kubernetes 资源简介
什么是资源?
在 kubernetes 中,有两个基础但是非常重要的概念:node 和 pod。node 翻译成节点,是对集群资源的抽象;pod 是对容器的封装,是应用运行的实体。node 提供资源,而 pod 使用资源,这里的资源分为计算(cpu、memory、gpu)、存储(disk、ssd)、网络(network bandwidth、ip、ports)。这些资源提供了应用运行的基础,正确理解这些资源以及集群调度如何使用这些资源,对于大规模的 kubernetes 集群来说至关重要,不仅能保证应用的稳定性,也可以提高资源的利用率。
在这篇文章,我们主要介绍 CPU 和内存这两个重要的资源,它们虽然都属于计算资源,但也有所差距。CPU 可分配的是使用时间,也就是操作系统管理的时间片,每个进程在一定的时间片里运行自己的任务(另外一种方式是绑核,也就是把 CPU 完全分配给某个 pod 使用,但这种方式不够灵活会造成严重的资源浪费,kubernetes 中并没有提供);而对于内存,系统提供的是内存大小。
CPU 的使用时间是可压缩的,换句话说它本身无状态,申请资源很快,也能快速正常回收;而内存大小是不可压缩的,因为它是有状态的(内存里面保存的数据),申请资源很慢(需要计算和分配内存块的空间),并且回收可能失败(被占用的内存一般不可回收)。
把资源分成可压缩和不可压缩,是因为在资源不足的时候,它们的表现很不一样。对于不可压缩资源,如果资源不足,也就无法继续申请资源(内存用完就是用完了),并且会导致 pod 的运行产生无法预测的错误(应用申请内存失败会导致一系列问题);而对于可压缩资源,比如 CPU 时间片,即使 pod 使用的 CPU 资源很多,CPU 使用也可以按照权重分配给所有 pod 使用,虽然每个人使用的时间片减少,但不会影响程序的逻辑。
在 kubernetes 集群管理中,有一个非常核心的功能:就是为 pod 选择一个主机运行。调度必须满足一定的条件,其中最基本的是主机上要有足够的资源给 pod 使用。
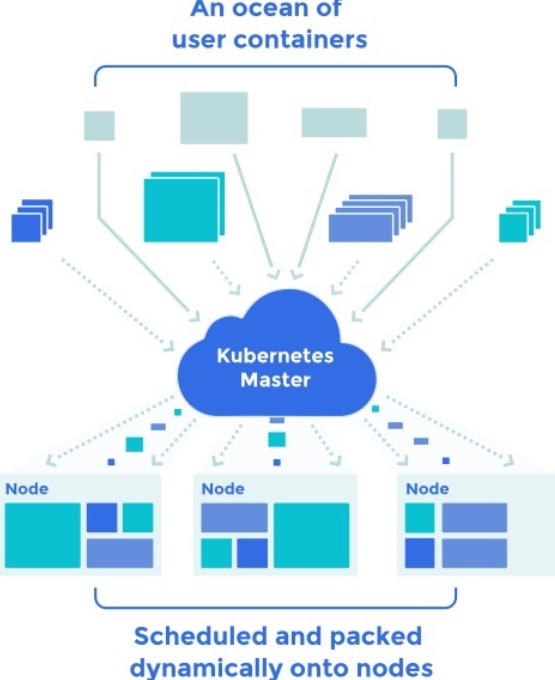
<p>资源除了和调度相关之外,还和很多事情紧密相连,这正是这篇文章要解释的。</p>
<h3 id="kubernetes-资源的表示"><a href="#kubernetes-资源的表示" class="headerlink" title="kubernetes 资源的表示"></a>kubernetes 资源的表示</h3><p>用户在 pod 中可以配置要使用的资源总量,kubernetes 根据配置的资源数进行调度和运行。目前主要可以配置的资源是 CPU 和 memory,对应的配置字段是 <code>spec.containers[].resource.limits/request.cpu/memory</code>。</p>
<p>需要注意的是,用户是对每个容器配置 request 值,所有容器的资源请求之和就是 pod 的资源请求总量,而我们一般会说 pod 的资源请求和 limits。</p>
<p><code>limits</code> 和 <code>requests</code> 的区别我们下面会提到,这里先说说比较容易理解的 cpu 和 memory。</p>
<p><code>CPU</code> 一般用核数来标识,一核CPU 相对于物理服务器的一个超线程核,也就是操作系统 <code>/proc/cpuinfo</code> 中列出来的核数。因为对资源进行了池化和虚拟化,因此 kubernetes 允许配置非整数个的核数,比如 <code>0.5</code> 是合法的,它标识应用可以使用半个 CPU 核的计算量。CPU 的请求有两种方式,一种是刚提到的 <code>0.5</code>,<code>1</code> 这种直接用数字标识 CPU 核心数;另外一种表示是 <code>500m</code>,它等价于 <code>0.5</code>,也就是说 <code>1 Core = 1000m</code>。</p>
<p>内存比较容易理解,是通过字节大小指定的。如果直接一个数字,后面没有任何单位,表示这么多字节的内存;数字后面还可以跟着单位, 支持的单位有 <code>E</code>、<code>P</code>、<code>T</code>、<code>G</code>、<code>M</code>、<code>K</code>,前者分别是后者的 <code>1000</code> 倍大小的关系,此外还支持 <code>Ei</code>、<code>Pi</code>、<code>Ti</code>、<code>Gi</code>、<code>Mi</code>、<code>Ki</code>,其对应的倍数关系是 <code>2^10 = 1024</code>。比如要使用 100M 内存的话,直接写成 <code>100Mi</code>即可。</p>
<h3 id="节点可用资源"><a href="#节点可用资源" class="headerlink" title="节点可用资源"></a>节点可用资源</h3><p>理想情况下,我们希望节点上所有的资源都可以分配给 pod 使用,但实际上节点上除了运行 pods 之外,还会运行其他的很多进程:系统相关的进程(比如 sshd、udev等),以及 kubernetes 集群的组件(kubelet、docker等)。我们在分配资源的时候,需要给这些进程预留一些资源,剩下的才能给 pod 使用。预留的资源可以通过下面的参数控制:</p>
<ul>
<li><code>--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi]</code>:控制预留给 kubernetes 集群组件的 CPU、memory 和存储资源</li>
<li><code>--system-reserved=[cpu=100mi][,][memory=100Mi][,][ephemeral-storage=1Gi]</code>:预留给系统的 CPU、memory 和存储资源</li>
</ul>
<p>这两块预留之后的资源才是 pod 真正能使用的,不过考虑到 eviction 机制(下面的章节会提到),kubelet 会保证节点上的资源使用率不会真正到 100%,因此 pod 的实际可使用资源会稍微再少一点。主机上的资源逻辑分配图如下所示:</p>
<p><img src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxoxsulyj31b10qo76a.jpg" alt="kubernetes reserved resource" class="post-img" data-src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxoxsulyj31b10qo76a.jpg"></p>
<p><strong>NOTE:</strong>需要注意的是,allocatable 不是指当前机器上可以分配的资源,而是指能分配给 pod 使用的资源总量,一旦 kubelet 启动这个值是不会变化的。</p>
<p>allocatable 的值可以在 node 对象的 <code>status</code> 字段中读取,比如下面这样:</p>
