

kubernetes 实践四:Pod详解
本篇是关于k8s的Pod,主要包括Pod和容器的使用、Pod的控制和调度管理、应用配置管理等内容。
Pod的定义
Pod是k8s的核心概念一直,就名字一样,是k8s中一个逻辑概念。Pod是docekr容器的集合,每个Pod中至少有一个Pause容器和业务容器。和docker容器关注单个可用的资源不同,Pod更多在应用层的角度,将多个docker容器组合来实现作为一个应用,它是k8s中最小的资源单位。
结合docker本身容器的特性,Pod中所有容器都是共享资源,如磁盘、网络、CPU、内存等,同时,一个Pod共用一个网络。
以下的yaml格式的Pod定义文件:
apiVersion: v1
kind: Pod
metadata:
name: string
namespace: string
labels:
- name: string
annotations:
- name: string
spec:
containers:
- name: string
image: string
imagePullPolicy: [Always | Never | IfNotPresent]
command: [string]
args: [string]
workingDir: string
volumeMounts: string
- name: string
mountPath: string
readOnly: boolean
ports:
- name: string
containerPort: int
hostPort: int
protocol: string
env:
- name: string
value: string
resources:
limits:
cpu: string
memory: string
requests:
cpu: string
memory: string
livenessProbe:
exec:
command: [string]
httpGet:
path: string
port: number
scheme: string
httpHeaders:
- name: string
value: string
tcpSocket:
port: number
initialDelaySeconds: 0
timeoutSeconds: 0
periodSeconds: 0
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure]
nodeSelector: object
imagePullSecrets:
- name: string
hostNetwork: false
volumes:
- name: string
emptyDir: {}
hostPath:
path: string
secret:
secretName: string
items:
- key: string
value: string
configMap:
name: string
items:
- key: string
- path: string
Pod定义文件模板中各属性的说明如下:



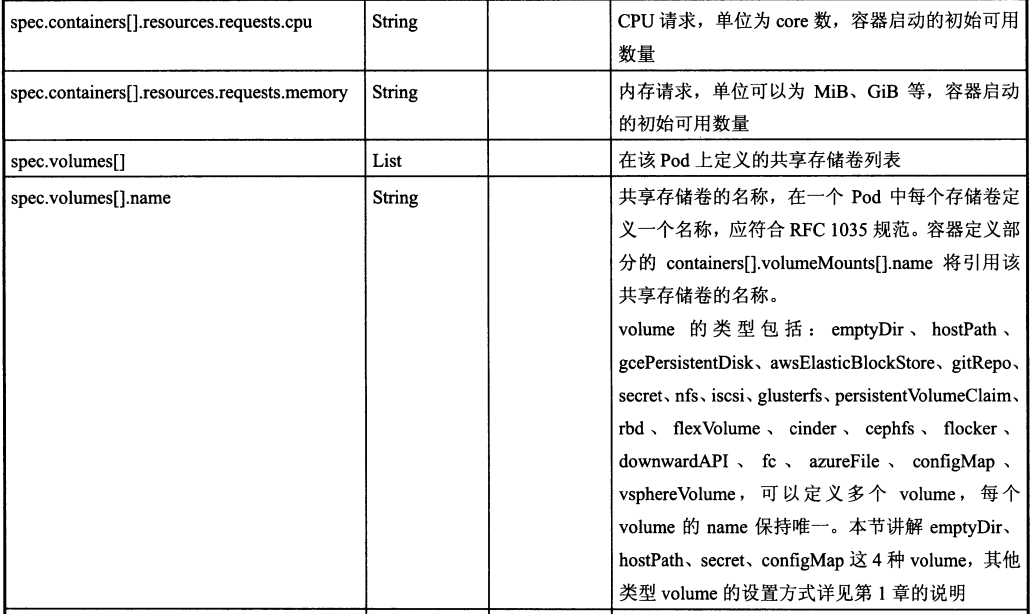
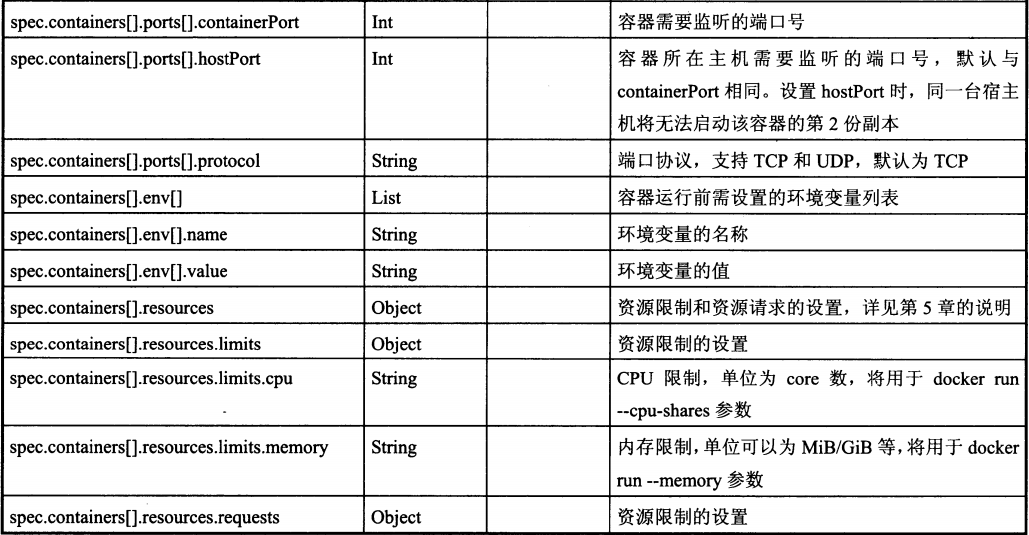
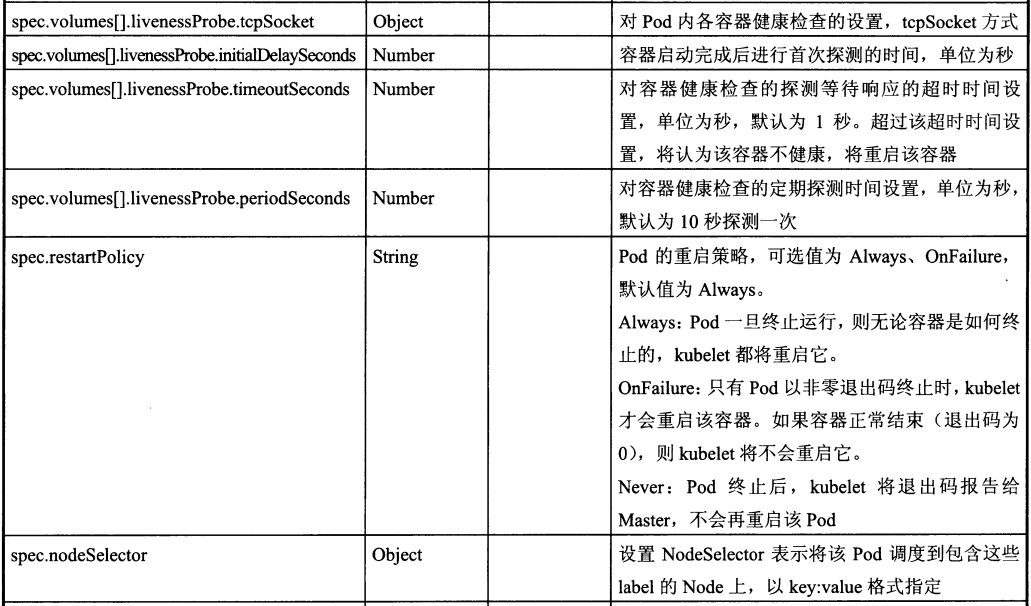

