

深度确定性策略梯度(DDPG)
本文首发于行者AI
离散动作与连续动作
离散动作与连续动作是相对的概念,前者可数,后者不可数。离散动作如LunarLander-v2环境,可以采取四种离散动作;连续动作如Pendulum-v1环境,动作是向左或向右转,用力矩衡量,范围为[-2,2]的连续空间。
对于连续的动作控制空间,Q-learning与DQN等算法是无法处理的。我们无法用这些算法穷举出所有action的Q值,更无法取其中最大的Q值。那如何输出连续的动作呢,我们可以借用万能的神经网络来处理。在离散动作的场景下,比如输出上下左右这四个动作。有几个动作,神经网络就输出几个概率值,我们用来表示这个随机性的策略。在连续的动作场景下,比如要输出机器人手臂弯曲的角度,这样的一个动作,网络就输出一个具体的浮点数,用来代表这个确定性的策略。
随机性策略与确定性策略
对随机性策略来讲,输入某一个状态s,采取某一个动作的可能性是一个概率值,类似抽奖,根据概率随机抽取某一个动作。而对于确定性策略来讲,它没有概率的影响。当神经网络的参数固定下来了之后,输入同样的状态,必然输出同样的动作,这就是确定性的策略。
深度确定性策略梯度
在连续控制领域,比较经典的强化学习算法就是深度确定性策略梯度(deep deterministic policy gradient,DDPG)。DDPG的特点可以从名字当中拆解后取理解。拆解成深度、确定性和策略梯度。 深度是用了神经网络;确定性表示DDPG输出的是一个确定性的动作,可以用于连续动作的场景;策略梯度代表用到策略网络。
DDPG是DQN的一个扩展版本,可以扩展到连续动作空间。在 DDPG 的训练中,同样有目标网络和经验回收,经验回放和DQN一样,但目标网络更新跟DQN 有所区别。首先回顾一下DQN的更新公式:
其中只能处理离散动作,DDPG就是改变这一部分,用一个Actor网络,使其可以处理连续动作空间。DDPG直接在DQN基础上加了一个策略网络直接输出动作值,所以DDPG需要一边学习Q网络,一边学习策略网络。Q网络的参数用w表示。策略网络的参数用θ表示,这其实是Actor-Critic结构。如图1所示。
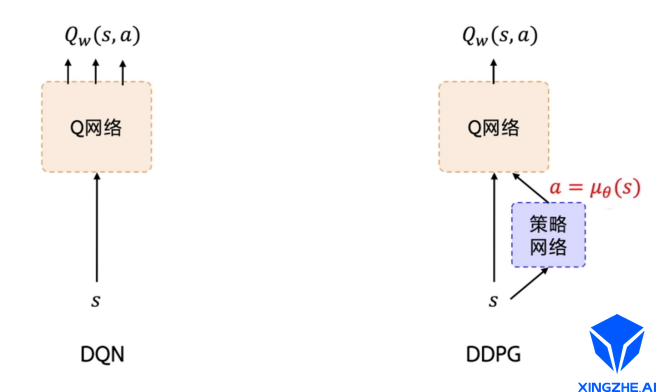
图1 从DQN到DDPG
通俗地解释一下演员-评论员的结构,策略网络扮演的就是演员的角色,它负责对外展示输出,输出舞蹈动作。Q网络就是评论员,它会在每一个步骤都对演员输出的动作做一个评估,打一个分,估计一下演员的动作未来能有多少收益,也就是去估计这个演员输出这个动作的Q值大概是多少,即 Qw(s, a)。演员就需要根据舞台目前的状态来做出一个动作。演员根据评论员的打分来调整自己的策略,也就是更新演员的神经网络参数θ,争取下次可以做得更好。评论员则是要根据观众的反馈,也就是环境的反馈奖励来调整自己的打分策略,也就是要更新评论员的神经网络的参数w ,目标是要让每一场表演都获得观众尽可能多的欢呼声跟掌声,也就是要最大化未来的总收益。
最开始训练的时候,这两个神经网络参数是随机的。所以评论员最开始是随机打分的,然后演员也跟着乱来,就随机表演,随机输出动作。但是由于我们有环境反馈的奖励存在,所以评论员的评分会越来越准确,也会评判的那个演员的表现会越来越好。既然演员是一个神经网络,是我们希望训练好的策略网络, 我们就需要计算梯度来去更新优化里面的参数 θ 。简单来说,我们希望调整演员的网络参数,使得评委打分尽可能得高。注意,这里的演员是不管观众的,它只关注评委,它就是迎合评委的打分Qw(s, a)而已。
接下来就是类似 DQN。DQN的最佳策略是想要学出一个很好的Q网络,学好这个网络之后,我们希望选取的那个动作使Q值最大。DDPG的目的也是为了求解让Q值最大的那个动作。 演员只是为了迎合评委的打分而已,所以用来优化策略网络的梯度就是要最大化这个Q值,那么构造的损失函数就是让Q取一个负号。以此来最小化损失,也就是最大化Q。如图2所示.
