Windows下JMeter分布式压测环境搭建
在项目中我们经常会有压测的需求,而小巧轻便且免费的JMeter也顺势成为了我们的主流压测工具。
JMeter是Apache组织开发的开源项目,设计之初是用于做性能测试的,同时它在实现对各种接口的调用方面做得比较成熟,因此,常被用作接口功能测试和性能测试。它能够很好的支持各种常见接口,如HTTP(S)、WebService、JDBC、FTP等、并以多种形式展示测试结果。
然而,在使用JMeter进行压测时,单机受限于内存,CPU,网络IO。我们发现当被测接口需要很高的并发量,或者有些接口访问数很高的时候,很容易就导致本地端口被占满,出现请求报错的情况。此时,本地的一些TCP配置、性能峰值就可能成为性能测试的瓶颈点。(服务器还没被压崩,本地已经崩了== )
因此,本文梳理了基于JMeter的分布式压测环境的搭建方法来解决这个问题,并能够满足参数化的需求。
1. Jmeter分布式执行原理
JMeter分布式执行时,选择其中一台作为调度机(master),其他机器作为执行机(slave);
master会在本地编辑好jmx压测脚本,执行时,master将jmx脚本发送至slave上,slaver执行时不需要启动jmeter,只需要把jmeter-sever.bat文件打开以非GUI形式执行;
slave执行完毕后将结果回传给master,并由master进行结果的汇总;
简单来说能达到的效果也就是:比如我在JMeter jmx脚本中设立的线程数是100,我在本地单机运行就会产生100次请求。如果我有1台master机器,2台slave机器,那么每次会向服务器发送的请求数总共就是100*3次。
2. 环境搭建方法
2.1 环境准备
(1)master:JMeter版本5.1.1,jdk版本1.8;
(2)slave:另外1台测试机,JMeter版本5.1.1,jdk版本1.8;
注意:JMeter和jdk版本与master一致,否则会出现一些意外的问题。具体的安装教程就不在这里做赘述了,网上有很多参考文章,可自行查阅。
2.2 master机器配置
(1)要保证master机器进行测试脚本的有效分发,需要配置slave机器的ip地址和端口号。在master安装目录的bin文件下,打开Jmeter/bin/jmeter.properties,找到remote_hosts=127.0.0.1的值并做修改:

PS:若有多台远程机需要都加进来,用逗号隔开,前面127.0.0.1为本机,默认端口为1099(可自定义)
(2)参数化配置
参数文件必须为绝对路径,否则脚本执行时无法找到参数配置文件,因为master调度机在分发jmx脚本时,不会分发脚本中对应的参数文件。因此,需要手动将参数文件分发给slave机器(并且放在绝对路径下对应的位置,不然slave会找不到文件)

2.3 slave机器的配置
(1)slave安装jdk和JMeter,并配置环境变量。尽量保持与master机器版本一致。两台slave机器JMeter的安装路径也保持一致,方便后续进行参数化配置;
(2)在Slave机器上,找到Jmeter/bin/jmeter.properties设置:server_port=1099;

(3)进入slave的bin目录下,执行jmeter-server.bat,启动JMeter服务;启动成功如下图:
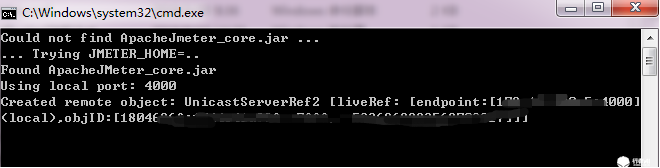
2.4 验证分布式环境是否搭建成功
启动master机器中JMeter的GUI界面,在运行-远程启动选项中可以看到配置好的slave机器,此时说明已经连接上远程slave机器。

如果你的环境在选择全部启动之后,没有报错,且发起请求数量和预先jmx设置的线程数一致,说明JMeter分布式测试环境搭建成功,可以开始测试了。
3. 问题及注意事项
-
master和slave必须是在同一网段;
-
关闭防火墙;
-
在master启动远程机器时,提示FileNotFoundException;
原因:自JMeter 4.0以来,RMI的默认传输机制将使用ssl协议。ssl协议需要密钥和证书才能工作。
解决方案:在Jmeter/bin/jmeter.properties中,找到server.rmi.ssl.disable,并设置:server.rmi.ssl.disable=true,表示不使用ssl。master和salve都得修改。

线程数的设定;
最终的并发线程数=jmx脚本设定的并发数*salve机器数量
JMeter分布式测试,是通过网络连接将执行脚本分发至机器上去的,也就是每个执行机拿到的脚本都是独立的,都会去执行jmx中设定的并发数。
同步定时器的使用;
该定时器的作用是用来设置集合点,从而阻塞线程,直到指定的线程数量达到后,再一起释放,可以瞬间产生很大的压力。那么在分布式中是怎样来应用的呢?
举个栗子:
我们在一个线程组中设立线程数为100,因为有3台slave,因此我们期望瞬时并发能达到300,故增加了一个固定定时器,并期望达到300的瞬时并发,如下图:
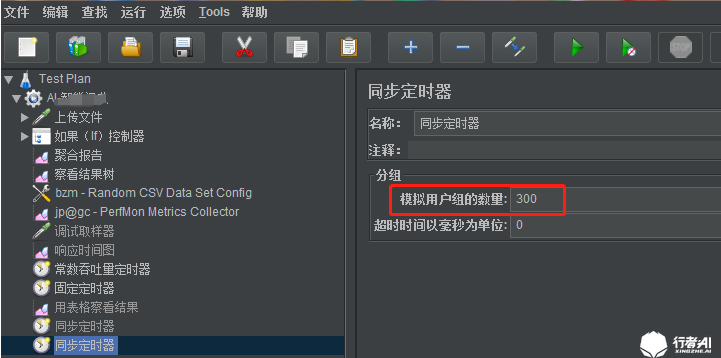
启用3台slave机器之后发现,并没有任何请求。这是因为同步定时器的设置只在当前的jvm中起作用,而3台 slave则是3个独立的jvm,而同步定时器是需要在线程数达到设置的线程数后才会释放,若没有达到就会一直死 等。显然每台独立的slave永远也不会达到300的线程数,因为每台slave设置的线程数也才100,所以不会执行。 因此, 在分布式的情况下,设立的同步定时器中的阻塞线程数不要大于每个jvm中启用的线程数。
slave机过了一段时间打印了“starting...”之后,一直没有变化,也没有finish,master机也没有执行结果;
查看JMeter-sever.log发现:connection refused to host:172.2x.xxx.x....
那该IP又是从哪里来的呢?最终发现,该IP为虚拟机网... 解决方案:如果远程负载机有虚拟网络,需要关闭虚拟网络。

结论:JMeter是JAVA应用,对于内存和CPU的占用较大,当使用单机进行测试时,对于高并发的压测,JMeter本身就会消耗本机很多资源,再想增大并发,一台机器就会显得有心无力,很容易达性能瓶颈。使用分布式压测,可以有效减少因本机性能对压测结果的影响。
PS:
我们是行者AI,我们在“AI+游戏”中不断前行。
如果你也对游戏感兴趣,对AI充满好奇,那就快来加入我们(hr@xingzhe.ai)。
