1. 探索大规模分析的基础知识
描述数据仓库体系结构
大规模数据分析体系结构可能各不相同,用于实现它们的特定技术也有所不同,但一般情况下会包括以下元素:
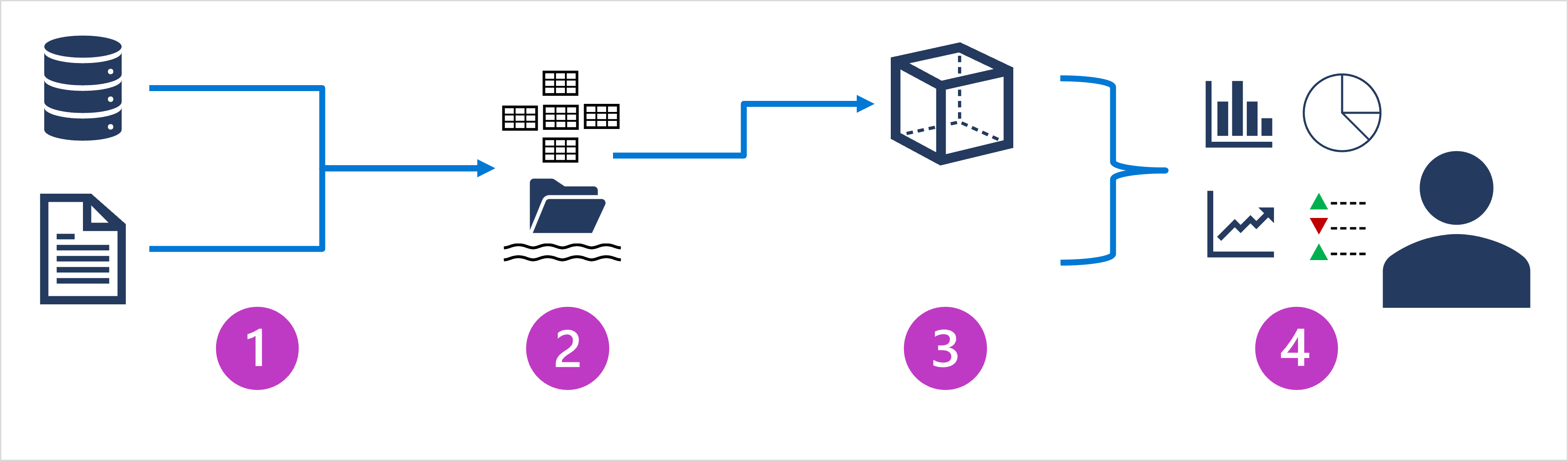
- 数据引入和处理
将一个或多个事务数据存储、文件、实时流或其他源中的数据加载到数据湖或关系数据仓库。
加载操作通常涉及以下操作:提取、转换和加载 (ETL) 或提取、加载和转换 (ELT) 过程,在其中将清除、筛选和重构数据以进行分析。
在 ETL 过程中,在加载数据到分析存储区之前转换数据,而在 ELT 过程中,将复制数据到存储区,然后再转换。
无论采用哪种方式,都将优化生成的数据结构以进行分析查询。
数据处理通常由分布式系统执行,这些系统可以使用多节点群集并行处理大量数据。
数据引入包括静态数据的批处理和流式处理数据的实时处理。 - 分析数据存储
用于大规模分析的数据存储包括关系“数据仓库”、基于文件系统的“数据湖”,以及合并数据仓库和数据湖功能的混合体系结构(有时称为“数据湖仓库”或“湖数据库”)。 - 分析数据模型
虽然数据分析人员和数据科学家可以直接在分析数据存储中使用数据,但通常会创建一个或多个数据模型,以便对数据进行预先聚合,以便更容易地生成报表、仪表板和交互式可视化效果。
通常,这些数据模型被描述为“多维数据集”,其中,数字数据值在一个或多个维度上聚合(例如,按产品和区域确定销售总额)。
该模型封装了数据值与维度实体之间的关系,以支持“向上/向下钻取”分析。 - 数据可视化
数据分析师使用分析模型中的数据,直接从分析存储中创建报表、仪表板和其他可视化对象。
此外,组织中的用户(可能不是技术专业人员)可能会执行自助服务数据分析和报告。
数据的可视化效果可为企业或其他组织显示趋势、比较和关键绩效指标 (kpi),并可采用打印报表、文档中的图形和图表、PowerPoint 的演示文稿、基于 web 的仪表板和交互式环境的形式,从而用户可在其中直观地浏览数据。
了解数据引入管道
现在可以探索如何将数据从一个或多个源注入到分析数据存储中。
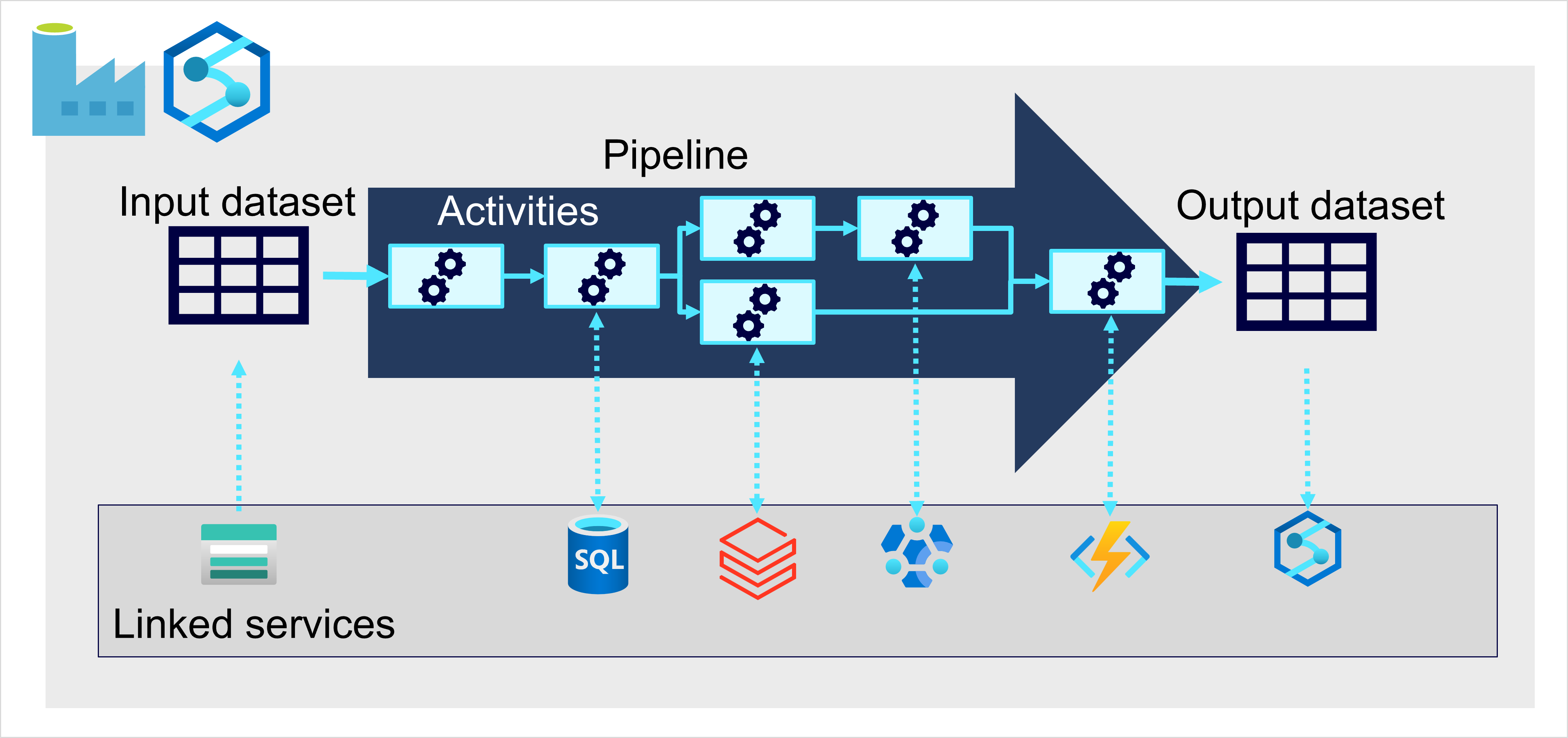
在 Azure 上,通过创建协调 ETL 进程的“管道”,可以最好地实施大规模数据引入。
