kubernetes 实践一:基本概念和架构
这里记录kubernetes学习和使用过程中的内容。
CentOS7 k8s-1.13 flanneld-0.10 docker-18.06 etcd-3.3
kubernetes基本概念
kubernetes,又称k8s,是现今最流行的开源容器编排系统,是Google公司其内部十几年容器经验和技术的结晶,著名软件Google Borg的开源版本。它包含了以下特性:
- 自动化装箱:在不牺牲可用性的条件下,基于容器对资源的要求和约束自动部署容器。同时,为了提高利用率和节省更多资源,将关键和最佳工作量结合在一起。
- 自愈能力:当容器失败时,会对容器进行重启;当所部署的Node节点有问题时,会对容器进行重新部署和重新调度;当容器未通过监控检查时,会关闭此容器;直到容器正常运行时,才会对外提供服务。
- 水平扩容:通过简单的命令、用户界面或基于CPU的使用情况,能够对应用进行扩容和缩容。
- 服务发现和负载均衡:开发者不需要使用额外的服务发现机制,就能够基于Kubernetes进行服务发现和负载均衡。
- 自动发布和回滚:Kubernetes能够程序化的发布应用和相关的配置。如果发布有问题,Kubernetes将能够回归发生的变更。
- 保密和配置管理:在不需要重新构建镜像的情况下,可以部署和更新保密和应用配置。
- 存储编排:自动挂接存储系统,这些存储系统可以来自于本地、公共云提供商(例如:GCP和AWS)、网络存储(例如:NFS、iSCSI、Gluster、Ceph、Cinder和Floker等)。
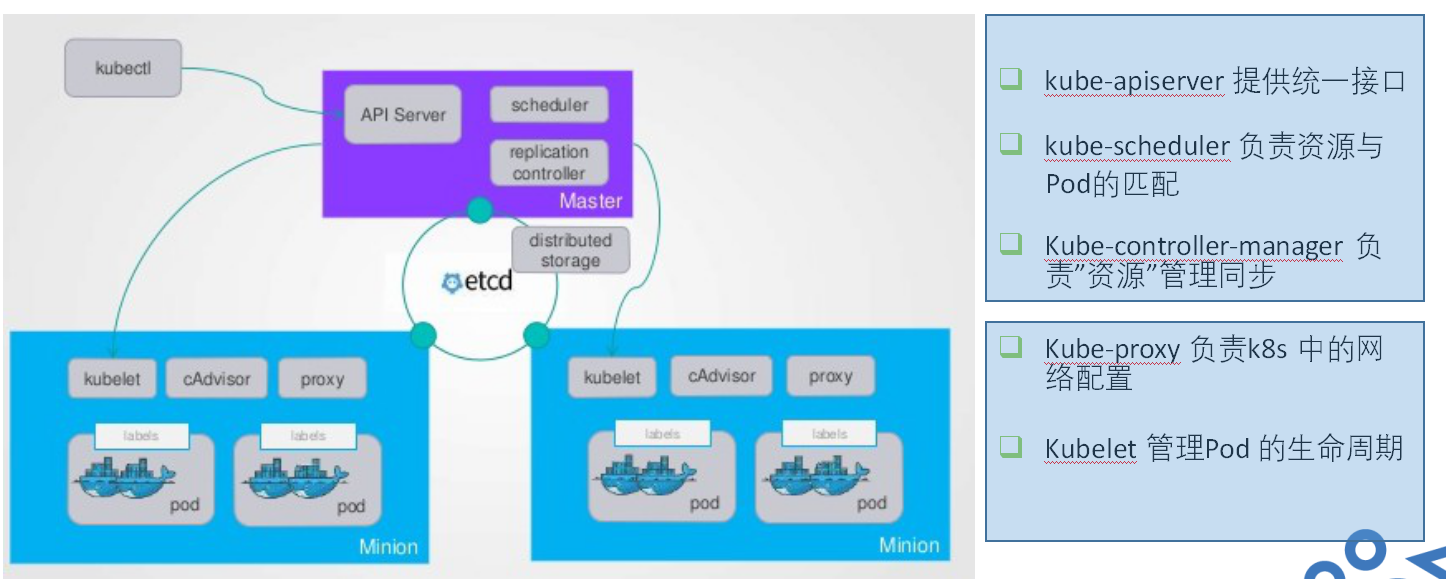
Master
Master是Kubernetes里的集群控制节点,每个k8s集群里都需要一个Master节点来负责整个集群的管理和控制,基本k8s上所有的控制命令都是由它发起的,如果它宕机了,那整个集群所有的控制命令都可能不可用了。所有一般它是一台物理机或虚拟机。
一般Master节点上需要启动以下服务:
- kube-apiserver (Kubernetes Api Server),提供 HTTP Rest 接口的关键服务进程,是 k8s 里所有资源增、删、查、改等操作的唯一入口,也是集群控制的入口服务。
- kube-controller-manager(Kubernetes Controller Manager),k8s 里所有资源对象的自动化中心,管理所有的资源。
- kube-scheduler(Kubernetes Scheduler),负责资源调度(Pod 调度)的服务。
其实还有一个etcd服务,存储 k8s 里所有资源对象的数据。
Node
k8s 集群中节点分为管理节点Master和工作节点Node,在早期版本里叫Minion。和Master一样,它一般是一台物理机或虚拟机。Master负责任务的分配调度,Node就负责任务执行,实际的工作都是在Node节点上(使用docker),当一个Node宕机是,它的任务会被分配到其他Node节点上。
Node节点也有一些关键的服务:
- kubelet:负责Pod对应容器的创建、启停等任务,同时与Master节点密切协作,实现集群管理的基本功能。