注:k8s的Pod启动命令不能是后台执行的,不然k8s会不断创建新的Pod而陷入无限循环中。如果docker镜像的命令无法改造为前台执行,可以使用开源工具Supervisor。或是 && tail -f xx 这样的组合命令。
静态Pod
静态Pod是由Kubelet进行管理的的仅存在于特定Node上的Pod。它们不能通过API Server进行管理,也无法和ReplicationController、Deployment或者DaemonSet进行关联,kubelet也不乏对它们进行健康检查。静态Pod总是由kubelet创建,也由kubelet来销毁。同时也只运行在该kubelet所在的Node上。
创建静态Pod由两种方式:配置文件和HTTP。
1.配置文件方式
静态文件存放的位置在kubelet的配置文件中定义,由参数staticPodPath指定,如果k8s集群由kubeadm搭建,那默认存储在目录/etc/kubernetes/manifests下。我们定义配置文件static-nginx.yaml:
apiVersion: v1
kind: Pod
metadata:
name: static-nginx
labels:
name: static-nginx
spec:
containers:
- name: static-nginx
image: nginx
ports:
- name: nginx
containerPort: 80
不需要使用命令创建,等他一会,kubelet会自动创建Pod
[root@k8s-master ~]# kubectl get pods
static-nginx-k8s-master 1/1 Running 0 12m
注:如果一段时间还是没有生成Pod,可以查看日志文件 /var/log/messages
删除Pod不是使用命令kubelet delete ...,而是直接删除/etc/kubernetes/manifests/static-nginx.yaml,kubelet自动会删除Pod。
2.HTTP方式
kubelet会定时根据参数--manifest-url来下载镜像并生成静态Pod。
注:比较巧妙地方的是kubeadm安装地管理节点 kube-apiserver、kube-sheduler、kube-controller-manager 组件都是静态的Pod。
Pod共享volume
之前说过,同一个Pod中的容器能共享Volume,那怎么将Volume共享给Pod呢。
关键在于配置文件中的spec.containers[].volumeMounts和spec.volumes[]参数,例如Pod中容器之间共享一个emptyDir的目录,名为logs,配置文件就可以这样:
apiVersion: v1
kind: Pod
metadata:
name: volume-pod
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: logs
mountPath: /usr/local/nginx/logs
- name: busybox
image: busybox
volumeMounts:
- name: logs
mountPath: /logs
volumes:
- name: logs
emptyDir: {}
这样一来,容器nginx和busybox就共享一个目录,且各自挂载的路径也不同。重点是用volumes定义要共享的volume,再在containers上使用volumeMounts参数来使用。
