

OpenStack NUMA 配置
NUMA 体系架构
- SMP 体系架构
- NUMA 体系架构
- NUMA 结构基本概念
- Openstack flavor NUMA 策略
- Nova 实现 NUMA 流程
1. SMP 体系架构
CPU 计算平台体系架构分为 SMP 体系架构和 NUMA 体系架构等,下图为 SMP 体系架构:
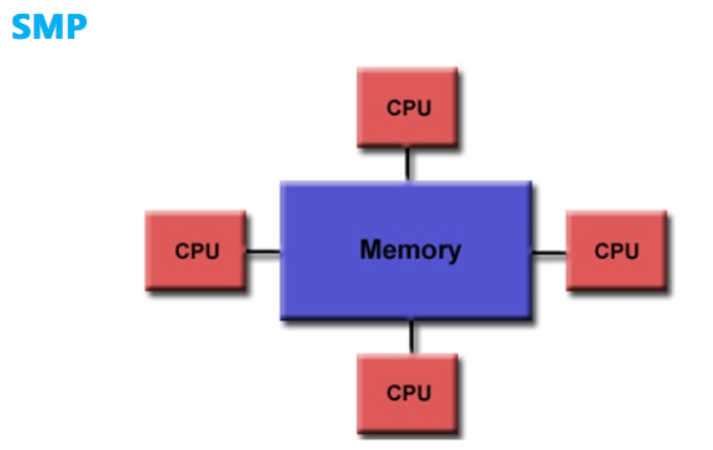
SMP(Sysmmetric Multi-Processor System,对称多处理器系统),它由多个具有对称关系的处理器组成。所谓对称,即处理器之间是水平的镜像关系,没有主从之分。SMP 架构使得一台计算机不再由单个 CPU 组成。
SMP 的结构特征是多处理器共享一个集中式存储器,每个处理器访问存储器的时间片一致,使工作负载能够均匀的分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。但是,如果多个处理器同时请求访问共享资源时,就会引发资源竞争,需要软硬件实现加锁机制来解决这个问题。所以,SMP 又称为 UMA(Uniform Memory Access,一致性存储器访问),其中,一致性指的是在任意时刻,多个处理器只能为内存的每个数据保存或共享一个唯一的数值。
因此,这样的架构设计无法拥有良好的处理器数量扩展性,因为共享内存的资源竞态总是存在的,处理器利用率最好的情况只能停留在 2 到 4 颗。
2. NUMA 体系架构
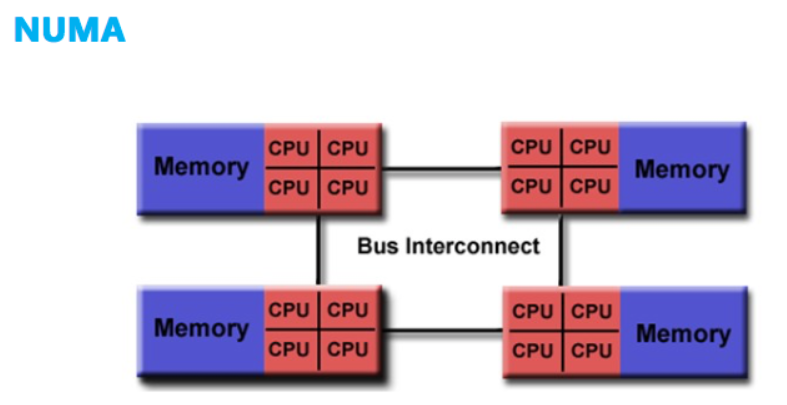
计算机系统中,处理器的处理速度要远快于内存的读写速度,所以限制计算机计算性能的瓶颈在存储器带宽上。SMP 架构因为限制了处理器访问存储器的频次,所以处理器可能会时刻对数据访问感到饥饿。
NUMA(Non-Uniform Memory Access,非一致性存储器访问)架构优化了 SMP 架构扩展性差以及存储器带宽窄的问题。
从上图可以看出,NUMA 和 SMP 架构是类似的,同样只会保存一份操作系统和数据库的副本,表示 NUMA 架构中的处理器依旧能够访问到整个存储器。两种主要的区别在于 NUMA 架构采用了分布式存储器,将处理器和存储器划分为不同的节点(NUMA Node),每个节点都包含了若干的处理器与内存资源。多节点的设计有效提高了存储器的带宽和处理器的扩展性。假设系统含有 4 个 NUMA 节点,那么在理想情况下系统的存储器带宽将会是 SMP 架构的 4 倍。
另一方面,NUMA 节点的处理器可以访问到整体存储器。按照节点内外,内存被分为节点内部的本地内存以及节点外部的远程内存。当处理器访问本地内存时,走的是内部总线,当处理器访问远程内存时,走的是主板上的 QPI 互联模块。访问前者的速度要远快于后者,NUMA(非一致性存储器访问)因此而得名。
3. NUMA 结构基本概念
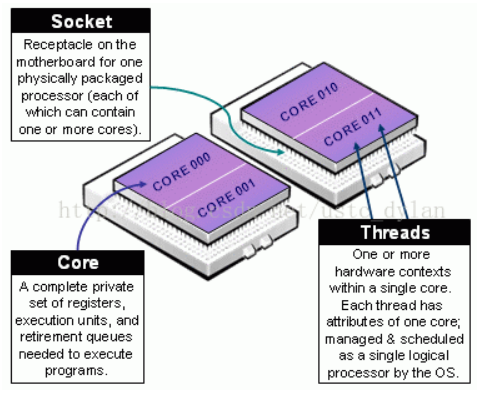
- Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽。
