2. 了解实时分析的基础知识
个人、公司和其他组织对技术的使用的增加,以及智能设备和 Internet 访问的激增,导致可生成、捕获和分析的数据量大幅增加。
这些数据中的大部分数据都可以作为永久数据流实时(或至少是准实时)进行处理,从而创建显示即时见解和趋势或在事件发生时立即采取响应操作的系统。
了解批处理和流处理
数据处理就是通过某个过程将原始数据转换为有意义的信息。
两种用于处理数据的一般方法:
- 批处理,在此方法中,收集并存储多项数据记录,然后在一次操作中一起处理它们。
- 流处理,在此方法中,持续监视数据源,并在出现新数据事件时实时处理数据源。
了解批处理
在批处理中,收集并存储新到达的数据元素,整个组以批处理方式一起处理。
处理每个组的确切时间可以通过多种方式来确定。
例如,可以根据计划的时间间隔(例如,每小时)处理数据,也可以在到达特定数量的数据时触发数据处理,或者作为某些其他事件的结果进行处理。
批处理的优点:
- 可以在方便的时间处理大量数据。
- 可以计划在计算机或系统可能处于空闲状态(如整夜)或在非高峰时间运行。
批处理的缺点:
- 引入数据和获取结果之间的时间延迟。
- 在执行批处理之前,必须准备好批处理作业的所有输入数据。这意味着必须仔细检查数据。在批处理作业期间发生的数据问题、错误和程序崩溃会使整个进程停止运行。 必须仔细检查输入数据,然后才能再次运行作业。 即使是微小的数据错误也可能会阻止批处理作业运行。
了解流处理
在流式处理中,每个新数据在到达时就会得到处理。
与批处理不同,不存在等待下一批要处理的数据的情况,而是将数据作为独立单位实时进行处理,不视为一次处理一个的批次。
在连续生成新动态数据的情况下,流式数据处理非常有用。
流数据的现实生活中的示例包括:
- 金融机构会实时跟踪股票市场的变化,计算风险值,并根据股票价格变动自动重新平衡投资组合。
- 在线游戏公司收集有关玩家游戏交互的实时数据,并将数据馈送到其游戏平台。然后,它会实时分析数据,提供奖励和动态体验来吸引玩家。
- 一个房地产网站需要跟踪移动设备中的数据子集,并基于其地理位置对要访问的房产提供实时房产建议。
流处理非常适合需要实时响应的时间关键操作。 例如,监控建筑物烟雾和热量的系统需要触发警报并为门解锁,以便在发生火灾时居民能够立即逃离。
了解批处理数据和流式处理数据之间的差异
批处理和流式处理之间除了处理数据的方式以外,还有一些其他不同之处:
- 数据范围:批处理可处理数据集中的所有数据。 流式处理通常只能访问接收到的最新数据,或在滚动时间范围(例如过去 30 秒)内访问。
- 数据大小:批处理适用于高效处理大型数据集。 流式处理适用于单个记录或包含少量记录的小批数据。
- 性能:延迟是接收和处理数据所需的时间。 批处理的延迟通常是几个小时。 流式处理通常会立即发生,延迟以秒或毫秒计。
- 分析:通常使用批处理来执行复杂的分析。 流式处理用于简单的响应功能、聚合或计算(例如移动平均值)。
结合批处理和流式处理
许多大规模分析解决方案包括批处理和流处理的混合,同时支持历史和实时数据分析。
