



Spring Cloud源码分析(四)Zuul:核心过滤器
通过之前发布的《Spring Cloud构建微服务架构(五)服务网关》一文,相信大家对于Spring Cloud Zuul已经有了一个基础的认识。通过前文的介绍,我们对于Zuul的第一印象通常是这样的:它包含了对请求的路由和过滤两个功能,其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础;而过滤器功能则负责对请求的处理过程进行干预,是实现请求校验、服务聚合等功能的基础。然而实际上,路由功能在真正运行时,它的路由映射和请求转发都是由几个不同的过滤器完成的。其中,路由映射主要通过pre类型的过滤器完成,它将请求路径与配置的路由规则进行匹配,以找到需要转发的目标地址;而请求转发的部分则是由route类型的过滤器来完成,对pre类型过滤器获得的路由地址进行转发。所以,过滤器可以说是Zuul实现API网关功能最为核心的部件,每一个进入Zuul的HTTP请求都会经过一系列的过滤器处理链得到请求响应并返回给客户端。
下面,我们就通过本文来详细了解一下Spring Cloud Zuul的过滤器!以下内容节选自《Spring Cloud微服务实战》,稍做加工。
过滤器
在Spring Cloud Zuul中实现的过滤器必须包含4个基本特征:过滤类型、执行顺序、执行条件、具体操作。这些元素看着似乎非常的熟悉,实际上它就是ZuulFilter接口中定义的四个抽象方法:
String filterType();
|
它们各自的含义与功能总结如下:
- filterType:该函数需要返回一个字符串来代表过滤器的类型,而这个类型就是在HTTP请求过程中定义的各个阶段。在Zuul中默认定义了四种不同生命周期的过滤器类型,具体如下:
- pre:可以在请求被路由之前调用。
- routing:在路由请求时候被调用。
- post:在routing和error过滤器之后被调用。
- error:处理请求时发生错误时被调用。
- filterOrder:通过int值来定义过滤器的执行顺序,数值越小优先级越高。
- shouldFilter:返回一个boolean类型来判断该过滤器是否要执行。我们可以通过此方法来指定过滤器的有效范围。
- run:过滤器的具体逻辑。在该函数中,我们可以实现自定义的过滤逻辑,来确定是否要拦截当前的请求,不对其进行后续的路由,或是在请求路由返回结果之后,对处理结果做一些加工等。
请求生命周期
上一节中,对于Spring Cloud Zuul中的过滤器类型filterType,我们已经做过一些简单的介绍,Zuul默认定义了四个不同的过滤器类型,它们覆盖了一个外部HTTP请求到达API网关,直到返回请求结果的全部生命周期。下图源自Zuul的官方WIKI中关于请求生命周期的图解,它描述了一个HTTP请求到达API网关之后,如何在各个不同类型的过滤器之间流转的详细过程。
