


Go 汇编学习笔记
0.前言
学习 Go 离不开看源码,源码又包含大量汇编代码,离开汇编是学不好 Go 的。同样,离开汇编去学习计算机是不完整的,汇编是基石,是离操作系统和硬件最近的一层。
虽然之前学过一点 Go 汇编,也写了博客,再回头看还是有些地方不理解,看完王爽老师的《汇编语言》部分内容豁然开朗,也加深了对 Go 汇编的理解。
本篇笔记结合王爽老师《汇编语言》和《Go 高级编程》部分内容,对理解进行总结,强化,加工再输出。
1.8086 汇编语言
注:王爽老师教材所用系统为 8086 16位体系架构,这里的举例环境为 X86 64 位体系架构:
Linux lubanseven 4.19.148-2.wf31.x86_64 #1 SMP Mon Oct 26 13:10:20 EET 2020 x86_64 x86_64 x86_64 GNU/Linux
1.1 计算机基础知识
计算机处理的语言称为机器语言,它是 0 和 1 组成的二进制序列。二进制序列难读,难写,难维护,后来在机器语言之上又加了一层汇编语言,它是一种注记语言,通过汇编器将汇编语言翻译为机器语言。对于程序员来说只用写汇编语言就能操作计算机。对于可复用的汇编代码,可抽象为公共库的形式,通过链接的方式生成机器代码。
因此,汇编顺序可记为:汇编 -> 编译 -> 链接 -> 机器码。
不管是机器语言还是汇编都需要操作寄存器和内存。通过指令将寄存器和内存串联起来即可实现 CPU 工作。指令集,寄存器和内存介绍如下。
1.1.1 指令集
完整的 X86 指令集:https://github.com/golang/arch/blob/master/x86/x86.csv
1.1.2 寄存器
寄存器是 CPU 的组成部分,它是有限存储容量的高速存储部件,可用来存储指令,数据和内存地址。
寄存器按类型可分为通用寄存器,指令寄存器,标志寄存器。
通用寄存器:
- ah/al = 8bits
- ax/bx = 16bits
- eax/ebx = 32bits
- rax/rbx = 64bits
- ...
指令寄存器:
- PC
- rip
标志寄存器:
- eflags
不同寄存器有特定的作用,可通过 dlv 的 regs 查看寄存器:

(dlv) regs Rip = 0x000000000046886f Rsp = 0x000000c000038780 Rax = 0x0000000000468860 Rbx = 0x0000000000000000 Rcx = 0x000000c000000180 Rdx = 0x0000000000484318 Rsi = 0x00007f2471803108 Rdi = 0x000000c00001a120 Rbp = 0x000000c0000387d0 R8 = 0x0000000000000000 R9 = 0x0000000000000000 ... Rflags = 0x0000000000000202 [IF IOPL=0] Es = 0x0000000000000000 Cs = 0x0000000000000033 Ss = 0x000000000000002b Ds = 0x0000000000000000 Fs = 0x0000000000000000 Gs = 0x0000000000000000
1.1.3 内存
内存是存储汇编代码和数据的存储器。程序中代码和数据要放在内存中存储,且要分段存储。即,代码存储在代码段,数据存储在数据段。为何要这样存储,一来程序简洁,二来段空间是有限的,指令通过 CS (基地址)和 IP(偏移地址)寄存器访问段空间(假设数据也放在代码段),而 IP 寄存器是有限位的,这一限制导致了偏移地址访问内存段不可能无限大。因此,分段是必须的。
程序分为代码段和数据段。在代码段中如果一条条执行指令,程序的复用性很差,引入 push/pushf 和 pop/popf 指令和栈(FILO)可实现在代码段中调用子代码段,子代码段在高级语言中也称为函数。
函数所使用的栈空间是从高地址到低地址分配的,寄存器 SS(基地址) 和 SP(偏移地址)记录了栈空间的内存位置。
指令是软件实现,寄存器和内存是物理实体。CPU 通过什么将寄存器和内存串联起来按照指令执行呢?
