

项目地址:https://github.com/xyhcq/top250
我在本次项目中负责写爬虫中对数据分析的一部分,根据马壮分析过的html,我来进一步写代码获取数据,具体的功能及实现方法我已经写在了注释里:
首先,通过访问要爬的网站,并将网站保存在变量里,为下一步数据分析做准备
def getData(html): # 分析代码信息,提取数据 soup = BeautifulSoup(html, "html.parser")
这时,如果我们print soup,是会在窗口上显示出网站的源代码的。
先把第一部电影信息的源代码放这,便于理解

首先,我们要爬取电影名字,我们经过分析(网页代码层次还是比较清晰的)
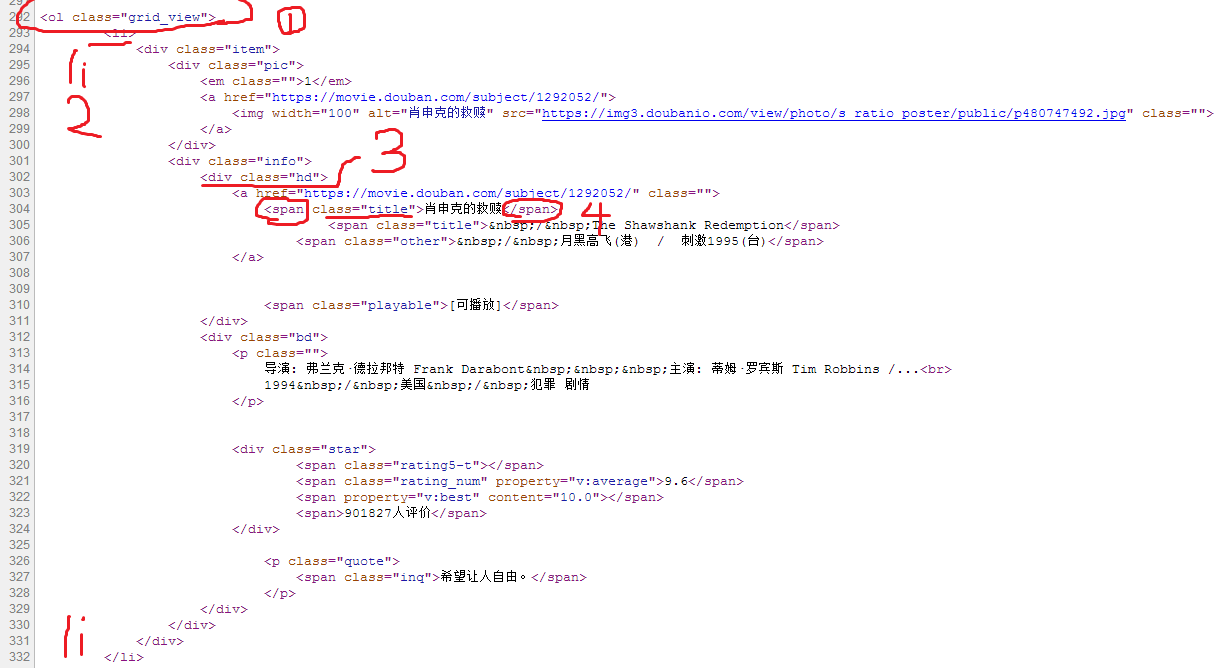
然后就可以写出爬取名字的部分了,
# 找到第一个class属性值为grid_view的ol标签 movieList=soup.find('ol',attrs={'class':'grid_view'}) # 找到所有的li标签 for movieLi in movieList.find_all('li'): # 找到第一个class属性值为hd的div标签 movieHd=movieLi.find('div',attrs={'class':'hd'}) # 找到第一个class属性值为title的span标签 # 获取电影名字 movieName=movieHd.find('span',attrs={'class':'title'}).getText() print movieName
经过运行,名字也确实能爬去并显示了,然后我们还是按照这种找标签的方法,以此类推,就能抓取其他的信息了:
# 获取电影链接 movieUrl=movieHd.find('a class="" href="') print movieUrl # 获取电影导演/演员 movieBd = movieLi.find('div', attrs={'class': 'bd'}) movieSF=movieBd.find('p',attrs={'class':''}).getText() print movieSF # 获取电影的评分 movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText() print movieScore #获取电影的评论数 movieEval=movieLi.find('div',attrs={'class':'star'}) movieEvalNum=re.findall(r'\d+',str(movieEval))[-1] print movieEvalNum
这里要说一下,如果找不到标签,有时候程序会卡住不动,排查发现问题出在简评上,所以;
# 获取电影短评 movieQuote = movieLi.find('span', attrs={'class': 'inq'}) # 有的电影没有短评,为防止报错,加次 if(movieQuote): print movieQuote.getText() else: print ('没有短评!')