可以使用 Azure 数据工厂创建和运行管道,或者如果要在统一工作区中管理数据分析解决方案的所有组件,也可以在 Azure Synapse Analytics 或 Microsoft Fabric 中使用类似的管道引擎。
在任一情况下,管道都由一个或多个操作数据的“活动”组成。输入数据集提供源数据,而活动可定义为在生成输出数据集之前增量操作数据的数据流。
管道可以连接到外部数据源,以便与各种数据服务集成。
了解分析数据存储
数据仓库
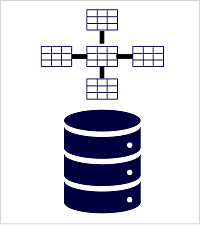
数据仓库是一个关系数据库,其中的数据存储在为数据分析(而非事务性工作负载)进行优化的架构中。
通常情况下,事务性存储中的数据会被转换为某种架构,其中的数值存储在中心的事实数据表中,这些表与一个或多个维度表相关,表示可聚合数据的实体(事实表、维度表)。
例如,“fact”表可能包含销售订单数据,可以按客户、产品、商店和时间维度进行聚合(使你能够轻松地找到每个商店每月的总销售收入)。
这类“fact”和“dimension”表架构称为“星型架构”;虽然它通常通过添加与“dimension”表相关的其他表来扩展到“雪花型”架构,以表示维度层次结构(例如,product 可能与产品类别相关)。
(即星型模型和雪花模型,在星型模型上对维度表进行规范化得到雪花模型,星型模型是雪花模型的一种特例)
如果拥有可以组织成表的结构化架构的事务性数据,且希望使用 SQL 来查询它们,则数据仓库是一种很好的选择。
湖数据库

数据湖是一种文件存储,通常位于可用于高性能数据访问的分布式文件系统上。
Spark 或 Hadoop 等技术通常用于处理对存储文件的查询,并返回数据以进行报告和分析。
这些系统通常会应用“读取模式”方法在读取数据进行分析时定义半结构化数据文件上的表格架构,而无需在存储时应用约束。
数据湖非常适合用于支持混合使用结构化、半结构化、甚至非结构化的数据,在将数据写入存储时无需强制执行架构即可进行分析。
可以使用混合方法,将数据湖和数据仓库的功能组合到“湖数据库”或“数据湖仓库”中。
原始数据作为文件存储在数据湖中,关系存储层将基础文件抽象化并将其公开为表,这些表可以使用 SQL 进行查询。
Azure Synapse Analytics 中的 SQL 池包含 PolyBase,可让你基于数据湖(和其他源)中的文件定义外部表,并使用 SQL 查询它们。