通过系统总线。根据总线位置可将总线分为内部总线和外部总线,根据总线类型可将总线分为地址总线,数据总线和控制总线。
地址总线负责传输地址,如 mov ax, [dx] 指令,将 ds(基地址) 和 dx 寄存器中存储的内存地址的内容传递给 ax,在传递过程中首先通过地址总线取 dx 的内存地址。在通过数据总线,将内存地址中存储的数据传输到 ax 中。
Ps: 理解了总线就能知道为什么数据从内存到内存传输是不行的,因为数据要经过总线,通过 CPU 根据指令读取内存数据到寄存器,再写入寄存器的数据到内存地址。
1.2 汇编指令
汇编指令集有很多,这里摘几个重点的介绍下指令背后的逻辑。
1.2.1 jmp
jmp 跳转指令,跳转指令实际上改变的是段偏移地址寄存器的值。跳转又可分为段内跳转和段间跳转,段间跳转改变的是段偏移地址(IP)和段基址寄存器 (CS) 的值。
1.2.2 cmp
cmp 比较指令,比较指令通过将操作数相减来改变 flag 寄存器的标志位。
cmp 指令常和逻辑判断指令结合,逻辑判断指令 (jnz/jnb/...) 通过检查 flag 寄存器标志位确定判断结果。
1.2.3 call 和 ret
汇编代码中通过 call 和 ret (不是必须的)实现子程序段的进入和返回。
call 可看作以下指令的合集:
push IP
jmp near ptr 标号
注意,jmp 标号可实现段内和段间地址跳转。如果是段间地址跳转 call 指令等于:
push CS
push IP
jmp far ptr 标号
ret 指令可看作:
pop IP(段内)
举例如下:
assume cs:code code segment start: mov ax, 1 mov cx, 3 call s mov bx, ax mov ax, 4c00h int 21h s: add ax, ax loop s ret code ends end start
执行流程如下:
- CPU 读入指令 call s,IP 加 2 指向指令 mov bx, ax。
- CPU 执行 call s,段内跳转。首先,将 IP 值 push 到栈上 (栈的位置通过 SS 基地址和 SP 偏移地址定位。SP–2 开辟空间给 IP,接着 IP 值存储到开辟空间) 。然后,执行 jmp near ptr s 跳转到子程序段 s 处。跳转到 s 处改变的是 IP 的值,CS 和 IP 共同定位指令执行位置。
- 当执行 s 到 ret 处,执行 pop IP 弹出栈上 IP 的值到 IP 寄存器,IP 的值指向的是 call 的下一条指令,从而实现子程序的返回和程序的执行。
2. Go 汇编
2.1 计算机结构
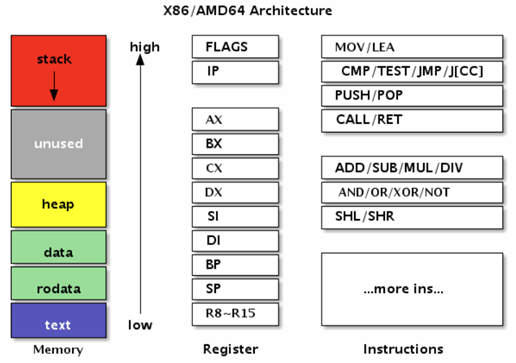
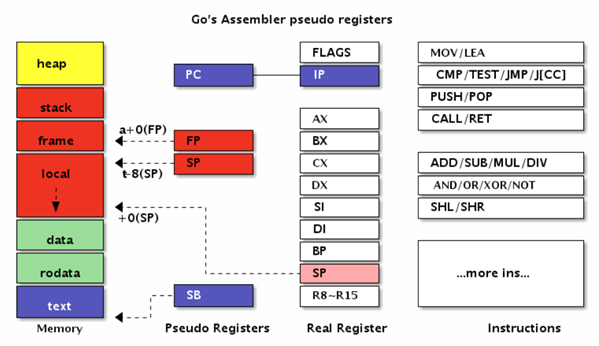
Go 汇编和 8086 汇编体系架构如下:
AMD64 架构 Go 汇编 AMD64 架构
其中:
- text: 内存区中的代码段
- rodata: 数据段,存储的是只读数据
- data: 数据段
Go 汇编代码新增四个伪寄存器 PC,FP,SP 和 SB 简化汇编代码的编写:
- FP: 使用形如 symbol+offset(FP) 的方式,引用函数的输入参数。例如 arg0+0(FP),arg1+8(FP),使用 FP 不加 symbol 时,无法通过编译,在汇编层面来讲,symbol 并没有什么用,加 symbol 主要是为了提升代码可读性。另外,官方文档虽然将伪寄存器 FP 称之为 frame pointer,实际上它根本不是 frame pointer,按照传统的 x86 的习惯来讲,frame pointer 是指向整个 stack frame 底部的 BP 寄存器。假如当前的 callee 函数是 add,在 add 的代码中引用 FP,该 FP 指向的位置不在 callee 的 stack frame 之内,而是在 caller 的 stack frame 上。
- PC: 实际上就是在体系结构的知识中常见的 pc 寄存器,在 x86 平台下对应 ip 寄存器,amd64 上则是 rip。
- SB: 全局静态基指针,一般用来声明函数或全局变量。
- SP: plan9 的这个 SP 寄存器指向当前栈帧的局部变量的开始位置,使用形如 symbol+offset(SP) 的方式,引用函数的局部变量。offset 的合法取值是 [-framesize, 0),注意是个左闭右开的区间。假如局部变量都是 8 字节,那么第一个局部变量就可以用 localvar0-8(SP) 来表示。这也是一个词不表意的寄存器。与硬件寄存器 SP 是两个不同的东西,在栈帧 size 为 0 的情况下,伪寄存器 SP 和硬件寄存器 SP 指向同一位置。手写汇编代码时,如果是 symbol+offset(SP) 形式,则表示伪寄存器 SP。如果是 offset(SP) 则表示硬件寄存器 SP。务必注意。对于编译输出(go tool compile -S / go tool objdump)的代码来讲,目前所有的 SP 都是硬件寄存器 SP,无论是否带 symbol。
