
bool next();
// 得到结果集中的字段值
string value(int index);
// 事务操作
bool transaction();
// 提交事务
bool commit();
// 事务回滚
bool rollback();
// 刷新起始的空闲时间点
void refreshAliveTime();
// 计算连接存活的总时长
long long getAliveTime();
private:
void freeResult(); // 释放结果集内存
MYSQL *m_conn = nullptr; // 数据库对象
MYSQL_RES *m_result = nullptr; // select 查询后的结果集
MYSQL_ROW m_row = nullptr; // 用于遍历结果集,保存一行数据
steady_clock::time_point m_alivetime; // 创建绝对时钟
};
连接池头文件
#pragma once
#include <queue>
#include <mutex>
#include <condition_variable>
#include <thread>
#include "MysqlConn.h"
#include <atomic>
using namespace std;
class ConnectionPool
{
public:
// 设置静态方法,因为不能创建对象,所以设置为静态方法,通过类名获取这个数据库连接池实例
static ConnectionPool *getConnectPool();
// 删除拷贝构造函数和 "=" 操作符重载,因为要保证只有一个连接池实例
ConnectionPool(const ConnectionPool &obj) = delete;
ConnectionPool &operator=(const ConnectionPool &obj) = delete;
// 外部调用这个,取出一个数据库连接
shared_ptr<MysqlConn> getConnection();
~ConnectionPool();
private:
// 构造函数私有化,不允许外部创建,因为保持一个对象,单例模式
ConnectionPool();
// 解析 json数据
bool parseJsonFile();
// 创建新的连接的线程处理动作函数
void produceConnection();
// 销毁连接线程的线程处理动作函数
void recycleConnection();
// 增加连接
void addConnection();
string m_ip; // 数据发服务器的 IP地址
string m_user; // 数据库服务器用户名
string m_passwd; // 对应的密码
string m_dbName; // 数据库服务器上对应的数据库名
unsigned short m_port; // 数据库服务器端口号
int m_minSize; // 连接数量的最小值,这个是维护队列的最小值,保证突然的大量连接请求
int m_maxSize; // 连接数量的最大值,这个是队列数量 + m_busySize,表示最多只支持的连接数,包括了正在使用的
atomic<int> m_busySize; // 正在忙的连接数,这个是共享资源,设置为原子变量
int m_timeout; // 超时时长,当连接数用完后等待的阻塞时长
int m_maxIdleTime; // 最大空闲时长,决定是否断开这个数据库连接
// 连接池队列,存储的时是若干个数据库连接
queue<MysqlConn *> m_connectionQ;
mutex m_mutexQ; // 连接池队列的互斥锁
condition_variable m_cond; // 条件变量
};
构造函数
- 首先解析 json 格式数据,设置端口号和 IP
- 然后以最小连接数添加连接到队列
- 创建两个线程进行管理添加连接和销毁连接的实现
添加连接
- 这个使用一个线程单独维护,一直运行,除非连接池发送一个关闭信号
- 持续判断能否添加连接
// 创建新的连接
void ConnectionPool::produceConnection()
{
while (true)
{
if (isShutdown)
return;
// 最小连接数,保证队列里有最小连接数,即使不使用,应对突然的高数量访问
unique_lock<mutex> locker(m_mutexQ);
while (m_connectionQ.size() >= m_minSize || m_connectionQ.size() + m_busySize >= m_maxSize)
{
m_cond.wait(locker);
// 这个非常重要,如果是因为连接池关闭唤醒,直接退出
if (isShutdown)
return;
}
addConnection(); // 将连接加入队列 (封装的函数)
m_cond.notify_all(); // 唤醒阻塞在队列为空的线程
}
}
- 如果队列的数量比最小连接数大,就不需要添加连接
- 如果队列的连接数量 + 忙的连接 (正在被使用的) 超过了连接上限,就不需要往队列里生产连接了,即使此时队列的数量比最小连接数小,仍不能添加连接,因为添加连接后,客户端就能取,如果都取了,就超过连接上限了,因此维护的是队列连接数 + 忙的连接数要小于最大连接上限
- 也就是只有队列的数量比最小连接数小,并且此时队列的连接数量 + 忙的连接 (正在被使用的) 小于连接上限,才添加连接到队列
销毁连接
- 也是使用一个线程隔一段时间就进行检测,销毁的连接是队列中的空闲连接
- 因此取头部连接,计算它的存活时间,如果大于我们设定的值,就销毁这个连接,弹出队列,销毁它是因为它一直没被使用,属于空闲连接,只需一直销毁到保持有最小连接数即可
- 注意销毁弹出之前,需要满足队列的数量大于最小连接数,如果小于,就不进行这个操作
