

Xilinx 常用模块汇总(verilog)【03】
作者:桂。
时间:2018-05-10 2018-05-10 21:03:44
链接:http://www.cnblogs.com/xingshansi/p/9021919.html
前言
主要记录常用的基本模块。
一、模块汇总
- 17- 自相关操作xcorr
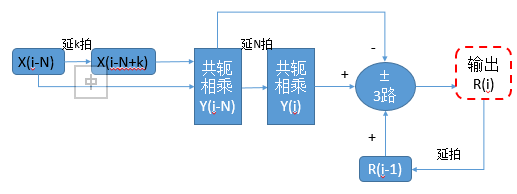
实现思路主要参考:工程应用中的自相关操作,根据推导可以看出,自相关操作涉及的基本操作有:复数相乘、递归【自回归,IIR等都需要该操作】。
涉及到具体模块:1)10- 共轭复数相乘模块; 2)11- 复数延拍模块; 3)递归 —> 1- 3个数组合加、减运算(分I\Q分别调用)。
路径:印象笔记:0019/015
MATLAB仿真(实际操作中,N除不除->移位,差别不大):
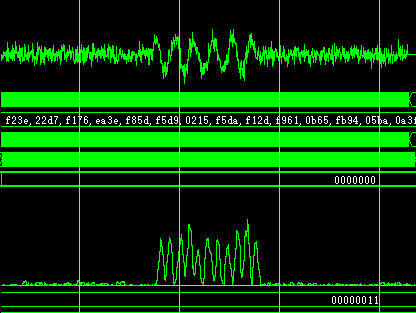
clc;clear all;close all; fs = 960e6; f0 = 20e6; t = [0:255]/fs; sig = [zeros(1,384),exp(1j*(2*pi*t*f0+pi/4)),zeros(1,384)]; sig = awgn(sig,5); %自相关 N = 64; k = 1; R = zeros(1,length(sig)); for i = N+1:length(sig)-k R(i) = R(i-k) + 1/N * (sig(i)*conj(sig(i+k)) - sig(i-N)*conj(sig(i-N+k))); end figure() subplot 211 plot(abs(sig)/max(abs(sig))); subplot 212 plot(abs(R)/max(abs(R)));
verilog【给出完整分析、实现、仿真过程】:
不失一般性,以k=1为例,
理论分析:
用到的基本模块:1)10- 共轭相乘;2)11- 复数延拍;3)1- 3路加减运算。
硬件实现:
其中延拍,也可调用原语:SRL(移位链 )+ FDRE的思路:
//Shift:SRL[A3A2A1A0] + 2 parameter width = 16; //data width genvar ii; generate for(ii = 0; ii < width; ii++) begin:delay // (* HLUTNM = ii *) SRL16E #( .INIT(16'h0000) // Initial Value of Shift Register ) SRL16E_u1 ( .Q(out_cache[ii]), // SRL data output .A0(1'b0), // Select[0] input .A1(1'b1), // Select[1] input .A2(1'b1), // Select[2] input .A3(1'b0), // Select[3] input .CE(1'b1), // Clock enable input .CLK(clk), // Clock input .D(ddata[ii]) // SRL data input ); FDRE #( .INIT(1'b0) // Initial value of register (1'b0 or 1'b1) ) FDRE_u1 ( .Q(out[ii]), // 1-bit Data output .C(clk), // 1-bit Clock input .CE(1'b1), // 1-bit Clock enable input .R(sclr), // 1-bit Synchronous reset input .D(out_cache[ii]) // 1-bit Data input ); end endgenerate细节可参考scm.pdf /hdl.pdf:
功能仿真:
1)生成仿真数据:
clc;clear all;close all; fs = 960e6; f0 = 20e6; t = [0:255]/fs; sig = [zeros(1,384),sin(2*pi*t*f0+pi/4),zeros(1,384)]; sig = awgn(sig,10); L = length(sig); N = 17; t0 = [0:L-1]/fs; y_n = round(sig*(2^(N-2)-1)); %write data fid = fopen('sig.txt','w'); for k=1:length(y_n) B_s=dec2bin(y_n(k)+((y_n(k))<0)*2^N,N); for j=1:N if B_s(j)=='1' tb=1; else tb=0; end fprintf(fid,'%d',tb); end fprintf(fid,'\r\n'); end fprintf(fid,';'); fclose(fid);2)仿真结果:
MATLAB测试数据:
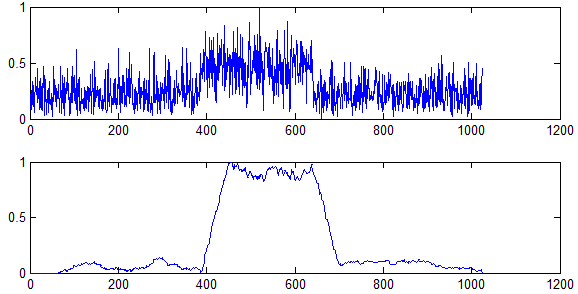
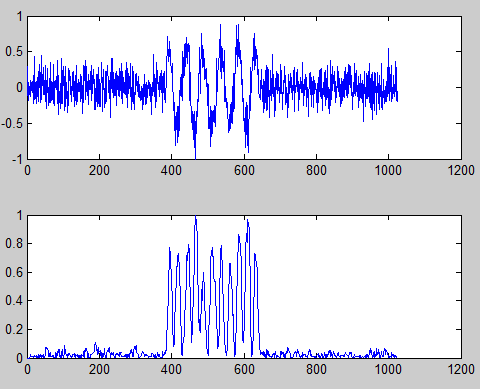
VIVADO输出结果:
从仿真结果可以看出,二者完全一致,Xcorr模块有效。【X点自相关,仅需要修改共轭相乘结果的延迟拍数即可,这便实现了参数化。】
代码路径:印象笔记0019/015Xcorr

- 18- 数据速率转化模块
路径:印象笔记-1/0019/017
跨时钟域,对于moni-bit,可用打2拍的思路,即定义两级寄存器,以降低亚稳态概率;对于multi-bits,目前跨时钟域的数据传输,常用的两个基本思路是:1)异步FIFO;2)异步 dual port RAM 。(ug473.pdf)
1)FIFO(first in first out)
更多细节可参考:印象笔记-3-FPGA/024-FIFO核使用,以及博文:基础003_V7-Memory Resources
要点1:最小深度计算
要点2:数据传输转换关系:输入的数据量理论上需要小于等于输出的数据量。
FIFO多与高速接口配合使用。
2)Dual port RAM
关于IP核的使用,可参考:印象笔记-3/FPGA/025-双端口RAM参数设置,双端口RAM与FIFO最大的区别在于存在读、写地址,如果数据存在偏移,可以很方便地修正偏移量。
应用举例:现有两路数据存在偏移,希望将二者对齐,以Dual port RAM为例,调用XILINX 的 IP核,细节参考博文:DUAL PORT RAM应用实例

- 19- 卷积模块(convolution)
路径:1/0019/019
分析:卷积的理论细节及多种实现思路,可参考博文:信号处理——卷积(convolution)的实现
这里只给出一种普适的思路,且仅考虑实数情况:对于复数域C,拆解为实、虚部即可。定义序列h:
对应卷积原理:
实现的思路是:1)直接延拍+寄存器,2)累加操作(累加长度等于最短序列长度,此处为M),即可完成卷积。
延拍 + 寄存器:
delay_all.sv
 View Code`timescale 1ns/1ps /* Function: DPRAM for data aligned Author: Gui. Data: 2018年5月14日16:31:09 */ /* 等价于: dout <= {dout[Num-2:0],din}; // SliceM without rst */ module delay_all(din, clk, sclr, dout); parameter datwidth = 17; parameter Num = 8; input [datwidth-1:0] din; input clk; input sclr; output [Num-1:0][datwidth-1:0] dout; // logic [Num-1:0][datwidth-1:0] dat; genvar ii; generate for (ii = 1;ii < Num; ii++) begin:delayall delay #( .datwidth(datwidth) ) u1( .din(dat[ii-1]), .clk(clk), .sclr(sclr), .dout(dat[ii]) ); end endgenerate always @(posedge clk) if(sclr) begin dat <= 0; end else begin dat[0] <= din; end assign dout = dat; endmodule