2.2 函数调用
通过函数分析代码如下:
func main() { a, b := 1, 2 println(sum(a, b)) } func sum(x, y int) int { z := x + y return z }
通过 go tool compile -S -N -l 反汇编代码,其中 -N -l 指明编译器不优化汇编代码。汇编代码输出较多不易展开,这里逐段分析。
对于 main 函数段如下:
0x0000 00000 (main.go:3) TEXT "".main(SB), ABIInternal, $56-0 0x0000 00000 (main.go:3) MOVQ (TLS), CX 0x0009 00009 (main.go:3) CMPQ SP, 16(CX) 0x000d 00013 (main.go:3) PCDATA $0, $-2 0x000d 00013 (main.go:3) JLS 121 ... 0x0079 00121 (main.go:6) NOP 0x0079 00121 (main.go:3) PCDATA $1, $-1 0x0079 00121 (main.go:3) PCDATA $0, $-2 0x0079 00121 (main.go:3) CALL runtime.morestack_noctxt(SB) 0x007e 00126 (main.go:3) PCDATA $0, $-1 0x007e 00126 (main.go:3) NOP 0x0080 00128 (main.go:3) JMP 0
TEXT 段是声明段,SB 是静态基地址寄存器,$56-0 中 56 表示 main 函数帧栈大小,0 表示传入参数和返回值。
接着,MOVQ (TLS),CX 和 CMPQ SP,16(CX)比较函数帧栈空间是否足够,如果不足执行 JLS 跳到 121 行,121 行执行的是 runtime.morestack_noctxt 函数,该函数为 main 帧栈开辟栈空间,开辟完栈空间后执行 JMP 0 跳转到 main 函数处继续判断栈空间是否足够,重复上述过程,直到空间足够。
这里有几个问题需要再详细了解下:
- MOVQ (TLS),CX 和 CMPQ SP,16(CX)是怎么比较栈空间的?
- 什么情况会出现栈空间不足?
分别讨论这两个问题。
问题1:
MOVQ (TLS), CX 负责加载 g 结构体指针,CMPQ SP, 16(CX) 将栈指针 SP 和 g 结构体的 stackgroud0 成员比较,如果比较结果小于 0 说明栈空间不足,跳到 runtime.morestack_noctxt 开辟栈空间。
通过 dlv debug 查看这一过程:
(dlv) disassemble TEXT main.main(SB) /root/go/src/spec/asm/main.go main.go:3 0x468860 64488b0c25f8ffffff mov rcx, qword ptr fs:[0xfffffff8] main.go:3 0x468869 483b6110 cmp rsp, qword ptr [rcx+0x10] ... main.go:3 0x46886d 766a jbe 0x4688d9 main.go:3 0x4688d9 e802b0ffff call $runtime.morestack_noctxt
寄存器 rsp 和 rcx 的值为:
(dlv) regs Rsp = 0x000000c000038780 Rcx = 0x000000c000000180
注意,rcx 表示的是偏移地址,和 rsp 地址比较的是偏移地址 rcx 和基地址的地址。
问题2:
一个典型的场景是调用递归函数时栈空间不足。调用递归时,编译器无法事先预知递归函数函数栈大小,在递归调用时,会动态分配函数栈。
举例:
func main() { println(sum(100)) } func sum(n int) int { if n > 0 { return n + sum(n-1) } else { return 0 } }
执行函数得到结果 5050。当给函数 sum 加上 nosplit 限制后,程序执行将报错:
//go:nosplit func sum(n int) int { ... } $ go run main.go # command-line-arguments main.sum: nosplit stack overflow 792 assumed on entry to main.sum (nosplit) 768 after main.sum (nosplit) uses 24 760 on entry to main.sum (nosplit) ...
