
gpu机器安装nvidia-smi和python的tensorflow-gpu模块
os: ubuntu14.04.4
python: 2.7.13
tensorflow-gpu: 1.4.1
cuda: 8.0.44-1
cudnn: cudnn-8.0-linux-x64-v6.0-tgz
1.安装支持gpu设置的tensorflow-gpu
pip install tensorflow-gpu==1.4.1 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2.安装cuda
dpkg -i cuda-repo-ubuntu1404_10.0.130-1_amd64.deb apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1404/x86_64/7fa2af80.pub apt-get update apt-get install cuda=8.0.44-1
安装完cuda,就有nvidia-smi命令可以在shell命令行查看gpu设备。因为nvidia-418、nvidia-418-dev这2个已经被当成依赖安装完成了。
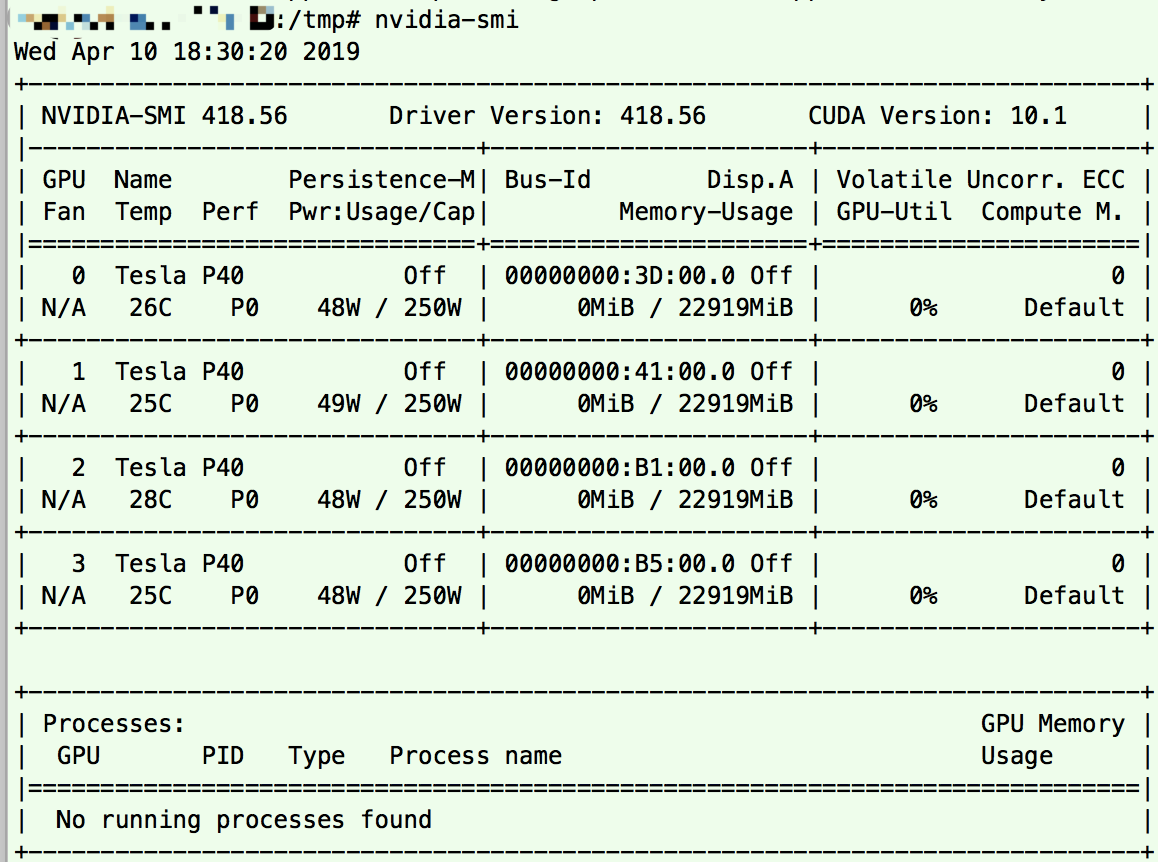
当时因为碰到这个问题 https://devtalk.nvidia.com/default/topic/1048630/b/t/post/5322060/
解决思路来自 https://developer.nvidia.com/cuda-10.0-download-archive选择操作系统、版本,下载cuda-repo-ubuntu1404_10.0.130-1_amd64.deb。
3.安装cudnn
因为libcudnn.so.6: cannot open shared object file: No such file or directory这个报错
google了一圈发现, 问题出在 TensorFlow 1.4-gpu 是基于cuDNN6,需要的也就是libcudnn.so.6了。