Pod ConfigMap
k8s 在 1.2版本时提供了一种统一的集群配置管理方案,就是ConfigMap,利用不同配置和不同容器分离开的方式,让复杂容器管理简单化。
ConfigMap的用法
ConfigMap供容器使用的典型用法如下:
- 生成为容器内的环境变量。
- 设置容器启动命令的启动参数(需设置为环境变量)。
- 以 Volume 的形式挂载为容器内部的文件或目录。
ConfigMap的创建
1.yaml文件方式
# cm.appvars.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-appvars
data:
apploglevel: info
appdatadir: /var/data
指定命令创建:
kubectl create -f cm-appvars.yaml
查看命令就用:
kubectl get configMap -o json
或者key:value也可以使用配置文件的别名和文件的内容。
data:
key-serverxml: |
<?xml ?>
......
......
<?xml ... ?>
key-properties: "key=...
....
"
注意格式问题。
2.kubelet命令行创建
直接通过kubectl create configmap也可以创建ConfigMap,可以使用参数--from-file或--from-literal指定内容。
通过--from-file参数从文件中创建,可以指定key的名称,可以在一个命令中创建包含多个key的ConfigMap,语法为:
kubectl create configmap NAME --from-file=[key=]source --from-file=[key=]source
通过--from-file参数从目录中进行创建,该目录的每个配置文件名都被设置为key,文件的内容被设置为value,语法为:
kubectl create configmap NAME --from-file=config-files-dir
通过--file-literal从文本中进行创建、直接将指定的key#=value#创建为ConfigMap的内容,语法为:
kubectl create configmap NAME --from-literal=key1=value1 --from-literal=key2=value2
ConfigMap的使用
ConfigMap的使用也有几种方式。
1.环境变量
apiVersion: v1
kind: Pod
metadata:
name: cm-test-pod
spec:
containers:
- name: cm-test
image: buysbox
env:
- name: APPLOGLEVEL # 定义环境变量名称
valueFrom: # key "apploglevel" 对应的值
configMapKeyRef:
name: cm-appvars # 环境变量的值取自 cm-appvars 中
key: apploglevel # key 为 "apploglevel"
- name: APPDATADIR
valueFrom:
configMapKeyRef:
name: cm-appvars
key: appdatadir
restartPolicy: Never
要点是环境变量中使用valueFrom参数指定configMapKeyRef
2.volumeMount的方式
...