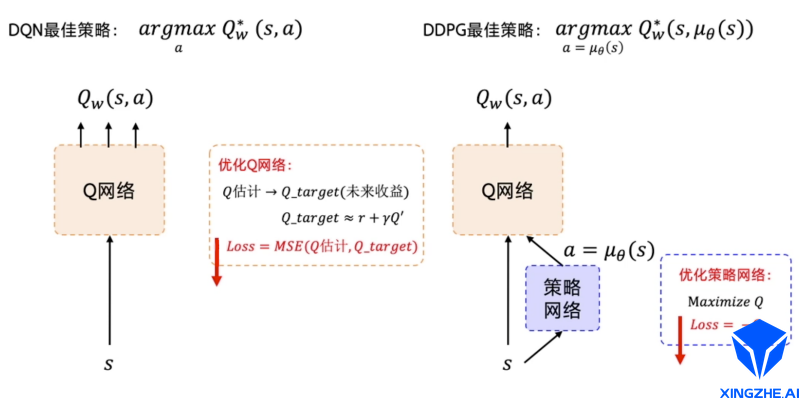
图2 DQN与DDPG的区别与联系
这里要注意,除了策略网络要做优化,DDPG还有一个Q网络也要优化。评委一开始也不知道怎么评分,它也是在一步一步的学习当中,慢慢地去给出准确的打分。我们优化Q网络的方法其实跟DQN优化Q网络的方法是一样的,我们用真实的奖励r和下一步的Q(即Q’)来去拟合未来的收益 Q_target。然后让Q网络的输出去逼近这个Q_target。构造的损失函数就是直接求这两个值的均方差。
为了稳定 Q_target,DDPG分别给Q网络和策略网络都搭建了目标网络,和DQN类似。策略网络的目标网络和Q网络的目标网络这两个网络是固定一段时间的参数之后再跟评估网络同步一下最新的参数。算法流程如图3所示。

图3 DDPG算法流程
代码实现
案例: 倒立摆问题。钟摆以随机位置开始,目标是将其向上摆动,使其保持直立。 测试环境: Pendulum-v1
动作:往左转还是往右转,用力矩来衡量,即力乘以力臂。范围[-2,2]:(连续空间)
状态:cos(theta), sin(theta) , thetadot。
奖励:越直立拿到的奖励越高,越偏离,奖励越低。奖励的最大值为0。
定义网络结构:
class ValueNetwork(nn.Module):
def __init__(self, num_inputs, num_action, hidden_size, init_w=3e-3):
super(ValueNetwork, self).__init__()
self.linear1 = nn.Linear(num_inputs + num_action, hidden_size)
self.linear2 = nn.Linear(hidden_size, hidden_size)
self.linear3 = nn.Linear(hidden_size, 1)
self.linear3.weight.data.uniform_(-init_w, init_w)
self.linear3.bias.data.uniform_(-init_w, init_w)
def forward(self, state, action):
x = torch.cat([state, action], 1)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = self.linear3(x)
return x
class PolicyNetwork(nn.Module):
def __init__(self, num_inputs, num_actions, hidden_size, init_W = 3e-3):
super(PolicyNetwork, self).__init__()
self.linear1 = nn.Linear(num_inputs, hidden_size)
self.linear2 = nn.Linear(hidden_size, hidden_size)
self.linear3 = nn.Linear(hidden_size, num_actions)
self.linear3.weight.data.uniform_(-init_W, init_W)
self.linear3.weight.data.uniform_(-init_W, init_W)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.tanh(self.linear3(x))
return x
def get_action(self, state):
state = torch.FloatTensor(state).unsqueeze(0).to(device)
action = self.forward(state)
return action.detach().cpu().numpy()[0,0]
定义DDPG类:
class DDPG(object):
def __init__(self, action_dim, state_dim, hidden_dim):
super(DDPG, self).__init__()
self.action_dim, self.state_dim, self.hidden_dim = action_dim, state_dim, hidden_dim
self.batch_size = 128
self.gamma = 0.99
self.min_value = -np.inf
