

Java并发笔记(一)
1. lock (todo)
2. 写时复制容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。CopyOnWrite并发容器用于读多写少的并发场景。Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器, 它们是CopyOnWriteArrayList和CopyOnWriteArraySet (没有map的写时复制容器,可以自己实现).
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
http://ifeve.com/java-copy-on-write/
3. 线程安全容器分类
- 同步容器,如Vector、Hashtable。这些类实现线程安全方式是:将它们的状态封装起来,并对每个公有方法都进行同步,使得每次只有一个线程能访问容器的状态。
同步容器类虽然都是线程安全的,但在某些情况下可能需要额外的客户端加锁来保护复合操作。
- 并发容器,如ConcurrentHashMap。并发容器用来改进同步容器的性能。同步容器将所有对容器状态的访问都串行化(包括读),严重降低并发性。
ConcurrentHashMap采用粒度更细的分段锁来实现多个线程的并发访问。
- 写时复制容器,如CopyOnWriteArrayList。在某些场合下用于替代同步容器,提供更好的并发性能,并且在迭代期间不需要对容器进行加锁或复制。
- 阻塞队列,如BlockingQueue。阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞。试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。同样,试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程使队列重新变得空闲起来,如从队列中移除一个或者多个元素,或者完全清空队列可用于多线程间协作运行,如生产者-消费者模型。比同步容器拥有更好的并发性能,因为当某线程进入synchronized代码块获得锁后,如果不满足一定条件时,会执行wait()方法重新释放锁。
http://ifeve.com/blocking-queues/
- 无
4. 线程中断 interrupt
Java曾经提供过抢占式中断,但问题多多,例如的Thread.stop。另一方面,出于Java应用代码的健壮性的考虑,降低了编程门槛,减少不清楚底层机制的程序员无意破坏系统的概率,这个问题很多,比如会破坏数据的完整性。
如今,Java的线程调度不提供抢占式中断,而采用协作式的中断。其实,协作式的中断,原理很简单,就是轮询某个表示中断的标记,我们在任何普通代码的中都可以实现。 例如下面的代码:
volatile bool isInterrupted; //… while(!isInterrupted) { compute(); }
interrupt就是这样的一个通知,将Thead里的中断标志位设为true,而线程能否退出,就看用户的代码对于这个通知是怎么处理的了。
对于处于sleep,wait,join等操作的线程(即线程已被阻塞),如果被调用interrupt()后,会抛出InterruptedException,然后线程的中断标志位会由true重置为false,因为线程为了处理异常已经重新处于就绪状态。这其实是在sleep,wait,join这些方法内部会不断检查中断状态的值,而方法自己抛出的InterruptedException。
实际上,JVM内部确实为每个线程维护了一个中断标记。但应用程序不能直接访问这个中断变量,必须通过下面几个方法进行操作:
public class Thread { //设置中断标记 public void interrupt() { ... } //获取中断标记的值 public boolean isInterrupted() { ... } //清除中断标记,并返回上一次中断标记的值 public static boolean interrupted() { ... } ... }
举个栗子:
public class InterruptDemo extends Thread { public static void main(String[] args) throws InterruptedException { //创建线程 InterruptDemo sleep = new InterruptDemo(); //启动线程 sleep.start(); //主线程中断5秒钟 Thread.sleep(5000); //sleep子线程被中断 sleep.interrupt(); } public void run() { try { //做一个无限循环,每一秒打印一条信息 while (true) { sleep(1000); System.out.println(getName() + " Is Running"); } } catch (InterruptedException e) { //被终端以后打印一条信息 System.out.println(getName() + " Is Interrupted"); return; } } }
运行结果如下:
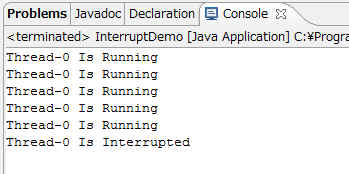
OK,打印5次信息后成功被中断。
对于以下代码:
while(true){ try { Thread.sleep(1000); }catch(InterruptedException ex) { logger.error("thread interrupted",ex); } }
当线程执行sleep(1000)之后会被立即阻塞,如果在阻塞时外面调用interrupt来中断这个线程,那么就会执行logger.error().
这个时候其实线程并未中断(因为抛出异常后中断标志又重置为false),执行完这条语句之后线程会继续执行while循环,开始sleep,所以说如果没有对InterruptedException进行处理,后果就是线程可能无法中断。
所以,在任何时候碰到InterruptedException,都要手动把自己这个线程中断。由于这个时候已经处于非阻塞状态,所以可以正常中断,最正确的代码如下:
while(!Thread.isInterrupted()){ try { Thread.sleep(1000); }catch(InterruptedException ex) { Thread.interrupt() } }
这样可以保证线程一定能够被及时中断。
总之,如果线程没有被阻塞,调用interrupt()将不起作用;否则,线程就将得到InterruptedException异常。
http://blog.csdn.net/hudashi/article/details/6958550
http://blog.csdn.net/lxcjie/article/details/8575169
http://blog.csdn.net/srzhz/article/details/6804756
http://www.ibm.com/developerworks/cn/java/j-jtp05236.html
5. 闭锁
Latch闭锁的意思,是一种同步的工具类。类似于一扇门:在闭锁到达结束状态之前,这扇门一直是关闭着的,不允许任何线程通过,当到达结束状态时,这扇门会打开并允许所有的线程通过。且当门打开了,就永远保持打开状态。
作用:可以用来确保某些活动直到其他活动都完成后才继续执行。
使用场景:
1)例如我们上例中所有人都到达饭店然后吃饭;
2)某个操作需要的资源初始化完毕
3)某个服务依赖的线程全部开启等等...