View Code`timescale 1ns/1ps /* Function: DPRAM for data aligned Author: Gui. Data: 2018年5月14日16:31:09 */ /* 等价于: dout <= {dout[Num-2:0],din}; // SliceM without rst */ module delay_all(din, clk, sclr, dout); parameter datwidth = 17; parameter Num = 8; input [datwidth-1:0] din; input clk; input sclr; output [Num-1:0][datwidth-1:0] dout; // logic [Num-1:0][datwidth-1:0] dat; genvar ii; generate for (ii = 1;ii < Num; ii++) begin:delayall delay #( .datwidth(datwidth) ) u1( .din(dat[ii-1]), .clk(clk), .sclr(sclr), .dout(dat[ii]) ); end endgenerate always @(posedge clk) if(sclr) begin dat <= 0; end else begin dat[0] <= din; end assign dout = dat; endmoduledelay.sv
View Code`timescale 1ns/1ps /* Function: DPRAM for data aligned Author: Gui. Data: 2018年5月14日16:21:09 */ module delay(din, clk, sclr, dout); parameter datwidth = 17; input [datwidth-1:0] din; input clk; input sclr; output [datwidth-1:0] dout; wire [datwidth-1:0] q; genvar ii; generate for(ii = 0; ii < datwidth; ii++) begin:delay FDRE #( .INIT(1'b0) // Initial value of register (1'b0 or 1'b1) ) FDRE_u1 ( .Q(q[ii]), // 1-bit Data output .C(clk), // 1-bit Clock input .CE(1'b1), // 1-bit Clock enable input .R(sclr), // 1-bit Synchronous reset input .D(din[ii]) // 1-bit Data input ); end endgenerate endmodule该延拍操作可等价为一个语句:
dout <= {dout[Num-2:0],din};不添加复位信号,则内部资源调用CLB中的SliceM。
累加操作,3加法器结合:
localparam ParaNum = (Num % 3)?(Num/3 + 1):(Num/3);// parallel Number localparam Actbits = ParaNum*3;// Actually bits该操作对于卷积系数较少的情况勉强适用,但对于阶数过大的情形、既耗内存、又增加群延迟。对于阶数较多的情形,可借助FIR调用DSP48E_05一文的实现思路。关于IP核的使用,对应文档::pg149-fir-compiler.pdf
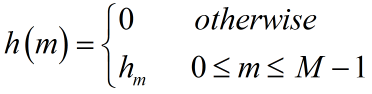
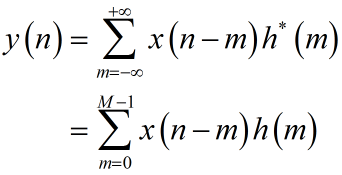

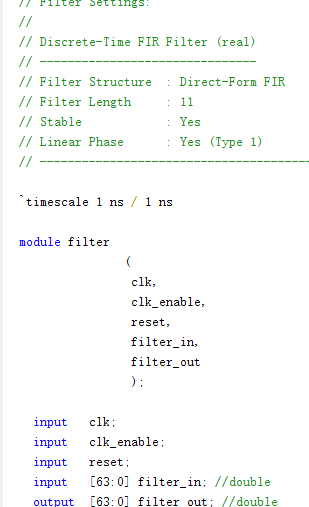
- 20- FIR滤波模块
原理同19- 卷积操作,完全一致,滤波器系数设计参考博文:fdatool的滤波器设计 以及 FIR特性及仿真实现_01
如果只是基本的滤波器实现,可以借助Fdatool -> targets -> generate HDL.
