
强化学习 | D3QN原理及代码实现
本文首发于:行者AI
2016年Google DeepMind提出了Dueling Network Architectures for Deep Reinforcement Learning,采用优势函数advantage function,使Dueling DQN在只收集一个离散动作的数据后,能够更加准确的去估算Q值,选择更加合适的动作。Double DQN,通过目标Q值选择的动作来选择目标Q值,从而消除Q值过高估计的问题。D3QN(Dueling Double DQN)则是结合了Dueling DQN和Double DQN的优点。
1. Dueling DQN
决斗(Dueling)DQN,网络结构如图1所示,图1中上面的网络为传统的DQN网络。图1中下面的网络则是Dueling DQN网络。Dueling DQN网络与传统的DQN网络结构的区别在于Dueling DQN的网络中间隐藏层分别输出value函数和advantage function优势函数,通过: - 计算出各个动作对应的Q值。
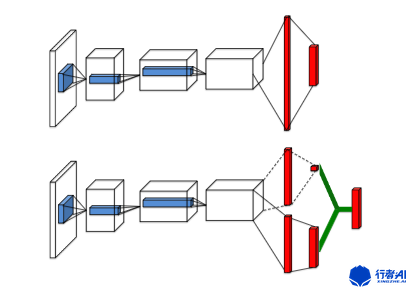
图1. Dueling DQN网络结构
2. D3QN
Double DQN只在DQN的基础上有一点改动,就不在这儿介绍了,如果对DQN还不了解的话,可以戳这里。
2.1 D3QN算法流程
-
初始化当前网络参数,初始化目标网络参数,并将网络参数赋值给网络,,总迭代轮数,衰减因子,探索率,目标Q网络参数更新频率,每次随机采样的样本数。
-
初始化replay buffer
-
for to do
1) 初始化环境,获取状态
2)while True
a)根据状态获取,输入当前网络,计算出各个动作对应的Q值,使用-贪婪法选择当前下对应的动作
b)执行动作,得到新的状态和奖励,游戏是否为结束状态
c)将{},5个元素存入
d)if
break
e)从中随机采样个样本,{},,计算当前网络的:
f)使用均方损失函数,计算loss,反向传播更新参数
g)if t % p == 0:
h)
2.2 D3QN的参数调优
-
epslion-Greedy策略,在设置探索率epslion,在不同环境中所选的有很大的“讲究”,一般离散的动作比较多,那么epslion就选择大一些,反之则选择小一些的,笔者在训练雅达利游戏Berzerk-ram-v0时,将epslion等于0.1变成0.2之后,学习效率得到了很大的提升。
-
关于网络结构,笔者认为不能使用过宽的网络,避免网络过于冗余,导致出现过拟合现象。网络的宽度一般不超过。
-
关于replay buffer的容量max数值的容量,一般设置为到。关于采样采用优先队列的排列的buffer,笔者正在探索中,在一些问题上并没有得到比较理想的效果。
-
batch size的选择,一般都会2的n次方,具体多大的值适合,还需要我们去尝试。
-
关于gamma的选择。一般选择为0.99、0.95、0.995等,切记万万不可等于1,等于1就会出现“Q值过大”的风险。
3. 代码实现
笔者实现了一个简单的D3QN(Dueling Double DQN)。抱歉并没有实现Prioritized Replay buffer。
3.1 网络结构
主要采用全连接网络,没有采用卷积。动作选择也写在了网络里面。
import random
from itertools import count
from tensorboardX import SummaryWriter
import gym
from collections import deque
import numpy as np
from torch.nn import functional as F
import torch
import torch.nn as nn
class Dueling_DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(Dueling_DQN, self).__init__()
self.state_dim = state_dim
self.action_dim = action_dim
self.f1 = nn.Linear(state_dim, 512)
self.f2 = nn.Linear(512, 256)
self.val_hidden = nn.Linear(256, 128)
self.adv_hidden = nn.Linear(256, 128)
self.val = nn.Linear(128, 1)
self.adv = nn.Linear(128, action_dim)
def forward(self, x):
x = self.f1(x)
x = F.relu(x)
x = self.f2(x)
x = F.relu(x)
val_hidden = self.val_hidden(x)
val_hidden = F.relu(val_hidden)
adv_hidden = self.adv_hidden(x)
adv_hidden = F.relu(adv_hidden)
val = self.val(val_hidden)
adv = self.adv(adv_hidden)
adv_ave = torch.mean(adv, dim=1, keepdim=True)
x = adv + val - adv_ave
return x
def select_action(self, state):
with torch.no_grad():
# print(state)
Q = self.forward(state)
action_index = torch.argmax(Q, dim=1)
return action_index.item()
3.2 Memory
用于存放经验
class Memory(object):
def __init__(self, memory_size:int):
self.memory_size = memory_size
self.buffer = deque(maxlen=self.memory_size)
def add(self, experience) -> None:
self.buffer.append(experience)
def size(self):
return len(self.buffer)
def sample(self, batch_size: int, continuous: bool = True):