- kube-proxy:实现 Kubernetes Service 的通信与负载均衡机制的重要组件
- Docker Engine(docker):docker引擎,负责本机的容器创建和管理工作。
- flanneld:严格来说它不是 k8s 的核心组件,它用来管理 k8s 集群的网络。
使用命令
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.10.11 Ready <none> 2d7h v1.13.0
192.168.10.12 Ready <none> 2d2h v1.13.0
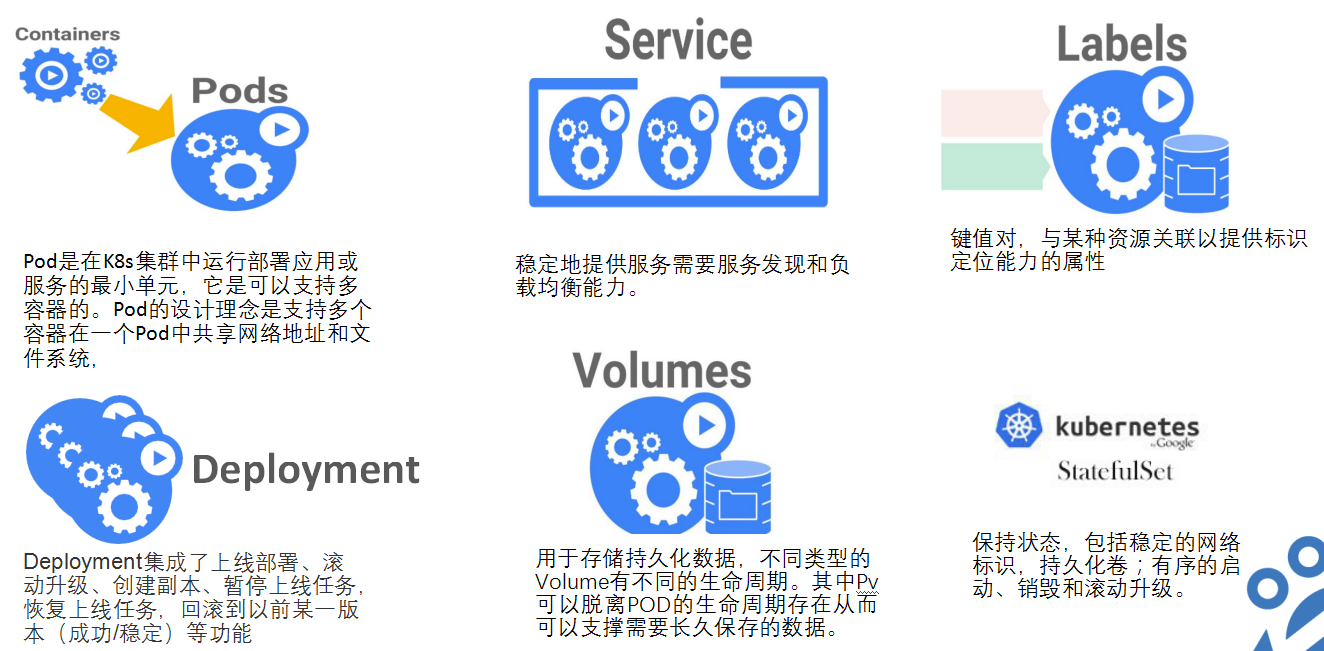
Pod
Pod 是 k8s 最重要也是最基本的概念,每个Pod都有一个特殊的被称为“根容器”的Pause容器。Pause容器对应的镜像属于 k8s 平台的一部分,每个Pod由Pause容器和业务容器组成。

为什么由Pod的概念和Pod这样的结构呢:原因如下:
- 在一组容器作为单元的情况下,我们难以对“整体”简单地进行判断及有效地行动。引入业务无关并且不易死亡地Pause容器作为Pod的根容器,以它地状态代表整个容器组地状态,以此来解决这个难题。
- Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间地文件共享问题。
Kubernetes为每个Pod都分配了唯一地IP地址,称之为Pod IP,一个Pod里地多个容器共享Pod IP地址。k8s采用虚拟二层网络技术,如flanneld、OpenvSwitch等实现集群内任务两个Pod之间地TCP/IP直接通信。
Pod有两种类型:普通地Pod和静态Pod(static Pod)
- 普通Pod 存储在etcd中,创建后就被k8s调度到某个Node上,随后被kubelet实例化成一组容器并启动。默认情况下,如果Pod中某个容器停止,则重启Pod中所有容器,如果所在地Node宕机,则调度到其他Node上。
- static Pod 存储在某个具体Node地一个具体文件中,并且只在此Node上启动运行。
以下是Pod、容器和Node的关系:

同时Pod还能对使用的服务器上的计算资源设置限额,配置如下:
spec:
containers:
- name: db
image: mysql
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Requests 为该资源的最小申请量,Limits则是上限值,超过可能被k8s kill并重启。memory单位为字节数,cpu单位m表示千分之一的配额,“250m”表示占用0.25个CPU
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-f8g28 1/1 Running 0 80m
myweb-529z6 1/1 Running 0 73m
myweb-dkb4n 1/1 Running 0 73m
myweb-ggvwz 1/1 Running 0 73m
myweb-j5t4x 1/1 Running 0 73m