流处理解决方案通常捕获实时数据,通过筛选或聚合这些数据对其进行处理,并通过实时仪表板和可视化效果呈现它们(例如,显示当前一小时内经过道路的行驶的汽车总数),同时也将处理后的结果保存在数据存储中,以便与批处理数据一起用于历史分析(例如,用于分析过去一年的交通量)。
即使不需要对数据进行实时分析或可视化,也经常使用流技术来捕获实时数据并将其存储在数据存储中,以供后续进行批处理(这相当于将沿道路行驶的所有汽车重定向到停车场,然后再对其进行计数)。
下图显示了可在大规模数据分析体系结构中结合批处理和流处理的一些方法。
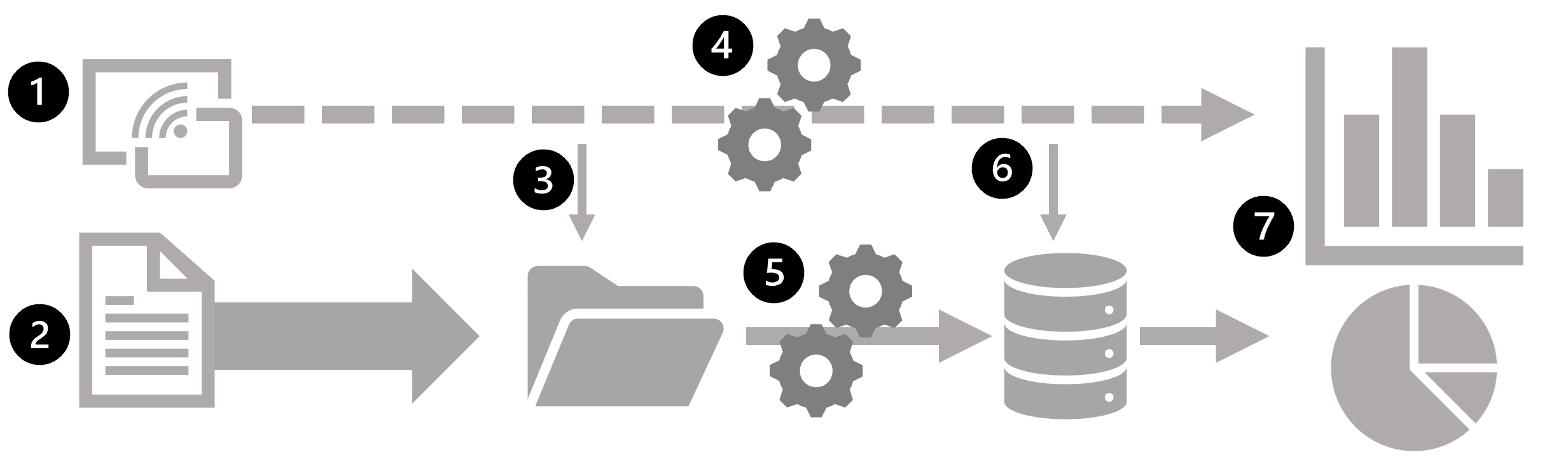
- 实时捕获来自流数据源的数据事件。
- 将来自其他源的数据引入到数据存储(通常是数据湖)供进行批处理。
- 如果不需要实时分析,将捕获的流数据写入到数据存储以供后续进行批处理。
- 在需要实时分析时,使用流处理技术来准备供实时分析或可视化的流数据;通常通过筛选或聚合临时窗口的数据。
- 定期对非流数据进行批处理,以准备用于分析,并将结果保存在分析数据存储(通常称为数据仓库)中供进行历史分析。
- 流处理的结果也可以保存在分析数据存储中,以支持历史分析。
- 使用分析和可视化工具来显示和浏览实时和历史数据。
结合的批数据处理和流数据处理的常用解决方案体系结构包括 lambda 和 delta 体系结构。
这些体系结构的详细信息不在本课程的范围之内,但它们包含用于大规模批数据处理和实时流处理的技术,以创建端到端分析解决方案。
探索流处理体系结构的常见元素
可使用多种技术来实现流处理解决方案,尽管具体的实现细节可能会有所不同,但大多数流体系结构都有一些通用的元素。
流处理的通用体系结构
最简单地说,流处理的高级体系结构如下所示:
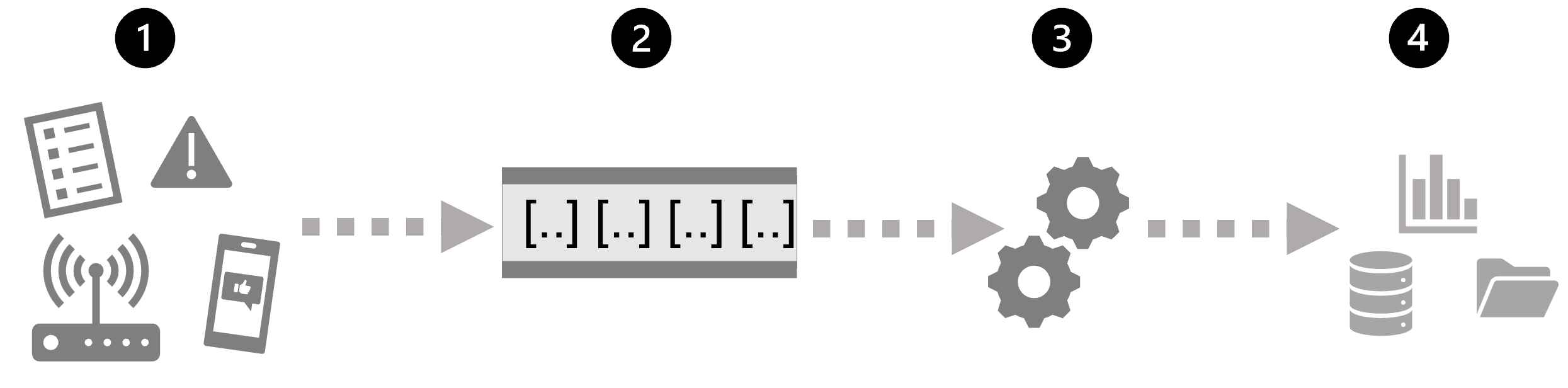
- 事件生成一些数据。 这可能是传感器发出的信号、发布的社交媒体消息、写入的日志文件条目或导致某些数字数据的任何其他事件。
- 将在流式处理源中捕获生成的数据供进行处理。 在简单情况下,该源可能是云数据存储中的文件夹或数据库中的表。 在更可靠的流解决方案中,该源可能是封装逻辑以确保按顺序处理事件数据以及每个事件仅处理一次的“队列”。
- 事件数据通常由永久查询进行处理,该查询对事件数据进行操作,以选择特定类型事件、项目数据值或临时时间段(或窗口)的聚合数据值的数据 - 例如,通过计算每分钟的传感器发射数。
- 流处理操作的结果将写入到输出(或接收器)以供后续下游查询进行进一步处理,该输出(或接收器)可能是文件、数据库表、实时可视化仪表板或其他队列。
Azure 中的实时分析
Microsoft Azure 支持多种可用于实现流式处理数据实时分析的技术,其中包括:
- Azure 流分析:一种平台即服务 (PaaS) 解决方案,可用于定义从流源引入数据、应用永久查询并将结果写入到输出的流作业。
- Spark 结构化流:一种开源库,使你能够在基于 Apache Spark 的服务(包括 Azure Synapse Analytics、Azure Databricks 和 Azure HDInsight)上开发复杂的流解决方案。