self.max_value = np.inf
self.soft_tau = 1e-2
self.replay_buffer_size = 5000
self.value_lr = 1e-3
self.policy_lr = 1e-4
self.update_count = 0
self.value_net = ValueNetwork(state_dim, action_dim, hidden_dim).to(device)
self.policy_net = PolicyNetwork(state_dim, action_dim, hidden_dim).to(device)
self.target_value_net = ValueNetwork(state_dim, action_dim, hidden_dim).to(device)
self.target_policy_net = PolicyNetwork(state_dim, action_dim, hidden_dim).to(device)
for target_param, param in zip(self.target_value_net.parameters(), self.value_net.parameters()):
target_param.data.copy_(param.data)
for target_param, param in zip(self.target_policy_net.parameters(), self.policy_net.parameters()):
target_param.data.copy_(param.data)
self.value_optimizer = optim.Adam(self.value_net.parameters(), lr=self.value_lr)
self.policy_optimizer = optim.Adam(self.policy_net.parameters(), lr=self.policy_lr)
self.value_criterion = nn.MSELoss()
self.replay_buffer = ReplayBuffer(self.replay_buffer_size)
def update(self):
state, action, reward, next_state, done = self.replay_buffer.sample(self.batch_size)
state = torch.FloatTensor(state).to(device)
next_state = torch.FloatTensor(next_state).to(device)
action = torch.FloatTensor(action).to(device)
reward = torch.FloatTensor(reward).unsqueeze(1).to(device)
done = torch.FloatTensor(np.float32(done)).unsqueeze(1).to(device)
policy_loss = self.value_net(state, self.policy_net(state))
policy_loss = - policy_loss.mean()
next_action = self.target_policy_net(next_state)
target_value = self.target_value_net(next_state, next_action)
expected_value = reward + (1.0 - done) * self.gamma * target_value
expected_value = torch.clamp(expected_value, self.min_value, self.max_value)
value = self.value_net(state, action)
value_loss = self.value_criterion(value, expected_value.detach())
for name, param in self.value_net.named_parameters():
param.requires_grad = False
self.policy_optimizer.zero_grad()
policy_loss.backward()
self.policy_optimizer.step()