错误原因是加上 nosplit,即声明该函数不允许扩栈,当栈内存不足时程序将报错。查看反汇编代码:
"".sum STEXT nosplit size=103 args=0x10 locals=0x20 funcid=0x0 0x0000 00000 (main.go:16) TEXT "".sum(SB), NOSPLIT|ABIInternal, $32-16 0x0000 00000 (main.go:16) SUBQ $32, SP 0x0004 00004 (main.go:16) MOVQ BP, 24(SP) 0x0009 00009 (main.go:16) LEAQ 24(SP), BP ...
从反汇编代码可以看出,比较栈大小和开辟栈空间指令被禁用了。
继续查看 go 汇编代码:
0x000f 00015 (main.go:3) PCDATA $0, $-1 0x001d 00029 (main.go:3) FUNCDATA $0,
PCDATA 用于生成 PC 表格,通过 PC 表格可以查询指令对应的函数和位置信息。
FUNCDATA 生成 FUNC 表格,用于记录函数的参数、局部变量的指针信息。
(详细描述可参考这里)
接着看代码:
0x000f 00015 (main.go:3) SUBQ $56, SP 0x0013 00019 (main.go:3) MOVQ BP, 48(SP) 0x0018 00024 (main.go:3) LEAQ 48(SP), BP
当栈空间足够时,继续往下执行。首先,SP 栈偏移寄存器减 $56,注意这里的 SP 是真寄存器,栈是从高地址到低地址增长的,减 $56 表示开辟 56 字节的内存空间。
开辟空间后,将 BP 寄存器作为 main 函数栈的栈底。首先,将原 BP 寄存器的值移动到 48(SP)处,48(SP)表示寄存器值加 48。然后,通过 LEAQ 指令将 48(SP)的地址赋给 BP 寄存器。
通过 dlv debug 查看这一过程如下:
=> main.go:3 0x46886f* 4883ec38 sub rsp, 0x38 (dlv) regs Rsp = 0x000000c000038780 Rbp = 0x000000c0000387d0 main.go:3 0x46886f* 4883ec38 sub rsp, 0x38 main.go:3 0x468873 48896c2430 mov qword ptr [rsp+0x30], rbp main.go:3 0x468878 488d6c2430 lea rbp, ptr [rsp+0x30] => main.go:4 0x46887d 48c744242001000000 mov qword ptr [rsp+0x20], 0x1 (dlv) regs Rsp = 0x000000c000038748 Rbp = 0x000000c000038778 (dlv) print *(*int)(uintptr(0x000000c000038778)) 824633952208
从上述过程可以看出:
- sub rsp, 0x38 指令将 rsp 寄存器的值减 0x38,0x38是 $56 的十六进制表示。rsp 的值从 0x000000c000038780 变为 0x000000c000038748(0x000000c000038780-0x38)。
- mov qword ptr [rsp+0x30], rbp 指令将 rbp 的值 0x000000c0000387d0 存到[rsp+0x30](内存地址 0x000000c000038778)。
- lea rbp, ptr [rsp+0x30] 将地址0x000000c000038778 存到 rbp 中。此时,rbp 指向的内存地址的值为原 rbp 的值。打印 rbp 内存地址的值为 824633952208,该值即是 0x000000c0000387d0 的十进制表示。