spec:
containers:
- name: cm-test-app
image: busybox
volumeMounts:
- name: serverxml # 引用volume名
mountPath: /configfiles # 挂载到容器内的目录
volumes:
- name: serverxml
configMap:
name: cm-appconfigfiles # 使用 ConfigMap "cm-appconfigfiles"
items:
- key: key-serverxml # key=key-serverxml
path: server.xml # value将server.xml文件名进行挂载
如果在引用 ConfigMap 时不指定 items,则使用 volumeMount 方式在容器内的目录中为每个 item 生成一个文件名为 key 的文件。
ConfigMap 的限制条件
使用 ConfigMap 的限制条件如下:
- ConfigMap 必须在 Pod 之前创建。
- ConfigMap 也可以定义为属于某个 Namespace。 只有处于相同 Namespace 中的 Pod 可以引用它。
- ConfigMap 中的配额管理还未能实现。
- 静态Pod无法引用 ConfigMap。
- 在 Pod 对 ConfgMap 进行挂载(volumeMount)操作时,容器内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,目录中将包含 ConfigMap 定义的每个 item,如果该目录下原先还有其他文件,则容器内的该目录将会被挂载的 ConfigMap 进行覆盖。如果应用程序需要保留原来的其他文件,则需要进行额外的处理。可以通过将 ConfigMap 挂载到容器内部的临时目录,在通过启动脚本将配置文件复制或者链接到应用所用的实例配置目录下。
Pod生命周期和重启策略
Pod的状态
| 状态值 | 描述 |
|---|---|
| Peding | API Server 已经创建该Pod,但Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程 |
| Running | Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态 |
| Succeeded | Pod内所有容器均成功执行退出,且不会再重启 |
| Failed | Pod内所有容器均已退出,但至少有一个容器退出为失败状态 |
| Unknown | 由于某种原因无法获取该Pod的状态,可能由于容器通信不畅导致 |
Pod的RestartPolicy重启策略:
- Always:当容器失效时,有Kubelet自动重启容器。
- OnFailure:当容器终止运行且退出码不为0,由kubelet自动重启该容器。
- Never:不论容器运行状态如何,kubelet都不会启动该容器。
每种控制器对Pod的重启策略不同:
- RC和DaemonSet:必须设置为 Always,需要保证该容器持续运行。
- Job:OnFailure或Never,确保容器执行完成后不再重启。
- kubelet:在Pod失效时自动重启它,不论RestartPolicy设置为什么值,并且也不会对Pod进行健康检查。
Pod健康检查
Pod的健康状态检查可以通过两类探针来检查:LivenessProbe 和 ReadinessProbe。
- LivenessProbe:用于判断容器是否存活(running 状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回值永远是“Success”。
- ReadinessProbe:用于判断容器是否自动完成(ready 状态),可以接收请求。 如果ReadinessProbe探针检测到失败,则Pod的状态将被修改。Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的Endpoint。
kubelet定期执行LivenessProbe探针来诊断容器的健康状况。LivenessProbe有三种实现方式。
ExecAction:在容器内部执行一个命令,如果该命令的返回码为0,则表明容器健康。
...
spec:
containers:
- name: liveness
...
livenessProbe:
exec:
command:
- cat
- /tmp/health
initialDelaySeconds: 15 # 探针初始化检测时间间隔,单位为秒
timeoutSeconds: 1 # 返回超时时间,单位为秒。如果超时kubelet会重启容器
TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接。则表明容器健康。
...
spec:
containers:
- name: liveness
...