<pre class=" language-yaml"><code class="language-yaml"><span class="token key atrule">status</span><span class="token punctuation">:</span>
<span class="token key atrule">allocatable</span><span class="token punctuation">:</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"2"</span>
<span class="token key atrule">ephemeral-storage</span><span class="token punctuation">:</span> <span class="token string">"35730597829"</span>
<span class="token key atrule">hugepages-2Mi</span><span class="token punctuation">:</span> <span class="token string">"0"</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> 3779348Ki
<span class="token key atrule">pods</span><span class="token punctuation">:</span> <span class="token string">"110"</span>
<span class="token key atrule">capacity</span><span class="token punctuation">:</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"2"</span>
<span class="token key atrule">ephemeral-storage</span><span class="token punctuation">:</span> 38770180Ki
<span class="token key atrule">hugepages-2Mi</span><span class="token punctuation">:</span> <span class="token string">"0"</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> 3881748Ki
<span class="token key atrule">pods</span><span class="token punctuation">:</span> <span class="token string">"110"</span>
</code></pre>
<h2 id="kubernetes-资源对象"><a href="#kubernetes-资源对象" class="headerlink" title="kubernetes 资源对象"></a>kubernetes 资源对象</h2><p>在这部分,我们来介绍 kubernetes 中提供的让我们管理 pod 资源的原生对象。</p>
<h3 id="请求(requests)和上限(limits)"><a href="#请求(requests)和上限(limits)" class="headerlink" title="请求(requests)和上限(limits)"></a>请求(requests)和上限(limits)</h3><p>前面说过用户在创建 pod 的时候,可以指定每个容器的 Requests 和 Limits 两个字段,下面是一个实例:</p>
<pre class=" language-yaml"><code class="language-yaml"><span class="token key atrule">resources</span><span class="token punctuation">:</span>
<span class="token key atrule">requests</span><span class="token punctuation">:</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> <span class="token string">"64Mi"</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"250m"</span>
<span class="token key atrule">limits</span><span class="token punctuation">:</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> <span class="token string">"128Mi"</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"500m"</span>
</code></pre>
<p><code>Requests</code> 是容器请求要使用的资源,kubernetes 会保证 pod 能使用到这么多的资源。请求的资源是调度的依据,只有当节点上的可用资源大于 pod 请求的各种资源时,调度器才会把 pod 调度到该节点上(如果 CPU 资源足够,内存资源不足,调度器也不会选择该节点)。</p>
<p>需要注意的是,调度器只关心节点上可分配的资源,以及节点上所有 pods 请求的资源,而<strong>不关心</strong>节点资源的实际使用情况,换句话说,如果节点上的 pods 申请的资源已经把节点上的资源用满,即使它们的使用率非常低,比如说 CPU 和内存使用率都低于 10%,调度器也不会继续调度 pod 上去。</p>
<p> <code>Limits</code> 是 pod 能使用的资源上限,是实际配置到内核 cgroups 里面的配置数据。对于内存来说,会直接转换成 <code>docker run</code> 命令行的 <code>--memory</code> 大小,最终会配置到 cgroups 对应任务的 <code>/sys/fs/cgroup/memory/……/memory.limit_in_bytes</code> 文件中。</p>
<p> <strong>NOTE</strong>:如果 limit 没有配置,则表明没有资源的上限,只要节点上有对应的资源,pod 就可以使用。</p>
<p>使用 requests 和 limits 概念,我们能分配更多的 pod,提升整体的资源使用率。但是这个体系有个非常重要的问题需要考虑,那就是<strong>怎么去准确地评估 pod 的资源 requests</strong>?如果评估地过低,会导致应用不稳定;如果过高,则会导致使用率降低。这个问题需要开发者和系统管理员共同讨论和定义。</p>
<h3 id="limit-range(默认资源配置"><a href="#limit-range(默认资源配置" class="headerlink" title="limit range(默认资源配置)"></a>limit range(默认资源配置)</h3><p>为每个 pod 都手动配置这些参数是挺麻烦的事情,kubernetes 提供了 <code>LimitRange</code> 资源,可以让我们配置某个 namespace 默认的 request 和 limit 值,比如下面的实例:</p>