Synapse Analytics 还支持一种“湖数据库”方法,在此方法中,可以使用数据库模板来定义数据仓库的关系架构,同时将基础数据存储在数据湖存储中 – 将存储和计算分别用于数据仓库解决方案。
数据湖仓库是基于 Spark 系统中的一种相对较新的方法,通过“增量湖”等技术启用;这会将关系存储功能添加到 Spark,因此,可以定义表来强制执行架构和事务一致性,支持批处理加载和流式处理数据源,并提供 SQL API 进行查询。
对比
- 数据仓库:传统关系型数据仓库
- 数据湖:解决数仓不便处理半结构化、非结构化数据的问题
- 湖数据库(数据湖仓库):即使对半结构化、非结构化等数据,也支持在数据基础上定义表,使用 SQL API 进行查询
探索平台即服务 (PaaS) 解决方案
在 Azure 上,可以使用三个主要的平台即服务 (PaaS) 服务来实现大规模分析存储。
 |
Azure Synapse Analytics 是统一的、端到端的大规模数据分析解决方案。 | 它汇集了多项技术和功能,使你能够将可缩放的、高性能基于 SQL Server 的关系数据仓库的数据完整性和可靠性与数据湖和开源 Apache Spark 的灵活性结合起来。 它还包括使用 Azure Synapse 数据资源管理器池对日志和遥测分析的本机支持,以及用于数据引入和转换的内置数据管道。 所有 Azure Synapse Analytics 服务都可以通过名为 Azure Synapse Studio 的单个交互式用户界面来管理,其中包括创建交互式笔记本,可在其中合并 Spark 代码和 markdown 内容。 当想要在 Azure 上创建单个、统一的分析解决方案时,Synapse Analytics 是一个不错的选择。 |
 |
Azure Databricks 是流行的 Databricks 平台的 Azure 实现。 | Databricks 是一种基于 Apache Spark 构建的综合性数据分析解决方案,提供了本机 SQL 功能,以及用于数据分析和数据科学的负载优化 Spark 群集。Databricks 提供了一个交互式用户界面,通过该界面可以管理系统,并且可以在交互式笔记本中查看数据。由于在多个云平台上的常见用途,如果想要在平台上使用现有的专业知识,或者需要在多云环境中操作或支持云可移植解决方案,则可以考虑将 Azure Databricks 用作分析存储。 |
