


服务器跑大量高负载程序,会造成cpu soft lockup。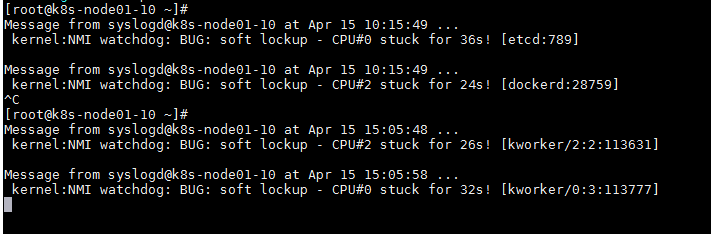
解决办法:
#追加到配置文件中
echo 30 > /proc/sys/kernel/watchdog_thresh
#查看
[root@git-node1 data]# tail -1 /proc/sys/kernel/watchdog_thresh
30
#临时生效
sysctl -w kernel.watchdog_thresh=30
#内核软死锁(soft lockup)bug原因分析
Soft lockup名称解释:所谓,soft lockup就是说,这个bug没有让系统彻底死机,但是若干个进程(或者kernel thread)被锁死在了某个状态(一般在内核区域),很多情况下这个是由于内核锁的使用的问题。
或者
vi /etc/sysctl.conf
kernel.watchdog_thresh=30
参考文章:
CentOS内核,对应的文件是/proc/sys/kernel/watchdog_thresh。
CentOS内核和标准内核还有一个地方不一样,就是处理CPU占用时间过长的函数,CentOS下是watchdog_timer_fn()函数。
如果你的内核是标准内核的话,可以通过修改/proc/sys/kernel/softlockup_thresh来修改超时的阈值
参考文献:https://zhidao.baidu.com/question/1829924822713415300.html
首先,这条信息可以输出,说明即使发生死锁或者死循环,还是有代码可以执行。第二,可以通过这个日志信息,找到对应的处理函数,这个函数所在的模块就是用来处理CPU被过度使用时用到的。所以通过这个事情,可以看到内核打印出的只言片语都有可能成为你解决问题的关键,一定要从重视这些信息,从中找出有用的东西。 我经常看的内核版本是官方的2.6.32内核,这个版本中我找到的函数是softlockup_tick(),这个函数在时钟中断的处理函数run_local_timers()中调用。这个函数会首先检查watchdog线程是否被挂起,如果不是watchdog线程,会检查当前占有CPU的线程占有的时间是否超过系统配置的阈值,即softlockup_thresh。如果当前占有CPU的时间过长,则会在系统日志中输出我们上面看到的那条日志。接下来才是最关键的,就是输出模块信息、寄存器信息和堆栈信息,检查softlockup_panic的值是否为1。如果softlockup_panic为1,则调用panic()让内核挂起,输出OOPS信息。代码如下所示:/** This callback runs from the timer interrupt, and checks * whether the watchdog thread has hung or not:*/void softlockup_tick(void){int this_cpu = smp_processor_id(); unsigned long touch_timestamp = per_cpu(touch_timestamp, this_cpu); unsigned long print_timestamp; struct pt_regs *regs = get_irq_regs(); unsigned long now; /* Warn about unreasonable delays: */ if (now <= (touch_timestamp + softlockup_thresh))return; per_cpu(print_timestamp, this_cpu) = touch_timestamp; spin_lock(&print_lock); printk(KERN_ERR BUG: soft lockup - CPU#%d stuck for %lus! [%s:%d]\n, this_cpu, now - touch_timestamp, current-comm, task_pid_nr(current)); print_modules(); print_irqtrace_events(current);if (regs)show_regs(regs);elsedump_stack(); spin_unlock(&print_lock); if (softlockup_panic) panic(softlockup: hung tasks);} 但是softlockup_panic的值默认竟然是0,所以在出现死锁或者死循环的时候,会一直只输出日志信息,而不会宕机,这个真是好坑啊!所以你得手动修改/proc/sys/kernel/softlockup_panic的值,让内核可以在死锁或者死循环的时候可以宕机。如果你的机器中安装了kdump,在重启之后,你会得到一份内核的core文件,这时从core文件中查找问题就方便很多了,而且再也不用手动重启机器了。如果你的内核是标准内核的话,可以通过修改/proc/sys/kernel/softlockup_thresh来修改超时的阈值,如果是CentOS内核的话,对应的文件是/proc/sys/kernel/watchdog_thresh。CentOS内核和标准内核还有一个地方不一样,就是处理CPU占用时间过长的函数,CentOS下是watchdog_timer_fn()函数。 这里介绍下lockup的概念。lockup分为soft lockup和hard lockup。 soft lockup是指内核中有BUG导致在内核模式下一直循环的时间超过10s(根据实现和配置有所不同),而其他进程得不到运行的机会。hard softlockup是指内核已经挂起,可以通过watchdog这样的机制来获取详细信息。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步