<pre class=" language-yaml"><code class="language-yaml"><span class="token key atrule">apiVersion</span><span class="token punctuation">:</span> <span class="token string">"v1"</span>
<span class="token key atrule">kind</span><span class="token punctuation">:</span> <span class="token string">"LimitRange"</span>
<span class="token key atrule">metadata</span><span class="token punctuation">:</span>
<span class="token key atrule">name</span><span class="token punctuation">:</span> you<span class="token punctuation">-</span>shall<span class="token punctuation">-</span>have<span class="token punctuation">-</span>limits
<span class="token key atrule">spec</span><span class="token punctuation">:</span>
<span class="token key atrule">limits</span><span class="token punctuation">:</span>
<span class="token punctuation">-</span> <span class="token key atrule">type</span><span class="token punctuation">:</span> <span class="token string">"Container"</span>
<span class="token key atrule">max</span><span class="token punctuation">:</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"2"</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> <span class="token string">"1Gi"</span>
<span class="token key atrule">min</span><span class="token punctuation">:</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"100m"</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> <span class="token string">"4Mi"</span>
<span class="token key atrule">default</span><span class="token punctuation">:</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"500m"</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> <span class="token string">"200Mi"</span>
<span class="token key atrule">defaultRequest</span><span class="token punctuation">:</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"200m"</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> <span class="token string">"100Mi"</span>
</code></pre>
<p>如果对应 namespace 创建的 pod 没有写资源的 requests 和 limits 字段,那么它会自动拥有下面的配置信息:</p>
<ul>
<li>内存请求是 100Mi,上限是 200Mi</li>
<li>CPU 请求是 200m,上限是 500m</li>
</ul>
<p>当然,如果 pod 自己配置了对应的参数,kubernetes 会使用 pod 中的配置。使用 LimitRange 能够让 namespace 中的 pod 资源规范化,便于统一的资源管理。</p>
<h3 id="资源配额(resource-quota)"><a href="#资源配额(resource-quota)" class="headerlink" title="资源配额(resource quota)"></a>资源配额(resource quota)</h3><p>前面讲到的资源管理和调度可以认为 kubernetes 把这个集群的资源整合起来,组成一个资源池,每个应用(pod)会自动从整个池中分配资源来使用。默认情况下只要集群还有可用的资源,应用就能使用,并没有限制。kubernetes 本身考虑到了多用户和多租户的场景,提出了 namespace 的概念来对集群做一个简单的隔离。</p>
<p>基于 namespace,kubernetes 还能够对资源进行隔离和限制,这就是 resource quota 的概念,翻译成资源配额,它限制了某个 namespace 可以使用的资源总额度。这里的资源包括 cpu、memory 的总量,也包括 kubernetes 自身对象(比如 pod、services 等)的数量。通过 resource quota,kubernetes 可以防止某个 namespace 下的用户不加限制地使用超过期望的资源,比如说不对资源进行评估就大量申请 16核 CPU 32G内存的 pod。</p>
<p>下面是一个资源配额的实例,它限制了 namespace 只能使用 20核 CPU 和 1G 内存,并且能创建 10 个 pod、20个 rc、5个 service,可能适用于某个测试场景。</p>
<pre class=" language-yaml"><code class="language-yaml"><span class="token key atrule">apiVersion</span><span class="token punctuation">:</span> v1
<span class="token key atrule">kind</span><span class="token punctuation">:</span> ResourceQuota