if batch_size > self.size():
batch_size = self.size()
if continuous:
rand = random.randint(0, len(self.buffer) - batch_size)
return [self.buffer[i] for i in range(rand, rand + batch_size)]
else:
indexes = np.random.choice(np.arange(len(self.buffer)), size=batch_size, replace=False)
return [self.buffer[i] for i in indexes]
def clear(self):
self.buffer.clear()
3.3 超参数
GAMMA = 0.99
BATH = 256
EXPLORE = 2000000
REPLAY_MEMORY = 50000
BEGIN_LEARN_SIZE = 1024
memory = Memory(REPLAY_MEMORY)
UPDATA_TAGESTEP = 200
learn_step = 0
epsilon = 0.2
writer = SummaryWriter('logs/dueling_DQN2')
FINAL_EPSILON = 0.00001
3.4 主程序
设置优化器,更新网络参数等
env = gym.make('Berzerk-ram-v0')
n_state = env.observation_space.shape[0]
n_action = env.action_space.n
target_network = Dueling_DQN(n_state, n_action)
network = Dueling_DQN(n_state, n_action)
target_network.load_state_dict(network.state_dict())
optimizer = torch.optim.Adam(network.parameters(), lr=0.0001)
r = 0
c = 0
for epoch in count():
state = env.reset()
episode_reward = 0
c += 1
while True:
# env.render()
state = state / 255
p = random.random()
if p < epsilon:
action = random.randint(0, n_action-1)
else:
state_tensor = torch.as_tensor(state, dtype=torch.float).unsqueeze(0)
action = network.select_action(state_tensor)
next_state, reward, done, _ = env.step(action)
episode_reward += reward
memory.add((state, next_state, action, reward, done))
if memory.size() > BEGIN_LEARN_SIZE:
learn_step += 1
if learn_step % UPDATA_TAGESTEP:
target_network.load_state_dict(network.state_dict())
batch = memory.sample(BATH, False)
batch_state, batch_next_state, batch_action, batch_reward, batch_done = zip(*batch)
batch_state = torch.as_tensor(batch_state, dtype=torch.float)
batch_next_state = torch.as_tensor(batch_next_state, dtype=torch.float)
batch_action = torch.as_tensor(batch_action, dtype=torch.long).unsqueeze(0)
batch_reward = torch.as_tensor(batch_reward, dtype=torch.float).unsqueeze(0)
batch_done = torch.as_tensor(batch_done, dtype=torch.long).unsqueeze(0)
with torch.no_grad():
target_Q_next = target_network(batch_next_state)
Q_next = network(batch_next_state)
Q_max_action = torch.argmax(Q_next, dim=1, keepdim=True)
y = batch_reward + target_Q_next.gather(1, Q_max_action)
loss = F.mse_loss(network(batch_state).gather(1, batch_action), y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
writer.add_scalar('loss', loss.item(), global_step=learn_step)
# if epsilon > FINAL_EPSILON: ## 减小探索
# epsilon -= (0.1 - FINAL_EPSILON) / EXPLORE
if done:
break
state = next_state
r += episode_reward
writer.add_scalar('episode reward', episode_reward, global_step=epoch)
if epoch % 100 == 0:
print(f"第{epoch/100}个100epoch的reward为{r / 100}", epsilon)
r = 0
if epoch % 10 == 0:
torch.save(network.state_dict(), 'model/netwark{}.pt'.format("dueling"))
4. 资料
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端