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 15 # 探针初始化检测时间间隔,单位为秒
timeoutSeconds: 1 # 返回超时时间,单位为秒
HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于等于400,则认为容器状态健康。
...
spec:
containers:
- name: liveness
...
livenessProbe:
httpGet:
path: /_status/healthz
port: 80
initialDelaySeconds: 15 # 探针初始化检测时间间隔,单位为秒
timeoutSeconds: 1 # 返回超时时间,单位为秒
Pod调度
在k8s中,Pod在大部分场景在都只是容器的载体而已,通常需要通过RC、Deployment、DaemonSet、Job等对象来完成Pod的调度与自动控制功能。
RC、Deployment全自动调度
RC的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终保持用户指定的副本数量。
Pod的调度策略除了有系统内置的Node调度算法,还可以在Pod的定义中使用NodeSelector或者NodeAffinity来指定满足条件的Node进行调度。
1.NodeSelector:定向调度
k8s上的服务Scheduler服务负责实现Pod的调度,整个调度通过执行一系列复杂的算法,最终为每个Pod计算出一个最佳的目标节点,这一过程是自动完成的。NodeSelector 调度就是通过给Node打上Label,使用Pod的NodeSelector属性来匹配的。
首先通过kubectl label命令给目标Node打上一些标签:
kubectl label node <node-name> <label-key>=<label-value>
然后,在Pod的定义中加上nodeSelector的设置
...
template:
...
spec:
...
nodeSelector:
label-key: label-value
注:如果有多个节点都定义了相同的label,scheduler就会根据调度算法从这组Node进行Pod调度,但是如果Pod上定义了nodeSelector参数,但是Node上无法找到对应的Node,则Pod无法被调度成功。
2.NodeAffinity:亲和性调度
NodeAffinity意为亲和性的策略调度,是一种更加灵活的调度策略。增加了In、NotIn、Exists、DoesNotExists、Gt、Lt等操作符来选择Node。同时还添加一些信息来设置亲和性调度策略:
- RequiredDuringSchedulingRequiredDuringExecution:类似于 NodeSelector,但在 Node不满足时,系统将从该Node上移除之前调度上的Pod。
- RequiredDuringSchedulingRequiredIgnoredExecution:在Node不满足条件时,系统不一定从该Node上移除之前调度上的Pod。
- PreferredDuringSchedulingRequiredIgnoredExecution:指定在满足条件的Node中,哪些Node应更优先地进行调度。同时在Node不满足条件时,系统不一定从该Node上移除之前调度地Pod。
NodeAffinity 对应地还有 PodAffinity 和 PodAntiAffinity。
下面来个实例,指定Pod运行到kubernetes.io/e2e-az-name值为e2e-az1 或e2e-az2的节点上面
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
annotations:
scheduler.alpha.kubernetes.io/affinity: >
{
"nodeAffinity": {
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "kubernetes.io/e2e-az-name",
"operator": "In",
"values": ["e2e-az1", "e2e-az2"]
}
]
}
]
}
}
}
another-annotation-key: another-annotation-value
spec:
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0
2.DaemonSet:特定场景调度
DaemonSet是k8s1.2版本新增地一种资源对象,用于在集群中每个Node上仅运行一份Pod的副本实例。它具有以下的应用实例:
- 在每个 Node 上运行一个 GlusterFS 存储或者 Ceph 存储的 daemon 进程。
- 在每个 Node 上运行一个日志采集程序,例如fluented或者logstach。
- 在每个 Node 上运行一个健康程序,采集该Node的运行性能数据。
DaemonSet 的 Pod 调度策略与 RC 类似,除了使用系统内置的算法在每台Node上进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围进行调度。
批处理调度
k8s在1.2版本以后,开始支持批处理类型的应用,我们可以通过k8s Job资源对象来定义并启动一个批处理任务。批处理任务通常并行或串行启动多个计算进程去处理一批工作项(work item)。
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
template:
metadata:
name: myjob
spec:
containers:
- name: hello
image: busybox
command: ["echo", "hello world"]
restartPolicy: Never
- batch/v1是当前job的Version
- 指定当前资源的类型时Job
- restartPolicy是指当前的重启策略。对于 Job,只能设置为 Never 或者 OnFailure。对于其他 controller(比如 Deployment)可以设置为 Always 。
查看批处理任务:
[root@k8s-master ~]# kubectl get jobs
NAME COMPLETIONS DURATION AGE
myjob 1/1 21s 4m44s
同时也可以指定批处理的并行个数和重复次数
...
spec:
completions: 6 # 重复次数
parallelism: 3 # 并行个数
...