- Azure 数据资源管理器:高性能数据库和分析服务,已针对使用时序元素引入和查询批处理或流式处理数据进行了优化,并且可以用作独立的 Azure 服务或用作 Azure Synapse Analytics 工作区中的 Azure Synapse 数据资源管理器运行时。
流处理的源
通常使用以下服务在 Azure 上引入流处理数据:
- Azure 事件中心:一种数据引入服务,可用于管理事件数据队列,确保按顺序处理每个事件且每个事件仅处理一次。
- Azure IoT 中心:一种类似于 Azure 事件中心的数据引入服务,但经过优化,可用于管理来自物联网 (IoT) 设备的事件数据。
- Azure Data Lake Store Gen 2:一种高度可缩放的存储服务,通常用于批处理方案,但也可以用作流数据源。
- Apache Kafka:一种开源数据引入解决方案,通常与 Apache Spark 一起使用。 可使用 Azure HDInsight 创建 Kafka 群集。
流处理的接收器
流处理的输出通常发送到以下服务:
- Azure 事件中心:用于将已处理的数据排队以进行进一步的下游处理。
- Azure Data Lake Store Gen 2 或 Azure blob 存储:用于将处理的结果保存为文件。
- Azure SQL 数据库或 Azure Synapse Analytics 或 Azure Databricks:用于将处理的结果保存在数据库表中以供查询和分析。
- Microsoft Power BI:用于在报表和仪表板中生成实时数据可视化效果。
探索 Azure 流分析
Azure 流分析是一种用于复杂事件处理和流数据分析的服务。 流分析用于:
- 从输入(如 Azure 事件中心、Azure IoT 中心或 Azure 存储 blob 容器)引入数据。
- 通过使用查询选择、投影和聚合数据值来处理数据。
- 将结果写入到输出,例如 Azure Data Lake Gen 2、Azure SQL 数据库、Azure Synapse Analytics、Azure Functions、Azure 事件中心、Microsoft Power BI 或其他输出。
![]()
启动后,流分析查询将永久运行,在新数据到达输入时处理新数据,并将结果存储到输出中。
当你需要持续捕获流式处理源中的数据、对其进行筛选或聚合,并将结果发送到数据存储或下游过程进行分析和报告时,Azure 流分析是一种很好的技术选择。
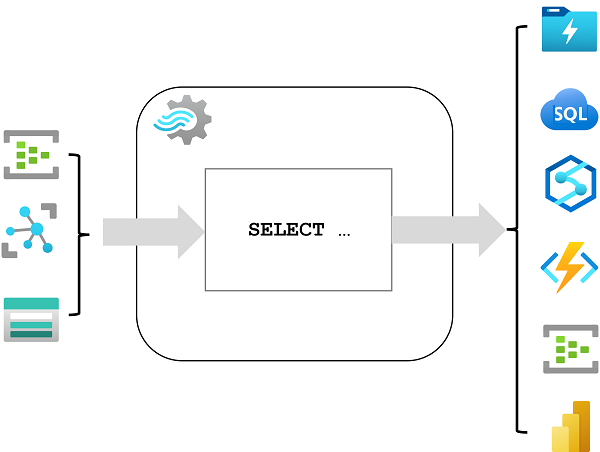
Azure 流分析作业和群集
使用 Azure 流分析的最简单方法是在 Azure 订阅中创建流分析作业,配置其输入和输出,并定义该作业将用于处理数据的查询。 查询使用结构化查询语言 (SQL) 语法来表示,并且可以合并来自多个数据源的静态参考数据,以提供可与从输入中引入的流数据结合的查找值。
如果你的流处理要求很复杂并且占用大量资源,你可创建流分析群集,该群集使用与流分析作业相同的基础处理引擎,但位于专用租户中(因此你的处理不受其他客户的影响),并且具有可配置的可伸缩性,使你能够为特定方案定义吞吐量和成本的适当平衡。