- 21- Hilbert变换
原理同19- 卷积操作,完全一致,Hilbert工程实现上也可以借助FIR的设计思想,且设计工具也完全一致,不再具体描述。
目前主要的模块:

- 22- IIR滤波模块
该功能目前使用较少,拆解下来:延拍 + 加减法,差别不大。同样可以直接用MATLAB生成verilog文件:
View Code// ------------------------------------------------------------- // // Module: filteriir // Generated by MATLAB(R) 8.1 and the Filter Design HDL Coder 2.9.3. // Generated on: 2018-05-15 13:03:46 // ------------------------------------------------------------- // ------------------------------------------------------------- // HDL Code Generation Options: // // Name: filteriir // TargetLanguage: Verilog // TestBenchStimulus: step ramp chirp // GenerateHDLTestBench: off // Filter Specifications: // // Sampling Frequency : N/A (normalized frequency) // Response : Lowpass // Specification : N,F3dB // Filter Order : 10 // 3-dB Point : 0.45 // ------------------------------------------------------------- // ------------------------------------------------------------- // HDL Implementation : Fully parallel // Multipliers : 15 // Folding Factor : 1 // ------------------------------------------------------------- // Filter Settings: // // Discrete-Time IIR Filter (real) // ------------------------------- // Filter Structure : Direct-Form II, Second-Order Sections // Number of Sections : 5 // Stable : Yes // Linear Phase : No // ------------------------------------------------------------- `timescale 1 ns / 1 ns module filteriir ( clk, clk_enable, reset, filter_in, filter_out ); input clk; input clk_enable; input reset; input [63:0] filter_in; //double output [63:0] filter_out; //double //////////////////////////////////////////////////////////////// //Module Architecture: filteriir //////////////////////////////////////////////////////////////// // Local Functions // Type Definitions // Constants parameter scaleconst1 = 3.6533535137021494E-01; //double parameter coeff_b1_section1 = 1.0000000000000000E+00; //double parameter coeff_b2_section1 = 2.0000000000000000E+00; //double parameter coeff_b3_section1 = 1.0000000000000000E+00; //double parameter coeff_a2_section1 = -2.7099751179194387E-01; //double parameter coeff_a3_section1 = 7.3233891727280376E-01; //double parameter scaleconst2 = 2.9120577213381943E-01; //double parameter coeff_b1_section2 = 1.0000000000000000E+00; //double parameter coeff_b2_section2 = 2.0000000000000000E+00; //double parameter coeff_b3_section2 = 1.0000000000000000E+00; //double parameter coeff_a2_section2 = -2.1600986428424435E-01; //double parameter coeff_a3_section2 = 3.8083295281952212E-01; //double parameter scaleconst3 = 2.4834107896254057E-01; //double parameter coeff_b1_section3 = 1.0000000000000000E+00; //double parameter coeff_b2_section3 = 2.0000000000000000E+00; //double parameter coeff_b3_section3 = 1.0000000000000000E+00; //double parameter coeff_a2_section3 = -1.8421380307753588E-01; //double parameter coeff_a3_section3 = 1.7757811892769818E-01; //double parameter scaleconst4 = 2.2434814972791137E-01; //double parameter coeff_b1_section4 = 1.0000000000000000E+00; //double parameter coeff_b2_section4 = 2.0000000000000000E+00; //double parameter coeff_b3_section4 = 1.0000000000000000E+00; //double parameter coeff_a2_section4 = -1.6641639010121584E-01; //double parameter coeff_a3_section4 = 6.3808989012861264E-02; //double parameter scaleconst5 = 2.1350378853875973E-01; //double parameter coeff_b1_section5 = 1.0000000000000000E+00; //double parameter coeff_b2_section5 = 2.0000000000000000E+00; //double parameter coeff_b3_section5 = 1.0000000000000000E+00; //double parameter coeff_a2_section5 = -1.5837228791342844E-01; //double parameter coeff_a3_section5 = 1.2387442068467328E-02; //double // Signals real input_register; // double real scale1; // double real scaletypeconvert1; // double // Section 1 Signals real a1sum1; // double