- Core: 物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等。
-
Thread: 使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。
- Node: 包含有若干个物理 CPU 的组。
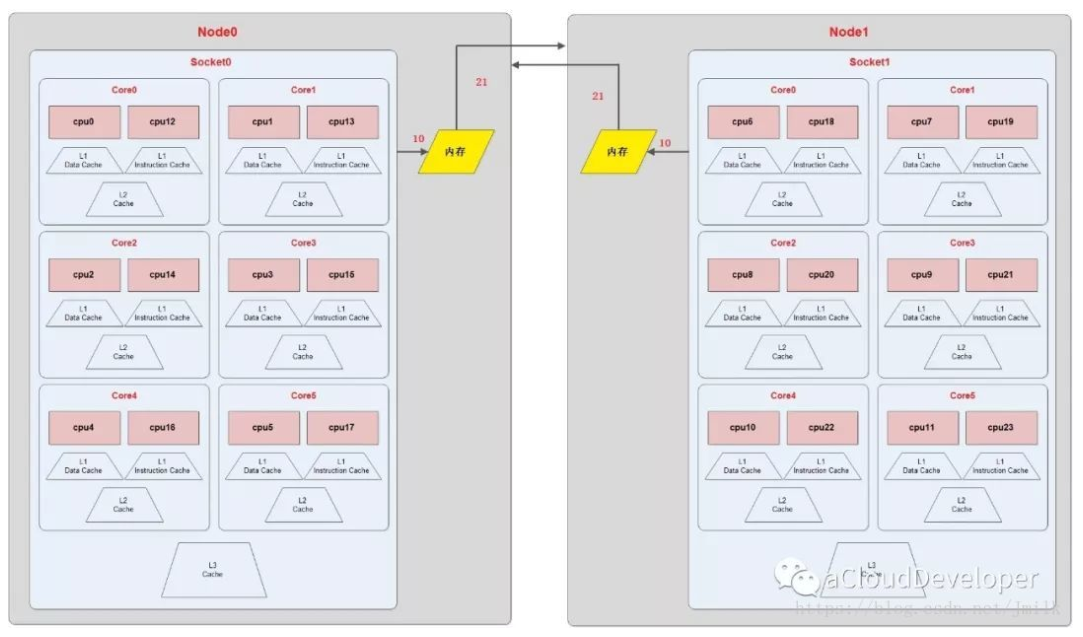
上图的 NUMA Topology 有 2 个 NUMA node,每个 node 有 1 个 socket,即 pCPU, 每个 pCPU 有 6 个 core,1 个 core 有 2 个 Processor,则共有逻辑 cpu processor 24 个。
在 LIUNX 命令行中执行 lscpu 即可看到机器的 NUMA 拓扑结构:
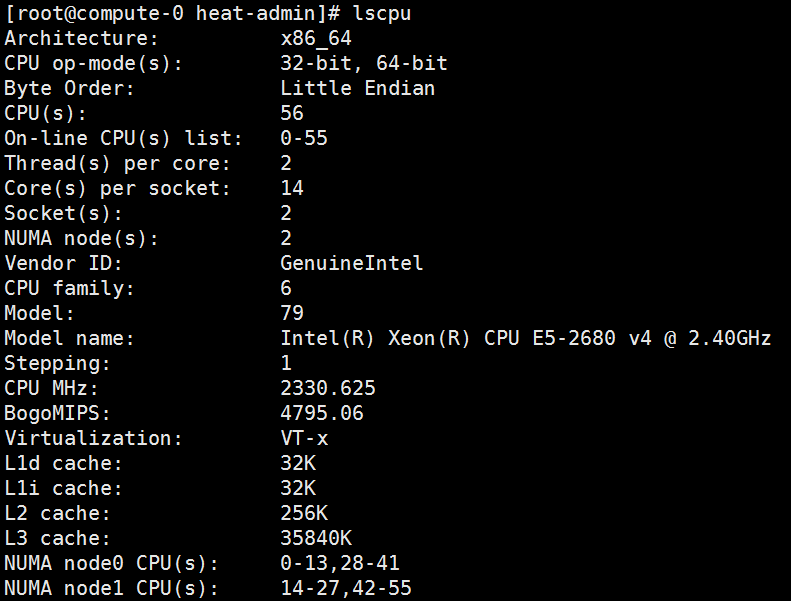
如上图所示,机器有 2 个 node 分配到 2 个 socket 上,每个 socket 有 14 个 core,每个 core 有 2 个 processor, 则共有 56 个 cpu processor。同时,从上图也可看出 NUMA node 0 上的 cpu 分布为 0-13,28-41,而 node 1 上的分布为 14-27, 42-55。
由上节分析知,NUMA node 处理器访问本地内存的速度要快于访问远端内存的速度。访问速度与 node 的距离有关系,node 间的距离称为 node distance,使用 numactl --hardware 可以 show 出该距离:

node0 的本地内存大小为 32209MB,Node1 的本地内存大小为 32316MB。Node0 到本地内存的 distance 为 10,到 node1 的内存 distance 距离为 20。node1 到本地内存的 distance 为10,到 node0 的内存distance距离为20。
进一步对上面的 NUMA Topology 图进行介绍。
Liunx 上使用 cat /proc/cpuinfo 命令 show 出 cpu 信息:
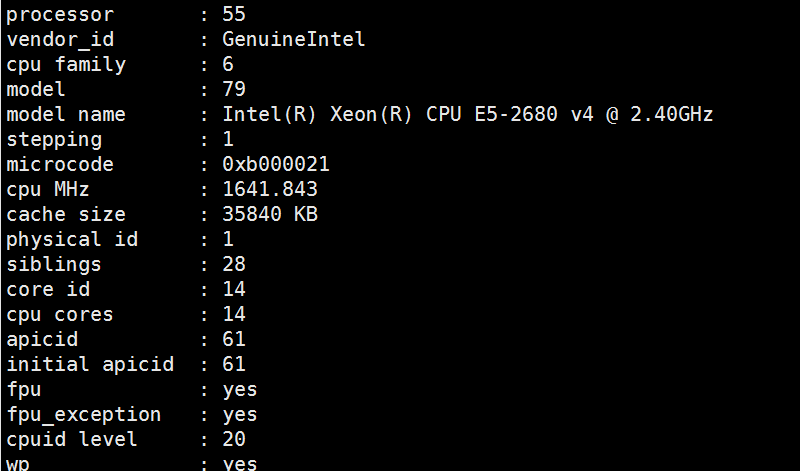
其中 physical id 表示 socket 号。当前的 cpu core 是第 14 个 ,siblings 为 28 表示此 cpu14 在 core14 里面的兄弟逻辑 cpu 为 cpu28。CPU 14 和 CPU 28 共享 L1 Data cache、L1 instruction 和 L2 Cache 。