同时k8s还支持定时任务,类似linux的Crontab。利用 CronJob 资源对象表示:
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["echo","hello k8s job!"]
restartPolicy: Never
- batch/v2alpha1 是当前 CronJob 的 apiVersion。
- 指明当前资源的类型为 CronJob。
- schedule 指定什么时候运行 Job,其格式与 Linux cron 一致。这里 */1 * * * * 的含义是每一分钟启动一次。
- jobTemplate 定义 Job 的模板,格式与前面 Job 一致。
但是创建CronJob会报错:
[root@k8s-master ~]# kubectl apply -f job/cronJob.yaml
error: unable to recognize "job/cronJob.yaml": no matches for kind "CronJob" in version "batch/v2alpha1"
修改kube-apiserver配置文件,/etc/kubernetes/manifests/kube-apiserver.yaml
...
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=192.168.10.20
- --runtime-config=batch/v2alpha1=true # 添加版本
...
重启kubelet
systemctl restart kubelet
重新创建CronJob
kubectl apply -f job/cronJob.yaml
Pod 的扩容和缩容
k8s RC的Scale机制能让我们在运行中修改Pod的数量。通过命令:
[root@k8s-master ~]# kubectl get rc
NAME DESIRED CURRENT READY AGE
redis-master 1 1 1 4d11h
redis-slave 2 2 2 4d11h
[root@k8s-master ~]# kubectl scale rc redis-slave --replicas=3
replicationcontroller/redis-slave scaled
关键在于指定参数--replicas的值,如果该值大于当前rc对应的Pod的值,就添加Pod;反之,则杀死。
除了使用命令kubectl scale之外,k8s还支持 HPA(Horizontal Pod Autoscaler)用于实现基于CPU使用率进行自动Pod扩容缩容的功能。HPA针对RC或Department对象,且Pod必须定义resource.request.cpu。HPA控制器基于Master的kube-controller-manager服务启动参数--horizontal-pod-autoscaler-sync-period定义的探测周期(默认值为15s),周期性地监测目标Pod地资源性能指标,并与HPA资源对象中地扩缩容条件进行对比,在满足条件时对Pod副本数量进行调整。
需要自动调整的RC或Deployment配置如下:
apiVersion: v1
kind: Service
metadata:
name: svc-hpa
namespace: default
spec:
selector:
app: myapp
type: NodePort ##注意这里是NodePort,下面压力测试要用到。
ports:
- name: http
port: 80
nodePort: 31111
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp-demo
namespace: default
labels:
app: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
resources:
requests:
cpu: 50m
memory: 50Mi
limits:
cpu: 50m
memory: 50Mi
HPA配置如下:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-v2
namespace: default
spec:
minReplicas: 1 ##至少1个副本
maxReplicas: 8 ##最多8个副本
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50 ##注意此时是根据使用率,也可以根据使用量:targetAverageValue
- type: Resource
resource:
name: memory
targetAverageUtilization: 50 ##注意此时是根据使用率,也可以根据使用量:targetAverageValue
其中关键的参数:
- scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController或ReplicaSet
- minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的CPU使用率为50%。
- metrics:目标指标值。
Pod的升级和回滚
k8s支持对以下资源的升级和回滚:
- Deployment
- Daemonset
- Statefulset
Deployment 的升级
以Deployment为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
使用升级命令:
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
或者使用kubectl edit命令修改nginx版本为1.9.1。
一旦镜像名(或Pod的定义)发生修改,则将触发系统完成Deployment所有运行Pod的滚动升级操作,使用命令查看:
kubectl rollout status deployment/nginx-deployment
Deployment的回滚
首先可以使用命令来查看可回滚的版本:
kubectl rollout history deployment/nginx-deployment
然后使用命令进行回滚:
kubectl rollout undo deployment/nginx-deployment
或者使用指定回滚版本:
kubectl rollout undo deployment/nginx-deployment --to-revision=3
Deployment 暂停和恢复回滚
如果Deployment的恢复比较复杂或者在回滚过程中临时需要修改,就可以先暂停回滚,当修改完成后再恢复。
暂停回滚使用命令
kubectl rollout pause deployment/nginx-deployment
暂停回滚后我们可以对deployment进行任意次的修改,如更新容器的资源限制:
kubectl set resources deployment nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi
修改完成后再恢复回滚:
kubectl rollout resume deployment/nginx-deployment

 浙公网安备 33010602011771号
浙公网安备 33010602011771号