

redis(二)高级用法
1 事务
redis的事务是一组命令的集合。事务同命令一样都是redis的最小执行单元,一个事务中的命令要么执行要么都不执行。
首先需要multi命令来开始事务,用exec命令来执行事务。

127.0.0.1:6379> multi OK 127.0.0.1:6379> hset user:1 name xiaoming QUEUED 127.0.0.1:6379> hset user:1 name daxiong QUEUED 127.0.0.1:6379> exec 1) (integer) 0 2) (integer) 0 127.0.0.1:6379> hgetall user:1 1) "name" 2) "daxiong" 3) "score" 4) "61"
multi代表事务的开始,返回ok表示成功;
exec代表事务的执行,返回各个命令的执行结果;
在multi和exec中间添加需要执行的命令。
在multi开始后,所有命令都不会执行,而是全部暂时保存起来,在执行exec命令后会按照命令保存的顺序依次执行各个命令。
如果事务执行过程中存在失败的情况下(某一个命令执行失败后其他命令会继续执行),需要开发人员自行处理后果。
注意:redis不支持回滚操作,导致redis的错误异常需要开发人员处理。
2 watch
watch命令可以监控一个或多个键值的变化,一旦其中一个键被改变,之后的事务就不会执行,而且监控会一直持续到exec命令。
127.0.0.1:6379> set key 1 OK 127.0.0.1:6379> watch key OK 127.0.0.1:6379> set key 2 OK 127.0.0.1:6379> multi OK 127.0.0.1:6379> set key 3 QUEUED 127.0.0.1:6379> exec (nil) 127.0.0.1:6379> get key "2"
3生存时间
(1)设置key的超时时间,超时后redis会自动删除指定key值,类似于memcache中的超时时间。
expire key seconds //设置成功返回1,失败返回0
127.0.0.1:6379> set session:aabb uid1122 OK 127.0.0.1:6379> expire session:aabb 300 (integer) 1 127.0.0.1:6379> del session:aabb (integer) 1 127.0.0.1:6379> expire session:aabb 300 (integer) 0 127.0.0.1:6379> expire session:aabb 300 (integer) 1 127.0.0.1:6379> ttl session:aabb (integer) 290
(2)查询剩余超时时间
ttl key
127.0.0.1:6379> expire session:aabb 300 (integer) 1 127.0.0.1:6379> ttl session:aabb (integer) 290
(3)取消超时时间
127.0.0.1:6379> get session:aabb "300" 127.0.0.1:6379> ttl session:aabb (integer) 280 127.0.0.1:6379> persist session:aabb (integer) 1 127.0.0.1:6379> ttl session:aabb (integer) -1
(4)如果使用设置相关的命令,会取消该键的超时间
缓存数据
在某些情况下,需要缓存一部分网站数据,而网站数据由需要持续的更新(假如需要两个小时更新一次),那么可以采用redis进行缓存这部分数据,设置数据的超时时间为2小时,
每当有请求访问的时候首先到redis中查找该数据是否存在,如果存在直接读取,如果不存在的话重新从数据库中读取该数据加载到redis中。
在缓存数据的时候需要考虑到被缓存数据的大小,如果缓存数据较大,会占用过多的内存资源,有必要在配置文件中限制内存的使用大小(maxmemory)。
当超过maxmemory的限制后,redis会根据maxmemory-policy参数指定的策略(包括LRU等算法)来删除不需要的键。
4 排序
sort命令支持对集合类型、类表类型、有序集合类型进行排序。
127.0.0.1:6379> lpush list 1 2 6 3 4 9 8 (integer) 7 127.0.0.1:6379> sort list 1) "1" 2) "2" 3) "3" 4) "4" 5) "6" 6) "8" 7) "9"
可以对有序集合的值进行排序:
127.0.0.1:6379> zadd set 50 2 40 3 20 1 60 5 (integer) 4 127.0.0.1:6379> sort set 1) "1" 2) "2" 3) "3" 4) "5"
sort命令可以添加desc来实现倒序排序
127.0.0.1:6379> sort set desc 1) "5" 2) "3" 3) "2" 4) "1"
BY参数
很多时候我们需要根据ID对应的对象的某一个属性进行排序,那么如何才能把多个不同的数据进行关联查询呢?