[***@controller-0 ~]$ cat /sys/devices/system/cpu/cpu14/cache/index0/type Data [***@controller-0 ~]$ cat /sys/devices/system/cpu/cpu14/cache/index1/type Instruction [***@controller-0 ~]$ cat /sys/devices/system/cpu/cpu14/cache/index2/type Unified [***@controller-0 ~]$ cat /sys/devices/system/cpu/cpu14/cache/index0/size 32K [***@controller-0 ~]$ cat /sys/devices/system/cpu/cpu14/cache/index1/size 32K [***@controller-0 ~]$ cat /sys/devices/system/cpu/cpu14/cache/index2/size 256K
4. Openstack flavor NUMA 策略
cpu 绑核策略
对 Libvirt 驱动而言,虚拟机的 vCPU 可以绑定到主机的物理 CPU 上(pCPU)。这些配置可以改善虚拟机实例的精确度与性能。
openstack flavor set FLAVOR-NAME \ --property hw:cpu_policy=CPU-POLICY \ --property hw:cpu_thread_policy=CPU-THREAD-POLICY
有效的CPU-POLICY值为:
- shared (默认值) : 虚拟机的 vCPU 允许在主机 pCPU 上自由浮动,尽管可能受到 NUMA 策略的限制。
- dedicated: 虚拟机 vCPU 被严格绑定到一组主机 pCPU 上。
有效的 CPU-THREAD-POLICY 值为:
- prefer (默认值) : 主机可能是也可能不是 SMT 架构,如果应用 SMT 架构时,优选兄弟线程。
- isolate: 应用在主机可能不是 SMT 架构,或者必须模拟非 SMT 架构。当主机不是 SMT 架构时,每个 vCPU 相当于一个核。如果主机应用 SMT 架构,也就是说一个物理核有多个兄弟线程,每个 vCPU 也相当于一个物理核。其他虚拟机的 vCPU 不会放在同一个核上。选中的核上只有一个兄弟线程可用。
- require: 主机必要使用 SMT 架构。每个 vCPU 被分配在兄弟线程上。如果主机没有 SMT 架构,那就不使用此主机。如果主机使用 SMT 架构,却没有足够空闲线程的核,那么 nova 调度失败。
NUMA拓扑
Libvirt 驱动程序可以为虚拟机 vCPU 定义放置的 NUMA 节点,或者定义虚拟机从哪个 NUMA 节点分配 vCPU 与内存。
$ openstack flavor set FLAVOR-NAME \ --property hw:numa_nodes=FLAVOR-NODES \ --property hw:numa_cpus.N=FLAVOR-CORES \ --property hw:numa_mem.N=FLAVOR-MEMORY
- FLAVOR-NODES: 限制虚拟机 vCPU 线程运行的可选 NUMA 节点数量。如果不指定,则 vCPU 线程可以运行在任意可用的 NUMA 节点上。