myweb-l6wqv 1/1 Running 0 73m
nginx 1/1 Running 1 88m
Event
Event是一个事件的记录,记录了事件的最早产生时间、最后重现时间、重复时间、发起者、类型,以及导致此事件的原因等信息。Event通常会关联到某个具体的资源对象上、是排错的重要参考信息。
[root@k8s-master ~]# kubectl get events
LAST SEEN TYPE REASON KIND MESSAGE
100m Normal RegisteredNode Node Node 192.168.10.11 event: Registered Node 192.168.10.11 in Controller
99m Normal Starting Node Starting kube-proxy.
99m Normal Starting Node Starting kubelet.
Label
Label是一个 key=value的键值对,用来管理k8s中的资源。它可以附加到各种资源对象上,如Node、Pod、Service、RC等。资源和对象为多对多关系,支持在资源生命周期的任意阶段确定。它支持以下语法:
- name = redis:匹配具有标签name=redis的资源对象
- env != production:匹配所有不具有标签 env=production 的资源对象
- name in (redis-master, redis-slave):匹配所有具有标签name=redis-master或者name=redis-slave的资源对象
- name not in (php-frontend):匹配所有不具有标签 name = php-frontend 的资源对象
- name=redis,env!=production:匹配多个条件
Label Selector 在 k8s 中重要使用场景如下:
- kube-controller 进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量始终符合预期设定的全自动控制流程。
- kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载机制。
- 通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略,kube-scheduler进程可以实现Pod“定向调度”的特性。
Replication Controller(RC)
RC 是 k8s 系统中的核心概念之一,简单来说,它其实是定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值。它包含如下几个部分:
- Pod 期待的副本数(replicas)。
- 用于筛选目标Pod的Label Selector。
- 当Pod的副本数量小于预期数量的时候,用于创建新Pod的Pod模板(template)。