<span class="token key atrule">metadata</span><span class="token punctuation">:</span>
<span class="token key atrule">name</span><span class="token punctuation">:</span> quota
<span class="token key atrule">spec</span><span class="token punctuation">:</span>
<span class="token key atrule">hard</span><span class="token punctuation">:</span>
<span class="token key atrule">cpu</span><span class="token punctuation">:</span> <span class="token string">"20"</span>
<span class="token key atrule">memory</span><span class="token punctuation">:</span> 1Gi
<span class="token key atrule">pods</span><span class="token punctuation">:</span> <span class="token string">"10"</span>
<span class="token key atrule">replicationcontrollers</span><span class="token punctuation">:</span> <span class="token string">"20"</span>
<span class="token key atrule">resourcequotas</span><span class="token punctuation">:</span> <span class="token string">"1"</span>
<span class="token key atrule">services</span><span class="token punctuation">:</span> <span class="token string">"5"</span>
</code></pre>
<p>resource quota 能够配置的选项还很多,比如 GPU、存储、configmaps、persistentvolumeclaims 等等,更多信息可以参考<a href="****">官方的文档</a>。</p>
<p>Resource quota 要解决的问题和使用都相对独立和简单,但是它也有一个限制:那就是它不能根据集群资源动态伸缩。一旦配置之后,resource quota 就不会改变,即使集群增加了节点,整体资源增多也没有用。kubernetes 现在没有解决这个问题,但是用户可以通过编写一个 controller 的方式来自己实现。</p>
<h2 id="应用优先级"><a href="#应用优先级" class="headerlink" title="应用优先级"></a>应用优先级</h2><h3 id="QoS(服务质量)"><a href="#QoS(服务质量)" class="headerlink" title="QoS(服务质量)"></a>QoS(服务质量)</h3><p>Requests 和 limits 的配置除了表明资源情况和限制资源使用之外,还有一个隐藏的作用:它决定了 pod 的 QoS 等级。</p>
<p>上一节我们提到了一个细节:如果 pod 没有配置 limits ,那么它可以使用节点上任意多的可用资源。这类 pod 能灵活使用资源,但这也导致它不稳定且危险,对于这类 pod 我们一定要在它占用过多资源导致节点资源紧张时处理掉。优先处理这类 pod,而不是资源使用处于自己请求范围内的 pod 是非常合理的想法,而这就是 pod QoS 的含义:根据 pod 的资源请求把 pod 分成不同的重要性等级。</p>
<p>kubernetes 把 pod 分成了三个 QoS 等级:</p>
<ul>
<li><strong>Guaranteed</strong>:优先级最高,可以考虑数据库应用或者一些重要的业务应用。除非 pods 使用超过了它们的 limits,或者节点的内存压力很大而且没有 QoS 更低的 pod,否则不会被杀死</li>
<li><strong>Burstable</strong>:这种类型的 pod 可以多于自己请求的资源(上限有 limit 指定,如果 limit 没有配置,则可以使用主机的任意可用资源),但是重要性认为比较低,可以是一般性的应用或者批处理任务</li>
<li><strong>Best Effort</strong>:优先级最低,集群不知道 pod 的资源请求情况,调度不考虑资源,可以运行到任意节点上(从资源角度来说),可以是一些临时性的不重要应用。pod 可以使用节点上任何可用资源,但在资源不足时也会被优先杀死</li>
</ul>
<p>Pod 的 requests 和 limits 是如何对应到这三个 QoS 等级上的,可以用下面一张表格概括:</p>
<p><img src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxpm62noj30p40d0tak.jpg" alt="pod QuS mapping" class="post-img" data-src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxpm62noj30p40d0tak.jpg"></p>
<p>看到这里,你也许看出来一个问题了:<strong>如果不配置 requests 和 limits,pod 的 QoS 竟然是最低的</strong>。没错,所以推荐大家理解 QoS 的概念,并且按照需求<strong>一定要给 pod 配置 requests 和 limits 参数</strong>,不仅可以让调度更准确,也能让系统更加稳定。</p>
<p><strong>NOTE</strong>:按照现在的方法根据 pod 请求的资源进行配置不够灵活和直观,更理想的情况是用户可以直接配置 pod 的 QoS,而不用关心具体的资源申请和上限值。但 kubernetes 目前还没有这方面的打算。</p>
<p>Pod 的 QoS 还决定了容器的 OOM(out-of-memory)值,它们对应的关系如下:</p>
<p><img src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxqj256ej30pa04374p.jpg" alt="pod QoS oom score" class="post-img" data-src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxqj256ej30pa04374p.jpg"></p>
<p>可以看到,QoS 越高的 pod oom 值越低,也就越不容易被系统杀死。对于 Bustable pod,它的值是根据 request 和节点内存总量共同决定的:</p>