解决方案:
到官网https://developer.nvidia.com/cudnn下载相应的cudnn库
tar xvzf cudnn-8.0-linux-x64-v6.0.tgz
cp -P cuda/include/cudnn.h /usr/local/cuda/include
cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
Now set Path variables
$ vim ~/.bashrc
翻到最底部加上:
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cuda
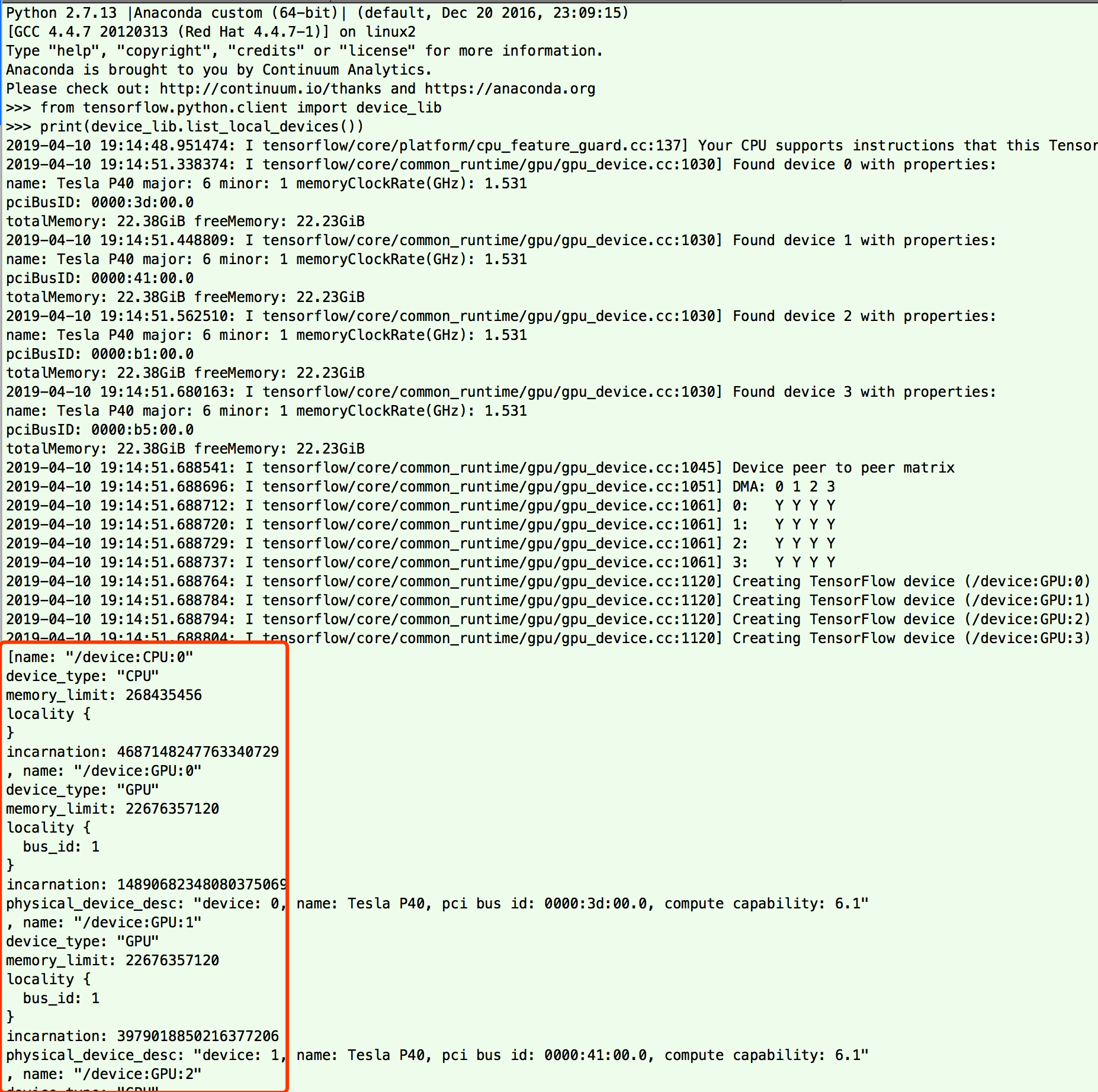
最后进去python命令行
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
看看输出信息有没有显示GPU设备
另外如果nvidia-smi碰到以下报错,可以尝试重启(反正我是这么解决的。。)
Failed to initialize NVML: Driver/library version mismatch
NVIDIA CUDA 国内镜像
下载地址:https://mirrors.aliyun.com/nvidia-cuda/
curl -fsSL https://mirrors.aliyun.com/nvidia-cuda/ubuntu1804/x86_64/7fa2af80.pub\ | sudo apt-key add - echo "deb https://mirrors.aliyun.com/nvidia-cuda/ubuntu1804/x86_64/ ./" > /etc/apt/sources.list.d/cuda.list
#安装最新版cuda
apt update && apt-get install nvidia-driver-455 -y

 浙公网安备 33010602011771号
浙公网安备 33010602011771号