【PYTHON】pandas字符替换
处理文本数据时,常见的存储格式为 textfile 格式,对应行分隔符为"\n",列分隔符为"\t"。
而大家往往不会直接使用txt格式文件进行日常操作,Excel 更为简便通用。
因此,如果我们需要处理的 Excel 数据中,某个取值内出现了"\t"或"\n"或"\r\n"符号,转为 txt 格式文件处理将出现数据错位的情况(如上传至 Hive 作为新表)。
示例
如下为取值内包含"\n"的示例
-
在 Excel 中查看数据为:
![]()
-
复制到文本编辑器中查看数据为:
![]()
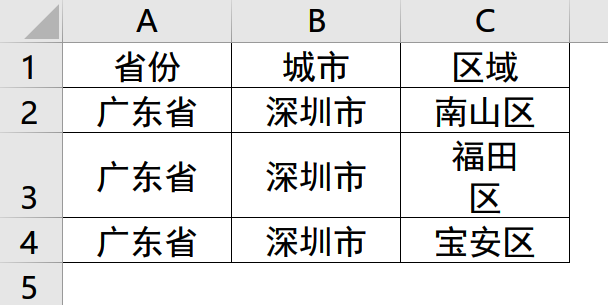

可以看出,在 Excel 中“福田区”这一取值虽然在同一单元格内,但内部进行了换行,即包含了"\n"符号,使用文本编辑器查看时即发现此处进行了换行。
如果不进行特殊处理,这样的数据直接导入 Hive 会发现如上数据错位的情况。
解决方案
-
简便方法
"\t"或"\n"或"\r\n"等都属于分隔符,以文本形式附加在原有字段之后。
简单粗暴的方法就是在 Excel、文本编辑器等软件中直接进行替换操作,将"\n"替换为""或其他非特殊字符串。
但如果数据量较大,这样的方法一是性能问题,二是可能会有误删的情况。 -
使用 pandas 中 replace() 方法处理
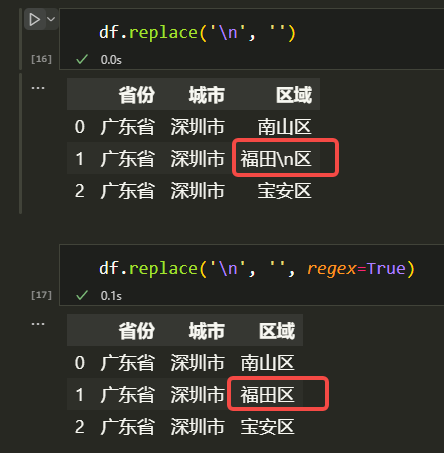
这个方法非常简单直观,直接对所有数据进行全局替换。
![]()
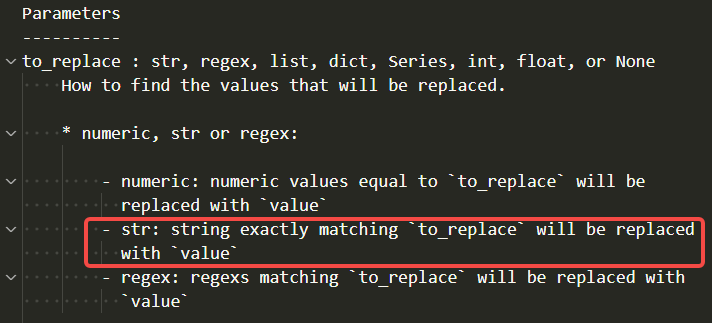
这里需要注意的是,如果传入的是字符串,默认情况下 pandas 会进行完全匹配(exactly matching)。
因此设置 regex=TRUE,使用正则匹配进行替换。
![]()
除此之外,还可以对 Series 或具体单元格使用 replace() 方法。
根据不同的场景及需求使用不同的方法,这样操作可以更为灵活。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号