<pre class=" language-go"><code class="language-go">oomScoreAdjust <span class="token operator">:=</span> <span class="token number">1000</span> <span class="token operator">-</span> <span class="token punctuation">(</span><span class="token number">1000</span><span class="token operator">*</span>memoryRequest<span class="token punctuation">)</span><span class="token operator">/</span>memoryCapacity
</code></pre>
<p>其中 <code>memoryRequest</code> 是 pod 申请的资源,<code>memoryCapacity</code> 是节点的内存总量。可以看到,申请的内存越多,oom 值越低,也就越不容易被杀死。</p>
<p>QoS 的作用会在后面介绍 eviction 的时候详细讲解。</p>
<h3 id="pod-优先级(priority)"><a href="#pod-优先级(priority)" class="headerlink" title="pod 优先级(priority)"></a>pod 优先级(priority)</h3><p>除了 QoS,kubernetes 还允许我们自定义 pod 的优先级,比如:</p>
<pre class=" language-yaml"><code class="language-yaml"><span class="token key atrule">apiVersion</span><span class="token punctuation">:</span> scheduling.k8s.io/v1alpha1
<span class="token key atrule">kind</span><span class="token punctuation">:</span> PriorityClass
<span class="token key atrule">metadata</span><span class="token punctuation">:</span>
<span class="token key atrule">name</span><span class="token punctuation">:</span> high<span class="token punctuation">-</span>priority
<span class="token key atrule">value</span><span class="token punctuation">:</span> <span class="token number">1000000</span>
<span class="token key atrule">globalDefault</span><span class="token punctuation">:</span> <span class="token boolean important">false</span>
<span class="token key atrule">description</span><span class="token punctuation">:</span> <span class="token string">"This priority class should be used for XYZ service pods only."</span>
</code></pre>
<p>优先级的使用也比较简单,只需要在 <code>pod.spec.PriorityClassName</code> 指定要使用的优先级名字,即可以设置当前 pod 的优先级为对应的值。</p>
<p>Pod 的优先级在调度的时候会使用到。首先,待调度的 pod 都在同一个队列中,启用了 pod priority 之后,调度器会根据优先级的大小,把优先级高的 pod 放在前面,提前调度。</p>
<p>另外,如果在调度的时候,发现某个 pod 因为资源不足无法找到合适的节点,调度器会尝试 preempt 的逻辑。<br>简单来说,调度器会试图找到这样一个节点:找到它上面优先级低于当前要调度 pod 的所有 pod,如果杀死它们,能腾足够的资源,调度器会执行删除操作,把 pod 调度到节点上。</p>
<p><a href="https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/" target="_blank" rel="noopener">Pod Priority and Preemption - Kubernetes</a></p>
<h2 id="驱逐(Eviction)"><a href="#驱逐(Eviction)" class="headerlink" title="驱逐(Eviction)"></a>驱逐(Eviction)</h2><p>至此,我们讲述的都是理想情况下 kubernetes 的工作状况,我们假设资源完全够用,而且应用也都是在使用规定范围内的资源。</p>
<p>但现实不会如此简单,在管理集群的时候我们常常会遇到资源不足的情况,在这种情况下我们要<strong>保证整个集群可用</strong>,并且尽可能<strong>减少应用的损失</strong>。保证集群可用比较容易理解,首先要保证系统层面的核心进程正常,其次要保证 kubernetes 本身组件进程不出问题;但是如果量化应用的损失呢?首先能想到的是如果要杀死 pod,要尽量减少总数。另外一个就和 pod 的优先级相关了,那就是尽量杀死不那么重要的应用,让重要的应用不受影响。</p>
<p>Pod 的驱逐是在 kubelet 中实现的,因为 kubelet 能动态地感知到节点上资源使用率实时的变化情况。其核心的逻辑是:kubelet 实时监控节点上各种资源的使用情况,一旦发现某个不可压缩资源出现要耗尽的情况,就会主动终止节点上的 pod,让节点能够正常运行。被终止的 pod 所有容器会停止,状态会被设置为 failed。</p>
<h3 id="驱逐触发条件"><a href="#驱逐触发条件" class="headerlink" title="驱逐触发条件"></a>驱逐触发条件</h3><p>那么哪些资源不足会导致 kubelet 执行驱逐程序呢?目前主要有三种情况:实际内存不足、节点文件系统的可用空间(文件系统剩余大小和 inode 数量)不足、以及镜像文件系统的可用空间(包括文件系统剩余大小和 inode 数量)不足。</p>
<p>下面这图是具体的触发条件:</p>
<p><img src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxrm6zfcj310m06ajst.jpg" alt="eviction condition" class="post-img" data-src="https://cizixs-blog.oss-cn-beijing.aliyuncs.com/006tNc79ly1g1qxrm6zfcj310m06ajst.jpg"></p>
