

Deployment 和 StatefulSets 概述
这篇概述是看文章提到的一段话 xxx is not targeted to be horizontally scalable 引发的,遂整理记录在这里。
起因是有两个应用,一个是无状态的,可以 horizontally scalable,另一个是有状态的,和数据库绑定,horizontally scalable。无状态的应用配成 Deployment, 有状态的应用配成 StatefulSets。
引发的思考是:有状态的应用怎么和数据库绑定以及扩展有状态应用会发生什么?带着这个问题开始了学习,并且整理如下。
Deployment 和 StatefulSets 控制器
介绍这两种控制器之前,先说下 Pod。Pod 是对 container 的一层封装,它的结构体定义可以看 这里:
// Pod is a collection of containers that can run on a host. This resource is created
// by clients and scheduled onto hosts.
type Pod struct {
metav1.TypeMeta `json:",inline"`
...
}
直接对 container 控制是很难控制的,比如扩展伸缩,网络管理等。所以,kubernetes 引入了 Pod 结构体作为最小的细粒度单元进行管理。在
深入剖析 Kubernetes 中将 container 比喻为集装箱,将 Pod 比喻为集装箱上的"抓手",这个比喻是很合理的。
那对于"抓手"用什么去抓呢?所谓的,起重机是哪个?
控制器就是这个起重机,在 Kubernetes 中控制器负责 Pod 的扩展伸缩等一系列控制,之所以是一系列是因为控制器不是一种,每种控制器负责不同的控制操作,它们都属于 kube controller manager
组件下定义的控制器,不同控制器可看 这里。控制器遵循通用的循环控制编排模式,其伪代码实现如下:
for {
acutalStatus := x.getPodActualStatus
expectStatus := x.getPodExpectStatus
if acutalStatus != expectStatus {
doControllerAction(...) // change the actual status to expected status
else
doNothing
}
}
对于 Pod 的扩展伸缩,编排控制器有 replicationcontrollers,它直接对 Pod 进行控制,当 Pod 期望数量和实际数量不一致时,扩展 Pod 实际数量到期望数量。反之亦然。
不过在用 replicationcontrollers 进行控制时有个问题,就是无法做到对 Pod 滚动更新的支持。试想 replicationcontrollers 控制器 A 直接控制 pod b,当 pod b 更新到
pod c 时,A 直接控制 c。如果此时想回去 b 就回不去了,因为 A 直接控制的是 c。
Kubernetes 引入了 Deployment 和 ReplicaSets 来支持滚动更新。Deployment 控制 replicasets,再由 ReplicaSets 控制 pod。ReplicaSets 对 pod 的控制是直接的,Deployment 对于
pod 的控制是间接的(可以通过 ownerReference field 查看对象所属的 owner)。
可由一张图解释这一控制过程:
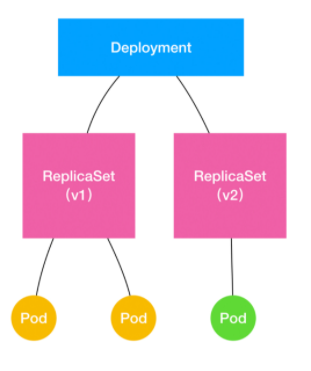
Deployment 控制 ReplicaSet(v1), ReplicaSet(v1) 控制 pod。当做滚动更新时,Deployment 创建新的 ReplicaSet(v2),由 v2 创建新版本 pod,并且 v1 删除旧版本 pod(这里涉及到 pod
滚动更新策略,不细讲)。最终,滚动更新的新 pod 由 v2 控制,而旧的 ReplicaSet v1 还在,当需要回滚时,旧的 pod 会再次被 ReplicaSet 创建。
至此,Pod 的扩展伸缩和滚动更新都做好了。
不过,还有一个问题。不管 Deployment 还是 ReplicationController 其管理的 pod 都是无状态的。默认 pod 都是一样的,而实际应用往往对 pod 的要求是有状态的。
比如 Pod 需要依赖特定数据库,比如 pod 有主备之分等情况,都没办法让这类 pod 由 Deployment 管理。
基于此,kubernetes 引入了 StatefulSets 控制器,顾名思义,它是对有状态 Pod 的管理。
StatefulSets 通过两点实现有状态 Pod 的管理:
- 拓扑状态:通过 service + pod 的形式找到每个 pod 的 ip,当 pod 删掉再重建之后 Kubernetes 还是能给它配置原来的 ip。
- 存储状态:通过 pvc 的形式将 pod 和 pvc 绑定,当 pod 扩展伸缩时,相应的 pvc 也会动态扩展伸缩。
对于第一点和第二点,在扩展讲一点,详细内容可看这里。
拓扑状态
# nslookup yyy.luban.svc.cluster.local
Server: 172.17.7.2
Address: 172.17.7.2#53
Name: yyy.luban.svc.cluster.local
Address: 10.10.xxx.xxx
# kubectl get endpoints -n luban | grep yyy
yyy 10.10.xxx.xxx
其中, yyy 是创建的 headless service,通过 DNS 解析出它对应的 endpoints,10.10.xxx.xxx 是对应的 pod ip。
存储状态
在 yaml 文件中添加 volumeClaimTemplates 模板定义 pod 绑定的 pvc:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
...
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
其中,pvc 将和 pod 一一绑定,扩展 pod 数,相应的 pvc 也会扩展:
$ kubectl get statefulsets.apps
NAME READY AGE
web 2/2 2m16s
$ kubectl edit statefulsets.apps
statefulset.apps/web edited
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2m38s
web-1 1/1 Running 0 90s
web-2 0/1 ContainerCreating 0 4s
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pvc-53b1361a-dc5f-4722-ae92-48dafd0717cb 1Gi RWO standard 2m43s
www-web-1 Bound pvc-332fa158-ecd9-4d3a-ada4-497b2bae1b3a 1Gi RWO standard 95s
www-web-2 Bound pvc-d5c1eb0c-ad91-4095-9da7-1876b1dfa135 1Gi RWO standard 9s