探索 Microsoft Azure 上的 Apache Spark
Apache Spark 是用于大规模数据分析的分布式处理框架。 可在以下服务中使用 Microsoft Azure 上的 Spark:
- Azure Synapse Analytics
- Azure Databricks
- Azure HDInsight
Spark 可用于跨多个群集节点并行运行代码(通常使用 Python、Scala 或 Java 编写),使其能够高效地处理大量数据。 Spark 可同时用于批处理和流处理。
Spark 结构化流
若要在 Spark 上处理流数据,可以使用 Spark 结构化流库,该库提供一个应用程序编程接口 (API),用于引入、处理和输出来自永久数据流的结果。
Spark 结构化流在 Spark 中普遍存在的名为数据帧 DataFrame 的结构上构建而成,该结构封装一个数据表。
你可使用 Spark 结构化流 API 将数据从实时数据源(如 Kafka 中心、文件存储或网络端口)读取到持续填充流中的新数据的“无边界”数据帧中。
然后,在数据帧上定义一个查询,用于选择、投影或聚合数据 - 通常是在临时窗口中。
查询的结果生成另一个数据帧,可保存该数据帧以供分析或进一步处理。

需要将流式处理数据合并到基于 Spark 的数据湖或分析数据存储中时,Spark 结构化流式处理是实时分析的最佳选择。
Delta Lake
Delta Lake 是一种开源存储层,为数据湖存储添加了对事务一致性、架构执行和其他常见数据仓库功能的支持。
此外,它还统一了流数据和批数据的存储,可在 Spark 中用于定义批处理和流处理的关系表。 当用于流处理时,Delta Lake 表可用作针对实时数据的查询的流源,或用作数据流将写入到的接收器。
Azure Synapse Analytics 和 Azure Databricks 中的 Spark 运行时包括对 Delta Lake 的支持。
当你需要在关系模式后面的数据湖中抽象批处理和流处理数据以进行基于 SQL 的查询和分析时,Delta Lake 与 Spark 结构化流式处理相结合是一个很好的解决方案。
探索 Microsoft Fabric 中的实时分析
Microsoft Fabric 包括对实时数据分析的本机支持,其中包括来自多个流式处理源的实时数据引入。
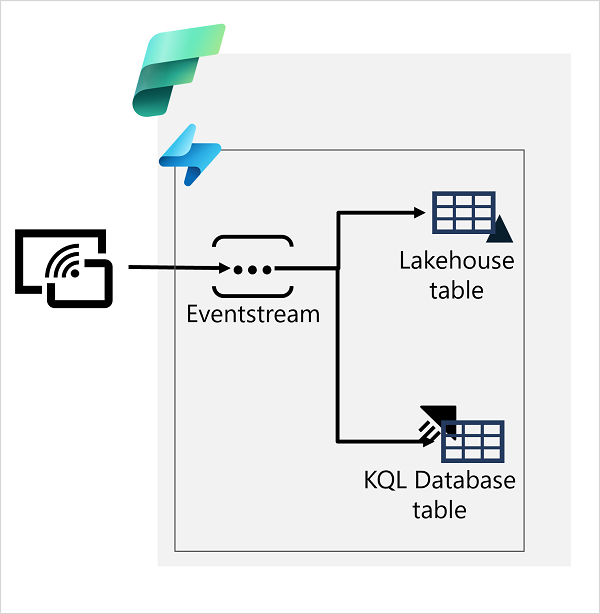
在 Microsoft Fabric 中,可以使用 eventstream 从流式处理源捕获实时事件数据,并将其保存在目标(例如 Lakehouse 或 KQL 数据库中的表)中。
将 eventstream 数据写入 Lakehouse 表时,可以应用聚合和筛选器来汇总捕获的数据。 KQL 数据库支持基于数据资源管理器引擎的表,使你能够通过运行 KQL 查询对表中的数据执行实时分析。 捕获表中的实时数据后,可以使用 Microsoft Fabric 中的 Power BI 创建实时数据可视化效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号