<p>有了数据的来源,另外一个问题是触发的时机,也就是到什么程度需要触发驱逐程序?kubernetes 运行用户自己配置,并且支持两种模式:按照百分比和按照绝对数量。比如对于一个 32G 内存的节点当可用内存少于 10% 时启动驱逐程序,可以配置 <code>memory.available<10%</code>或者 <code>memory.available<3.2Gi</code>。</p>
<p><strong>NOTE</strong>:默认情况下,kubelet 的驱逐规则是 <code>memory.available<100Mi</code>,对于生产环境这个配置是不可接受的,所以一定要根据实际情况进行修改。</p>
<h3 id="软驱逐(soft-eviction)和硬驱逐(hard-eviction)"><a href="#软驱逐(soft-eviction)和硬驱逐(hard-eviction)" class="headerlink" title="软驱逐(soft eviction)和硬驱逐(hard eviction)"></a>软驱逐(soft eviction)和硬驱逐(hard eviction)</h3><p>因为驱逐 pod 是具有毁坏性的行为,因此必须要谨慎。有时候内存使用率增高只是暂时性的,有可能 20s 内就能恢复,这时候启动驱逐程序意义不大,而且可能会导致应用的不稳定,我们要考虑到这种情况应该如何处理;另外需要注意的是,如果内存使用率过高,比如高于 95%(或者 90%,取决于主机内存大小和应用对稳定性的要求),那么我们不应该再多做评估和考虑,而是赶紧启动驱逐程序,因为这种情况再花费时间去判断可能会导致内存继续增长,系统完全崩溃。</p>
<p>为了解决这个问题,kubernetes 引入了 soft eviction 和 hard eviction 的概念。</p>
<p><strong>软驱逐</strong>可以在资源紧缺情况并没有哪些严重的时候触发,比如内存使用率为 85%,软驱逐还需要配置一个时间指定软驱逐条件持续多久才触发,也就是说 kubelet 在发现资源使用率达到设定的阈值之后,并不会立即触发驱逐程序,而是继续观察一段时间,如果资源使用率高于阈值的情况持续一定时间,才开始驱逐。并且驱逐 pod 的时候,会遵循 grace period ,等待 pod 处理完清理逻辑。和软驱逐相关的启动参数是:</p>
<ul>
<li><code>--eviction-soft</code>:软驱逐触发条件,比如 <code>memory.available<1Gi</code></li>
<li><code>--eviction-sfot-grace-period</code>:触发条件持续多久才开始驱逐,比如 <code>memory.available=2m30s</code></li>
<li><code>--eviction-max-pod-grace-period</code>:kill pod 时等待 grace period 的时间让 pod 做一些清理工作,如果到时间还没有结束就做 kill</li>
</ul>
<p>前面两个参数必须同时配置,软驱逐才能正常工作;后一个参数会和 pod 本身配置的 grace period 比较,选择较小的一个生效。</p>
<p><strong>硬驱逐</strong>更加直接干脆,kubelet 发现节点达到配置的硬驱逐阈值后,立即开始驱逐程序,并且不会遵循 grace period,也就是说立即强制杀死 pod。对应的配置参数只有一个 <code>--evictio-hard</code>,可以选择上面表格中的任意条件搭配。</p>
<p>设置这两种驱逐程序是为了平衡节点稳定性和对 pod 的影响,软驱逐照顾到了 pod 的优雅退出,减少驱逐对 pod 的影响;而硬驱逐则照顾到节点的稳定性,防止资源的快速消耗导致节点不可用。</p>
<p>软驱逐和硬驱逐可以单独配置,不过还是推荐两者都进行配置,一起使用。</p>
<h3 id="驱逐哪些-pods?"><a href="#驱逐哪些-pods?" class="headerlink" title="驱逐哪些 pods?"></a>驱逐哪些 pods?</h3><p>上面我们已经整体介绍了 kubelet 驱逐 pod 的逻辑和过程,那这里就牵涉到一个具体的问题:<strong>要驱逐哪些 pod</strong>?驱逐的重要原则是尽量减少对应用程序的影响。</p>
<p>如果是存储资源不足,kubelet 会根据情况清理状态为 Dead 的 pod 和它的所有容器,以及清理所有没有使用的镜像。如果上述清理并没有让节点回归正常,kubelet 就开始清理 pod。</p>
<p>一个节点上会运行多个 pod,驱逐所有的 pods 显然是不必要的,因此要做出一个抉择:在节点上运行的所有 pod 中选择一部分来驱逐。虽然这些 pod 乍看起来没有区别,但是它们的地位是不一样的,正如乔治·奥威尔在《动物庄园》的那句话:</p>
<blockquote>
<p>所有动物生而平等,但有些动物比其他动物更平等。</p>
</blockquote>
<p>Pod 也是不平等的,有些 pod 要比其他 pod 更重要。只管来说,系统组件的 pod 要比普通的 pod 更重要,另外运行数据库的 pod 自然要比运行一个无状态应用的 pod 更重要。kubernetes 又是怎么决定 pod 的优先级的呢?这个问题的答案就藏在我们之前已经介绍过的内容里:pod requests 和 limits、优先级(priority),以及 pod 实际的资源使用。</p>
<p>简单来说,kubelet 会根据以下内容对 pod 进行排序:pod 是否使用了超过请求的紧张资源、pod 的优先级、然后是使用的紧缺资源和请求的紧张资源之间的比例。具体来说,kubelet 会按照如下的顺序驱逐 pod:</p>
<ul>
<li>使用的紧张资源超过请求数量的 <code>BestEffort</code> 和 <code>Burstable</code> pod,这些 pod 内部又会按照优先级和使用比例进行排序</li>
<li>紧张资源使用量低于 requests 的 <code>Burstable</code> 和 <code>Guaranteed</code> 的 pod 后面才会驱逐,只有当系统组件(kubelet、docker、journald 等)内存不够,并且没有上面 QoS 比较低的 pod 时才会做。执行的时候还会根据 priority 排序,优先选择优先级低的 pod</li>
</ul>
<h3 id="防止波动"><a href="#防止波动" class="headerlink" title="防止波动"></a>防止波动</h3><p>这里的波动有两种情况,我们先说说第一种。驱逐条件出发后,如果 kubelet 驱逐一部分 pod,让资源使用率低于阈值就停止,那么很可能过一段时间资源使用率又会达到阈值,从而再次出发驱逐,如此循环往复……为了处理这种问题,我们可以使用 <code>--eviction-minimum-reclaim</code>解决,这个参数配置每次驱逐至少清理出来多少资源才会停止。</p>
<p>另外一个波动情况是这样的:Pod 被驱逐之后并不会从此消失不见,常见的情况是 kubernetes 会自动生成一个新的 pod 来取代,并经过调度选择一个节点继续运行。如果不做额外处理,有理由相信 pod 选择原来节点的可能性比较大(因为调度逻辑没变,而它上次调度选择的就是该节点),之所以说可能而不是绝对会再次选择该节点,是因为集群 pod 的运行和分布和上次调度时极有可能发生了变化。</p>