// 销毁连接
// 销毁的空闲连接,满足超过一定时长还是空闲就销毁
void ConnectionPool::recycleConnection()
{
while (true)
{
if (isShutdown)
return;
this_thread::sleep_for(chrono::milliseconds(500));
unique_lock<mutex> locker(m_mutexQ);
while (m_connectionQ.size() > m_minSize)
{
MysqlConn *conn = m_connectionQ.front();
// 存活的时间
if (conn->getAliveTime() >= m_maxIdleTime)
{
m_connectionQ.pop();
delete conn;
}
else
break;
}
}
}
取连接
- 首先需要检测这个队列是否为空,和现在忙的 (即正在使用的连接) 数量是否大于了连接上限,如果满足这二者之中的任何一个,都对其进行阻塞等待,不取连接
- 这个阻塞设置一个超时时间,如果满足上述二者只中一个,就阻塞,达到阻塞时长后,这个阻塞会解除,自己进行选择是退出还是继续进行阻塞
- 取连接后,由于这个连接不使用需要回收,重新加入队列中,因此需要保存这个连接,这个是一个指针,因此考虑共享智能指针维护,更安全
- 并且这个共享智能指针还有个功能,可以指定删除器函数,也就是这个指针生命周期结束后的指针处理,默认是清除智能指针指向的地址,由于这里不是进行销毁,我们需要重新加入队列,因此重定义删除器函数,使之为这个指针 (这个数据库连接)重新加入队列
// 外部调用这个,取出一个数据库连接
shared_ptr<MysqlConn> ConnectionPool::getConnection()
{
// 这个能判断四种情况
// 1. 如果没达到最大连接数请求,但是队列为空,阻塞
// 2. 如果没达到最大连接数请求,但是队列不为空,不阻塞
// 3. 如果达到最大连接数请求,但是队列不为空,阻塞
// 4. 如果达到最大连接s数请求,但是队列为空,阻塞
// 只要没达到最大连接数以及队列不为空,才能取连接,否则阻塞
// 设置的超时检测,超过时长没被唤醒,则继续执行 while 判断是否继续阻塞
unique_lock<mutex> locker(m_mutexQ);
while (m_connectionQ.empty() || (m_busySize >= m_maxSize))
{
// 阻塞指定的时间长度,时间到了就解除阻塞
if (cv_status::timeout == m_cond.wait_for(locker, chrono::milliseconds(m_timeout)))
{
// 进入这个 if 说明阻塞 m_timeout 这个时长,还是没有被唤醒
if (m_connectionQ.empty() || (m_busySize >= m_maxSize))
{
// 两种方式,continue继续阻塞,或者 return退出
// return nullptr;
continue;
}
}
}
// 使用共享的智能指针,回收当前连接用完后,重新 Push进队列中,自动回收
// 由于这个共享智能指针默认删除器处理动作是:回收这个智能指针指向的内存地址
// 但是我们不是要回收,我们是要重新加入队列,因此重新指定删除器函数
// 也就是第二个参数,这里使用 lambda方式实现
shared_ptr<MysqlConn> connptr(
m_connectionQ.front(),
[this](MysqlConn *conn)
{
unique_lock<mutex> locker(m_mutexQ);
// 更新加入队列的时间
conn->refreshAliveTime();
m_connectionQ.push(conn);
m_busySize--;
m_cond.notify_all(); // 唤醒因最大连接数阻塞的线程
});
m_connectionQ.pop();
m_busySize++;
// 本意是唤醒生产者线程,也就是唤醒创建新连接的线程
// 虽然会唤醒取连接的线程,但是不影响,它仍会继续阻塞
m_cond.notify_all();
return connptr;
}
解析 Json
- 为了不写死这个数据库连接的 IP 和端口号,这里使用 json 格式读取进去赋值
// 解析 json数据
bool ConnectionPool::parseJsonFile()
{
ifstream ifs("dbconf.json");
Reader rd;
Value root;
rd.parse(ifs, root);
if (root.isObject())
{
m_ip = root["ip"].asString();
m_port = root["port"].asInt();
m_user = root["userName"].asString();
m_passwd = root["password"].asString();
m_dbName = root["dbName"].asString();
m_minSize = root["minSize"].asInt();
m_maxSize = root["maxSize"].asInt();
m_maxIdleTime = root["maxIdleTime"].asInt();
m_timeout = root["timeout"].asInt();
m_busySize = 0;
return true;
}
return false;
}
说明: 参考学习 https://www.bilibili.com/video/BV1Fr4y1s7w4/?spm_id_from=333.999.0.0


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探