CountDowmLatch是一种灵活的闭锁实现,包含一个计数器,该计算器初始化为一个正数,表示需要等待事件的数量。countDown方法递减计数器,表示有一个事件发生,而await方法等待计数器到达0,表示所有需要等待的事情都已经完成。
http://blog.csdn.net/lmj623565791/article/details/26626391
6. 信号量Semaphore
计数信号量用来控制同时访问某个特定资源的操作数量,或者用来实现某种资源池,或者对容器施加边界。
可以用concurrent包中的Semaphore类来实现。当Semaphore的初始值为1时,可作为互斥量(mutex)。
acquire()方法获取Semaphore中的一个许可,如果没有许可,则阻塞直到拥有许可。
release()方法释放Semaphore中的一个许可。
7. 栅栏 (CyclicBarrier, Exchanger)
栅栏类似于闭锁,它能阻塞一组线程直到某个事件发生。栅栏与闭锁的关键区别在于,所有线程必须都到达栅栏位置,才能继续执行。
闭锁用于等待事件,栅栏用于等待其他线程。
例如,几个家庭决定在某个地方集合,所有人在超市门口碰头,之后再讨论下一步要做的事。
这里的人可以指代线程,线程没有执行完,即大家都在等待其他人一起到达后再执行后面的操作。而闭锁是指大家都已经执行完各自的线程(任务),某个领导人(另一事件) 等大家都到齐了准备开始后面的活动。
http://blog.csdn.net/lmc_wy/article/details/7866863
8. Executor框架
Executor框架是指java 5中引入的一系列并发库中与executor相关的一些功能类,其中包括线程池,Executor,Executors,ExecutorService,CompletionService,Future,Callable等。他们的关系为:
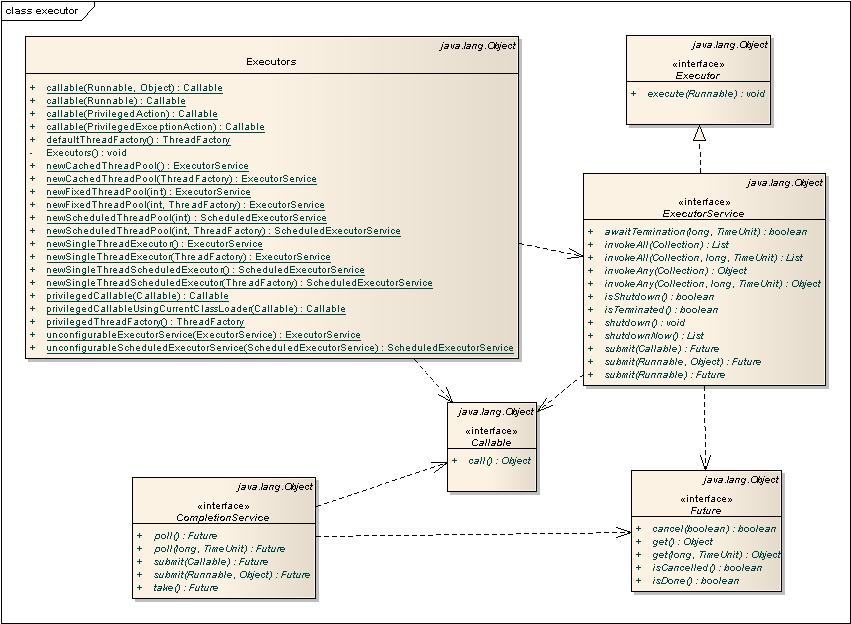
并发编程的一种编程方式是把任务拆分为一些列的小任务,即Runnable(或Callable),然后在提交给一个Executor执行,Executor.execute(Runnalbe) 。Executor在执行时使用内部的线程池完成操作。
使用Executor来执行多个线程的好处是用来避免线程的创建和销毁的开销,以提升效率。因此如果某些场景需要反复创建线程去处理同类事务的话,可以考虑使用线程池来处理。
- Executor接口只有一个execute(Runnable command)回调函数:
public interface Executor { /** * Executes the given command at some time in the future. The command * may execute in a new thread, in a pooled thread, or in the calling * thread, at the discretion of the <tt>Executor</tt> implementation. * * @param command the runnable task * @throws RejectedExecutionException if this task cannot be * accepted for execution. * @throws NullPointerException if command is null */ void execute(Runnable command); }
- Executors类本身并不实现线程池的功能,只是提供了获取ExecutorService的方法,而ExecutorService才是真正处理线程池相关逻辑的类。Executors下获取ExecutorService的方法有很多,用于获取各种不同的线程池,如单线程线程池、固定线程数的线程池等,不过最终还是调用ThreadPoolExecutor(ThreadPoolExecutor实现了ExecutorService)的构造函数来创建,如下:
public ThreadPoolExecutor(int corePoolSize,//最少线程数 int maximumPoolSize,//最大线程数 long keepAliveTime,//线程池满后,后续线程的等待时间 TimeUnit unit,//等待时间的单位 BlockingQueue<Runnable> workQueue,//等待线程队列 ThreadFactory threadFactory)//线程生产工厂
通过以上方法就可以创建一个线程池方法,可以限制线程的数量和等待队列中线程的等待时间等。然后如果要通过这个线程池来执行线程:
executorService.execute(new Runnable() { @Override public void run() { System.out.println("Execute in pool:" + Thread.currentThread().getId()); } });
通过execute()方法的执行是异步的,无法知道线程什么时候执行完毕。如果要想知道线程是否执行完毕,可以通过另外一个方法submit()来执行,然后获取到一个future对象, 然后通过get()方法来判断是否执行完毕:
Future<?> future = executorService.submit(new Runnable() { @Override public void run() { try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("Execute in pool:" + Thread.currentThread().getId()); } }); try { if(future.get()==null){ System.out.println("finish!!!"); } } catch (InterruptedException e) { //get()方法阻塞时被中断 e.printStackTrace(); } catch (ExecutionException e) { //任务里发生了exception e.printStackTrace(); }
但是通过这种方式只能知道线程是否执行完毕,却做不到将各线程的处理结果返回做归并处理。要实现这个目的可以使用Callable接口来封装任务逻辑,Callable和Runable的 唯一区别就是它支持返回处理结果:
Future<?> future = executorService.submit(new Callable<String>() { @Override public String call() throws Exception { return "hello callable!"; } }); try { System.out.println(future.get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); }
其中call()方法中返回的值,就是Future对象get()到的值。但是如果有多个线程在处理,然后要将这些线程的处理结果归并怎么做呢?当然可以使用ExecutorService来获取每个放到线程池的线程的Future对象,然后遍历的去get()然后去做归并处理。但是显然这种方法并不能做到先完成的就被先归并,而是取决于遍历到的时间,这显然降低了处理效率。要处理这种场景,可以使用另外一个Service–ExecutorCompletionService(ExecutorCompletionService继承自CompletionService):
public interface CompletionService<V> { Future<V> submit(Callable<V> task); Future<V> submit(Runnable task, V result);
//Retrieves and removes the Future representing the next completed task, waiting if none are yet present.
Future<V> take() throws InterruptedException;
//Retrieves and removes the Future representing the next completed task or <tt>null</tt> if none are present. Future<V> poll(); Future<V> poll(long timeout, TimeUnit unit) throws InterruptedException; }
public class ExecutorCompletionService<V> implements CompletionService<V> { // ExecutorCompletionService 组合了 Execute 和 BlockingQueue private final Executor executor; private final AbstractExecutorService aes; private final BlockingQueue<Future<V>> completionQueue;
public ExecutorCompletionService(Executor executor) { if (executor == null) throw new NullPointerException(); this.executor = executor; this.aes = (executor instanceof AbstractExecutorService) ? (AbstractExecutorService) executor : null; this.completionQueue = new LinkedBlockingQueue<Future<V>>(); } ... }
ExecutorService executorService = Executors.newFixedThreadPool(4); CompletionService<Long> completionService = new ExecutorCompletionService<Long>(executorService); for (int i = 0; i < 4; i++) { long sleep = (5 - i) * 1000; completionService.submit(new ExeWorker(sleep)); } for(int i=0;i<4;i++){ try { System.out.println(completionService.take().get()+" Get!"); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } class ExeWorker implements Callable<Long> { private long sleep; public ExeWorker(long sleep) { this.sleep = sleep; } @Override public Long call() throws Exception { System.out.println(sleep + " Executing!"); Thread.sleep(sleep); System.out.println(sleep + " Done!"); return sleep; } }
以线程的sleep时间为线程名称,然后输出结果为:
5000 Executing! 4000 Executing! 3000 Executing! 2000 Executing! 2000 Done! 2000 Get! 3000 Done! 3000 Get! 4000 Done! 4000 Get! 5000 Done! 5000 Get!
可以看出后面那个循环获取处理结果的地方的确是按先完成先返回的方式来实现。这种方法的一个约束就是需要知道有多少个线程在处理。其实CompletionService底层是通过一个BlockingQueue来存放处理结果,你也可以使用它自身封装好的带超时的poll方法来获取返回结果。
http://www.iteye.com/topic/366591
http://blog.csdn.net/yanhandle/article/details/9037401
http://blog.csdn.net/linghu_java/article/details/17123057
9. ThreadLocal(todo)
10. ThreadPoolExecutor (todo)
http://blog.csdn.net/wangwenhui11/article/details/6760474
http://blog.csdn.net/cutesource/article/details/6061229
http://dongxuan.iteye.com/blog/901689

 浙公网安备 33010602011771号
浙公网安备 33010602011771号