(1)首先,向userids中添加三个用户id
127.0.0.1:6379> lpush userids 1 2 3 (integer) 3
(2)其次,分别对三个用户添加分数
127.0.0.1:6379> set user_score_1 50 OK 127.0.0.1:6379> set user_score_2 30 OK 127.0.0.1:6379> set user_score_3 70 OK
(3)最后,使用sort、by命令来对对用户按照默认情况以及分数的递增和递减进行排序。
127.0.0.1:6379> sort userids 1) "1" 2) "2" 3) "3" 127.0.0.1:6379> sort userids by user_score_* 1) "2" 2) "1" 3) "3" 127.0.0.1:6379> sort userids by user_score_* desc 1) "3" 2) "1" 3) "2"
GET参数
get参数并不影响排序,它的作用是使sort命令返回的结果不再是元素自身的值,而是get参数中指定的键值,同by参数一样,支持字符串类型和散列类型的键。
127.0.0.1:6379> sort userids by user_score_* get user_name_* 1) "xiaoming" 2) "daxiong" 3) "xiaohong" 127.0.0.1:6379> sort userids by user_score_* desc get user_name_* 1) "xiaohong" 2) "daxiong" 3) "xiaoming"
STORE参数
store参数用于结果保存。
sort命令是redis的复杂命令之一,使用不好会造成性能的瓶颈。
sort命令的时间复杂度是O(n+mlog(m)),其中n是排序列表(集合和有序集合)中元素的个数,m是返回元素的个数。
Redis在排序前会建立一个长度为n的的容器来存储待排序元素,虽然是一个临时的过程,但是多个较大数据的排序操作则会严重影响系统的性能。
因此,在开发中需要注意:
(1)尽可能减少排序键中的元素个数,降低n
(2)使用Limit参数只获取需要的数据,降低n
(3)如果要排序的数据量较大,尽可能使用store名来缓存结果。
5 任务队列
任务队列一般适用于生产者和消费者之间通信的,那么在redis中很容易想到使用列表类型来实现任务队列,具体方法是创建一个任务队列,生产者主动lpush数据,而消费者去rpop数据,保持一个先进先出的循序。但是这样存在一个问题,消费者需要主动去请求数据,周期性的请求会造成资源的浪费,因此,redis提供了一个brpop的命令来解决这个问题。
BRPOP key timeout
brpop命令接收两个参数,第一个参数key为键值,第二个参数timeout为超时时间。BRPOP命令取数据时候,如果暂时不存在数据,该命令会一直阻塞直到达到超时时间。如果timeout设置为0,那么就会无限等待下去。
优先级队列
基于任务队列,如何实现优先级队列呢?
那么可以选择多个任务队列,而每个任务队列的任务优先级是不同的。
redis提供了下面的命令,会从左边第一个key开始读下去知道返回一个数据。
brpop key [key...] timetout
6 发布/订阅模式
redis提供了rabitmq类似的发布订阅模式,通过生产者使用下面的命令来发布消息,
PUBLISH CHANNEL MESSAGE
消费者通过下面的消息来订阅消息,
SUBSCRIBE CHANNEL MESSAGE
生产者:
#向channel.test发布消息 127.0.0.1:6379> publish channel.test hello (integer) 0 #返回0表明订阅者为0,没有发布消息 127.0.0.1:6379> publish channel.test hello (integer) 1 #返回n表明订阅者为n,成功发布给1个消费者
消费者:
#订阅channel.test消息 127.0.0.1:6379> subscribe channel.test Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "channel.test" 3) (integer) 1
#接收到来自channel.test的消息 1) "message" 2) "channel.test" 3) "hello"
原理:
发布订阅中使用到的命令就只有三个:PUBLISH,SUBSCRIBE,PSUBSCRIBE
- PUBLISH 用于发布消息
- SUBSCRIBE 也叫频道订阅,用于订阅某一特定的频道
- PSUBSCRIBE 也叫模式订阅,用于订阅某一组频道,使用glob的方式,比如xxx-*可以匹配xxx-a,和xxx-b,xxx-ddd等等
订阅频道: pubsub_channels
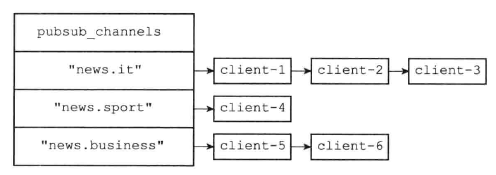
关联操作:
- 如果已经存在订阅者,则添加到链表的尾部
- 如果没有订阅者,那么创建频道,然后添加订阅者
删除操作:
- 找到对应的链表,进行删除
- 如果删除后,链表为空,则删除频道
模式订阅: pubsub_patterns
client-7订阅music.*
client-8订阅book.*
client-9订阅news.*
订阅模式:
- 新建一个pubsubPattern结构
- 添加到链表的尾部
退订模式:
- 查找相应的pubsubPattern然后删除
发送消息:
- 将消息发送给channel频道的所有订阅者
- 遍历整个pubsub_patterns表,查找匹配的模式,如果有一个或者多个模式与频道匹配,将消息发送给pattern模式的订阅者
相关命令:
- 查看所有的频道:PUBSUB CHANNELS
- 查询订阅者的数量:PUBSUB NUMSUB
- 查询服务器被订阅者的数量:PUBSUB NUMPAT
7 管道
redis的底层通信协议对管道提供了支持。通过管道可以一次性发送多条命令并在执行完后一次性将结果返回,
当一组命令中每条命令都不依赖之前命令的执行结果时就可以将这组命令一起通过管道发出。管道通过减少客户端与redis的通信次数来实现降低往返实验累计值的目的。
8 节省空间
(1)精简键名和键值
(2)redis为每种数据类型提供了两种内部编码。
例如散列类型的存储是通过散列表来实现的,redis会根据数据的多少来选择编码类型,
当数据较少的时候会采用紧凑但性能稍差的内部编码方式,而数据变多时会把编码方式改为散列表。