for name, param in self.value_net.named_parameters():
param.requires_grad = True
if self.update_count % 2 == 0:
self.value_optimizer.zero_grad()
value_loss.backward()
self.value_optimizer.step()
self.update_count += 1
for target_param, param in zip(self.target_value_net.parameters(), self.value_net.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - self.soft_tau) + param.data * self.soft_tau
)
for target_param, param in zip(self.target_policy_net.parameters(), self.policy_net.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - self.soft_tau) + param.data * self.soft_tau
)
训练模型:
def main():
env = gym.make('Pendulum-v1')
env = NormalizedActions(env)
ou_noise = OUnoise(env.action_space)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
hidden_dim = 256
ddpg = DDPG(action_dim, state_dim, hidden_dim)
max_frames = 50000
max_steps = 500
frame_idx = 0
rewards = []
batch_size = 128
while frame_idx < max_frames:
state = env.reset()
ou_noise.reset()
episode_reward = 0
for step in range(max_steps):
env.render()
action = ddpg.policy_net.get_action(state)
action = ou_noise.get_action(action, step)
next_state, reward, done, _ = env.step(action)
ddpg.replay_buffer.push(state, action, reward, next_state, done)
if len(ddpg.replay_buffer) > batch_size:
ddpg.update()
state = next_state
episode_reward += reward
frame_idx += 1
if done:
break
rewards.append(episode_reward)
env.close()
plot(frame_idx, rewards)
在更新policy网络时,未冻结value网络的参数,最终Reward曲线如图4所示:
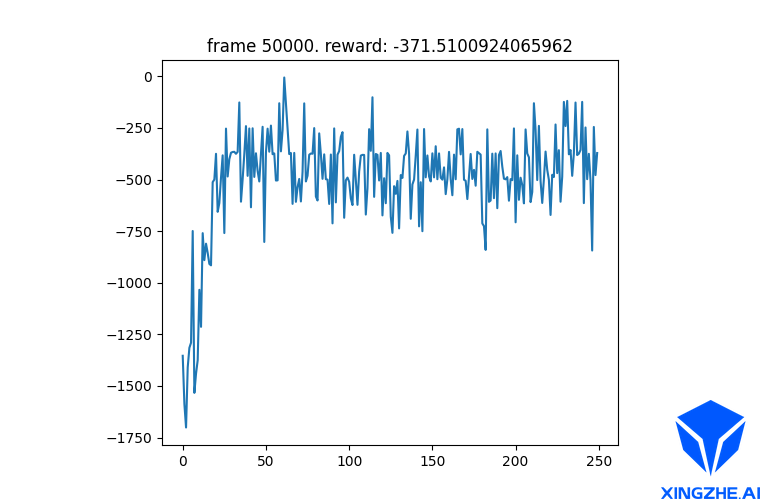
图4 Reward曲线
在更新policy网络时,冻结value网络的参数,最终Reward曲线如图5所示:
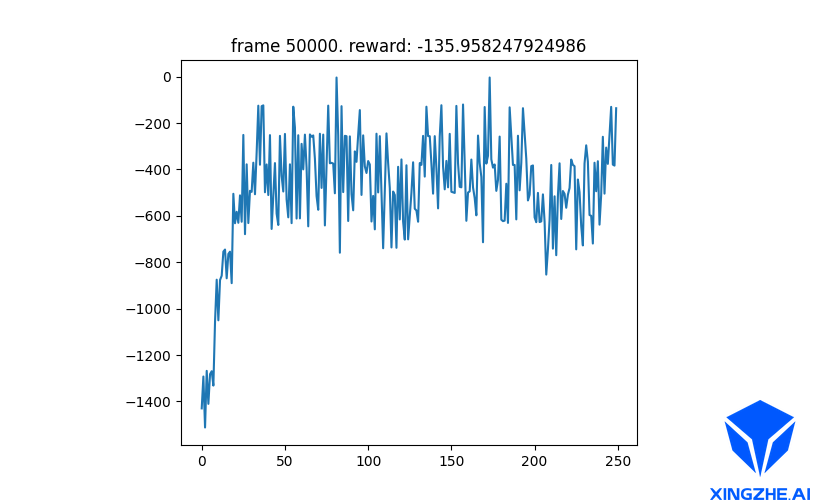
图5 Reward曲线
可以看出在更新policy网络时,由于没有冻结value网络的参数,使得更新波动较大,且更新目标不稳定,所以导致结果不如冻结后得到的reward。
总结
DDPG通过异策略的方式来训练一个确定性策略,在DQN的基础上做优化,较好的解决了连续动作空间处理的问题。
参考文献
[1]《Reinforcement+Learning: An+Introduction》
[2] https://blog.csdn.net/qq_37395293/article/details/114226081
我们是行者AI,我们在“AI+游戏”中不断前行。
前往公众号 【行者AI】,和我们一起探讨技术问题吧!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-03-30 requests+BeautifulSoup页面爬取数据对比测试
2021-03-30 APK反编译