当我们定义了一个RC并提交到k8s集群中以后,Master节点上的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,否则系统就会再自动创建一些Pod。
在运行期间,我们可以通过修改RC的副本数量来实现Pod的动态缩放
kubectl scale rc myweb --replicas=3
注意:删除RC并不会影响通过该RC已经创建好的Pod。为了删除所有Pod,可以设置replicas的值为0,然后更新该RC。另外,kubectl提供了delete命令来一次性删除RC和RC控制的全部Pod
同时k8s支持 ”滚动升级“。
在 k8s1.2的时候,Replication Controller 升级成一个行的概念 Replica Set,它支持基于集合的 Label Selector,它结合Deployment实现一整套Pod创建、删除、更新的编排机制。
总的来说,RC支持以下的一些特性:
- 在大多数情况下,我们通过定义一个RC实现Pod的创建过程及副本数量的自动控制。
- RC里包括完整的Pod定义模板。
- RC通过Label Selector机制实现对Pod副本的自动控制。
- 通过改变RC里的Pod副本数量,可以实现Pod的扩容或缩容功能。
- 通过改变RC里Pod模板中的镜像版本,可以实现Pod的滚动升级功能。
Deployment
Deployment 是 k8s1.2 引入的概念,用于更好解决Pod的编排问题,我们可以把它看作RC的一次升级。
Deployment应用场景:
- 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程。
- 检查Deployment的状态来看部署动作是否完成(Pod副本的数量是否达到预期的值)。
- 更新Deployment以创建新的Pod(比如镜像升级)。
- 如果当前Deployment不稳定,则回滚到一个早先的Deployment版本。
例如我们创建一个yaml文件,tomcat-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 1
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
运行以下命令创建Deployment:
kubectl create -f test/tomcat-deployment.yaml
运行以下命令查看Deployment的信息
# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
frontend 1/1 1 1 5m7s
以上输出中涉及的信息如下:
- READY:当前数量/Pod副本期望值
- UP-TO-DATE:最新版本的Pod的副本数量,用于指示在滚动升级的过程中,有多少个Pod副本已经成功升级。
- AVAILABLE:当前集群中可用的Pod副本数量,即集群中当前存活的Pod数量。
Horizontal Pod Autoscaler (HPA)
Horizontal Pod Autoscaler 简称 HPA,意思是Pod横向自动扩容,与之前的RC、Deployment一样,它也是 k8s 资源对象。通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性的调整目标Pod的副本数。HPA有两种方式作为Pod负载的度量指标:
- CPUutilizationPercentage。
- 应用程序自定义的度量指标,比如服务在每秒内的相应的请求数(TPS或QPS)。
Service 服务
Service 也是 k8s 里的最核心的资源对象之一,k8s 里的每个Service其实就是微服务架构中的一个”微服务“。Service,Pod和RC的关系如下:
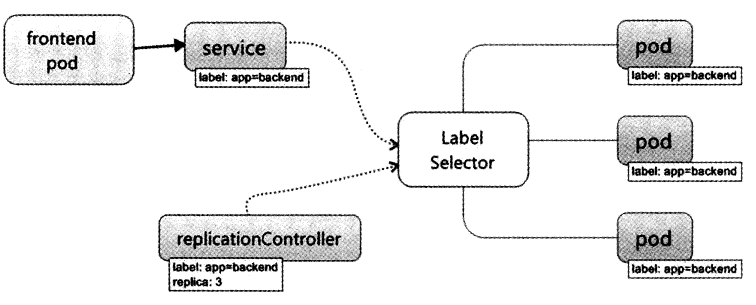
k8s 的Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实例,Service与其后端Pod副本集群之间则是通过Label Selector来实现”无缝对接“。而RC的作用实际上是保证Service的服务能力和服务质量始终处于预期的标准。
k8s 为每个Service分配一个全局唯一的虚拟IP地址,这个地址称为Cluster IP。
外部系统如何访问Service的呢?其实在 k8s 有“三种IP”:
- Node IP:Node 节点的额IP地址。Node IP是k8s集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个k8s集群。这也表明了k8s集群之外的节点访问k8s集群之内的某个节点或者TCP/IP服务的时候,必须要通过Node IP进行通信。
- Pod IP:Pod 的IP地址。它是Docker 根据docker0网桥的IP地址段进行分配的,通常是一个虚拟二层网络,因为k8s要求位于不同Node上的Pod能够彼此直接通信,所以k8s里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络直接通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。
- Cluster IP:Service 的 IP 地址。它是也是一个虚拟的IP,k8s集群外无法直接访问。
关于k8s Cluster IP的一些内容:
- Cluster IP仅仅作用于k8s Service这个对象,并由k8s管理和分配IP地址(来源于Cluster IP地址池)。
- Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础,并且它们属于k8s集群这样一个封闭的空间,集群外的节点如果要访问这个通信端口,则需要做一些额外的工作。
- 在k8s集群之内,Node IP网,Pod IP网与Cluster IP网之间的通信,采用的是k8s自定义的路由,与标准的IP路由不同。
Volume(存储卷)
Volume 是 Pod 中能够被多个容器访问的共享目录。k8s的Volume和docker的Volume不同,它定义在Pod上,被Pod中多个容器共享,同时它支持多个类型,如GlusterFs,Ceph等分布式文件系统。
Volume的使用也很简单,例如我们给一个Tomcat Pod添加一个名为dataVol的Volume,并Mount到容器的/mydata-data目录上,Pod的定义文件就可以这样写:
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
volumes:
- name: dastavol
emptyDir: {}
containers:
- name: tomcat-demo
image: tomcat
volumeMounts:
- mountPath: /mydata-data
name: datavol
imagePullPolicy: IfNotPresent
k8s Volume支持多种类型:
1.emptyDir
k8s 会自动分配一个目录,存在于Pod的生命周期中,数据的存放路径有kubelet指定。emptyDir的一些用途如下:
- 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留。
- 长时间任务的中间过程CheckPoint的临时保存目录。
- 一个容器需要从另一个容器获取数据的目录。
2.hostPath
hostPath 为在Pod上挂载宿主机上的文件或目录,它通常可以用于以下几个方面:
- 容器应用程序生成的日志文件需要永久保存时,可以使用宿主机的高速文件系统进行存储。
- 需要访问宿主机上Docker引擎内部数据结构的容器应用时,可以通过定义hostPath为宿主机/var/lib/docke目录,使容器内部应用可以直接访问Docker的文件系统。
使用这种类型的Volume时们需要注意以下几点:
- 在不同的Node上具有相同配置的Pod可能会因为宿主机上的目录和文件不同而导致对Volume上目录和文件的访问结果不一致。
- 如果使用了资源配额管理,则k8s无法将hostPath在宿主机上使用的资源纳入管理。
hostPath类型使用配置如下:
volumes:
- name: "persistent-storage"
hostPath:
path: "/data"
gcePersistentDisk()
使用这种类型的Volume表示使用谷歌云有云提供的永久磁盘(Persisten Disk,PD)存放Volume的数据,当Pod被删除时,PD只是被卸载(Umount)但不会被删除。使用gcePersistentDisk有以下限制条件:
- Node(运行kubelet的节点)需要是GCE虚拟机。
- 这些虚拟机需要与PD存在于相同的GCE项目和Zone中
通过gcloud命令即可创建一个PD:
gcloud compute disks create --size=500GB --zone=us-centroll-a my-data-disk
定义gcePersistentDisk类型的Volume的实例如下:
volumes:
- name: test-volume
gcePersistentDisk:
pdNamee: my-data-disk
fsType: ext4
awsElasticBlockStore
于GCE类似,该类型的Volume使用亚马逊公有云提供的EBS Volume存储数据,需要先创建一个EBS Volume才能使用awsElasticBlockStore。