接着往下走:
4: a, b := 1, 2 => 5: println(sum(a, b)) 6: } main.go:4 0x46887d 48c744242001000000 mov qword ptr [rsp+0x20], 0x1 main.go:4 0x468886 48c744241802000000 mov qword ptr [rsp+0x18], 0x2 => main.go:5 0x46888f 488b442420 mov rax, qword ptr [rsp+0x20]
执行赋值语句 a,b := 1, 2 后,汇编指令执行了 mov qword ptr [rsp+0x20], 0x1 和 mov qword ptr [rsp+0x18], 0x2,不难看出该指令是将 1 和 2 分别赋值到 [rsp+0x20] 和 [rsp+0x28]。已知 rsp 寄存器的值,可打印变量 a 和 b:
(dlv) print *(*int)(uintptr(0x000000c000038768)) 1 (dlv) print *(*int)(uintptr(0x000000c000038760)) 2
接着在 main.sum 处添加断点,next 执行到 main.sum:
(dlv) break main.sum Breakpoint 2 set at 0x468900 for main.sum() ./main.go:8 (dlv) next => 8: func sum(x, y int) int { (dlv) disassemble TEXT main.sum(SB) /root/go/src/spec/asm/main.go => main.go:8 0x468900* 4883ec10 sub rsp, 0x10 (dlv) regs Rsp = 0x000000c000038740
执行到 main.sum 可以看到 rsp 寄存器的值变成 0x000000c000038740,这是因为执行 call 指令时CPU 在栈上开辟了 8Bytes 存储 IP 寄存器的值,该值指向 call 下一条指令。
在执行到 main.sum 之前有几条指令是已经执行完了,如下:
main.go:5 0x46888f 488b442420 mov rax, qword ptr [rsp+0x20] main.go:5 0x468894 48890424 mov qword ptr [rsp], rax main.go:5 0x468898 48c744240802000000 mov qword ptr [rsp+0x8], 0x2
这三条指令是将 a, b 的内容拷贝到内存空间 [rsp+0x8] 和 [rsp] 中。 该内容即是函数 sum 的形参,形参是在 caller 函数的帧栈上分配的。
继续执行 next:
main.go:8 0x468900* 4883ec10 sub rsp, 0x10 main.go:8 0x468904 48896c2408 mov qword ptr [rsp+0x8], rbp main.go:8 0x468909 488d6c2408 lea rbp, ptr [rsp+0x8] main.go:8 0x46890e 48c744242800000000 mov qword ptr [rsp+0x28], 0x0 => main.go:9 0x468917 488b442418 mov rax, qword ptr [rsp+0x18]
和 main 帧栈类似。首先,将 rsp 减 0x10 开辟 16Bytes 内存空间。然后,将 rbp 作为 sum 帧栈的栈底。接着 mov qword ptr [rsp+0x28], 0x0 将 0 赋给内存空间 [rsp+0x28],[rsp+0x28] 是 main 帧栈的内存空间,其位置存放的是 sum 函数的返回值。