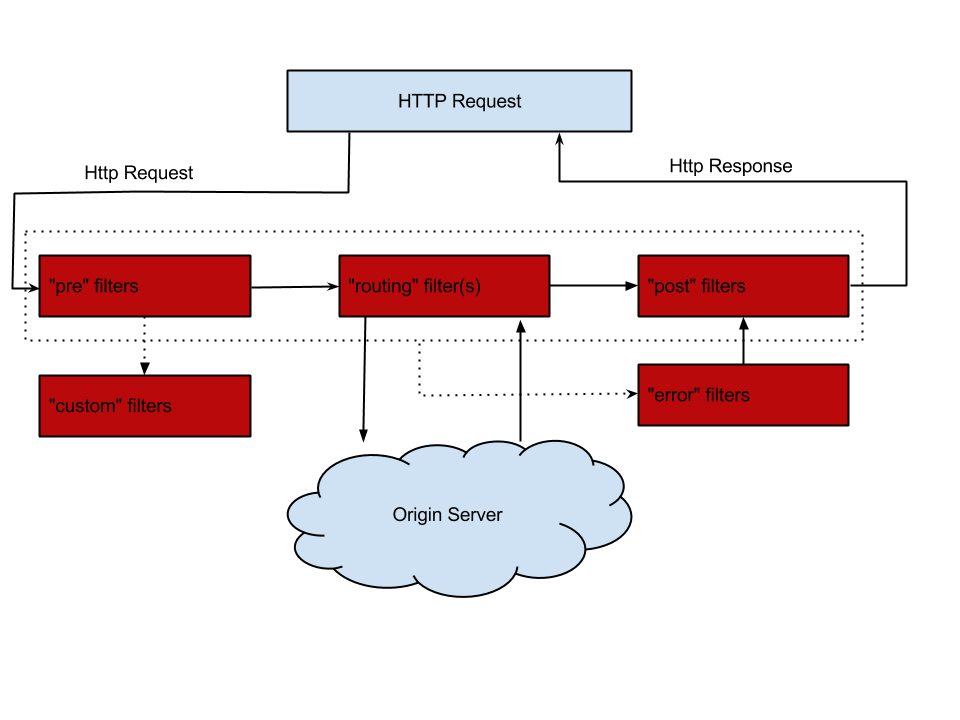 请求生命周期官方图解
请求生命周期官方图解
从上图中,我们可以看到,当外部HTTP请求到达API网关服务的时候,首先它会进入第一个阶段pre,在这里它会被pre类型的过滤器进行处理,该类型的过滤器主要目的是在进行请求路由之前做一些前置加工,比如请求的校验等。在完成了pre类型的过滤器处理之后,请求进入第二个阶段routing,也就是之前说的路由请求转发阶段,请求将会被routing类型过滤器处理,这里的具体处理内容就是将外部请求转发到具体服务实例上去的过程,当服务实例将请求结果都返回之后,routing阶段完成,请求进入第三个阶段post,此时请求将会被post类型的过滤器进行处理,这些过滤器在处理的时候不仅可以获取到请求信息,还能获取到服务实例的返回信息,所以在post类型的过滤器中,我们可以对处理结果进行一些加工或转换等内容。另外,还有一个特殊的阶段error,该阶段只有在上述三个阶段中发生异常的时候才会触发,但是它的最后流向还是post类型的过滤器,因为它需要通过post过滤器将最终结果返回给请求客户端(实际实现上还有一些差别,后续介绍)。
核心过滤器
在Spring Cloud Zuul中,为了让API网关组件可以更方便的上手使用,它在HTTP请求生命周期的各个阶段默认地实现了一批核心过滤器,它们会在API网关服务启动的时候被自动地加载和启用。我们可以在源码中查看和了解它们,它们定义于spring-cloud-netflix-core模块的org.springframework.cloud.netflix.zuul.filters包下。
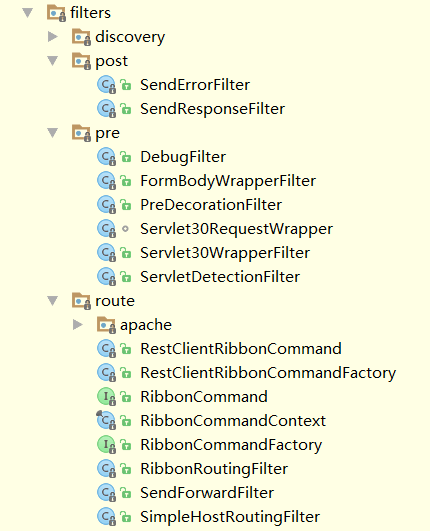 默认实现的核心过滤器
默认实现的核心过滤器
如上图所示,在默认启用的过滤器中包含了三种不同生命周期的过滤器,这些过滤器都非常重要,可以帮助我们理解Zuul对外部请求处理的过程,以及帮助我们如何在此基础上扩展过滤器去完成自身系统需要的功能。下面,我们将逐个地对这些过滤器做一些详细的介绍:
pre过滤器
- ServletDetectionFilter:它的执行顺序为-3,是最先被执行的过滤器。该过滤器总是会被执行,主要用来检测当前请求是通过Spring的DispatcherServlet处理运行,还是通过ZuulServlet来处理运行的。它的检测结果会以布尔类型保存在当前请求上下文的isDispatcherServletRequest参数中,这样在后续的过滤器中,我们就可以通过RequestUtils.isDispatcherServletRequest()和RequestUtils.isZuulServletRequest()方法判断它以实现做不同的处理。一般情况下,发送到API网关的外部请求都会被Spring的DispatcherServlet处理,除了通过/zuul/路径访问的请求会绕过DispatcherServlet,被ZuulServlet处理,主要用来应对处理大文件上传的情况。另外,对于ZuulServlet的访问路径/zuul/,我们可以通过zuul.servletPath参数来进行修改。