使用awsElasticBlockStore具有如下限制:
- Node(运行kubelet的节点)需要时AWS EC2实例。
- 这些AWS EC2实例需要于EBS volume存在于相同的region和availablity-zone中。
- EBS只支持单个EC2实例mount一个volume。
通过aws ec2 create-volume命令可以创建一个EBS volume:
aws ec2 create-volume --availability eu-west-1a --size 10 --volume-type gp2
定义awsElasticBlockStore类型的Volume实例如下:
volumes:
- name: test-volume
awsElasticBlockStore:
volumeID: aws://<availability-zone>/<volume-id>
fsType: ext4
5.NFS
使用NFS网络文件系统提供的共享目录存储数据时,我们需要在系统中部署一个NFS Server。定义NFS类型的Volume实例如下:
volumes:
- name: test-volume
nfs:
server: nfs-server.localhost
path: "/"
6.其他类型的Volume
- iscsi:使用ISCSI存储设备上的目录挂载到Pod中。
- flocker:使用Flocker来管理存储卷。
- glusterfs:使用开源GlusterFS网络文件系统的目录挂载到Pod中。
- rbd:使用Linux块设备共享存储(Rados Block Device)挂载到Pod中。
- gitRepo:通过挂载一个空目录,并从GIT库clone一个git repository以供Pod使用。
- secret:一个secret volume 用于为Pod提供加密的信息,你可以定义在k8s中的secret直接挂载为文件让Pod访问。secret volume是通过tmfs(内存文件系统)实现的,所以这类类型的volume总不会持久化。
Persistent Volume 和 Persistent Volume Claim
Volume是定义在Pod上,属于“计算资源”的一部分,“网络存储”则是相对独立于“计算资源”而存在的一种实体资源。Persistent Volume(PV)和与之相关联的Persistent Volume Claim(PVC)就类似这个。
PV可以说是k8s集群中的某个网络存储中对应的一块存储,它与Volume的区别如下:
- PV只能是网络存储,不属于任何Node,但可以在每个Node上访问。
- PV并不是定义在Pod上,而是独立于Pod之外定义。
- PV目录只有几种类型:GCE Persistent Disks、NFS、RBD、ISCSI、AWS ElasticBlockStore、GlusterFS等。
PersistentVolumeClaim (PVC) 是对 PV 的申请 (Claim)。PVC 通常由普通用户创建和维护。需要为 Pod 分配存储资源时,用户可以创建一个 PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes 会查找并提供满足条件的 PV。