 |
Azure HDInsight 是支持多种开源数据分析群集类型的 Azure 服务。 | 尽管不像 Azure Synapse Analytics 和 Azure Databricks 那样用户友好,但如果分析解决方案依赖于多个开源框架或需要将现有的基于 hadoop 的解决方案迁移到云,它可能是一个合适的选择。 |
其中每个服务都可以被视为分析数据“存储”,因为它们提供了可用于查询数据的架构和接口。然而,在许多情况下,数据实际存储在数据湖中,该服务用于“处理”数据和运行查询。
某些解决方案甚至可能会结合使用这些服务。提取、加载和转换 (ELT) 引入过程可能会将数据复制到数据湖中,然后使用其中一种服务来转换数据,并使用另一个服务对数据进行查询。
例如,管道可能会使用在 HDInsight 中运行的 MapReduce 作业或 Azure Databricks 中运行的笔记本来处理数据湖中的大量数据,然后将其加载到 Azure Synapse Analytics 中 SQL 池表中。
探索 Microsoft Fabric

使用 PaaS 服务的可缩放的分析可能很复杂、分散且成本高昂。
使用 Microsoft Fabric 时,无需将所有时间花在组合各种服务并实现业务用户访问它们所需要的接口上。相反,你可以使用易于理解、设置、创建和管理的单个产品。
Fabric 是统一的服务型软件 (SaaS) 产品/服务,所有数据采用单一开放格式存储在 OneLake 中。
OneLake 是 Fabric 以数据湖为中心的体系结构,它为数据专业人员和企业提供了一个单一的集成环境来协作处理数据项目。
将它看作是用于数据的 OneDrivea;OneLake 将不同区域和云中的存储位置组合到单个逻辑湖中,无需移动或复制数据。
数据可以在 OneLake 中以任何文件格式存储,并且可以是结构化或非结构化的。
对于表格数据,Fabric 中的分析引擎在写入 OneLake 时会以 delta 格式写入数据。
所有引擎都知道如何读取此格式并将差异文件视为表,而无论其由哪个引擎写入。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号