- Servlet30WrapperFilter:它的执行顺序为-2,是第二个执行的过滤器。目前的实现会对所有请求生效,主要为了将原始的HttpServletRequest包装成Servlet30RequestWrapper对象。
- FormBodyWrapperFilter:它的执行顺序为-1,是第三个执行的过滤器。该过滤器仅对两种类请求生效,第一类是Content-Type为application/x-www-form-urlencoded的请求,第二类是Content-Type为multipart/form-data并且是由Spring的DispatcherServlet处理的请求(用到了ServletDetectionFilter的处理结果)。而该过滤器的主要目的是将符合要求的请求体包装成FormBodyRequestWrapper对象。
- DebugFilter:它的执行顺序为1,是第四个执行的过滤器。该过滤器会根据配置参数zuul.debug.request和请求中的debug参数来决定是否执行过滤器中的操作。而它的具体操作内容则是将当前的请求上下文中的debugRouting和debugRequest参数设置为true。由于在同一个请求的不同生命周期中,都可以访问到这两个值,所以我们在后续的各个过滤器中可以利用这两值来定义一些debug信息,这样当线上环境出现问题的时候,可以通过请求参数的方式来激活这些debug信息以帮助分析问题。另外,对于请求参数中的debug参数,我们也可以通过zuul.debug.parameter来进行自定义。
- PreDecorationFilter:它的执行顺序为5,是pre阶段最后被执行的过滤器。该过滤器会判断当前请求上下文中是否存在forward.to和serviceId参数,如果都不存在,那么它就会执行具体过滤器的操作(如果有一个存在的话,说明当前请求已经被处理过了,因为这两个信息就是根据当前请求的路由信息加载进来的)。而它的具体操作内容就是为当前请求做一些预处理,比如:进行路由规则的匹配、在请求上下文中设置该请求的基本信息以及将路由匹配结果等一些设置信息等,这些信息将是后续过滤器进行处理的重要依据,我们可以通过RequestContext.getCurrentContext()来访问这些信息。另外,我们还可以在该实现中找到一些对HTTP头请求进行处理的逻辑,其中包含了一些耳熟能详的头域,比如:X-Forwarded-Host、X-Forwarded-Port。另外,对于这些头域的记录是通过zuul.addProxyHeaders参数进行控制的,而这个参数默认值为true,所以Zuul在请求跳转时默认地会为请求增加X-Forwarded-*头域,包括:X-Forwarded-Host、X-Forwarded-Port、X-Forwarded-For、X-Forwarded-Prefix、X-Forwarded-Proto。我们也可以通过设置zuul.addProxyHeaders=false关闭对这些头域的添加动作。