举个例子,一个NFS类型的PV,需要5G的存储空间:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /somepath
server: 172.17.0.2
PV的accessModes属性有以下选项:
- ReadWriteOnce:读写权限、并且只能被单个Node挂载。
- ReadOnlyMany:只读权限、允许被多个Node挂载。
- ReadWriteMany:读写权限、允许被多个Node挂载。
PV运行时有以下几种状态:
- Available:空闲状态
- Bound:已经绑定到某个PVC上。
- Released:对应的PVC已经删除,但资源还没有被集群收回。
- Failed:PV自动回收失败。
如果Pod想使用PV,就需要先定义一个PVC对象:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
然后配置Pod的Volume:
volumes:
- name: mypod
persistentVolumeClaim:
claimName: myclaim
Namespace
Namespace(命名空间)是k8s系统中另一个非常重要的概念,Namespace在很多情况下用于多租户的资源隔离,而且还能结合k8s的资源配额管理,限定不同租户能占用的资源。
k8s在自动之后,默认会创建一个“default”的Namespace,如果创建资源时,没有指定Namespace,默认就是“default”。
创建一个Namespace的命令如下:
kubectl create namespace test
查看Namespace则是使用:
# kubectl get ns
Annontation(注解)
Annontation于Label,也使用key/value键值对的形式进行定义。不同的是Label具有严格的命名规则,它定义的是k8s对象的元数据(Metadata),并且用于Label Select。而Annotation则是用户任务定义的“附加”信息,以便于外部工具进行查找。
一般来说,用Annontation来记录以下的信息:
- build信息、release信息、Docker镜像信息等。如时间戳、release id号、PR号、镜像hash值、docker register地址等。
- 日志库、监控库、分析库等资源库的地址信息。
- 程序调试工具信息,例如工具名称、版本号等。
- 团队的联系信息,例如电话号码、负责人名称、网址等。
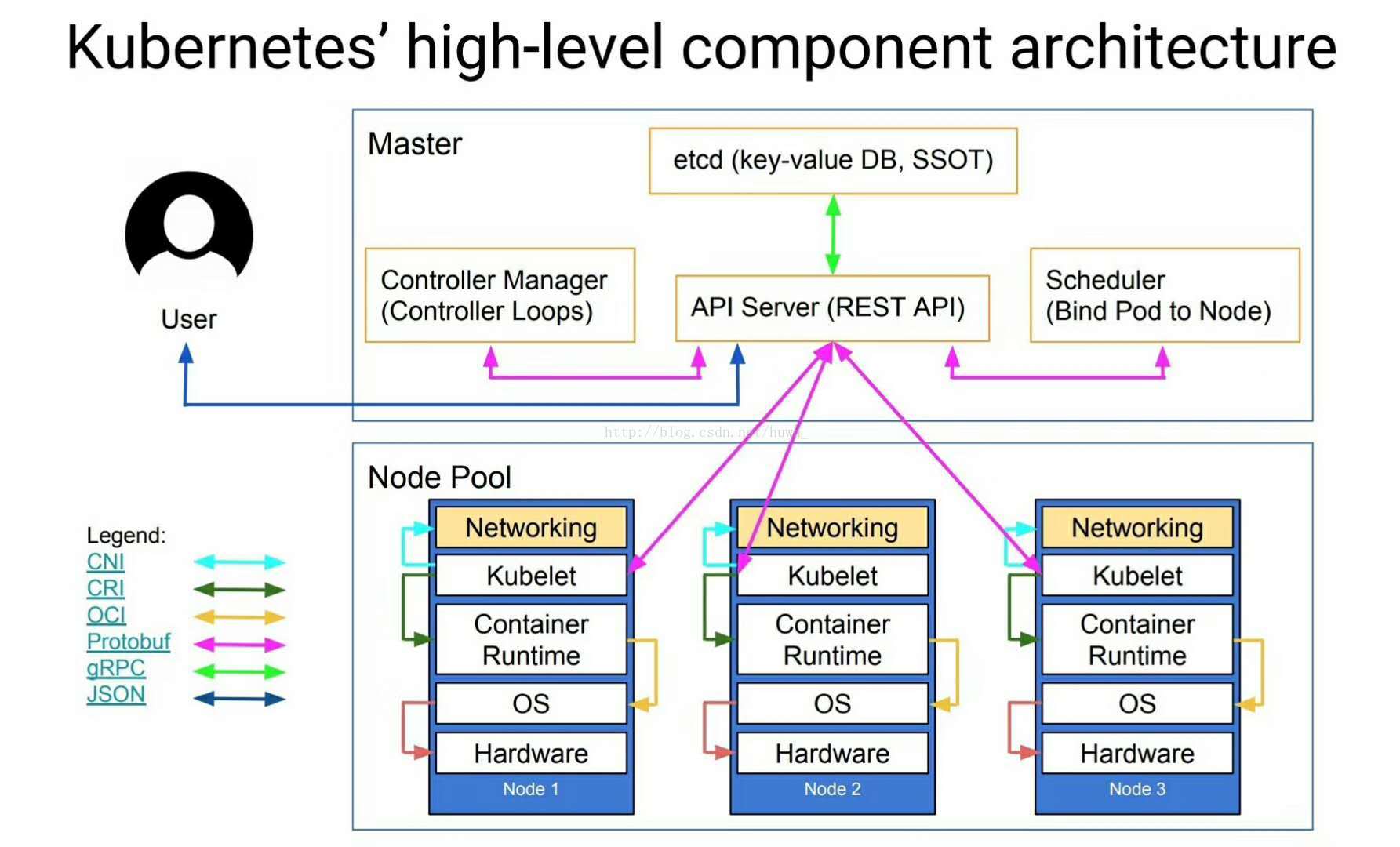
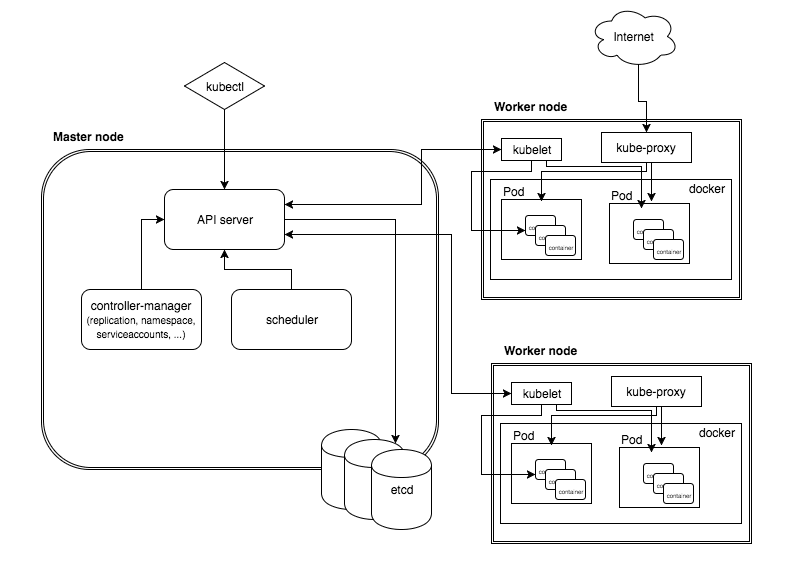
Kubernetes 架构
k8s整体架构
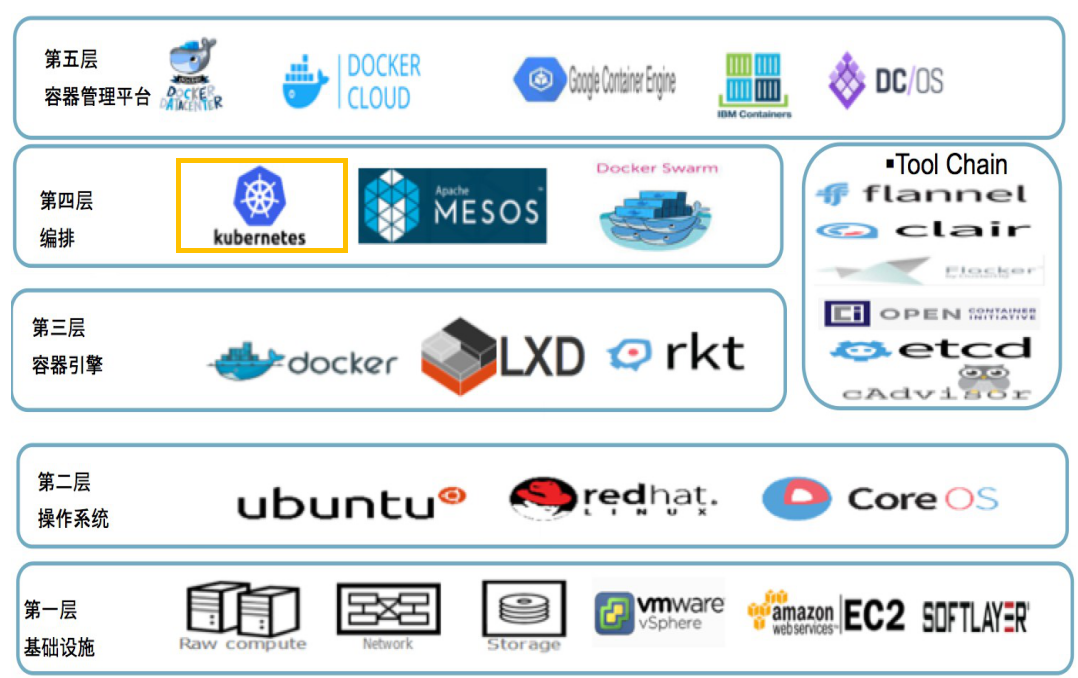
k8s生态信息
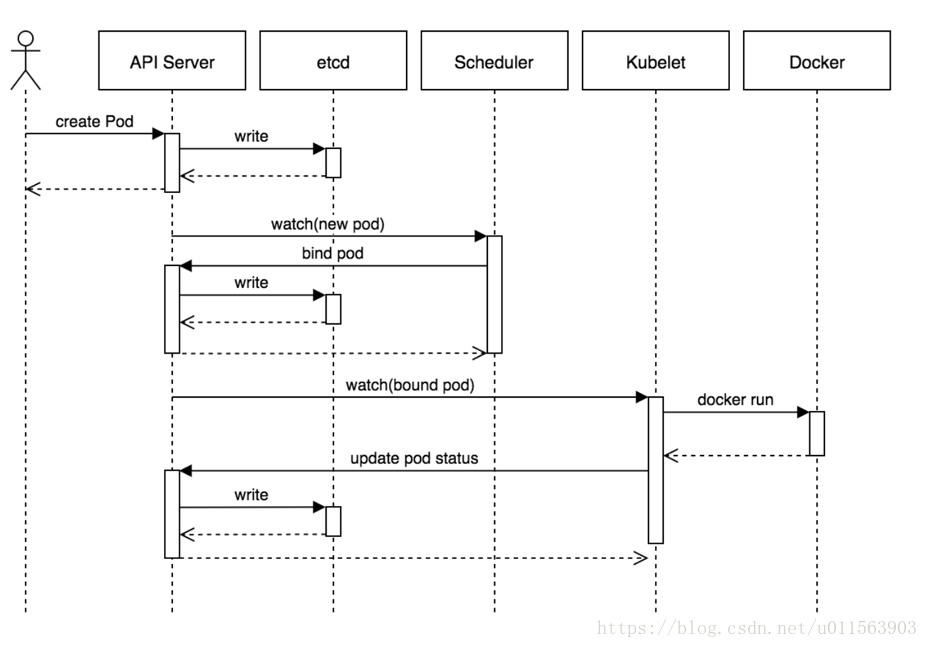
Pod创建流程