<p>无论如何,如果被驱逐的 pod 再次调度到原来的节点,很可能会再次触发驱逐程序,然后 pod 再次被调度到当前节点,循环往复…… 这种事情当然是我们不愿意看到的,虽然看似复杂,但这个问题解决起来非常简单:驱逐发生后,kubelet 更新节点状态,调度器感知到这一情况,暂时不往该节点调度 pod 即可。<code>--eviction-pressure-transition-period</code> 参数可以指定 kubelet 多久才上报节点的状态,因为默认的上报状态周期比较短,频繁更改节点状态会导致驱逐波动。</p>
<p>做一个总结,下面是一个使用了上面多种参数的驱逐配置实例(你应该能看懂它们是什么意思了):</p>
<pre class=" language-bash"><code class="language-bash hljs">–eviction-soft<span class="token operator">=</span>memory.available<span class="token operator"><</span>80%,nodefs.available<span class="token operator"><</span>2Gi \
–eviction-soft-grace-period<span class="token operator">=</span>memory.available<span class="token operator">=</span>1m30s,nodefs.available<span class="token operator">=</span>1m30s \
–eviction-max-pod-grace-period<span class="token operator">=</span>120 \
–eviction-hard<span class="token operator">=</span>memory.available<span class="token operator"><</span>500Mi,nodefs.available<span class="token operator"><</span>1Gi \
–eviction-pressure-transition-period<span class="token operator">=</span>30s \
--eviction-minimum-reclaim<span class="token operator">=</span><span class="token string"><span class="hljs-string">"memory.available=0Mi,nodefs.available=500Mi,imagefs.available=2Gi"</span></span>
</code></pre>
<h2 id="碎片整理和重调度"><a href="#碎片整理和重调度" class="headerlink" title="碎片整理和重调度"></a>碎片整理和重调度</h2><p>Kubernetes 的调度器在为 pod 选择运行节点的时候,只会考虑到调度那个时间点集群的状态,经过一系列的算法选择一个<strong>当时最合适</strong>的节点。但是集群的状态是不断变化的,用户创建的 pod 也是动态的,随着时间变化,原来调度到某个节点上的 pod 现在看来可能有更好的节点可以选择。比如考虑到下面这些情况:</p>
<ul>
<li>调度 pod 的条件已经不再满足,比如节点的 taints 和 labels 发生了变化</li>
<li>新节点加入了集群。如果默认配置了把 pod 打散,那么应该有一些 pod 最好运行在新节点上</li>
<li>节点的使用率不均匀。调度后,有些节点的分配率和使用率比较高,另外一些比较低</li>
<li>节点上有资源碎片。有些节点调度之后还剩余部分资源,但是又低于任何 pod 的请求资源;或者 memory 资源已经用完,但是 CPU 还有挺多没有使用</li>
</ul>
<p>想要解决上述的这些问题,都需要把 pod 重新进行调度(把 pod 从当前节点移动到另外一个节点)。但是默认情况下,一旦 pod 被调度到节点上,除非给杀死否则不会移动到另外一个节点的。</p>
<p>为此 kubernetes 社区孵化了一个称为 <a href="https://github.com/kubernetes-incubator/descheduler" target="_blank" rel="noopener"><code>descheduler</code></a> 的项目,专门用来做重调度。重调度的逻辑很简单:找到上面几种情况中已经不是最优的 pod,把它们驱逐掉(eviction)。</p>
<p>目前,descheduler 不会决定驱逐的 pod 应该调度到哪台机器,而是<strong>假定默认的调度器会做出正确的调度抉择</strong>。也就是说,之所以 pod 目前不合适,不是因为调度器的算法有问题,而是因为集群的情况发生了变化。如果让调度器重新选择,调度器现在会把 pod 放到合适的节点上。这种做法让 descheduler 逻辑比较简单,而且避免了调度逻辑出现在两个组件中。</p>
<p>Descheduler 执行的逻辑是可以配置的,目前有几种场景:</p>
<ul>
<li><code>RemoveDuplicates</code>:RS、deployment 中的 pod 不能同时出现在一台机器上</li>
<li><code>LowNodeUtilization</code>:找到资源使用率比较低的 node,然后驱逐其他资源使用率比较高节点上的 pod,期望调度器能够重新调度让资源更均衡</li>
<li><code>RemovePodsViolatingInterPodAntiAffinity</code>:找到已经违反 Pod Anti Affinity 规则的 pods 进行驱逐,可能是因为反亲和是后面加上去的</li>
<li><code>RemovePodsViolatingNodeAffinity</code>:找到违反 Node Affinity 规则的 pods 进行驱逐,可能是因为 node 后面修改了 label</li>
</ul>
<p>当然,为了保证应用的稳定性,descheduler 并不会随意地驱逐 pod,还是会尊重 pod 运行的规则,包括 pod 的优先级(不会驱逐 Critical pod,并且按照优先级顺序进行驱逐)和 PDB(如果违反了 PDB,则不会进行驱逐),并且不会驱逐没有 deployment、rs、jobs 的 pod 不会驱逐,daemonset pod 不会驱逐,有 local storage 的 pod 也不会驱逐。</p>
<p>Descheduler 不是一个常驻的任务,每次执行完之后会退出,因此推荐使用 CronJob 来运行。</p>
<p>总的来说,descheduler 是对原生调度器的补充,用来解决原生调度器的调度决策随着时间会变得失效,或者不够优化的缺陷。</p>