real a2sum1; // double real b1sum1; // double real b2sum1; // double real delay_section1 [0:1] ; // double real inputconv1; // double real a2mul1; // double real a3mul1; // double real b1mul1; // double real b2mul1; // double real b3mul1; // double real scale2; // double real scaletypeconvert2; // double // Section 2 Signals real a1sum2; // double real a2sum2; // double real b1sum2; // double real b2sum2; // double real delay_section2 [0:1] ; // double real inputconv2; // double real a2mul2; // double real a3mul2; // double real b1mul2; // double real b2mul2; // double real b3mul2; // double real scale3; // double real scaletypeconvert3; // double // Section 3 Signals real a1sum3; // double real a2sum3; // double real b1sum3; // double real b2sum3; // double real delay_section3 [0:1] ; // double real inputconv3; // double real a2mul3; // double real a3mul3; // double real b1mul3; // double real b2mul3; // double real b3mul3; // double real scale4; // double real scaletypeconvert4; // double // Section 4 Signals real a1sum4; // double real a2sum4; // double real b1sum4; // double real b2sum4; // double real delay_section4 [0:1] ; // double real inputconv4; // double real a2mul4; // double real a3mul4; // double real b1mul4; // double real b2mul4; // double real b3mul4; // double real scale5; // double real scaletypeconvert5; // double // Section 5 Signals real a1sum5; // double real a2sum5; // double real b1sum5; // double real b2sum5; // double real delay_section5 [0:1] ; // double real inputconv5; // double real a2mul5; // double real a3mul5; // double real b1mul5; // double real b2mul5; // double real b3mul5; // double real output_typeconvert; // double real output_register; // double // Block Statements always @ (posedge clk or posedge reset) begin: input_reg_process if (reset == 1'b1) begin input_register <= 0.0000000000000000E+00; end else begin if (clk_enable == 1'b1) begin input_register <= $bitstoreal(filter_in); end end end // input_reg_process always @* scale1 <= input_register * scaleconst1; always @* scaletypeconvert1 <= scale1; // ------------------ Section 1 ------------------ always @ (posedge clk or posedge reset) begin: delay_process_section1 if (reset == 1'b1) begin delay_section1[0] <= 0.0000000000000000E+00; delay_section1[1] <= 0.0000000000000000E+00; end else begin if (clk_enable == 1'b1) begin delay_section1[1] <= delay_section1[0]; delay_section1[0] <= a1sum1; end end end // delay_process_section1 always @* inputconv1 <= scaletypeconvert1; always @* a2mul1 <= delay_section1[0] * coeff_a2_section1; always @* a3mul1 <= delay_section1[1] * coeff_a3_section1; always @* b1mul1 <= a1sum1; always @* b2mul1 <= delay_section1[0] * coeff_b2_section1; always @* b3mul1 <= delay_section1[1]; always @* a2sum1 <= inputconv1 - a2mul1; always @* a1sum1 <= a2sum1 - a3mul1; always @* b2sum1 <= b1mul1 + b2mul1; always @* b1sum1 <= b2sum1 + b3mul1; always @* scale2 <= b1sum1 * scaleconst2; always @* scaletypeconvert2 <= scale2; // ------------------ Section 2 ------------------ always @ (posedge clk or posedge reset) begin: delay_process_section2 if (reset == 1'b1) begin delay_section2[0] <= 0.0000000000000000E+00; delay_section2[1] <= 0.0000000000000000E+00; end else begin if (clk_enable == 1'b1) begin delay_section2[1] <= delay_section2[0]; delay_section2[0] <= a1sum2; end end end // delay_process_section2 always @* inputconv2 <= scaletypeconvert2; always @* a2mul2 <= delay_section2[0] * coeff_a2_section2; always @* a3mul2 <= delay_section2[1] * coeff_a3_section2; always @* b1mul2 <= a1sum2; always @* b2mul2 <= delay_section2[0] * coeff_b2_section2; always @* b3mul2 <= delay_section2[1]; always @* a2sum2 <= inputconv2 - a2mul2; always @* a1sum2 <= a2sum2 - a3mul2; always @* b2sum2 <= b1mul2 + b2mul2; always @* b1sum2 <= b2sum2 + b3mul2; always @* scale3 <= b1sum2 * scaleconst3; always @* scaletypeconvert3 <= scale3; // ------------------ Section 3 ------------------ always @ (posedge clk or posedge reset) begin: delay_process_section3 if (reset == 1'b1) begin delay_section3[0] <= 0.0000000000000000E+00; delay_section3[1] <= 0.0000000000000000E+00; end else begin if (clk_enable == 1'b1) begin delay_section3[1] <= delay_section3[0]; delay_section3[0] <= a1sum3; end end end // delay_process_section3 always @* inputconv3 <= scaletypeconvert3; always @* a2mul3 <= delay_section3[0] * coeff_a2_section3; always @* a3mul3 <= delay_section3[1] * coeff_a3_section3; always @* b1mul3 <= a1sum3; always @* b2mul3 <= delay_section3[0] * coeff_b2_section3; always @* b3mul3 <= delay_section3[1]; always @* a2sum3 <= inputconv3 - a2mul3; always @* a1sum3 <= a2sum3 - a3mul3; always @* b2sum3 <= b1mul3 + b2mul3; always @* b1sum3 <= b2sum3 + b3mul3; always @* scale4 <= b1sum3 * scaleconst4; always @* scaletypeconvert4 <= scale4; // ------------------ Section 4 ------------------ always @ (posedge clk or posedge reset) begin: delay_process_section4 if (reset == 1'b1) begin delay_section4[0] <= 0.0000000000000000E+00; delay_section4[1] <= 0.0000000000000000E+00; end else begin if (clk_enable == 1'b1) begin delay_section4[1] <= delay_section4[0]; delay_section4[0] <= a1sum4; end end end // delay_process_section4 always @* inputconv4 <= scaletypeconvert4; always @* a2mul4 <= delay_section4[0] * coeff_a2_section4; always @* a3mul4 <= delay_section4[1] * coeff_a3_section4; always @* b1mul4 <= a1sum4; always @* b2mul4 <= delay_section4[0] * coeff_b2_section4; always @* b3mul4 <= delay_section4[1]; always @* a2sum4 <= inputconv4 - a2mul4; always @* a1sum4 <= a2sum4 - a3mul4; always @* b2sum4 <= b1mul4 + b2mul4; always @* b1sum4 <= b2sum4 + b3mul4; always @* scale5 <= b1sum4 * scaleconst5; always @* scaletypeconvert5 <= scale5; // ------------------ Section 5 ------------------ always @ (posedge clk or posedge reset) begin: delay_process_section5 if (reset == 1'b1) begin delay_section5[0] <= 0.0000000000000000E+00; delay_section5[1] <= 0.0000000000000000E+00; end else begin if (clk_enable == 1'b1) begin delay_section5[1] <= delay_section5[0]; delay_section5[0] <= a1sum5; end end end // delay_process_section5 always @* inputconv5 <= scaletypeconvert5; always @* a2mul5 <= delay_section5[0] * coeff_a2_section5; always @* a3mul5 <= delay_section5[1] * coeff_a3_section5; always @* b1mul5 <= a1sum5; always @* b2mul5 <= delay_section5[0] * coeff_b2_section5; always @* b3mul5 <= delay_section5[1]; always @* a2sum5 <= inputconv5 - a2mul5; always @* a1sum5 <= a2sum5 - a3mul5; always @* b2sum5 <= b1mul5 + b2mul5; always @* b1sum5 <= b2sum5 + b3mul5; always @* output_typeconvert <= b1sum5; always @ (posedge clk or posedge reset) begin: Output_Register_process if (reset == 1'b1) begin output_register <= 0.0000000000000000E+00; end else begin if (clk_enable == 1'b1) begin output_register <= output_typeconvert; end end end // Output_Register_process // Assignment Statements assign filter_out = $realtobits(output_register); endmodule // filteriir
- 23- 查找表和进位链(LUT CARRY,组合逻辑单元)
查找表分表是LUT2、LUT5、LUT6,一个基本例子:12bit或操作。
View Codeassign user_out = |datin[11:0]; //LUT wire out, out1_14; LUT6 #( .INIT(64'hFFFFFFFFFFFFFFFE)) out1 ( .I0(datin[3]), .I1(datin[2]), .I2(datin[5]), .I3(datin[4]), .I4(datin[7]), .I5(datin[6]), .O(out) ); LUT6 #( .INIT(64'hFFFFFFFFFFFFFFFE)) out2 ( .I0(datin[9]), .I1(datin[8]), .I2(datin[11]), .I3(datin[10]), .I4(datin[1]), .I5(datin[0]), .O(out1_14) ); LUT2 #( .INIT(4'hE)) out3 ( .I0(out), .I1(out1_14), .O(user_out) );
后续1:扩展矩阵运算、自适应处理模块
后续2:学习接口协议、通信网络协议
后续3:sysgen 学习模块搭建
后续4:HLS(选学)/microblaze
后续5:调研更加智能化地解决FPGA算法设计实现的工具,例如python好像就存在这样的工具包....
切记,兼顾论文阅读、多向前辈请教。