《Spring Cloud实战小贴士:Zuul处理Cookie和重定向》 一文中提到的加载敏感头信息加入到忽略头信息的操作调用就在PreDecorationFilter过滤器中实现。
route过滤器
- RibbonRoutingFilter:它的执行顺序为10,是route阶段第一个执行的过滤器。该过滤器只对请求上下文中存在serviceId参数的请求进行处理,即只对通过serviceId配置路由规则的请求生效。而该过滤器的执行逻辑就是面向服务路由的核心,它通过使用Ribbon和Hystrix来向服务实例发起请求,并将服务实例的请求结果返回。
- SimpleHostRoutingFilter:它的执行顺序为100,是route阶段第二个执行的过滤器。该过滤器只对请求上下文中存在routeHost参数的请求进行处理,即只对通过url配置路由规则的请求生效。而该过滤器的执行逻辑就是直接向routeHost参数的物理地址发起请求,从源码中我们可以知道该请求是直接通过httpclient包实现的,而没有使用Hystrix命令进行包装,所以这类请求并没有线程隔离和断路器的保护。
- SendForwardFilter:它的执行顺序为500,是route阶段第三个执行的过滤器。该过滤器只对请求上下文中存在forward.to参数的请求进行处理,即用来处理路由规则中的forward本地跳转配置。
post过滤器
- SendErrorFilter:它的执行顺序为0,是post阶段第一个执行的过滤器。该过滤器仅在请求上下文中包含error.status_code参数(由之前执行的过滤器设置的错误编码)并且还没有被该过滤器处理过的时候执行。而该过滤器的具体逻辑就是利用请求上下文中的错误信息来组织成一个forward到API网关/error错误端点的请求来产生错误响应。
- SendResponseFilter:它的执行顺序为1000,是post阶段最后执行的过滤器。该过滤器会检查请求上下文中是否包含请求响应相关的头信息、响应数据流或是响应体,只有在包含它们其中一个的时候就会执行处理逻辑。而该过滤器的处理逻辑就是利用请求上下文的响应信息来组织需要发送回客户端的响应内容。
这里不列出具体代码了,读者可自行根据类名来查看源码了解详细处理过程。下图是对上述过滤器根据顺序、名称、功能、类型做了综合的整理,可以帮助我们在自定义过滤器或是扩展过滤器的时候用来参考并全面地考虑整个请求生命周期的处理过程。
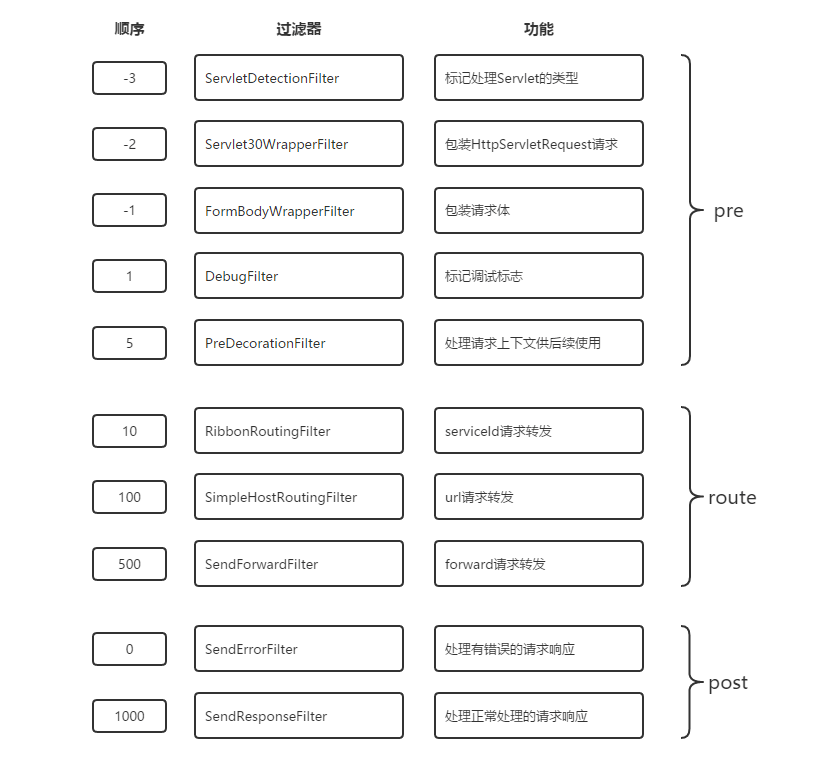 核心过滤器总结
核心过滤器总结
本文节选自《Spring Cloud微服务实战》,部分稍做加工,转载请注明出处