- N: 应用 CPU 或内存配置的虚拟机 NUMA 节点,值的范围从 0 到 FLAVOR-NODES - 1。比如为 0,则运行在NUMA节点 0,为 1,则运行在 NUMA 节点1。
- FLAVOR-CORES: 映射到虚拟机NUMA节点N上的虚拟机vCPU列表。如果不指定,vCPU 在可用的 NUMA 节点之间平均分配。
- FLAVOR-MEMORY: 映射到虚拟机 NUMA 节点 N 上的虚拟机内存大小。如果不指定,则内存平均分配到可用 NUMA 节点。
举例如下:
$ openstack flavor set aze-FLAVOR \ --property hw:numa_nodes=2 \ --property hw:numa_cpus.0=0,1 \ --property hw:numa_cpus.1=2,3 \ --property hw:numa_mem.0=2048 \ --property hw:numa_mem.1=2048 \
大页内存分配
$ openstack flavor set FLAVOR-NAME \
--property hw:mem_page_size=PAGE_SIZE
有效的 PAGE_SIZE 值为:
- small (默认值): 使用最小的内存页面,例如 x86 平台的 4KB。
- large: 虚拟机 RAM 使用大页内存。例如 x86 平台的 2MB 或 1G。
- any: 取决于计算驱动程序。此情况下,Libvirt 驱动可能会尝试寻找内存大页,但最终回落到小页。其他的驱动则可能选择可用策略。
注意:大页内存可以分配给虚拟机内存,而不考虑 Guest OS 是否使用。如果 Guest OS 不使用大页内存,则它值会识别小页。反过来,如果 Guest OS 计划使用大页内存,则一定要给虚拟机分配大页内存。否则虚拟机的性能将不及预期。
5. Nova 实现 NUMA 流程
Nova 实现 NUMA 流程如下所示:
1. nova-api 对 flavor metadata 或 image property 中的 NUMA 配置信息进行解析,生成 Guest NUMA topology,保存为 instance[‘numa_topology’]。
2. nova-scheduler 通过 NUMATopologyFilter 判断 Host NUMA topology 是否能够满足 Guest NUMA topology,进行 ComputeNode 调度。
3. nova-compute 再次通过 instance_claim 检查 Host NUMA 资源是否满足建立 Guest NUMA。
4. nova-compute 建立 Guest NUMA node 和 Host NUMA node 的映射关系,并根据映射关系调用 libvirt driver 生成 XML 文件。
5. Resource Tracker 会刷新 Host NUMA 资源的使用情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号