接着执行 next:
main.go:9 0x468917 488b442418 mov rax, qword ptr [rsp+0x18] main.go:9 0x46891c 4803442420 add rax, qword ptr [rsp+0x20] main.go:9 0x468921 48890424 mov qword ptr [rsp], rax => main.go:10 0x468925 4889442428 mov qword ptr [rsp+0x28], rax
可以看出 z := x + y 是将形参相加,相加结果通过 rax 寄存器存放到 [rsp] 处。这里,由于rsp 的位置变动了,相应的索引形参的内存地址也变成 [rsp+0x18] 和 [rsp+0x20] 而不是原始的 [rsp] 和 [rsp+0x8] 。其中,[rsp] 为 sum 帧栈局部变量 z 的内存地址。
继续执行 next:
(dlv) next > main.main() ./main.go:5 (PC: 0x4688a6) 4: a, b := 1, 2 => 5: println(sum(a, b)) main.go:5 0x4688a1 e85a000000 call $main.sum => main.go:5 0x4688a6 488b442410 mov rax, qword ptr [rsp+0x10]
函数执行到 call 指令的下一条指令,sum 执行的指令如下:
main.go:10 0x468925 4889442428 mov qword ptr [rsp+0x28], rax main.go:10 0x46892a 488b6c2408 mov rbp, qword ptr [rsp+0x8] main.go:10 0x46892f 4883c410 add rsp, 0x10 main.go:10 0x468933 c3 ret
首先,将形参相加的值存到 main 帧栈的返回空间 [rsp+0x28] 中。
然后,恢复 rbp 寄存器的原存储值,将 rsp 加 0x10 回收 sum 帧栈。从这里也可以看出,回收帧栈只是做了 rsp 寄存器的加法,并未清空 sum 帧栈存储的值。一个简单的实验是,即使 sum 帧栈回收了,我们还是可以拿到 sum 中局部变量 z 的值:
(dlv) print *(*int)(uintptr(0x000000c000038730)) 3
最后,执行 ret 指令,将栈上 IP 指令寄存器的值弹出并放到 IP 寄存器中。CPU 通过 CS(基地址) 和 IP(偏移地址)定位到指令 mov rax,qword ptr [rsp+0x10] ,从而实现函数的调用。
main 函数继续往下执行,对返回值进行处理,这里我们不继续执行了。读者应该能自行看出 main 对返回值做了什么操作了,这里只强调一点函数返回值的传递也是传值。
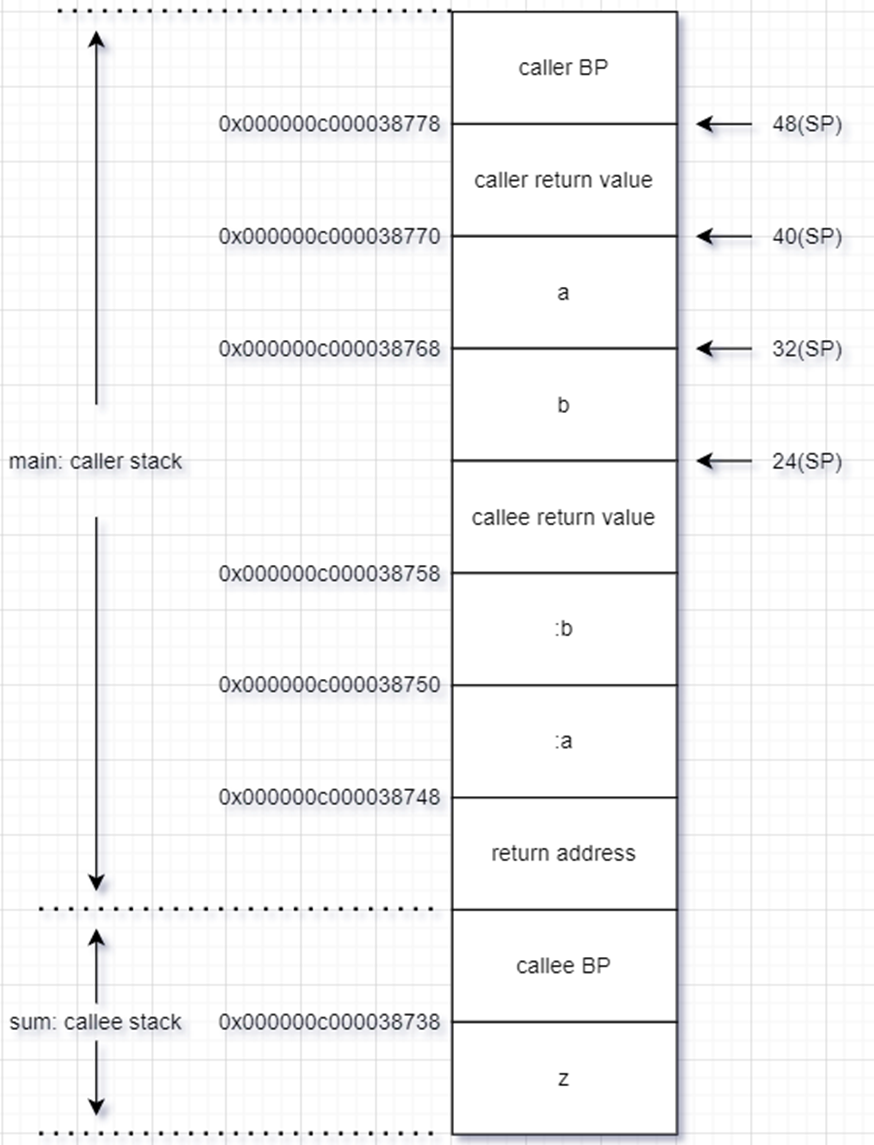
通过上述函数调用过程,画出 main 和 sum 帧栈结构图如下:
3. 引用
《Go 高级编程》:https://books.studygolang.com/advanced-go-programming-book/ch3-asm/readme.html
Go 汇编 layout:https://github.com/cch123/asmshare/blob/master/layout.md
Go 语言内联函数:https://segmentfault.com/a/1190000040399875



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2020-07-12 KVM 管理工具:libvirt