<h2 id="资源动态调整"><a href="#资源动态调整" class="headerlink" title="资源动态调整"></a>资源动态调整</h2><p>动态调整的思路:应用的实际流量会不断变化,因此使用率也是不断变化的,为了应对应用流量的变化,我们应用能够自动调整应用的资源。比如在线商品应用在促销的时候访问量会增加,我们应该自动增加 pod 运算能力来应对;当促销结束后,有需要自动降低 pod 的运算能力防止浪费。</p>
<p>运算能力的增减有两种方式:改变单个 pod 的资源,已经增减 pod 的数量。这两种方式对应了 kubernetes 的 HPA 和 VPA。</p>
<h3 id="Horizontal-Pod-AutoScaling(横向-Pod-自动扩展)"><a href="#Horizontal-Pod-AutoScaling(横向-Pod-自动扩展)" class="headerlink" title="Horizontal Pod AutoScaling(横向 Pod 自动扩展)"></a>Horizontal Pod AutoScaling(横向 Pod 自动扩展)</h3><p><img src="https://478h5m1yrfsa3bbe262u7muv-wpengine.netdna-ssl.com/wp-content/uploads/2018/02/autoscaler_kubernetes.jpg" alt="kubernetes HPA" class="post-img" data-src="https://478h5m1yrfsa3bbe262u7muv-wpengine.netdna-ssl.com/wp-content/uploads/2018/02/autoscaler_kubernetes.jpg"></p>
<p>横向 pod 自动扩展的思路是这样的:kubernetes 会运行一个 controller,周期性地监听 pod 的资源使用情况,当高于设定的阈值时,会自动增加 pod 的数量;当低于某个阈值时,会自动减少 pod 的数量。自然,这里的阈值以及 pod 的上限和下限的数量都是需要用户配置的。</p>
<p>上面这句话隐藏了一个重要的信息:HPA 只能和 RC、deployment、RS 这些可以动态修改 replicas 的对象一起使用,而无法用于单个 pod、daemonset(因为它控制的 pod 数量不能随便修改)等对象。</p>
<p>目前官方的监控数据来源是 metrics server 项目,可以配置的资源只有 CPU,但是用户可以使用自定义的监控数据(比如 prometheus),其他资源(比如 memory)的 HPA 支持也已经在路上了。</p>
<h3 id="Vertical-Pod-AutoScaling"><a href="#Vertical-Pod-AutoScaling" class="headerlink" title="Vertical Pod AutoScaling"></a>Vertical Pod AutoScaling</h3><p>和 HPA 的思路相似,只不过 VPA 调整的是单个 pod 的 request 值(包括 CPU 和 memory)。VPA 包括三个组件:</p>
<ul>
<li>Recommander:消费 metrics server 或者其他监控组件的数据,然后计算 pod 的资源推荐值</li>
<li>Updater:找到被 vpa 接管的 pod 中和计算出来的推荐值差距过大的,对其做 update 操作(目前是 evict,新建的 pod 在下面 admission controller 中会使用推荐的资源值作为 request)</li>
<li>Admission Controller:新建的 pod 会经过该 Admission Controller,如果 pod 是被 vpa 接管的,会使用 recommander 计算出来的推荐值</li>
</ul>
<p>可以看到,这三个组件的功能是互相补充的,共同实现了动态修改 pod 请求资源的功能。相对于 HPA,目前 VPA 还处于 alpha,并且还没有合并到官方的 kubernetes release 中,后续的接口和功能很可能会发生变化。</p>
<h3 id="Cluster-Auto-Scaler"><a href="#Cluster-Auto-Scaler" class="headerlink" title="Cluster Auto Scaler"></a>Cluster Auto Scaler</h3><p>随着业务的发展,应用会逐渐增多,每个应用使用的资源也会增加,总会出现集群资源不足的情况。为了动态地应对这一状况,我们还需要 CLuster Auto Scaler,能够根据整个集群的资源使用情况来增减节点。</p>
<p>对于公有云来说,Cluster Auto Scaler 就是监控这个集群因为资源不足而 pending 的 pod,根据用户配置的阈值调用公有云的接口来申请创建机器或者销毁机器。对于私有云,则需要对接内部的管理平台。</p>
<p>目前 HPA 和 VPA 不兼容,只能选择一个使用,否则两者会相互干扰。而且 VPA 的调整需要重启 pod,这是因为 pod 资源的修改是比较大的变化,需要重新走一下 apiserver、调度的流程,保证整个系统没有问题。目前社区也有计划在做原地升级,也就是说不通过杀死 pod 再调度新 pod 的方式,而是直接修改原有 pod 来更新。</p>
<p>理论上 HPA 和 VPA 是可以共同工作的,HPA 负责瓶颈资源,VPA 负责其他资源。比如对于 CPU 密集型的应用,使用 HPA 监听 CPU 使用率来调整 pods 个数,然后用 VPA 监听其他资源(memory、IO)来动态扩展这些资源的 request 大小即可。当然这只是理想情况,</p>
<h2 id="总结"><a href="#总结" class="headerlink" title="总结"></a>总结</h2><p>从前面介绍的各种 kubernetes 调度和资源管理方案可以看出来,提高应用的资源使用率、保证应用的正常运行、维护调度和集群的公平性是件非常复杂的事情,kubernetes 并没有<em>完美</em>的方法,而是对各种可能的问题不断提出一些针对性的方案。</p>
<p>集群的资源使用并不是静态的,而是随着时间不断变化的,目前 kubernetes 的调度决策都是基于调度时集群的一个静态资源切片进行的,动态地资源调整是通过 kubelet 的驱逐程序进行的,HPA 和 VPA 等方案也不断提出,相信后面会不断完善这方面的功能,让 kubernetes 更加智能。</p>
<p>资源管理和调度、应用优先级、监控、镜像中心等很多东西相关,是个非常复杂的领域。在具体的实施和操作的过程中,常常要考虑到企业内部的具体情况和需求,做出针对性的调整,并且需要开发者、系统管理员、SRE、监控团队等不同小组一起合作。但是这种付出从整体来看是值得的,提升资源的利用率能有效地节约企业的成本,也能让应用更好地发挥出作用。</p>
<div class="toc-main" style="right: -100%">
<div class="post-toc">
</body>
参考文章:
- kubernetes Pod 驱逐详解
- Kubernetes 内存资源限制实战
- Pod Priority and Preemption
- Understanding resource limits in kubernetes: memory
- Node-pressure Eviction



