New IO
为什么要使用NIO?
NIO是JDK1.4加入的新包,目的是为了让java程序员可以实现高速I/O而无需编写自定义的本机代码。NIO将最耗时的I/O操作(填充和提取缓冲区)转移回操作系统,因而可以极大地提高速度。
流与块的比较
原来的I/O库与NIO最重要的区别是数据打包和传输的方式,原来的I/O以流的方式处理数据,而NIO以块的方式处理数据。
面向流的I/O一次一个字节地处理素数。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据,效率相当慢。
面向块的I/O系统以块的形式处理数据。每一个操作都在一步中产生和消费一个块,效率比流快得多,但缺少一些优雅性和简单性。
缓冲区
在NIO库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的。在写入数据时,它是写入缓冲区中的。任何时候访问NIO中的数据,都是将他放到缓冲区中。
缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组,但是一个缓冲区不仅仅是数组。缓冲区提供了对数据的结构化访问,而且可以跟踪系统的读/写进程。
缓冲区类型
最常用的缓冲区类型是ByteBuffere。一个ByteBuffere可以在其底层字节数组上进行get/set操作(即自己的获取和设置)。ByteBuffere不是NIO中唯一的缓冲区类型,对于每一种基本java类型都有一种缓冲区类型:
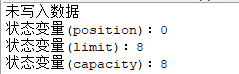
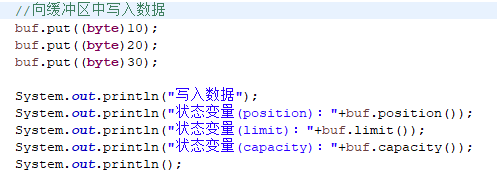
代码







 浙公网安备 33010602011771号
浙公网安备 33010602011771号